了解模型压缩与加速
模型压缩与加速
关于模型压缩与加速,想着先看看相关的视频了解了解,看的是B站视频。链接:https://www.bilibili.com/video/BV1VV4y1y7yx/?spm_id_from=333.337.search-card.all.click&vd_source=1b96401f7b3794cd336ed9054c440553
卷积结构的类型
正常卷积(convolution)
如下图,一个正常的卷积操作如下图所示:
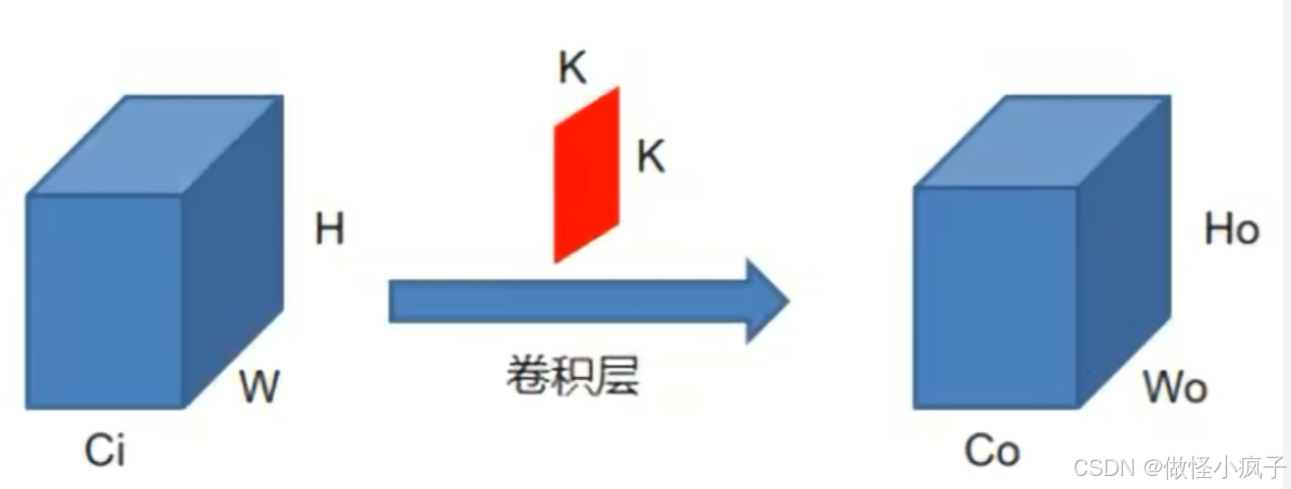
其中,输出的高和宽为:

参数量:
分组卷积(group convolution)
将输入的图像,按照通道数平均分成两组,分别进行卷积操作,就会得到两组feature map;
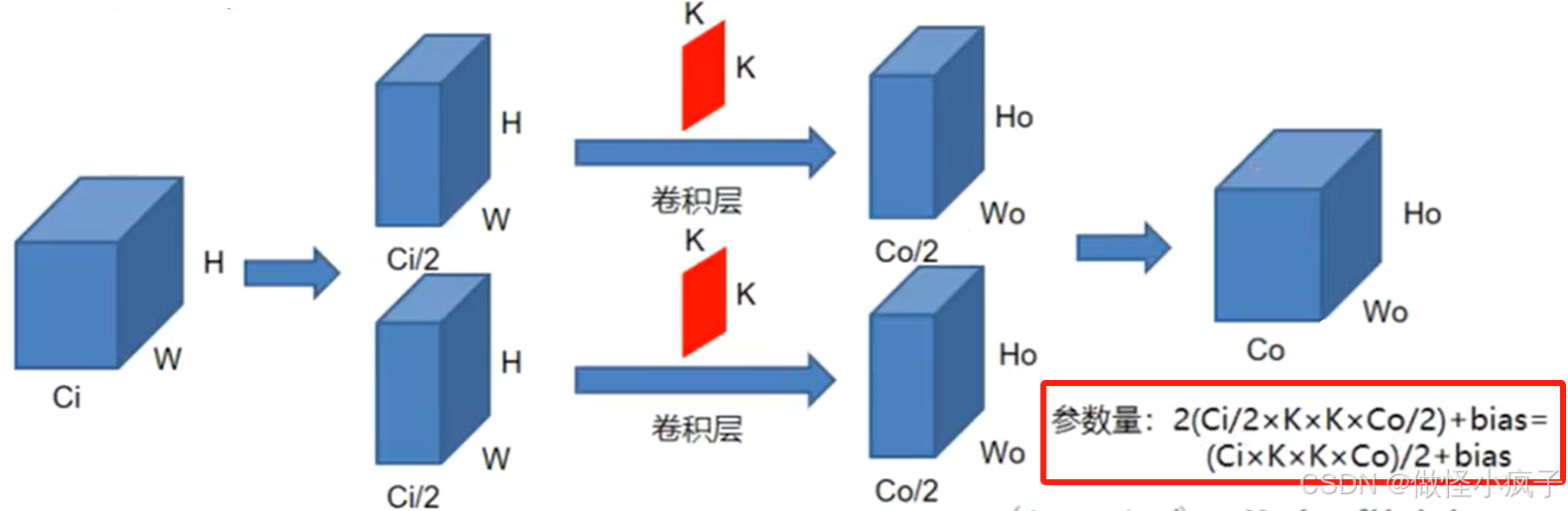
这样做可以减少参数量
深度卷积(Depthwise/ Channel-wise Convolution)
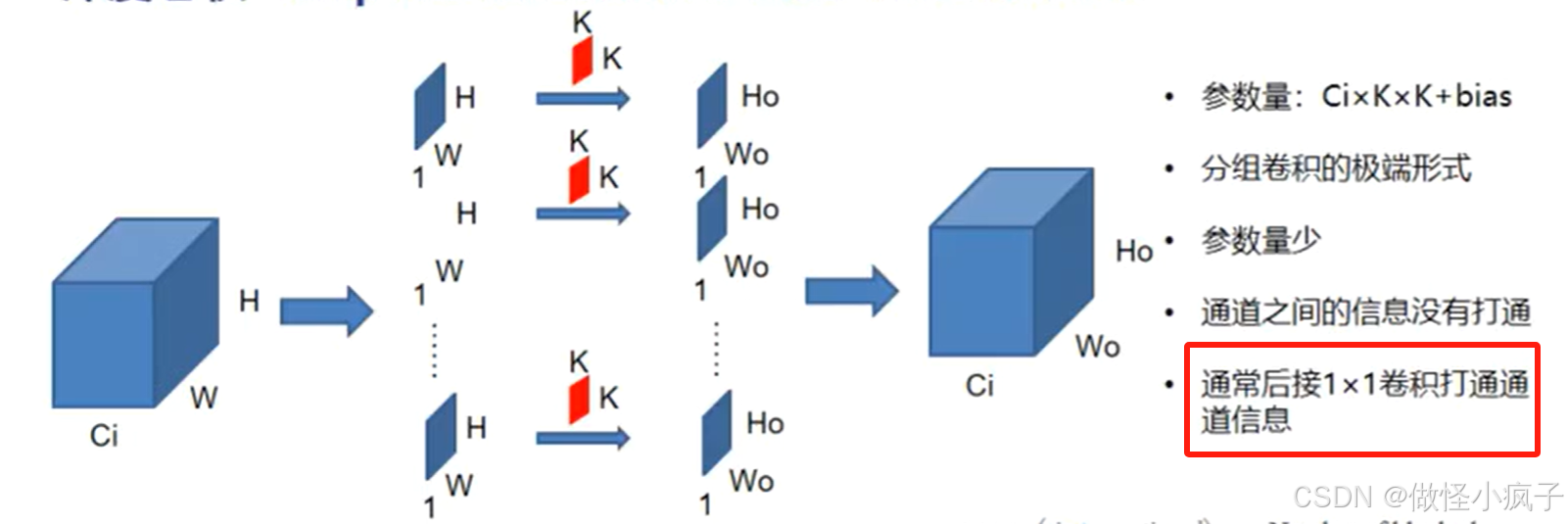
- 是分组卷积的极端形式,每个组只有一个通道;
- 由于每个通道独立卷积,通道之间的信息没有打通,这可能限制特征的融合。因此,通常会在深度可分离卷积后接一个 1 * 1 卷积,来实现不同通道间的信息交互和融合,提升模型的表达能力。
逐点卷积(Pointwise Convolution)
由于卷积核大小为 1 * 1 ,逐点卷积不提取空间信息,而是在通道维度上进行全连接操作,主要用于实现通道间的信息融合以及调整通道数量,比如可以将高通道数的特征图压缩,或者扩展低通道数的特征图 。

空洞卷积(Dilated Convolution)
一般是用在目标检测、分割任务里,参数量不变,但是却能够扩大感受野,从而能够提取多尺度的特征。
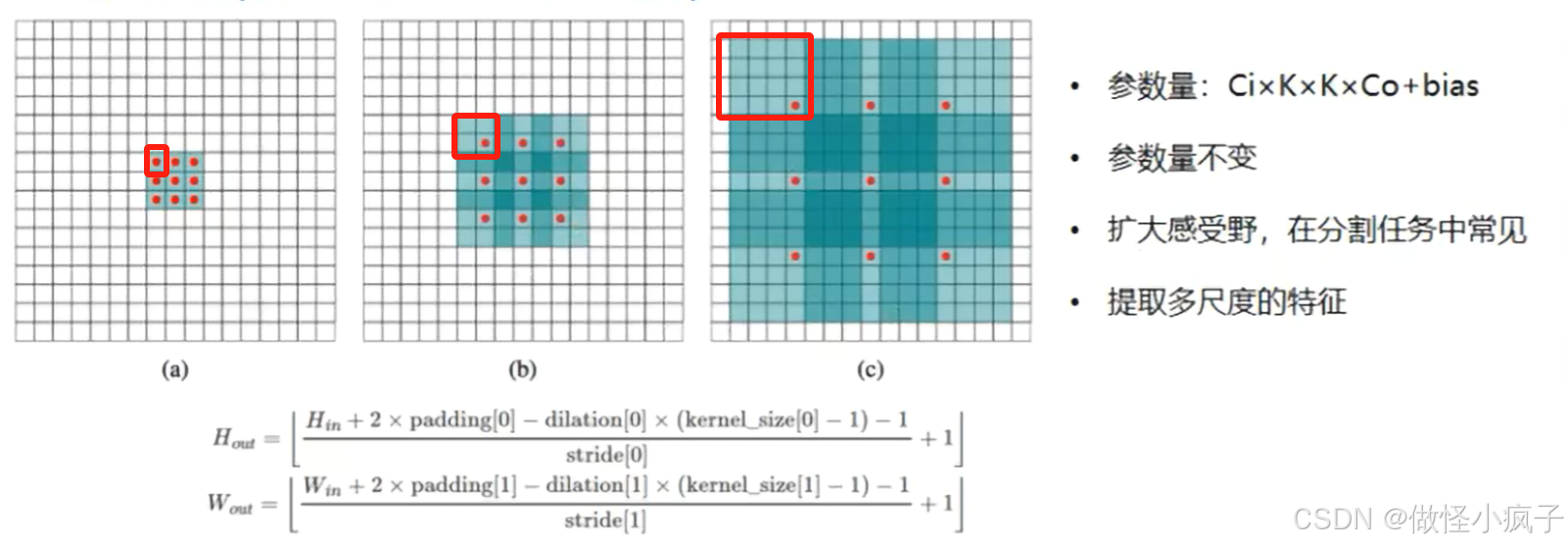
- 比如说有一个大小3 * 3的卷积核,绿色就代表卷积核的感受野,红色代表实际进行卷积操作的像素点。图A是正常卷积,默认空洞系数是1,B是空洞系数为2的卷积核,图C就是空洞系数为4。
- 可以看到图B里,虽然绿色范围很大,是7*7,但是红点还是9个,说明对于一个7x7的图像patch,只有9个红色的点和3x3的kernel发生卷积操作,其余的点略过。也可以理解为kernel的size为7x7,但是只有图中的9个点的权重不为0,其余都为0。
- 这样做的好处:扩大感受野的同时,不会像池化操作一样丢掉一些像素点的信息,还能降低图像的尺寸。
模型压缩和加速概述
深度学习的困境:模型太大,算力不足。
如何将大型的模型部署在移动设备、嵌入式设备?
基础理论:
- 必要性
- 在许多网络结构中,如VGG-16网络,参数数量1亿3千多万,占用500MB空间,需要进行309亿次浮点运算才能完成一次图像识别任务。
- 可行性
- 论文提出,其实在很多深度的神经网络中存在着显著的冗余。仅仅使用很少一部分(5%)权值就足以预测剩余的权值。该论文还提出这些剩下的权值甚至可以直接不用被学习。也就是说,仅仅训练一小部分原来的权值参数就有可能达到和原来网络相近甚至超过原来网络的性能(可以看作一种正则化)。
- 最终目的
- 最大程度的减小模型复杂度,减少模型存储需要的空间,也致力于加速模型的训练和推测
方法概述
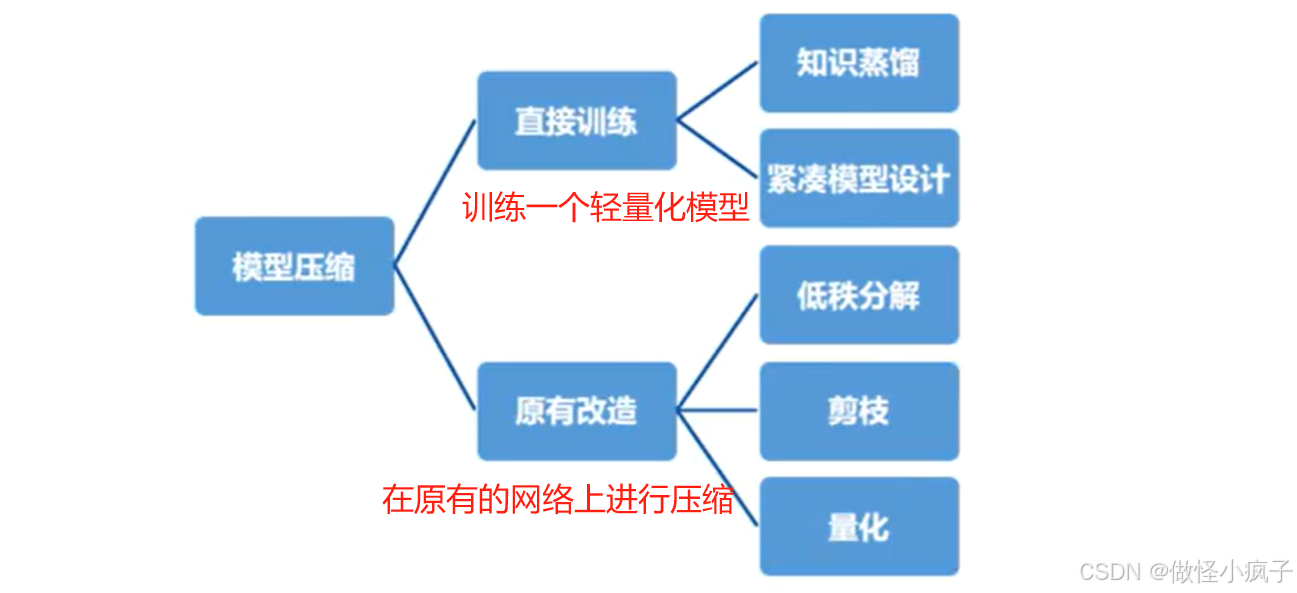
剪枝、量化比较多。
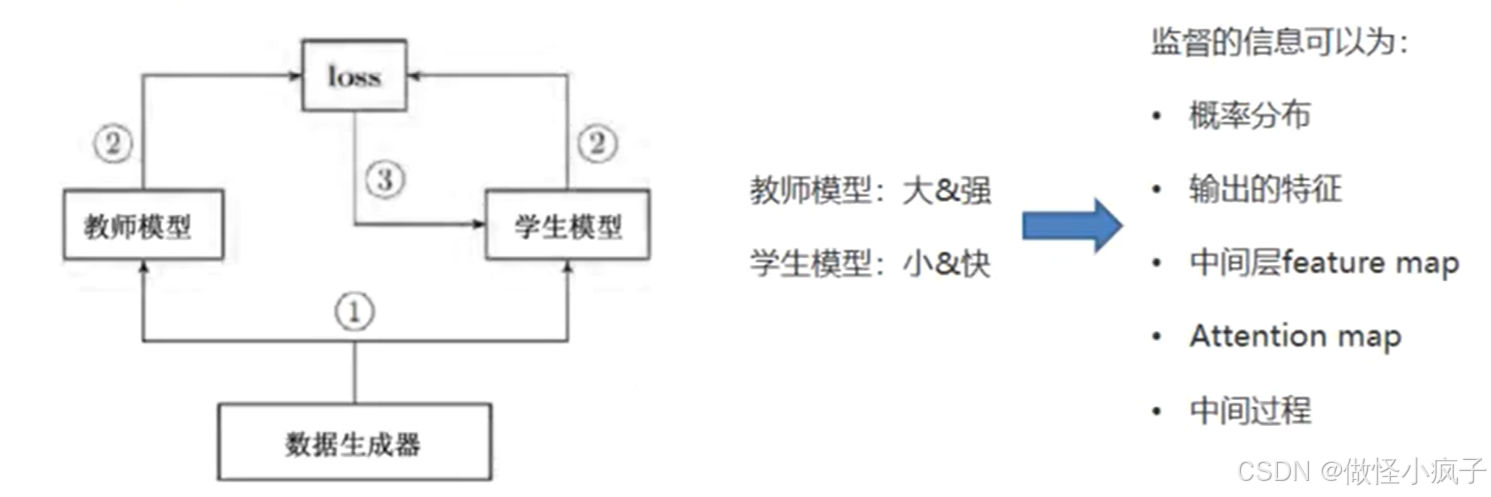
知识蒸馏(knowledge distillation)
其实就是迁移学习,通常要有一个预训练好的教师模型,取出要学习的相关信息指导学生模型训练。这个学生模型通常是自己定义好的、比较小的、轻量化网络。推理速度也会比教师模型快。
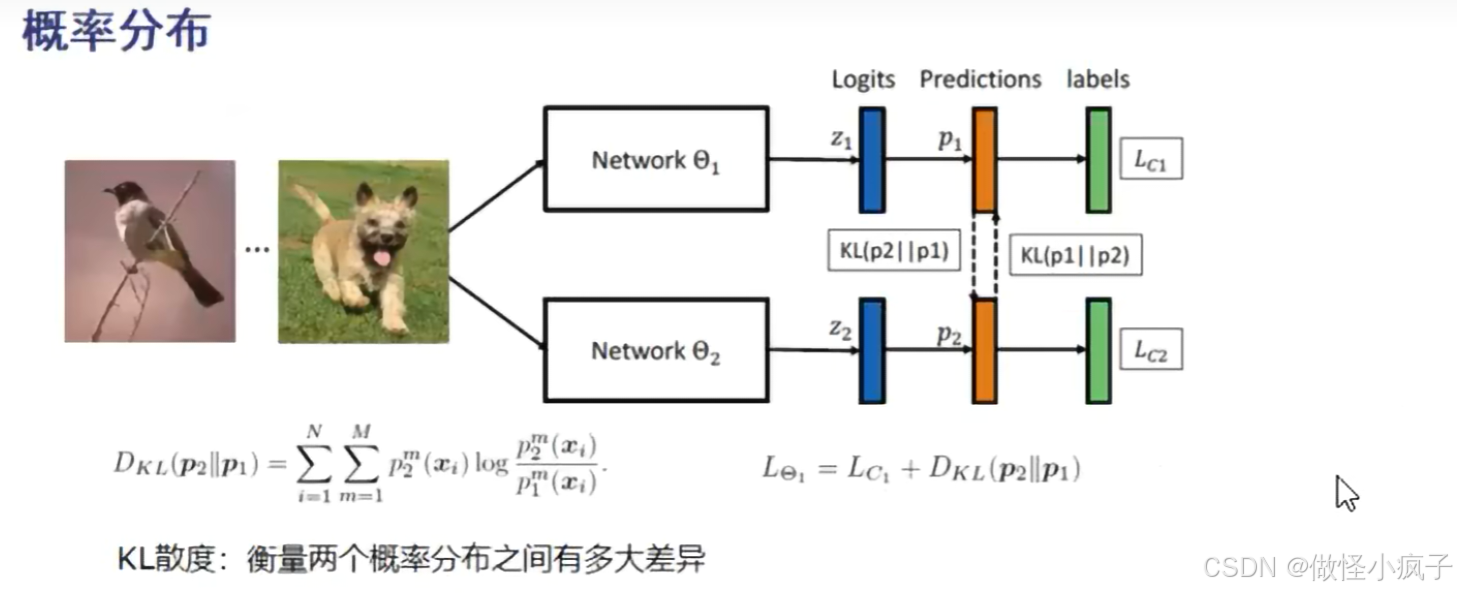
- 概率分布
使用KL散度来衡量两个概率分布之间的差异
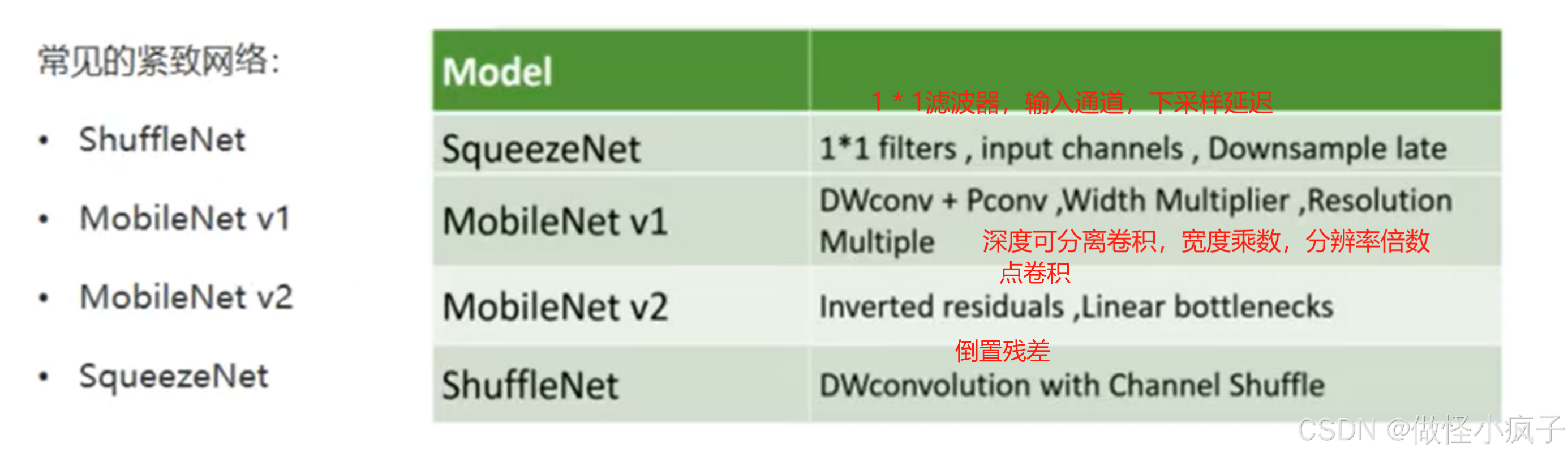
紧致的网络结构设计
-
SqueezeNet
-
该模型设计不仅是为了得到最佳的CNN精度,而是希望在简化网络复杂度的同时保证网络模型的识别精度。
-
主要使用以下三个方式简化网络复杂度
- 将3 * 3卷积核替换为1 * 1卷积核。(为了不影响精度,只做了部分替换)
- 减少输入3x3卷积的输入特征数量。将卷积层分解为squeeze层以及expand层,并封装为一个Fire Module。
- 在网络后期使用下采样,使得卷积层有较大的activation maps
-
Fire Module结构如下图所示:
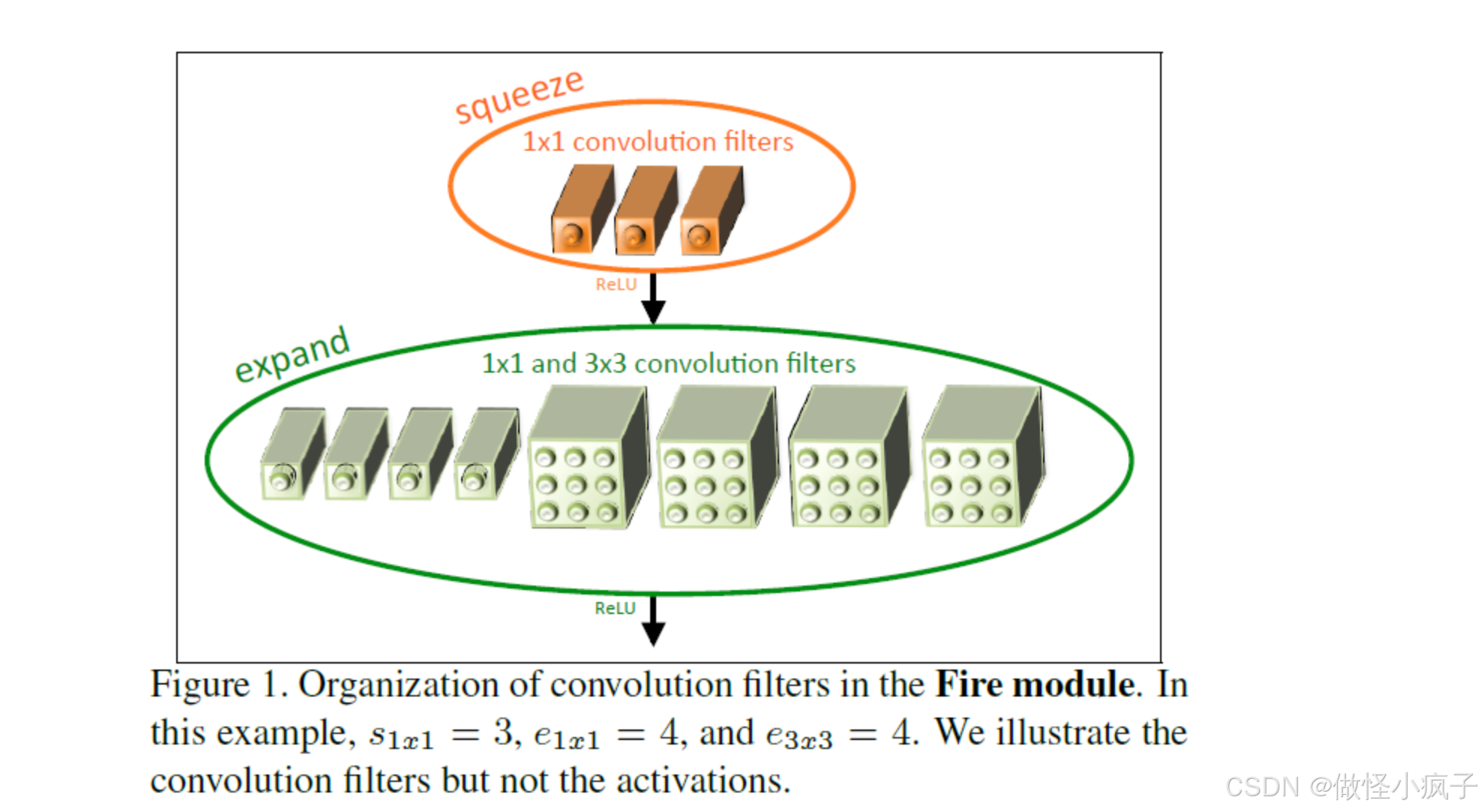
该模块的思想:将一个卷积层分解为一个Squeeze层和一个expand层,并各自带上Relu激活层。squeeze层包含全部都是1x1的卷积核,共有S个。expand层包含E1个 1x1核 和E3个3x3的卷积核,要求满足S<(E1+E3)。 -
网络结构:
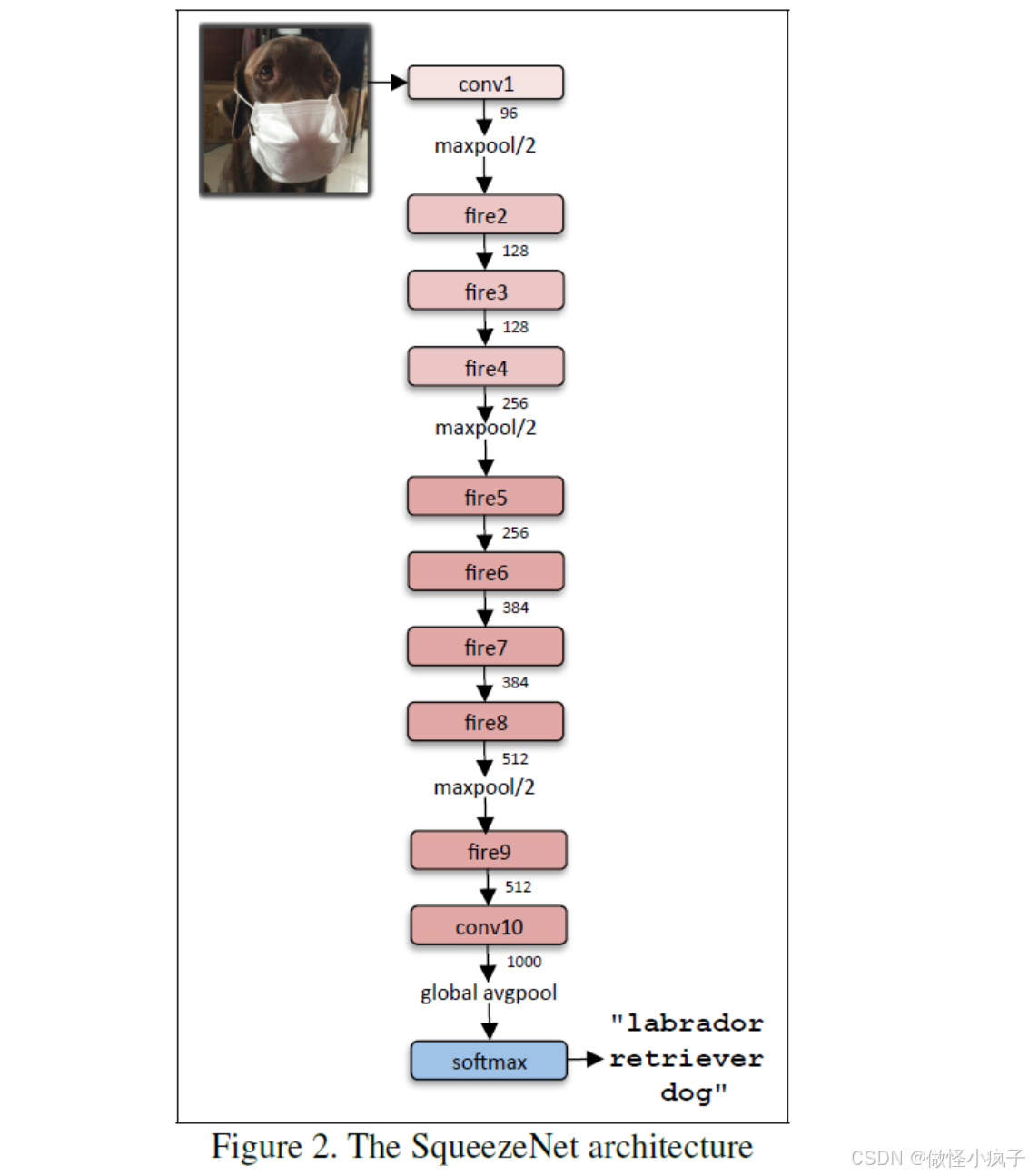
共有九层Fire Module。中间穿插了三个MAX pooling层,最后一层用Average Pooling层替换全连接层是的参数大量减少。最上层和下层各保留了一个卷积层,这样做的目的是保证输入输出的大小可掌握。 -
特点:
- SqueezeNet比AlexNet的参数减少的50倍,模型大小只有4.8M,在性能好的FPGA上可以运行起来,并且能带来与AlexNet相当的识别精度。
- 证明了小的神经网络也能达到很好的识别精度
-
-
MobileNet V1
之前有写过笔记,这里就不赘述了。 -
MobileNet V2
与MobileNet V1的区别:
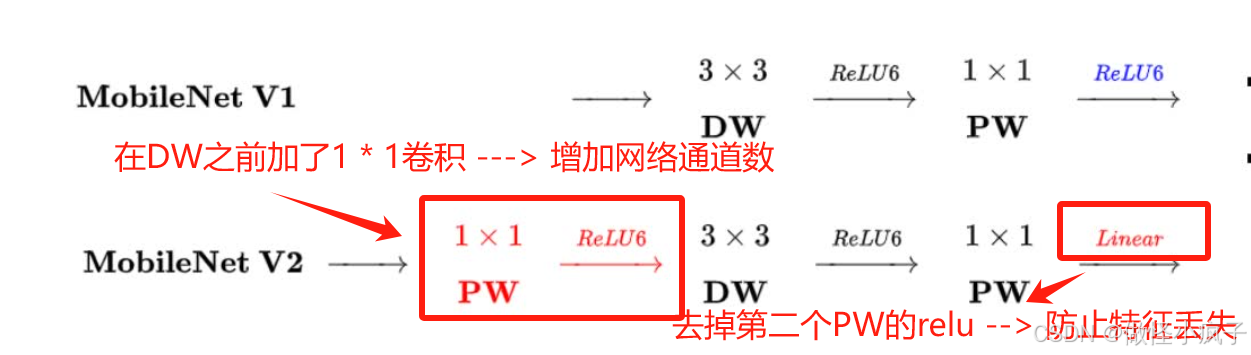
- V2增加了ResNet的shortcut结构
- 通过改变网络的参数设置,V2比V1进一步压缩了约50%,并且泛化能力提升。
-
ShuffleNet
-
ShuffleNet使用**通道打乱(通道洗牌,Channel Shuffle)**操作来代替1x1卷积,实现通道信息的融合。
-
Shuffle操作通过Reshape、 Permute操作实现,不包含参数。
-
如下图,图a是分组卷积,图b是Channel Shuffle 的分组卷积。
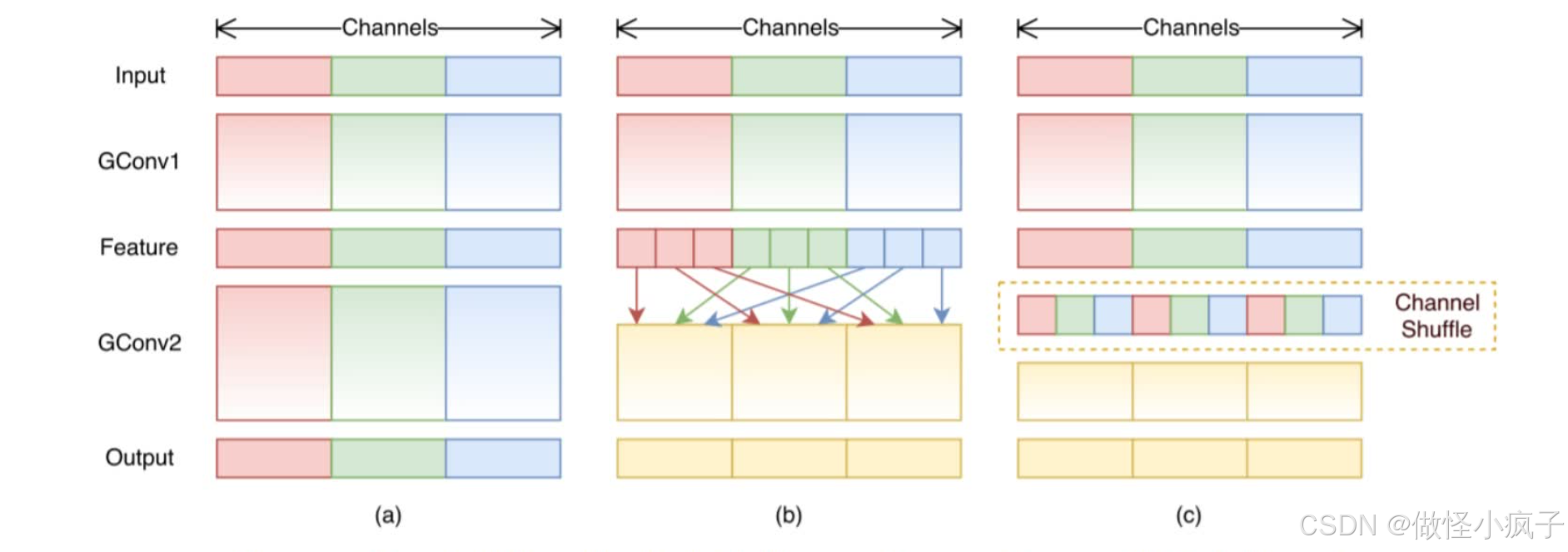
-
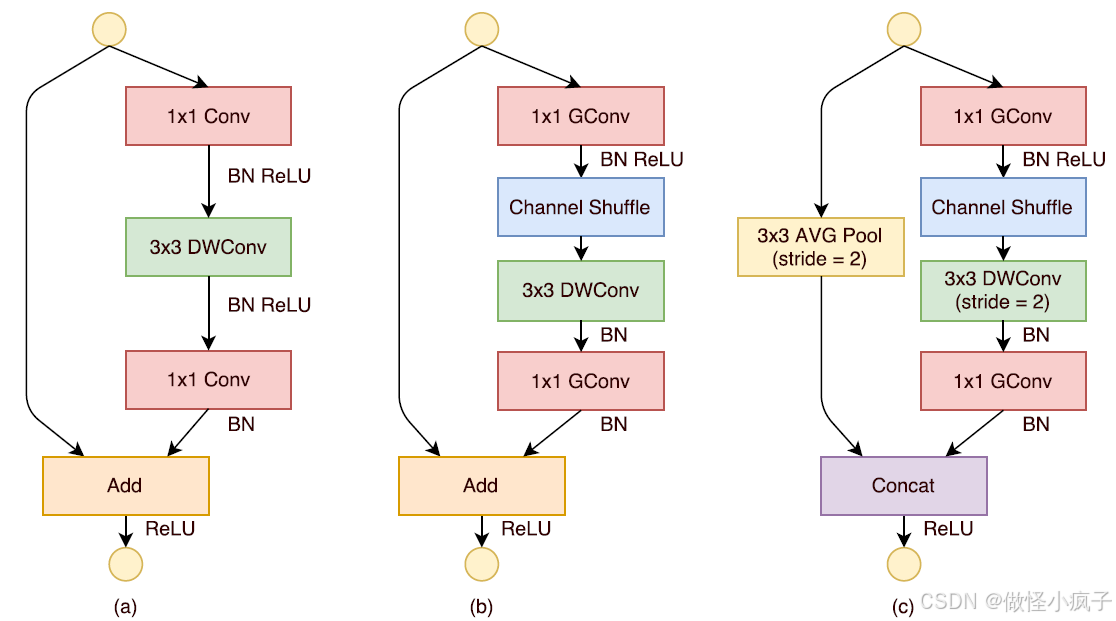
ShuffleNet Unit
- 基于残差块(residual block)和通道洗牌(channel shuffle)设计
- 如下图a所示,这是一个包含3层的残差单元:首先是1x1卷积,然后是3x3的depthwise convolution(DWConv,主要是为了降低计算量),这里的3x3卷积是瓶颈层(bottleneck),紧接着是1x1卷积,最后是一个短路连接,将输入直接加到输出上。
- 现在进行如下改进:将密集的1x1卷积替换成1x1的group convolution,不过在第一个1x1卷积之后增加了一个channel shuffle操作。值得注意的是3x3卷积后面没有增加channel shuffle,按paper的意思,对于这样一个残差单元,一个channel shuffle操作是足够了。还有就是3x3的depthwise convolution之后没有使用ReLU激活函数。
- 改进之后如图(b)所示。对于残差单元,如果stride=1时,此时输入与输出shape一致可以直接相加,而当stride=2时,通道数增加,而特征图大小减小,此时输入与输出不匹配。一般情况下可以采用一个1x1卷积将输入映射成和输出一样的shape。但是在ShuffleNet中,却采用了不一样的策略,
- 如图(c)所示:对原输入采用stride=2的3x3 avg pool,这样得到和输出一样大小的特征图,然后将得到特征图与输出进行连接(concat),而不是相加。这样做的目的主要是降低计算量与参数大小。
-
低秩分解
一个典型的CNN卷积核是一个 4D 张量我们知道会存在大量的冗余。而卷积计算本质上是矩阵分析的问题通过一些矩阵分析方法可以有效减少矩阵运算的计算量。比如说SVD奇异值分解、CP分解等等。
- 卷积分解
- 比如:将dxd卷积核分解为dx1和1xd卷积核。
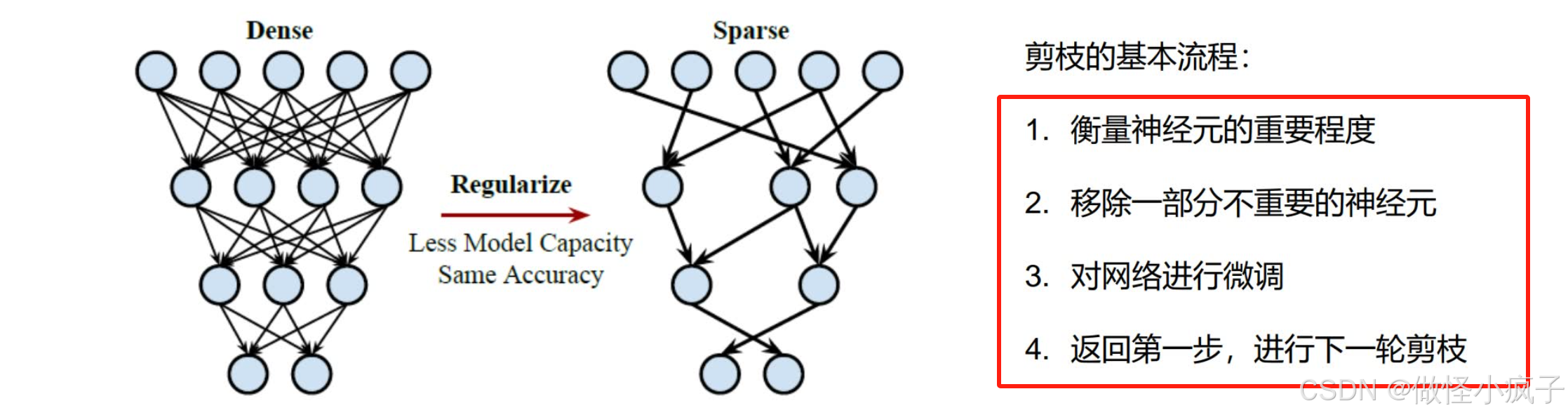
剪枝(Pruning)
网络训练完成后,裁剪掉贡献信息量不大的网络参数。如果权值越少,就认为经过激活之后所产生的影响几乎可以忽略不计。去除权重比较小的连接,使得网络稀疏。
-
剪枝基本流程:
-
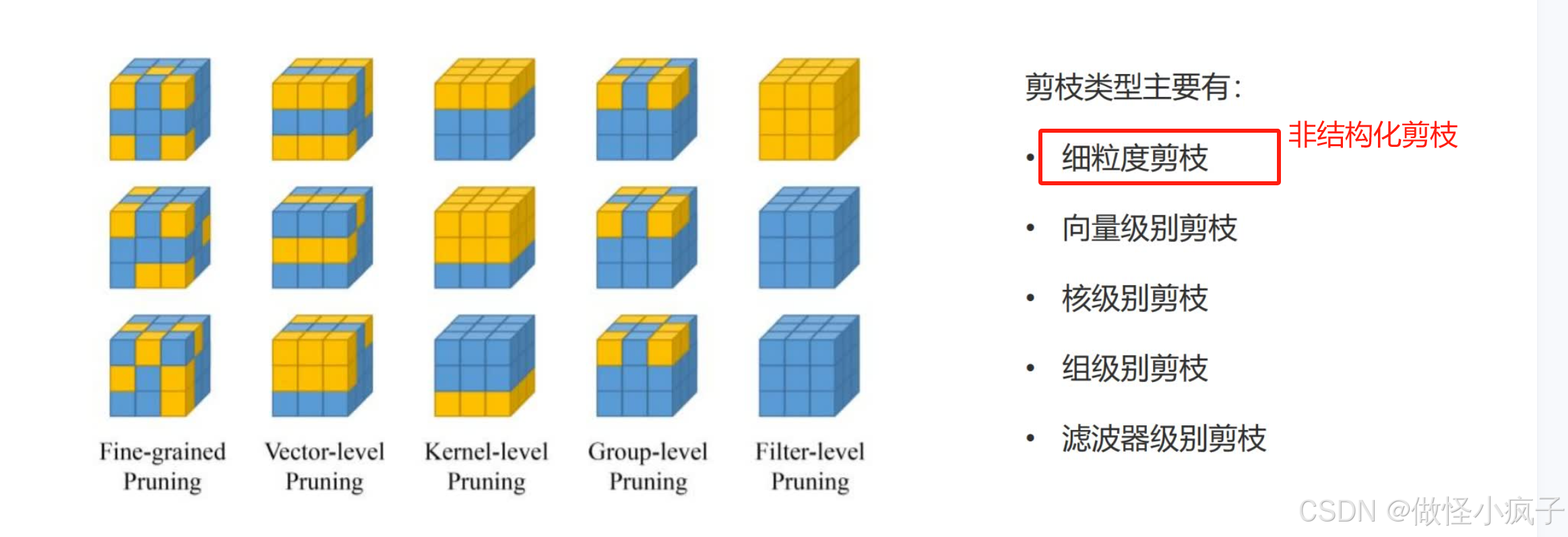
主要类型:
-
方法分类:
- 权重衰减法
- 通过在网络目标函数中引入表示结构复性的正则化项来使训练的网络权重趋向稀疏缺点是正则化参数/权重剪枝阈值对剪枝结果影响很大化。
- 灵敏度量化法
- 通过设计一个灵敏度评价指标,衡量网各节点对于网络误差的贡献(灵敏度),删除那些贡献不大的节点。
- 根据相关性剪枝
- 根据网络节点间的相关性或者相互作用进行剪枝,然后合并相关性较大的节点。类似于PCA一样,去除网络中信息几余的网络节点。
- 权重衰减法
-
其他方法:
- 梯度剪枝:保持神经节点的top-k梯度,并修剪其余的梯度。由于一些神经节点的梯度为零,可以加速反向传播。
- 通过设计一个尺度因子,实现滤channel维度上的剪枝
量化
一般而言,神经网络模型的参数都是用的32bit长度的浮点型数表示,实际上不需要保留那么高的精度,可以通过量化,比如用0~255表示原来32个bit所表示的精度,通过牺牲精度来降低每一个权值所需要占用的空间。
此外,SGD(Stochastic Gradient Descent)所需要的精度仅为6~8bit,因此合理的量化网络也可保证精度的情况下减小模型的存储体积。
- 二值量化(+1,-1)
- 三值量化(+1,-1,0)
- 多值量化(8bit,16bit等)
量化的对象有
- 网络权重
- 网络特征
- 网络梯度
方法总结
| 方法名称 | 描述 | 应用场景 | 方法细节 |
|---|---|---|---|
| 低秩分解 | 使用矩阵对参数进行分解估计 | 卷积层和全连接层 | 标准化的途径,很容易实施,支持从零训练和预训练 |
| 剪枝 | 删除对准确率影响不大的参数 | 卷积层和全连接层 | 对不同设置具有鲁棒性,可以达到较好效果,支持从零训练和预训练 |
| 量化 | 减少表示每个权重所需的比特数来压缩原始网络 | 卷积层和全连接层 | 多依赖于二进制编码方式,适合在FPGA、单片机等平台上部署 |
| 知识蒸馏 | 训练一个更紧凑的神经网络来从大的模型蒸馏知识 | 卷积层和全连接层 | 模型表现对应用程序和网络结构较为敏感,只能从零开始训练 |
| 转移、紧凑卷积核 | 设计特别的卷积核来保存参数 | 只有卷积层 | 算法依赖于应用程序,通常可以取得好的表现,只能从零开始训练 |
模型压缩和加速的参考内容
这个课可能有点久了,先做个了解吧,这是最近师兄给发的,感觉可以看看。
https://github.com/HuangOwen/Awesome-LLM-Compression