MySQL问题8
MySQL深度分页优化思路
常见的3种优化思路如下:
1. 子查询优化方式
示例改写前:
SELECT * FROM words
WHERE name = 'oee'
ORDER BY id
LIMIT 99999990, 10;
这个写法会导致 MySQL 扫描并丢弃前面 99999990 行,效率极低。
示例改写后:
SELECT * FROM words
WHERE name = 'one'AND id >= (SELECT id FROM wordsWHERE name = 'one'ORDER BY idLIMIT 99999990, 1)
ORDER BY id
LIMIT 10;
优点:
- 子查询只查索引字段
id,访问数据量小; - 主查询直接从命中的
id开始,避免大范围跳过; - 支持使用覆盖索引提升速度。
2. 记录 ID 方式(基于位置的分页)
每页返回当前页最大 ID,前端保存下来作为下一页的起点。
示例:
上一页最后一条记录的 id = 100001,则下一页查询为:
SELECT * FROM words
WHERE id > 100001
ORDER BY id
LIMIT 10;
优点:
- 无需 OFFSET,不跳过数据,效率高;
- 避免回表和大量扫描,非常适合“滚动加载”或“下一页”模式。
3. 使用 Elasticsearch 替代分页
对于超大数据量,可以将数据同步到 Elasticsearch,利用其内建的分页机制如:
search_after(推荐)scroll(适合大批量导出)
优点:
- ES 的倒排索引和分页机制在大数据下表现更好;
- 查询速度快,灵活支持多字段排序和全文搜索。
主从同步机制和实现策略
MySQL中的主从同步机制是一种数据复制技术,将主库(Master)的数据同步到一个或多个从库(Slave),主要通过二进制日志(bin log)实现数据的复制,然后推送给从数据库,从库重放对应日志完成复制。
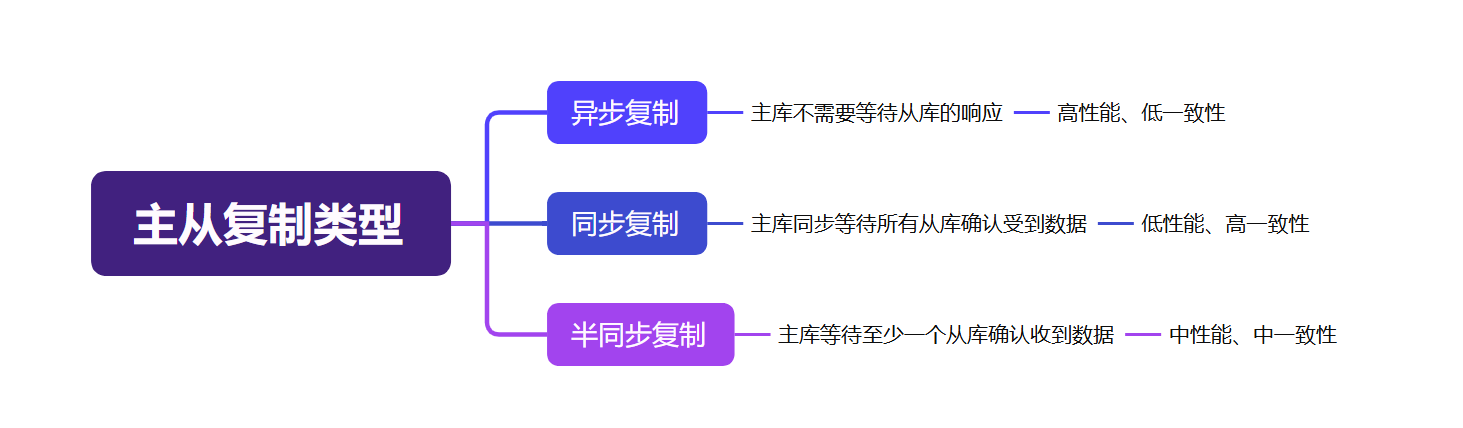
优化主从同步延迟
延迟是必然存在的,只能优化无法避免。
常见的4种解决方式:
1. 二次查询
如果从库查询不到结果,可以降级回主库查询一次。
查询从库 → 没查到 → 查询主库 → 返回结果
优点:
- 实现简单,属于兜底策略;
- 适用于部分对一致性有要求的接口,比如用户刚注册、写入后马上查询的场景。
缺点:
- 如果用得太频繁,反而将读压力转移回主库;
- 对主库造成冲击,违背了读写分离的初衷;
- 如果某些查询确定从库必定查不到,可能加剧问题。
2. 强制写后读走主库
对于“写入后立即读取”的操作,强制绑定这些查询走主库,确保数据最新。
在代码层约定:某些操作的读取必须从主库读。
优点:
- 保证强一致性;
- 避免延迟导致的数据查不到问题。
缺点:
- 写死逻辑,灵活性差;
- 开发维护成本高,不推荐大范围使用;
- 无法利用从库分担查询压力。
3. 关键业务读写都走主库
对于一些关键业务(如登录、注册、下单)直接从主库读写,不依赖从库。
举例:
用户注册后马上登录,如果读取从库可能查不到注册信息;此时登录接口直接走主库即可避免问题。
优点:
- 避免数据同步延迟引起的“查不到”;
- 适用于低频关键路径操作;
- 实现相对简单,业务上可控。
缺点:
- 主库读压力可能上升(但频率不高问题不大);
- 逻辑需要与业务强绑定。
4. 使用缓存(如 Redis)中转数据
主库写入后,将数据同步到缓存中(如 Redis)。读取请求优先从缓存中查询。
优点:
- 规避主从延迟问题,缓存读取更快;
- 减轻主库和从库压力;
- 适用于频繁访问的热点数据。
缺点:
- 引入缓存一致性问题;
- 缓存更新/失效策略需要配合设计;
- 系统复杂度提升。
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 二次查询 | 简单兜底 | 主库压力增加 | 不一致时容错 |
| 强制写后读主库 | 保证一致性 | 写死逻辑、维护复杂 | 写后即查操作 |
| 关键读写走主库 | 可控、可靠 | 主库压力略大 | 注册/登录类接口 |
| 使用缓存 | 高性能、抗延迟 | 引入一致性问题 | 热点数据读多写少 |