三、大模型微调的多种方法与应用场景
详解大模型微调的多种方法与应用场景
随着大模型的不断发展,如何有效地微调这些庞大的预训练模型以适应特定任务成为了研究和应用中的一个重要问题。大模型微调不仅能够提高任务性能,还能在不同的业务需求中提升模型的适应性。在本文中,我们将详细介绍几种常见的大模型微调方法,包括它们的定义、特点、区别、适用场景等内容。通过对这些方法的深入分析,帮助大家更好地理解如何选择合适的微调方式来提升大模型的表现。
1. Prompt Tuning:小模型适配下游任务
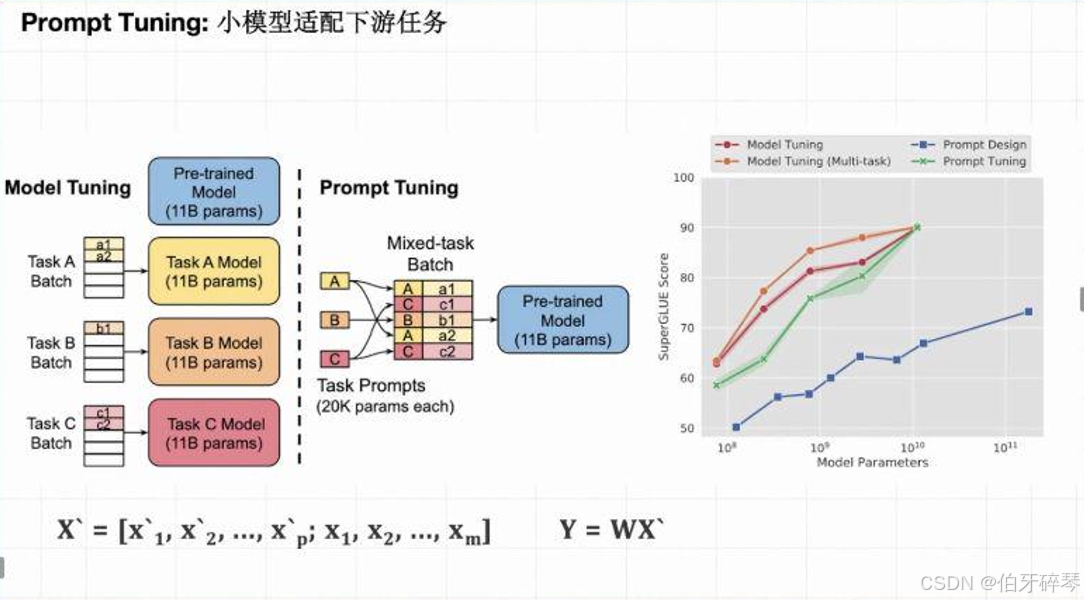
定义:
Prompt Tuning 是一种基于输入提示的微调方法,它通过调整和学习输入中的提示(prompt)来引导大模型的输出,以适配不同的下游任务。这种方法的一个显著特点是,它不需要改变模型的核心参数,而是通过设计任务相关的输入模板来对模型进行微调。
特点:
- 低开销:仅需训练一小部分参数(即任务相关的prompt),不会影响到大规模模型的核心结构。
- 快速调整:可以迅速适配不同的任务,且容易切换。
- 易于扩展:能够在多个不同任务间快速迁移,无需为每个任务训练一个新的模型。
适用场景:
Prompt Tuning 特别适用于需要快速调优并且不希望过多改变模型内部参数的场景。比如,问答系统、情感分析、文本生成等任务,都可以通过设计不同的prompt来实现。
2. Prefix Tuning:在 Transformer 中适配下游任务
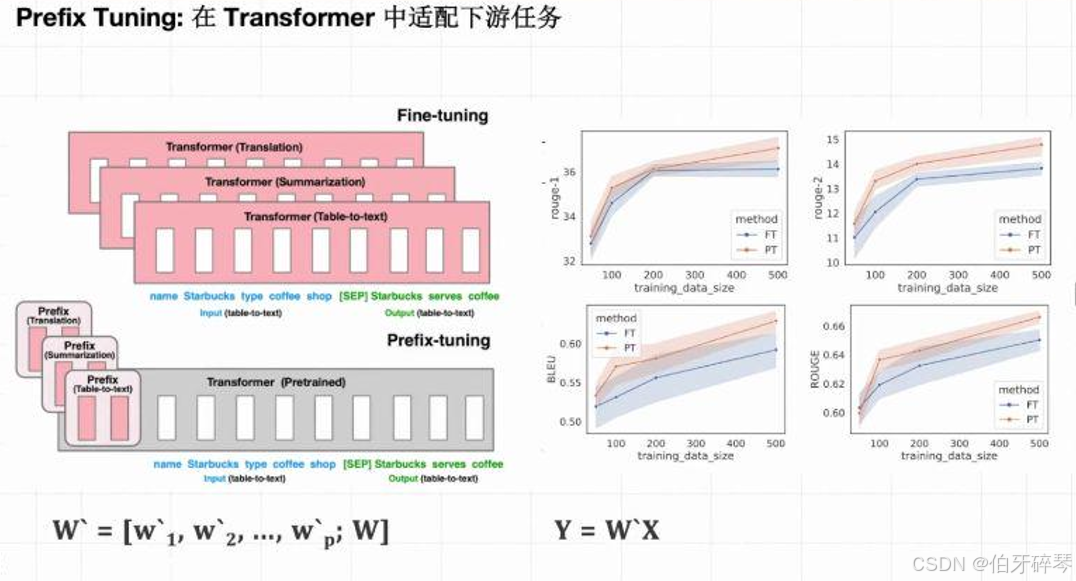
定义:
Prefix Tuning 是另一种基于Transformer架构的微调方法。它的原理是在输入序列的前面添加一组可训练的前缀(prefix),这些前缀会对模型的内部表示进行适配,从而帮助模型更好地执行特定任务。
特点:
- 前缀学习:通过在输入前加上训练得到的前缀,而不是改变模型内部的权重。
- 高效:相较于传统的微调方法,Prefix Tuning仅需训练较少的参数。
- 任务适配强:能够适配多个不同的任务,且在每个任务之间转换较为简便。
适用场景:
当你需要在多任务学习或者需要在多种任务之间快速切换时,Prefix Tuning 是一个非常有用的微调方法。它也适用于那些输入较长且复杂的任务,如文本摘要和翻译等。
3. LoRA:低秩适配方法
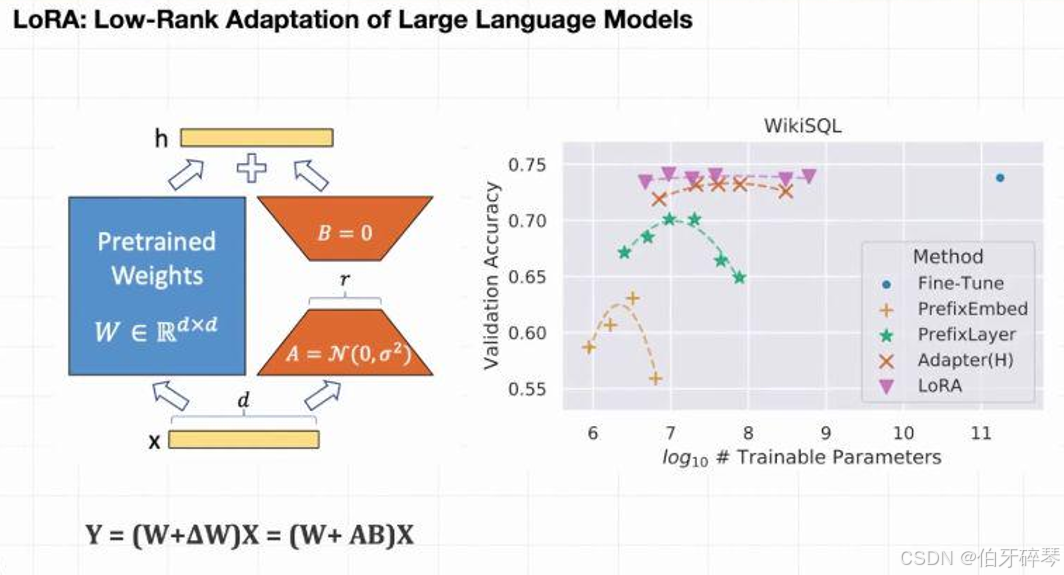
定义:
LoRA(Low-Rank Adaptation)是通过引入低秩矩阵来进行微调的技术。这种方法在大规模模型的训练中非常有效,通过在模型的参数矩阵上增加低秩矩阵,来减少计算和存储的开销,从而达到有效微调的目的。
特点:
- 低秩矩阵:LoRA通过将参数矩阵分解为低秩矩阵,只对少量参数进行训练,显著减少了计算和内存的开销。
- 高效:适用于大规模模型的微调,可以有效避免参数爆炸的计算瓶颈。
- 轻量:不需要对整个模型进行微调,适合需要高效微调的任务。
适用场景:
LoRA 在大规模预训练模型(如GPT、BERT等)的微调中非常有效,尤其在资源有限的情况下,能够提供有效的性能提升。适用于计算资源受限的高效微调场景。
4. QLoRA:量化版 LoRA
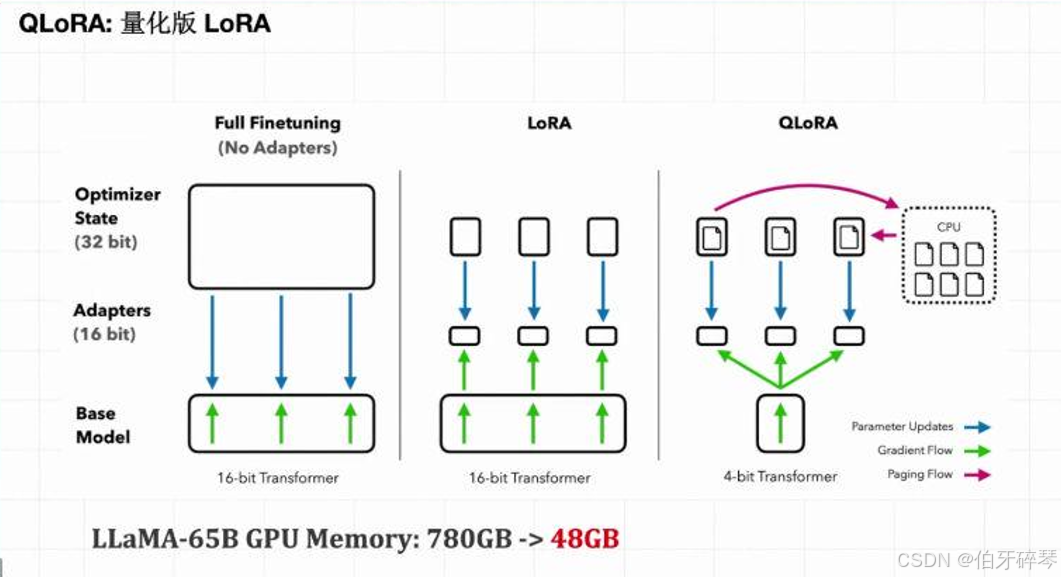
定义:
QLoRA 是在 LoRA 基础上结合量化技术的微调方法。量化是指将模型中的高精度(如浮点)权重转换为较低精度的表示(如整数或低精度浮点数)。通过量化,可以进一步减少内存占用和计算开销,提升微调效率。
特点:
- 低内存消耗:通过量化技术,减少了模型的内存消耗,使得在资源受限的设备上也能高效运行。
- 高效推理:量化后的模型通常能够在部署时提供更高效的推理性能。
- 结合 LoRA:既保留了 LoRA 的低秩适配优势,又引入了量化技术,进一步提升效率。
适用场景:
QLoRA 适用于需要在资源受限的硬件上进行微调和推理的场景,尤其是在移动设备、边缘设备或者嵌入式系统中运行大规模模型时。
5. AdaLoRA:自适应低秩分解
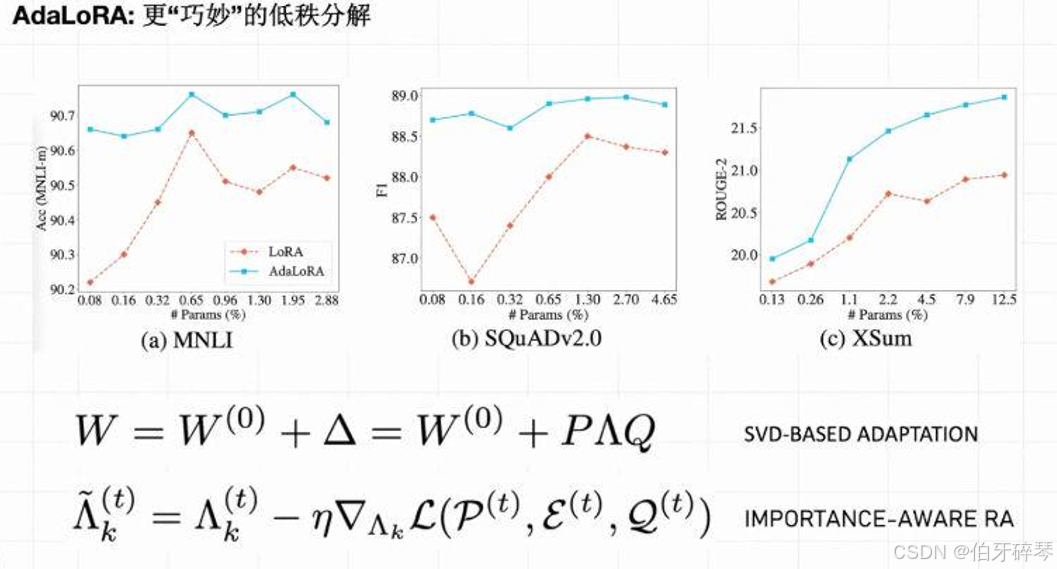
定义:
AdaLoRA 是 LoRA 的进一步扩展,它通过自适应调整低秩矩阵的维度来优化微调效果。在 AdaLoRA 中,模型会根据任务的不同自动选择不同的低秩矩阵的大小,从而在保证效率的同时,最大化微调效果。
特点:
- 自适应:通过动态调整低秩矩阵的大小,以适应不同的任务需求。
- 精细化优化:相比传统的 LoRA,AdaLoRA 能够提供更精细的微调控制。
- 灵活性强:能够根据每一层的具体需求进行调整,适应更多复杂的任务。
适用场景:
当需要在多个任务间迁移或者在非常复杂的任务中进行微调时,AdaLoRA 可以通过自适应的方式,提供更优的微调效果。
6. P Tuning:调整输入的嵌入
定义:
P Tuning 是一种通过调整模型输入的嵌入(embedding)来进行微调的技术。与传统的 prompt tuning 类似,P Tuning 并非直接调整输入的固定提示,而是学习特定任务的嵌入表示,从而优化模型的行为。
特点:
- 动态输入调整:通过学习任务相关的嵌入来动态调整模型的输出。
- 少量参数:仅训练嵌入参数,避免了对整个模型进行大量参数调整。
- 高效微调:相比传统微调方法,训练的参数量小,且计算开销较低。
适用场景:
P Tuning 适用于需要精细化控制输入并生成相应输出的任务,如文本生成、情感分析、命名实体识别等。
7. IA3 / UniPELT:输入感知注意力机制
定义:
IA3(Input-Aware Attention)和 UniPELT(Unified Prompt Embedding and Learning)是两种基于输入的微调方法。IA3 通过根据输入内容动态调整模型的注意力机制,使得模型能够更加自适应地处理不同类型的输入。UniPELT 则是通过一个统一的嵌入方式来引导模型学习任务特定的表示。
特点:
- 输入感知:能够根据输入内容自动调整模型的计算过程。
- 动态优化:通过感知输入的特征,调整注意力权重和模型的处理方式,从而提高任务的精度。
- 灵活性强:适应性较强,可以根据不同的输入类型动态进行调整。
适用场景:
适用于文本分类、信息抽取、实体识别等任务,特别是当输入类型多样,且任务具有一定复杂性时。
8. MoE(Mixture of Experts):专家模型的组合
定义:
MoE(Mixture of Experts)是一种通过多个专家模型组合来增强大模型能力的微调方法。模型通过选择性激活某些专家模型来处理特定的任务,从而在保证效率的同时提升模型的表达能力。
特点:
- 专家模型:通过多个子模型(专家)来解决不同任务,每次计算时只激活部分专家。
- 计算高效:减少了计算资源的浪费,通过选择性计算激活的专家模型来优化计算效率。
- 灵活性强:可以处理多任务,且能够根据任务的需求选择合适的专家。
适用场景:
MoE 特别适合处理多任务学习和大规模分类任务。它能够通过合理地选择专家模型来优化任务性能,且避免了对所有专家模型的计算。
9. RLHF / RLAIF:人类反馈与AI反馈的强化学习微调
定义:
RLHF(Reinforcement Learning with Human Feedback)是通过强化学习结合人类反馈来优化大模型的微调方式。人类通过反馈来评估模型的输出,模型则根据这些反馈进行自我优化。RLAIF(Reinforcement Learning with AI Feedback)则是通过AI代替人工来进行反馈,以进一步优化模型表现
。
特点:
- 人类反馈:通过直接或间接地引入人类评价,帮助模型调整其输出。
- 强化学习:结合强化学习的探索与利用策略,能够更有效地优化模型性能。
- 动态学习:模型在训练过程中能够根据反馈动态优化,提高生成效果。
适用场景:
RLHF 和 RLAIF 适合需要高度控制输出结果的任务,如对话生成、内容生成等任务,尤其适用于那些涉及用户交互和生成性任务的场景。
结语
随着大模型技术的发展,微调方法也在不断演进,从最基础的模型训练到如今的多种微调策略,每种方法都有其独特的优势。选择合适的微调方法,不仅能够提高模型的性能,还能在特定任务中获得更好的效果。在实际应用中,了解每种微调方法的特点和适用场景,能够帮助我们在复杂的任务中更好地选择和使用这些技术。
希望这篇文章能够帮助你更好地理解和应用大模型的微调技术。如果你对某种方法有更深入的兴趣或疑问,欢迎随时讨论!