自然语言处理 基于神经网络的词向量转化模型word2vec
目录
一.词向量转换的方法
二.one-hot编码
1.怎么对语料库中的每个字进行one-hot编码
2.one-hot编码的缺点
三.解决one-hot编码的维度灾难问题
1.如何解决维度灾难问题
2.什么是词嵌入
3.高效训练词向量的模型
4.word2vec模型原理
模型的训练过程:
模型结构:
一.词向量转换的方法
①基于统计的语言模型
②神经网络语言模型
统计语言模型存在的问题:
由于参数空间的爆炸式增长,它无法处理(N>3)的数据。
没有考虑词与词之间内在的联系性。例如,考虑"the cat is walking in the bedroom"这句话。如果我们在训练语料中看到了很多类似“the dog is walking in the bedroom”或是“the cat is running in the bedroom”这样的句子;那么,哪怕我们此前没有见过这句话"the cat is walking in the bedroom",也可以从“cat”和“dog”(“walking”和“running”)之间的相似性,推测出这句话的概率。
所以接下来我们介绍基于神经网络的词向量转化
二.one-hot编码
在处理自然语言时,通常将词语或者字做向量化,例如one-hot编码,例如我们有一句话为:“我爱北京天安门”,我们分词后对其进行one-hot编码,结果可以是:
“我”:[1,0,0,0] “爱”: [0,1,0,0] “北京”: [0,0,1,0] “天安门”: [0,0,0,1]
1.怎么对语料库中的每个字进行one-hot编码
- 统计语料库中所有的词的个数,例如4960个词。
- 按顺序依次给每个词进行one-hot编码,例如第1个词为:[1,0,0,0,0,0,0,….,0],就是第一个数字为0后面剩下的4959个为0,最后1个词为: [0,0,0,0,0,0,0,….,1]就是前4959个为0最后一个为1
- 理论上,每个词元会被分配一个唯一的二进制编码,通过在对应位置放置1,其余位置置0。
- 该方法的优点是输入向量长度固定,便于模型处理。
2.one-hot编码的缺点
- 在一个包含N个词元的语料库中,每个词元的编码向量(one-hot)长度恒定为N,但这会导致特征空间非常稀疏,带来维度灾难问题。
例如有一句话为“我爱北京天安门”,则传入神经网络输入层的数据为:
[1,0,0,0,0,0,0,….,0]
[0,1,0,0,0,0,0,….,0]
[0,0,1,0,0,0,0,….,0]
[0,0,0,1,0,0,0,….,0]也就是4*4960的矩阵但矩阵只有前四列有1,后面的4956列全为0,可以看出矩阵非常稀疏,出现维度灾难
三.解决one-hot编码的维度灾难问题
1.如何解决维度灾难问题
通过神经网络训练,将每个词都映射到一个较短的词向量上来。
例如有一句话为“我爱北京天安门”,通过神经网络训练后的数据为:
[0.62,0.12,0.01,0,0,0,0,….,0]
[0.1,0.12,0.001,0,0,0,0,….,0]
[0,0,0.01,0.392,0.39, 0,….,0]
[0,0,0,1,0,0.01,0.123,….,0.11](4*300)
也就是我们将原来的4*4960压缩到了4*300维的词向量,还可以发现维度中的数字已经不是1和0了,而是一些浮点数。这就叫做词嵌入
2.什么是词嵌入
将高维度的词表示转换为低维度的词表示的方法,我们称之为词嵌入(word embedding)
3.高效训练词向量的模型
word2vec模型
Google研究团队里的Tomas Mikolov等人于2013年的《Distributed Representations ofWords and Phrases and their Compositionality》以及后续的《Efficient Estimation of Word Representations in Vector Space》两篇文章中提出的一种高效训练词向量的模型,也就是word2vec。
4.word2vec模型原理
- 目标:将高维的One-Hot编码(如4960维)压缩到低维度的向量(如300维),形成更稠密、有意义的词向量。
- 核心思想:复现“完形填空”的逻辑,利用上下文信息来理解和表示词语。
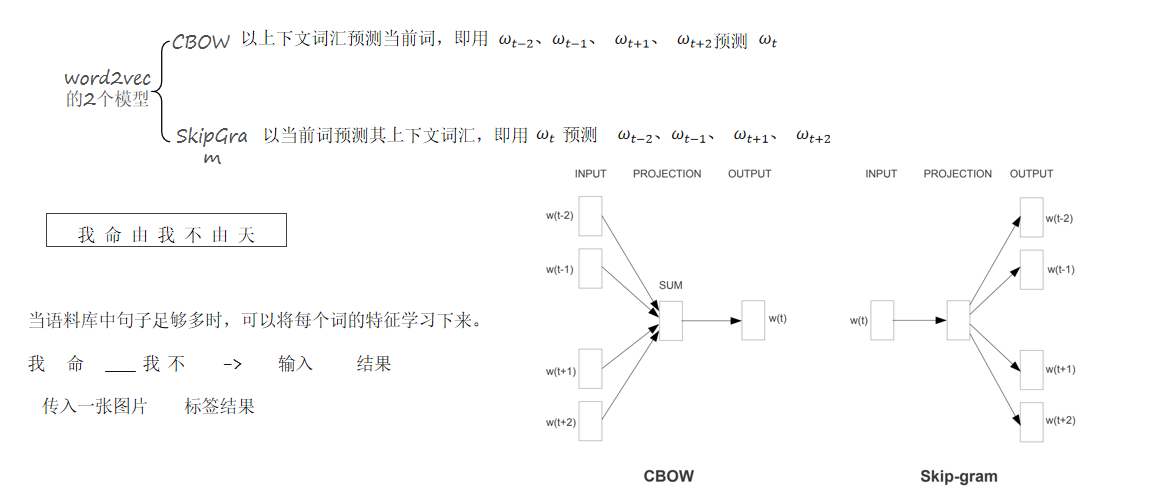
- 两种主要方法:
- CBOW (Continuous Bag-of-Words):使用上下文词的向量来预测中心词。
- Skip-gram:以当前词为中心,预测其上下文词。
模型的训练过程:
1、当前词的上下文词语的one-hot编码输入到输入层。 4*4960
2、这些词分别乘以同一个矩阵Wv*n(4960*300)后分别得到各自的1*N 向量。4*300
3、将多个这些1*N 向量取平均为一个1*N 向量。1*300
4、将这个1*N 向量乘矩阵 Wn*v(300*4960) ,变成一个1*V 向量。1*4960(因为cbow模型最后是预测一个词)
5、将1*V 向量softmax归一化后输出取每个词的概率向量1*V
6、将概率值最大的数对应的词作为预测词。
7、将预测的结果1*V 向量和真实标签1*V 向量(真实标签中的V个值中有一个是1,其他是0)计算误差(可以看作多分类问题的误差计算使用softmax交叉熵损失函数)
8、在每次前向传播之后反向传播误差,不断调整 WV*N和 W’V*N矩阵的值。
注意:做CBOW时,最终要的是WV*N 矩阵,因为这个矩阵就是最后就是训练好的词库词向量
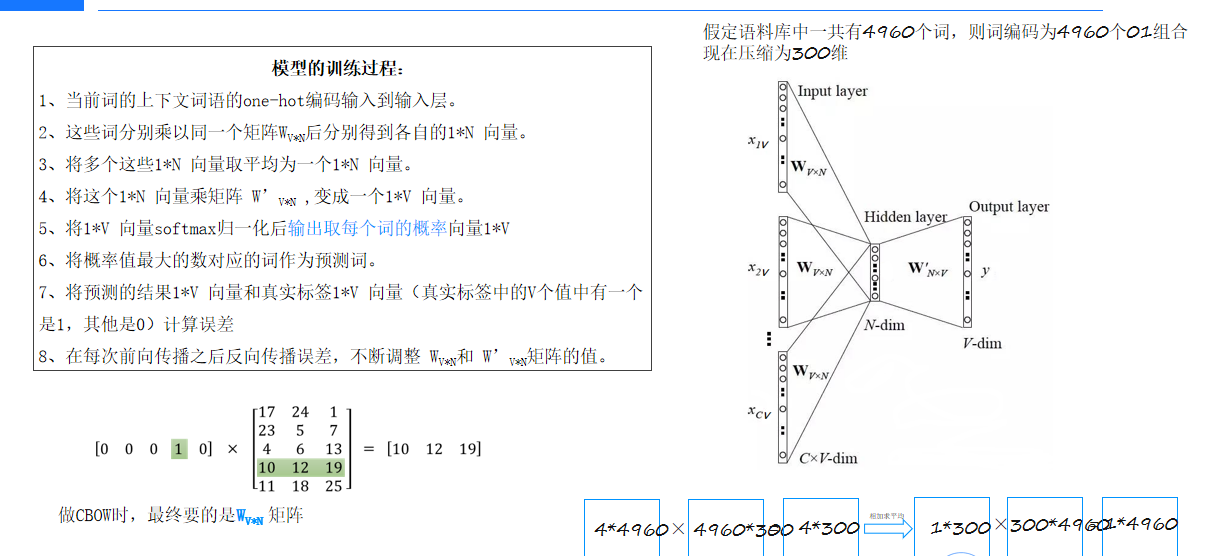
模型结构:
并非标准的全连接或卷积神经网络,而是采用专门的Embedding结构。 输入多个词的One-Hot向量(例如4*4960),经过一个共享的映射矩阵乘法运算,再进行平均或池化处理,最后经过一个可学习的矩阵变换和Softmax函数来生成预测结果(例如1*4960)。
训练过程会调整两个核心的可学习矩阵,其中一个(即Wv*n)直接用于生成最终的词向量空间。