cifar10分类对比:使用PyTorch卷积神经网络和SVM
数据集下载参考:cifar10下载太慢,解决使用第三方链接或迅雷下载-CSDN博客
PyTorch版本
CUDA available: True CUDA version: 12.6 cuDNN version: 91002 2.8.0+cu126 Using cuda device True 12.6 1 NVIDIA GeForce RTX 3050 Laptop GPU
我是用的PyTorch2.8.0
,cpu和gpu运行差别不大,cpu也能运行,16gb内存,一个epoch大概十几秒
cpu版本
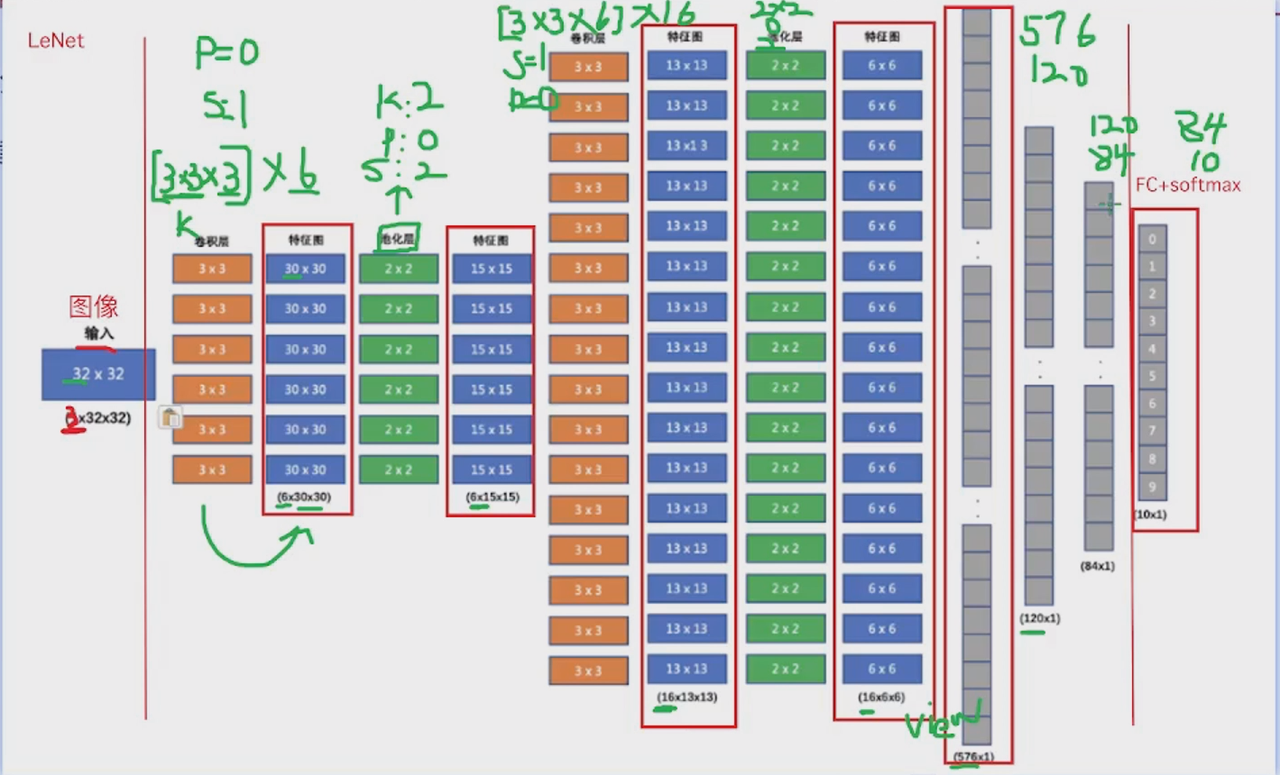
这个结构好像叫LeNet
from torchvision.datasets import CIFAR10
from torchvision.transforms import Compose, ToTensor
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import time
from tqdm import tqdm # 进度条库# -------------------------- 1. 移除 GPU 设备配置(默认使用 CPU) --------------------------
# 无需设置 device,PyTorch 默认在 CPU 上运行# 数据获取(不变)
train_data = CIFAR10(root='data', train=True, transform=Compose([ToTensor()]), )
test_data = CIFAR10(root='data', train=False, transform=Compose([ToTensor()]), )class imgClassification(nn.Module):def __init__(self):super(imgClassification, self).__init__()self.layer1 = nn.Conv2d(3, 6, 3, 1, 0)self.pooling1 = nn.MaxPool2d(2, 2, 0)self.layer2 = nn.Conv2d(6, 16, 3, 1, 0)self.pooling2 = nn.MaxPool2d(2, 2, 0)self.layer3 = nn.Linear(16*6*6, 120) # 576 = 16*6*6self.layer4 = nn.Linear(120, 84)self.out = nn.Linear(84, 10)def forward(self, x):x = torch.relu(self.layer1(x))x = self.pooling1(x)x = torch.relu(self.layer2(x))x = self.pooling2(x)x = x.reshape(x.size(0), -1)x = torch.relu(self.layer3(x))x = torch.relu(self.layer4(x))return self.out(x)# -------------------------- 2. 移除模型移至 GPU 的代码 --------------------------
model = imgClassification() # 直接在 CPU 上创建模型def train():cri = nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.parameters(), lr=0.001)epochs = 10loss_mean = []start_time_ = time.time()for epoch in range(epochs):epoch_start_time = time.time() # Epoch 耗时统计# CPU 训练时 num_workers 设为 0(避免多线程问题,Windows 系统推荐)dataloader = DataLoader(train_data, batch_size=64, shuffle=True, num_workers=0)pbar = tqdm(dataloader, total=len(dataloader), desc=f"Epoch {epoch+1}/{epochs}")loss_sum = 0for x, y in pbar:# -------------------------- 3. 移除数据移至 GPU 的代码 --------------------------# 直接使用 CPU 数据,无需 .to(device)y_predict = model(x)loss = cri(y_predict, y)optimizer.zero_grad()loss.backward()optimizer.step()loss_sum += loss.item()pbar.set_postfix({"batch_loss": f"{loss.item():.4f}"})epoch_time = time.time() - epoch_start_timeavg_loss = loss_sum / len(dataloader)loss_mean.append(avg_loss)print(f"\nEpoch {epoch+1}/{epochs}, Loss: {avg_loss:.4f}, Time: {epoch_time:.2f}s")pbar.close()print(f"\nCNN 训练完成,耗时:{time.time() - start_time_:.2f}秒")torch.save(model.state_dict(), 'model_cpu.pth')def test():model.load_state_dict(torch.load('model_cpu.pth', map_location='cpu')) # 强制加载到 CPUmodel.eval()test_loader = DataLoader(test_data, batch_size=64, shuffle=False, num_workers=0)total_correct = 0total_samples = 0with tqdm(test_loader, total=len(test_loader), desc="Testing") as pbar:for x, y in pbar:# 无需数据移至 GPUwith torch.no_grad():output = model(x)_, predicted = torch.max(output, 1)total_correct += (predicted == y).sum().item()total_samples += y.size(0)pbar.set_postfix({"acc": f"{total_correct/total_samples:.4f}"})accuracy = total_correct / total_samplesprint(f"测试集准确率: {accuracy:.4f}")if __name__ == '__main__':train()test()输出结果:
Epoch 1/10: 100%|█████████████████████████████████████████████████| 782/782 [00:13<00:00, 58.28it/s, batch_loss=1.7005]Epoch 1/10, Loss: 1.7876, Time: 13.42s
Epoch 2/10: 100%|█████████████████████████████████████████████████| 782/782 [00:14<00:00, 53.40it/s, batch_loss=1.4292]Epoch 2/10, Loss: 1.4649, Time: 14.65s
Epoch 3/10: 100%|█████████████████████████████████████████████████| 782/782 [00:15<00:00, 50.68it/s, batch_loss=1.9791]Epoch 3/10, Loss: 1.3326, Time: 15.43s
Epoch 4/10: 100%|█████████████████████████████████████████████████| 782/782 [00:14<00:00, 52.20it/s, batch_loss=1.2649]Epoch 4/10, Loss: 1.2460, Time: 14.98s
Epoch 5/10: 100%|█████████████████████████████████████████████████| 782/782 [00:14<00:00, 54.26it/s, batch_loss=0.5399]Epoch 5/10, Loss: 1.1878, Time: 14.41s
Epoch 6/10: 100%|█████████████████████████████████████████████████| 782/782 [00:14<00:00, 53.38it/s, batch_loss=0.9920]Epoch 6/10, Loss: 1.1380, Time: 14.65s
Epoch 7/10: 100%|█████████████████████████████████████████████████| 782/782 [00:12<00:00, 61.13it/s, batch_loss=1.3001]Epoch 7/10, Loss: 1.0967, Time: 12.79s
Epoch 8/10: 100%|█████████████████████████████████████████████████| 782/782 [00:11<00:00, 65.85it/s, batch_loss=0.7458]Epoch 8/10, Loss: 1.0587, Time: 11.88s
Epoch 9/10: 100%|█████████████████████████████████████████████████| 782/782 [00:11<00:00, 67.66it/s, batch_loss=1.0342]Epoch 9/10, Loss: 1.0181, Time: 11.56s
Epoch 10/10: 100%|████████████████████████████████████████████████| 782/782 [00:11<00:00, 68.29it/s, batch_loss=1.4575]Epoch 10/10, Loss: 0.9910, Time: 11.45sCNN 训练完成,耗时:135.24秒
Testing: 100%|███████████████████████████████████████████████████████████| 157/157 [00:01<00:00, 85.72it/s, acc=0.6083]
测试集准确率: 0.6083GPU版本
,支持cuda,不需要安装cuda和CUDNN,只需下载PyTorch的gpu版本,实际运行速度一样
from torchvision.datasets import CIFAR10
from torchvision.transforms import Compose, ToTensor
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import time # 用于计算耗时
from tqdm import tqdm # 用于进度条# 1. 检查 GPU 是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")# 数据加载
train_data = CIFAR10(root='data', train=True,transform=Compose([ToTensor()]))
test_data = CIFAR10(root='data', train=False,transform=Compose([ToTensor()]))class imgClassification(nn.Module):def __init__(self):super(imgClassification, self).__init__()self.layer1 = nn.Conv2d(3, 6, 3, 1, 0)self.pooling1 = nn.MaxPool2d(2, 2, 0)self.layer2 = nn.Conv2d(6, 16, 3, 1, 0)self.pooling2 = nn.MaxPool2d(2, 2, 0)self.layer3 = nn.Linear(16*6*6, 120) # 576 = 16*6*6self.layer4 = nn.Linear(120, 60)self.out = nn.Linear(60, 10)def forward(self, x):x = torch.relu(self.layer1(x))x = self.pooling1(x)x = torch.relu(self.layer2(x))x = self.pooling2(x)x = x.reshape(x.size(0), -1)x = torch.relu(self.layer3(x))x = torch.relu(self.layer4(x))return self.out(x)model = imgClassification().to(device)def train():cri = nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.parameters(), lr=0.001)epochs = 10loss_mean = []start_time2 = time.time()for epoch in range(epochs):# -------------------------- 添加 Epoch 耗时统计 --------------------------epoch_start_time = time.time() # 记录 Epoch 开始时间dataloader = DataLoader(train_data, batch_size=64,shuffle=True, num_workers=2)# -------------------------- 添加 tqdm 进度条 --------------------------pbar = tqdm(dataloader, total=len(dataloader),desc=f"Epoch {epoch+1}/{epochs}")loss_sum = 0for x, y in pbar:x, y = x.to(device), y.to(device)y_predict = model(x)loss = cri(y_predict, y)optimizer.zero_grad()loss.backward()optimizer.step()loss_sum += loss.item()# 实时更新进度条信息(当前 batch 损失)pbar.set_postfix({"batch_loss": f"{loss.item():.4f}"})# -------------------------- 计算 Epoch 耗时 --------------------------epoch_time = time.time() - epoch_start_time # 耗时 = 结束时间 - 开始时间avg_loss = loss_sum / len(dataloader)loss_mean.append(avg_loss)# 打印 Epoch 信息(包含耗时)print(f"\nEpoch {epoch+1}/{epochs}, Loss: {avg_loss:.4f}, Time: {epoch_time:.2f}s")pbar.close() # 关闭进度条print(f"\nCNN 训练完成,耗时:{time.time() - start_time2:.2f}秒")torch.save(model.state_dict(), 'model.pth')def test():model.load_state_dict(torch.load('model.pth'))model.eval()test_loader = DataLoader(test_data, batch_size=64,shuffle=False, num_workers=2)total_correct = 0total_samples = 0# -------------------------- 测试集添加 tqdm 进度条 --------------------------with tqdm(test_loader, total=len(test_loader), desc="Testing") as pbar:for x, y in pbar:x, y = x.to(device), y.to(device)with torch.no_grad():output = model(x)_, predicted = torch.max(output, 1)total_correct += (predicted == y).sum().item()total_samples += y.size(0)# 更新进度条(当前准确率)pbar.set_postfix({"acc": f"{total_correct/total_samples:.4f}"})accuracy = total_correct / total_samplesprint(f"Test Accuracy: {accuracy:.4f}")if __name__ == '__main__':train()test()
下面这个版本是问了DeepSeek的改进版本,准确率为72%,耗时7分钟,原本DeepSeek建议epoch跑200轮,这里我省时间只跑了10轮,换成了epoch=10
from torchvision.datasets import CIFAR10
from torchvision.transforms import Compose, ToTensor, Normalize, RandomCrop, RandomHorizontalFlip, RandomRotation
from torch.utils.data import DataLoader, random_split
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim.lr_scheduler import CosineAnnealingLR
import time
from tqdm import tqdm# -------------------------- 1. 设备检查与数据增强 --------------------------
# 检查 GPU 是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")# 数据增强:训练集添加随机变换,测试集仅标准化
train_transform = Compose([RandomCrop(32, padding=4), # 随机裁剪(填充4后切32x32)RandomHorizontalFlip(p=0.5), # 50%概率水平翻转RandomRotation(15), # 随机旋转±15度ToTensor(),Normalize(mean=[0.485, 0.456, 0.406], # ImageNet 均值std=[0.229, 0.224, 0.225]) # ImageNet 标准差
])test_transform = Compose([ToTensor(),Normalize(mean=[0.485, 0.456, 0.406], # 测试集使用相同标准化参数std=[0.229, 0.224, 0.225])
])# 加载数据集并拆分训练集/验证集
train_data = CIFAR10(root='data', train=True, transform=train_transform, )
test_data = CIFAR10(root='data', train=False, transform=test_transform, )# 从训练集拆分 10% 作为验证集(用于早停)
val_size = int(0.1 * len(train_data)) # 5000 样本
train_size = len(train_data) - val_size # 45000 样本
train_subset, val_subset = random_split(train_data, [train_size, val_size], generator=torch.Generator().manual_seed(42))# -------------------------- 2. 优化后的 CNN 模型 --------------------------
class ImprovedCNN(nn.Module):def __init__(self):super(ImprovedCNN, self).__init__()# 卷积块1:3→32通道,BatchNorm+ReLU+MaxPoolself.conv1 = nn.Sequential(nn.Conv2d(3, 32, kernel_size=3, padding=1), # 32x32x3 → 32x32x32nn.BatchNorm2d(32),nn.ReLU(inplace=True),nn.MaxPool2d(2, 2) # 32x32x32 → 16x16x32)# 卷积块2:32→64通道self.conv2 = nn.Sequential(nn.Conv2d(32, 64, kernel_size=3, padding=1), # 16x16x32 → 16x16x64nn.BatchNorm2d(64),nn.ReLU(inplace=True),nn.MaxPool2d(2, 2) # 16x16x64 → 8x8x64)# 卷积块3:64→128通道(增加深度)self.conv3 = nn.Sequential(nn.Conv2d(64, 128, kernel_size=3, padding=1), # 8x8x64 → 8x8x128nn.BatchNorm2d(128),nn.ReLU(inplace=True),nn.MaxPool2d(2, 2) # 8x8x128 → 4x4x128)# 全连接层:展平+Dropout+ReLUself.fc = nn.Sequential(nn.Flatten(), # 4x4x128 → 2048nn.Dropout(0.5), # 随机丢弃50%神经元,抑制过拟合nn.Linear(128 * 4 * 4, 512), # 2048 → 512nn.ReLU(inplace=True),nn.Dropout(0.5),nn.Linear(512, 10) # 512 → 10(输出10类))def forward(self, x):x = self.conv1(x)x = self.conv2(x)x = self.conv3(x)x = self.fc(x)return x# 初始化模型并移至 GPU
model = ImprovedCNN().to(device)# -------------------------- 3. 训练函数(含早停与学习率调度) --------------------------
def train():criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-4) # L2正则化scheduler = CosineAnnealingLR(optimizer, T_max=200) # 余弦退火学习率调度epochs = 10 # 最大训练轮次best_val_loss = float('inf') # 最佳验证集loss(用于早停)patience = 15 # 连续15轮无改进则早停counter = 0 # 早停计数器# 数据加载器(优化参数)train_loader = DataLoader(train_subset, batch_size=128, # 增大batch_size(需GPU内存支持,不足则降为64)shuffle=True, num_workers=4, # 数据加载线程数(CPU核心数)pin_memory=True # 加速CPU到GPU数据传输)val_loader = DataLoader(val_subset, batch_size=128, shuffle=False, num_workers=4, pin_memory=True)start_time = time.time()print(f"\n开始训练({epochs}轮,早停耐心={patience})...")for epoch in range(epochs):# -------------------------- 训练阶段 --------------------------model.train()epoch_start = time.time()train_loss = 0.0# tqdm进度条(显示当前epoch和batch损失)pbar = tqdm(train_loader, total=len(train_loader), desc=f"Epoch {epoch+1}/{epochs}")for x, y in pbar:x, y = x.to(device), y.to(device) # 数据移至GPUoptimizer.zero_grad()y_pred = model(x)loss = criterion(y_pred, y)loss.backward()optimizer.step()train_loss += loss.item() * x.size(0) # 累计损失(乘以batch_size)pbar.set_postfix({"batch_loss": f"{loss.item():.4f}"}) # 实时显示batch损失pbar.close()# 计算训练集平均损失avg_train_loss = train_loss / len(train_subset)epoch_time = time.time() - epoch_start # 当前epoch耗时# -------------------------- 验证阶段 --------------------------model.eval()val_loss = 0.0with torch.no_grad(): # 关闭梯度计算for x, y in val_loader:x, y = x.to(device), y.to(device)y_pred = model(x)loss = criterion(y_pred, y)val_loss += loss.item() * x.size(0)avg_val_loss = val_loss / len(val_subset)# -------------------------- 早停判断与学习率更新 --------------------------print(f"\nEpoch {epoch+1}/{epochs} | "f"Train Loss: {avg_train_loss:.4f} | "f"Val Loss: {avg_val_loss:.4f} | "f"Time: {epoch_time:.2f}s | "f"LR: {optimizer.param_groups[0]['lr']:.6f}")# 保存最佳模型(验证集loss最低)if avg_val_loss < best_val_loss:best_val_loss = avg_val_losstorch.save(model.state_dict(), "best_model.pth")print(f" → 验证集Loss改善,保存最佳模型(当前最佳Val Loss: {best_val_loss:.4f})")counter = 0 # 重置早停计数器else:counter += 1print(f" → 验证集Loss未改善({counter}/{patience})")if counter >= patience:print(f"\n早停触发!连续{patience}轮验证集Loss无改善。")break # 停止训练scheduler.step() # 更新学习率(余弦退火)total_time = (time.time() - start_time) / 60 # 总耗时(分钟)print(f"\n训练完成!总耗时:{total_time:.2f}分钟,最佳验证集Loss:{best_val_loss:.4f}")# -------------------------- 4. 测试函数(评估最佳模型) --------------------------
def test():# 加载最佳模型权重model.load_state_dict(torch.load("best_model.pth"))model.eval() # 切换到评估模式(关闭Dropout等)test_loader = DataLoader(test_data, batch_size=128, shuffle=False, num_workers=4, pin_memory=True)total_correct = 0total_samples = 0# 测试集预测(带进度条)pbar = tqdm(test_loader, total=len(test_loader), desc="Testing")with torch.no_grad():for x, y in pbar:x, y = x.to(device), y.to(device)y_pred = model(x)_, predicted = torch.max(y_pred, 1) # 取概率最大的类别total_correct += (predicted == y).sum().item()total_samples += y.size(0)# 更新进度条准确率pbar.set_postfix({"acc": f"{total_correct/total_samples:.4f}"})pbar.close()# 计算测试集准确率accuracy = total_correct / total_samplesprint(f"\n测试集准确率:{accuracy:.4f}({total_correct}/{total_samples})")# -------------------------- 主函数(训练+测试) --------------------------
if __name__ == "__main__":train() # 训练并保存最佳模型test() # 用最佳模型评估测试集输出结果:
Using device: cuda开始训练(10轮,早停耐心=15)...
Epoch 1/10: 100%|█████████████████████████████████████████████████| 352/352 [00:25<00:00, 13.95it/s, batch_loss=1.7817]Epoch 1/10 | Train Loss: 1.6704 | Val Loss: 1.4331 | Time: 25.24s | LR: 0.001000→ 验证集Loss改善,保存最佳模型(当前最佳Val Loss: 1.4331)
Epoch 2/10: 100%|█████████████████████████████████████████████████| 352/352 [00:24<00:00, 14.36it/s, batch_loss=1.1918]Epoch 2/10 | Train Loss: 1.4123 | Val Loss: 1.2391 | Time: 24.52s | LR: 0.001000→ 验证集Loss改善,保存最佳模型(当前最佳Val Loss: 1.2391)
Epoch 3/10: 100%|█████████████████████████████████████████████████| 352/352 [00:25<00:00, 13.66it/s, batch_loss=1.1010]Epoch 3/10 | Train Loss: 1.3009 | Val Loss: 1.1766 | Time: 25.77s | LR: 0.001000→ 验证集Loss改善,保存最佳模型(当前最佳Val Loss: 1.1766)
Epoch 4/10: 100%|█████████████████████████████████████████████████| 352/352 [00:25<00:00, 13.70it/s, batch_loss=1.1541]Epoch 4/10 | Train Loss: 1.2322 | Val Loss: 1.0717 | Time: 25.69s | LR: 0.000999→ 验证集Loss改善,保存最佳模型(当前最佳Val Loss: 1.0717)
Epoch 5/10: 100%|█████████████████████████████████████████████████| 352/352 [00:23<00:00, 15.28it/s, batch_loss=1.2895]Epoch 5/10 | Train Loss: 1.1726 | Val Loss: 1.1265 | Time: 23.04s | LR: 0.000999→ 验证集Loss未改善(1/15)
Epoch 6/10: 100%|█████████████████████████████████████████████████| 352/352 [00:24<00:00, 14.46it/s, batch_loss=1.1469]Epoch 6/10 | Train Loss: 1.1263 | Val Loss: 1.0567 | Time: 24.35s | LR: 0.000998→ 验证集Loss改善,保存最佳模型(当前最佳Val Loss: 1.0567)
Epoch 7/10: 100%|█████████████████████████████████████████████████| 352/352 [00:23<00:00, 15.22it/s, batch_loss=0.9576]Epoch 7/10 | Train Loss: 1.0950 | Val Loss: 0.9628 | Time: 23.14s | LR: 0.000998→ 验证集Loss改善,保存最佳模型(当前最佳Val Loss: 0.9628)
Epoch 8/10: 100%|█████████████████████████████████████████████████| 352/352 [00:23<00:00, 14.73it/s, batch_loss=1.1888]Epoch 8/10 | Train Loss: 1.0665 | Val Loss: 0.9559 | Time: 23.90s | LR: 0.000997→ 验证集Loss改善,保存最佳模型(当前最佳Val Loss: 0.9559)
Epoch 9/10: 100%|█████████████████████████████████████████████████| 352/352 [00:24<00:00, 14.40it/s, batch_loss=1.0437]Epoch 9/10 | Train Loss: 1.0386 | Val Loss: 0.8989 | Time: 24.44s | LR: 0.000996→ 验证集Loss改善,保存最佳模型(当前最佳Val Loss: 0.8989)
Epoch 10/10: 100%|████████████████████████████████████████████████| 352/352 [00:23<00:00, 14.83it/s, batch_loss=1.0087]Epoch 10/10 | Train Loss: 1.0127 | Val Loss: 0.9002 | Time: 23.74s | LR: 0.000995→ 验证集Loss未改善(1/15)训练完成!总耗时:7.34分钟,最佳验证集Loss:0.8989
Testing: 100%|█████████████████████████████████████████████████████████████| 79/79 [00:16<00:00, 4.78it/s, acc=0.7275]测试集准确率:0.7275(7275/10000)
SVM支持向量机运行
,很慢,跑了41分钟,我不想跑第二次了,用的是rbf高斯核
import numpy as np
import time
from sklearn.svm import SVC
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, classification_report
from torchvision.datasets import CIFAR10
from tqdm import tqdm# -------------------------- 1. 直接读取 CIFAR-10 原始 numpy 数据 --------------------------
train_data = CIFAR10(root='data', train=True, )
test_data = CIFAR10(root='data', train=False, )X_train_raw = train_data.data # (50000, 32, 32, 3)
y_train = np.array(train_data.targets) # (50000,)X_test_raw = test_data.data # (10000, 32, 32, 3)
y_test = np.array(test_data.targets) # (10000,)print(f"原始训练集数据形状:{X_train_raw.shape},标签形状:{y_train.shape}")
print(f"原始测试集数据形状:{X_test_raw.shape},标签形状:{y_test.shape}")# -------------------------- 2. 提取特征(仅修改 num_samples 为全样本) --------------------------
def extract_features(raw_images, raw_labels, num_samples):# 全样本时无需随机选择,直接取全部数据(保留原函数结构,仅修改 indices)indices = np.arange(len(raw_images)) # 全样本索引:0 ~ len(raw_images)-1selected_images = raw_images[indices] # 全部图像selected_labels = raw_labels[indices] # 全部标签images_flatten = selected_images.reshape(num_samples, -1) # 展平为 (num_samples, 3072)return images_flatten, selected_labels# 提取全样本特征(训练集 50000,测试集 10000)
X_train, y_train_small = extract_features(X_train_raw, y_train, num_samples=50000) # 全训练集
X_test, y_test_small = extract_features(X_test_raw, y_test, num_samples=10000) # 全测试集print(f"训练集特征形状:{X_train.shape}(样本数×特征维度)") # (50000, 3072)
print(f"测试集特征形状:{X_test.shape}") # (10000, 3072)# -------------------------- 3. 特征标准化(保持不变) --------------------------
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
print('特征标准化完成')# -------------------------- 4. SVM 训练与评估(保持 RBF 核和原始参数) --------------------------
svm = SVC(kernel='rbf', C=1.0, gamma='scale', random_state=42)start_time = time.time()
svm.fit(X_train_scaled, y_train_small) # 全样本训练(RBF 核会非常慢!)
train_time = time.time() - start_time
print(f"\nSVM 训练完成,耗时:{train_time:.2f}秒")y_pred = svm.predict(X_test_scaled)
accuracy = accuracy_score(y_test_small, y_pred)
print(f"测试集准确率:{accuracy:.4f}")print("\n分类报告:")
print(classification_report(y_test_small, y_pred, target_names=train_data.classes))输出结果
原始训练集数据形状:(50000, 32, 32, 3),标签形状:(50000,)
原始测试集数据形状:(10000, 32, 32, 3),标签形状:(10000,)
训练集特征形状:(50000, 3072)(样本数×特征维度)
测试集特征形状:(10000, 3072)
特征标准化完成SVM 训练完成,耗时:2513.30秒
测试集准确率:0.5481分类报告:precision recall f1-score supportairplane 0.62 0.62 0.62 1000automobile 0.65 0.66 0.66 1000bird 0.43 0.41 0.42 1000cat 0.38 0.39 0.38 1000deer 0.48 0.44 0.46 1000dog 0.49 0.43 0.46 1000frog 0.54 0.64 0.59 1000horse 0.65 0.57 0.61 1000ship 0.66 0.69 0.68 1000truck 0.59 0.62 0.60 1000accuracy 0.55 10000macro avg 0.55 0.55 0.55 10000
weighted avg 0.55 0.55 0.55 10000总结:
cnn能跑到60%准确度,原本的LeNet改进后的准确率是72%,svm是54%,重要的是cnn运行速度更快,应该是使用PyTorch运行很快,PyTorch对 CPU 训练做了 多线程向量化优化,传统的numpy很慢, CPU 单线程训练