第四章 哈希表
第四章 哈希表
参考文章:https://www.hello-algo.com/
1、哈希表(Hash Table)
1. 哈希表的基本概念
- 定义:哈希表(也称散列表)是一种通过键值对(key-value pair)存储数据的数据结构,能够实现高效的元素查询。
- 核心思想:通过哈希函数将键(key)映射到一个较小范围的索引(桶,bucket),从而快速定位到存储值(value)的位置。
- 时间复杂度:
- 查询操作:平均时间复杂度为 O(1)
- 添加操作:平均时间复杂度为 O(1)
- 删除操作:平均时间复杂度为 O(1)
2. 哈希表的常用操作
- 初始化:创建一个空的哈希表。
- 添加键值对:将一个键值对(key, value)插入哈希表中。
- 查询操作:通过键(key)快速获取对应的值(value)。
- 删除键值对:通过键(key)从哈希表中删除对应的键值对。
- 遍历操作:
- 遍历键值对(key-value pairs)
- 遍历键(keys)
- 遍历值(values)
3. 哈希表的实现原理
- 哈希函数:
- 作用:将键(key)映射到一个较小范围的索引(桶)。
- 计算过程:
- 使用哈希算法(如
hash(key))计算哈希值。 - 对哈希值取模(
hash(key) % capacity),得到数组索引。
- 使用哈希算法(如
- 冲突解决:
- 当两个不同的键映射到同一个索引时,会发生冲突。
- 常见解决方法:
- 链地址法(Separate Chaining):每个桶存储一个链表,冲突的键值对存储在链表中。
- 开放地址法(Open Addressing):寻找下一个空闲位置存储冲突的键值对。
4. 哈希表的简单实现
基于数组的实现:
-
使用一个固定大小的数组(桶数组)来存储键值对。
-
哈希函数计算键的存储位置。
-
示例代码(Java):
package com.liucc.linkedlist.chapter_hashing; import java.util.ArrayList; import java.util.List; /** * 键值对 */ class Pair { public int key; public String val; public Pair(int key, String val) { this.key = key; this.val = val; } } /** * 基于数组实现的Map */ class ArrayHashMap { private List<Pair> buckets; // 构造器初始化 public ArrayHashMap() { buckets = new ArrayList<>(); for (int i = 0; i < 100; i++) { buckets.add(null); } } // 哈希函数 public int hashing(int key) { return key % 100; } // 查询操作 public String get(int key) { int index = hashing(key); Pair pair = buckets.get(index); return pair == null ? null : pair.val; } // 添加/修改操作 public void put(int key, String val){ Pair pair = new Pair(key, val); int index = hashing(key); buckets.set(index, pair); } // 删除操作 public void remove(int key){ int index = hashing(key); buckets.set(index, null); } // 获取所有键值对 public List<Pair> pairSet(){ List<Pair> resuList = new ArrayList<>(); buckets.forEach(item -> { if (item != null) { resuList.add(item); } }); return resuList; } // 获取所有key public List<Integer> keySet(){ List<Integer> resultList = new ArrayList<>(); for (Pair pair : buckets) { if (pair != null) { resultList.add(pair.key); } } return resultList; } // 获取所有value public List<String> valus(){ List<String> resultList = new ArrayList<>(); for (Pair pair : buckets) { if (pair != null) { resultList.add(pair.val); } } return resultList; } // 打印 public void print() { for (Pair kv : pairSet()) { System.out.println(kv.key + " -> " + kv.val); } } } public class array_hash_map { public static void main(String[] args) { /* 初始化哈希表 */ ArrayHashMap map = new ArrayHashMap(); /* 添加操作 */ // 在哈希表中添加键值对 (key, value) map.put(12836, "小哈"); map.put(15937, "小啰"); map.put(16750, "小算"); map.put(13276, "小法"); map.put(10583, "小鸭"); System.out.println("\n添加完成后,哈希表为\nKey -> Value"); map.print(); /* 查询操作 */ // 向哈希表中输入键 key ,得到值 value String name = map.get(15937); System.out.println("\n输入学号 15937 ,查询到姓名 " + name); /* 删除操作 */ // 在哈希表中删除键值对 (key, value) map.remove(10583); System.out.println("\n删除 10583 后,哈希表为\nKey -> Value"); map.print(); /* 遍历哈希表 */ System.out.println("\n遍历键值对 Key->Value"); for (Pair kv : map.pairSet()) { System.out.println(kv.key + " -> " + kv.val); } System.out.println("\n单独遍历键 Key"); for (int key : map.keySet()) { System.out.println(key); } System.out.println("\n单独遍历值 Value"); for (String val : map.valus()) { System.out.println(val); } } }
5. 哈希表的优缺点
- 优点:
- 查询、插入、删除操作的平均时间复杂度为 O(1),效率极高。
- 实现简单,易于使用。
- 缺点:
- 哈希冲突可能导致性能下降,尤其是在大量数据时。
- 需要额外的空间来存储哈希表,空间利用率可能较低。
6. 哈希表的应用场景
- 快速查找:如字典、缓存、符号表等。
- 去重操作:通过哈希表快速判断元素是否存在。
- 关联数据:如数据库中的索引、用户信息存储等。
7. 哈希表与其他数据结构的对比
| 数据结构 | 查询时间复杂度 | 插入时间复杂度 | 删除时间复杂度 | 空间利用率 | 有序性 |
|---|---|---|---|---|---|
| 哈希表 | O(1) | O(1) | O(1) | 中等 | 无序 |
| 数组 | O(n) | O(n) | O(n) | 高 | 有序 |
| 链表 | O(n) | O(1) | O(1) | 中等 | 有序 |
| 二叉搜索树 | O(log n) | O(log n) | O(log n) | 高 | 有序 |
这个表格清晰地展示了哈希表相比其他常见数据结构在时间复杂度上的优势,特别是在查询操作方面。不过每种数据结构都有其适用场景,选择时需要根据具体需求来权衡。
2、哈希冲突
1. 哈希冲突的不可避免性
从以上可以看出,数据存储在 map 中的位置取决于key 的哈希值,而我们的哈希算法是key % capacity,因此很容易发生冲突。
如以下示例中,两个 key 计算出来的索引位置就会冲突。造成可能的情况就是两个学号指向的是同一个学生,这肯定是不合实际情况的。
12836 % 100 = 36
20336 % 100 = 36
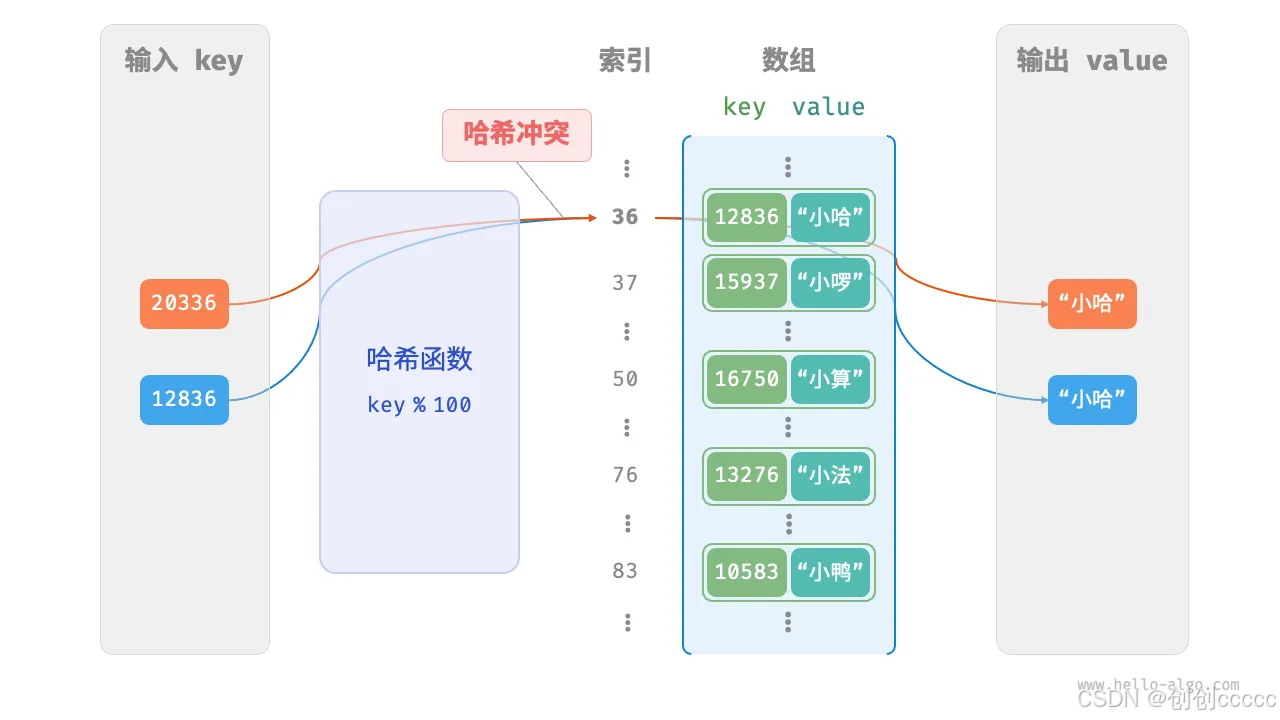
一种简单的解决办法就是对数组进行扩容,从而减少发生冲突的概率。如:
12836 % 200 = 36
20336 % 100 = 136
类似于数组扩容,哈希表扩容需将所有键值对从原哈希表迁移至新哈希表,非常耗时;并且由于哈希表容量 capacity 改变,我们需要通过哈希函数来重新计算所有键值对的存储位置,这进一步增加了扩容过程的计算开销。为此,编程语言通常会预留足够大的哈希表容量,防止频繁扩容。
负载因子(load factor)是哈希表的一个重要概念,其定义为哈希表的元素数量除以桶数量,用于衡量哈希冲突的严重程度,也常作为哈希表扩容的触发条件。例如在 Java 中,当负载因子超过 0.75 时,系统会将哈希表扩容至原先的 2 倍。
- 背景:哈希表是一种通过哈希函数将键映射到数组(桶)中的数据结构,用于快速存储和查找键值对。
- 冲突原因:哈希函数的输入空间(如全体整数)通常远大于输出空间(如哈希表的容量),因此多个键可能被映射到同一个桶索引,这种现象称为哈希冲突。
- 冲突影响:哈希冲突可能导致查询结果错误,严重影响哈希表的可用性。
2. 解决哈希冲突的策略
为了解决哈希冲突,可以采用以下两种主要策略:
- 改良哈希表结构:使哈希表在发生冲突时仍能正常工作。
- 扩容操作:仅在冲突严重时才执行扩容,以减少数据搬运和哈希值计算的开销。
3. 链式地址(Separate Chaining)
-
核心思想:将哈希表中的每个桶从单个元素扩展为链表,所有映射到同一桶索引的键值对都存储在同一个链表中。
-
操作方法:
- 查询:通过哈希函数找到桶索引,然后遍历链表查找目标键值对。
- 添加:将键值对添加到链表中。
- 删除:从链表中删除目标键值对。
-
优点:结构简单,易于实现。
-
缺点:
- 占用更多内存(链表包含指针)。
- 查询效率降低(需要线性遍历链表)。
-
示例代码(这里以动态数组代替链表进行简单实现,负载因子达到 2/3 时触发扩容)
package com.liucc.linkedlist.chapter_hashing; import java.util.ArrayList; import java.util.List; // 链式地址哈希表 // 这里使用列表(动态数组)代替链表进行简单实现 class HashMapChaining { int size; // 键值对数量 int capacity; // 哈希表容量 double loadThreas; // 触发扩容的负载因子 int extendRatio; // 扩容倍数 List<List<Pair>> buckets; // 桶数组 // 构造器 public HashMapChaining() { capacity = 4; // 初始容量 loadThreas = 2.0 / 3.0; // 扩容阈值 extendRatio = 2; // 扩容2倍 buckets = new ArrayList<>(capacity); for (int i = 0; i < capacity; i++) { buckets.add(new ArrayList<>()); } } // 哈希函数 public int hashFunc(int key) { return key % capacity; } // 负载因子 public double loadFactor() { return (double) size / capacity; } // 查询 public String get(int key){ int index = hashFunc(key); List<Pair> pairs = buckets.get(index); for (Pair pair : pairs) { if (pair.key == key) { return pair.val; } } return null; // 没有找到就返回null } // 新增/更新 public void put(int key, String val){ // 当负载因子达到阈值,进行扩容 if (loadFactor() >= loadThreas) { // TODO 扩容 } int index = hashFunc(key); List<Pair> pairs = buckets.get(index); for (Pair pair : pairs) { if (pair.key == key) { // buckets中已存在指定key,走更新 pair.val = val; return; } } // 走新增 pairs.add(new Pair(key, val)); size++; return; } // 删除 public void remove(int key){ int index = hashFunc(key); List<Pair> pairs= buckets.get(index); for (Pair pair : pairs) { if (pair.key == key) { pairs.remove(pair); size--; break; } } } // 扩容 public void extend(){ // 备份原始buckets List<List<Pair>> bucketsTmp = buckets; // 对buckets进行扩容 capacity = capacity * extendRatio; buckets = new ArrayList<>(capacity); // 将已有paris拷贝到buckets size = 0; // 重置size for (List<Pair> pairs : bucketsTmp) { for (Pair pair : pairs) { put(pair.key, pair.val); } } } // 打印 void print() { for (List<Pair> bucket : buckets) { List<String> res = new ArrayList<>(); for (Pair pair : bucket) { res.add(pair.key + " -> " + pair.val); } System.out.println(res); } } } public class hash_map_chaining { public static void main(String[] args) { /* 初始化哈希表 */ HashMapChaining map = new HashMapChaining(); /* 添加操作 */ // 在哈希表中添加键值对 (key, value) map.put(12836, "小哈"); map.put(15937, "小啰"); map.put(16750, "小算"); map.put(13276, "小法"); map.put(10583, "小鸭"); System.out.println("\n添加完成后,哈希表为\nKey -> Value"); map.print(); /* 查询操作 */ // 向哈希表中输入键 key ,得到值 value String name = map.get(13276); System.out.println("\n输入学号 13276 ,查询到姓名 " + name); /* 删除操作 */ // 在哈希表中删除键值对 (key, value) map.remove(12836); System.out.println("\n删除 12836 后,哈希表为\nKey -> Value"); map.print(); } }
值得注意的是,当链表很长时,查询效率很差(线性阶)。此时可以将链表转换为“AVL 树”或“红黑树”,从而将查询操作的时间复杂度优化至对数阶。
4. 开放寻址(Open Addressing)
开放寻址是一种解决哈希冲突的策略,当发生冲突时,会在哈希表中寻找下一个可用的空位来存储键值对。开放寻址的实现方法包括:
- 线性探测(Linear Probing):当发生冲突时,依次检查后续的桶,直到找到空位。
- 平方探测(Quadratic Probing):当发生冲突时,按照平方序列(如1², 2², 3²…)来寻找空位。
- 多次哈希(Double Hashing):使用第二个哈希函数来确定探测序列。
5. 总结
- 哈希冲突是哈希表设计中不可避免的问题,但可以通过链式地址或开放寻址等方法解决。
- 链式地址通过将冲突的键值对存储在链表中,简单易实现,但可能会增加内存占用和查询时间。
- 开放寻址通过在哈希表中寻找下一个空位来解决冲突,适合内存有限的场景。
- 不同的编程语言提供了不同的数据结构和工具来实现哈希表,开发者可以根据具体需求选择合适的方法。