S 4.1深度学习--自然语言处理NLP--理论
一·前言解释
语言模型:
- 统计语言模型
- 神经语言模型
统计语言模型存在的问题:
1、由于参数空间的爆炸式增长,它无法处理(N>3)的数据。
cv = CountVectorizer(ngram_range=(1,2)) #统计每篇文章中每个词出现的频
2、没有考虑词与词之间内在的联系性。例如,考虑 "the cat is walking in the bedroom" 这句话。如果我们在训练语料中看到了很多类似 “the dog is walking in the bedroom” 或是 “the cat is running in the bedroom” 这样的句子;那么,哪怕我们此前没有见过这句话 "the cat is walking in the bedroom",也可以从 “cat” 和 “dog”(“walking” 和 “running”)之间的相似性,推测出这句话的概率。
from sklearn.feature_extraction.text import CountVectorizer
#需要转化的语句ngram_range(1, 2):对词进行组合
(1)本例组合方式:两两组合
['bird', 'cat', 'cat cat', 'cat fish', 'dog', 'dog cat', 'fish', '
(2)如果ngram_range(1, 3),则会出现3个词进行组合
['bird', 'cat', 'cat cat', 'cat fish', 'dog', 'dog cat', 'dog cat
'dog cat fish', 'fish', 'fish bird']texts=["dog cat fish","dog cat cat","fish bird", 'bird']
cont = []
'''我们 今天 来 学习 人工智能'''
#实例化一个模型
cv = CountVectorizer(ngram_range=(1,2)) #统计每篇文章中每个词出现的频#训练此模型
cv_fit=cv.fit_transform(texts)#每个词在这篇文章中出现的次数print(cv_fit)
# 打印出模型的全部词库
print(cv.get_feature_names())#打印出每个语句的词向量
print(cv.fit.toarray())
##打印出所有数据求和结果
# print(cv_fit.toarray().sum(axis=0))二·语言转换方法--神经语言模型--词嵌入embeding
如何解决维度灾难问题?
通过神经网络训练,将每个词都映射到一个较短的词向量上来。
例如有一句话为 “我爱北京天安门”,通过神经网络训练后的数据为:
plaintext
[0.62,0.12,0.01,0,0,0,0,...,0]
[0.1,0.12,0.001,0,0,0,0,...,0]
[0,0,0.01,0.392,0.39, 0,...,0]
[0,0,1,0,0.01,0.123,...,0.11] (4*300)
注意:维度中的数字已经不是 1 和 0 了,而是一些浮点数。
(旁注:“这个较短的词向量维度是多大呢?一般需要在训练时自己来指定。现在很常见的例如 300 维。”)
什么是词嵌入?
这种将高维度的词表示转换为低维度的词表示的方法,我们称之为词嵌入(word embedding)。
Google 研究团队里的 Tomas Mikolov 等人于 2013 年的《Distributed Representations of Words and Phrases and their Compositionality》以及后续的《Efficient Estimation of Word Representations in Vector Space》两篇文章中提出的一种高效训练词向量的模型,也就是word2vec(word to vector)。
在处理自然语言时,通常将词语或者字做向量化,例如 one - hot 编码,例如我们有一句话为:“我爱北京天安门”,我们分词后对其进行 one - hot 编码,结果可以是:
“我”:[1,0,0,0]
“爱”:[0,1,0,0]
“北京”:[0,0,1,0]
“天安门”:[0,0,0,1]
如果需要对语料库中的每个字进行 one - hot 编码如何实现?
- 统计语料库中所有的词的个数,例如 4960 个词。
- 按顺序依次给每个词进行 one - hot 编码,例如第 1 个词为:[1,0,0,0,0,0,0,....,0],最后 1 个词为:[0,0,0,0,0,0,0,....,1]
存在的问题?
矩阵为非常稀疏,出现维度灾难。例如有一句话为 “我爱北京天安门”,传入神经网络输入层的数据为:
[1,0,0,0,0,0,0,....,0]
[0,1,0,0,0,0,0,....,0]
[0,0,1,0,0,0,0,....,0]
[0,0,0,1,0,0,0,....,0](4*4960)
如何压缩矩阵--word2vec
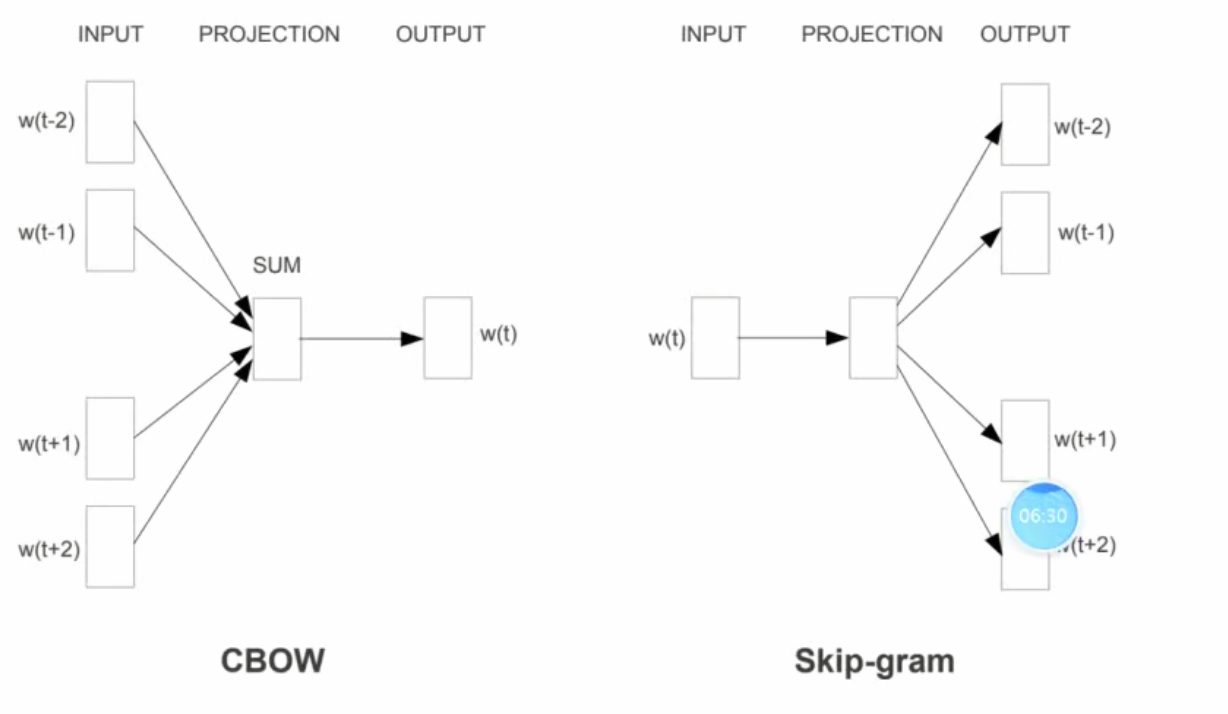
word2vec 的 2 个模型
CBOW:以上下文词汇预测当前词,即用 预测
预测 这里前几个词和后几个词没有限制
这里前几个词和后几个词没有限制
SkipGram:以当前词预测其上下文词汇,即用 预测,同理这里前几个词和后几个词没有限制
我命由我不由天
当语料库中句子足够多时,可以将每个词的特征学习下来。
我 命 ____ 我不 -> 输入 结果
传入一张图片 标签结果
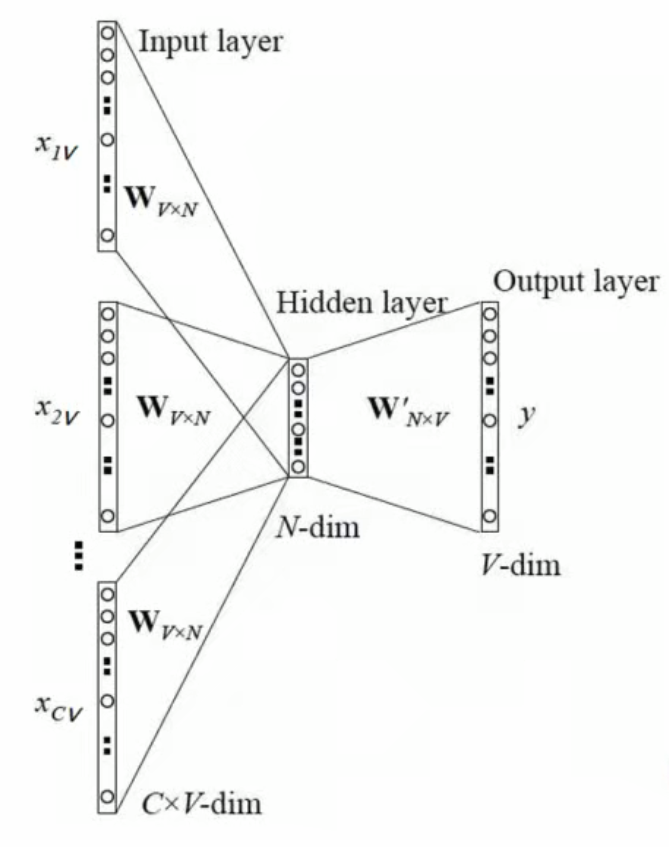
模型的训练过程:
1、当前词的上下文词语的 one - hot 编码输入到输入层。
2、这些词分别乘以同一个矩阵 后分别得到各自的1*N向量。
3、将多个这些1*N向量取平均为一个1*N向量。
4、将这个1*N向量乘矩阵,变成一个1*V向量。
5、将1*V向量 softmax (交叉熵损失函数)归一化后输出取每个词的概率向量1*V。
6、将概率值最大的数对应的词作为预测词。
7、将预测的结果1*V向量和真实标签1*V向量(真实标签中的 V 个值中有一个是 1,其他是 0)计算误差。
8、在每次前向传播之后反向传播误差,不断调整和
矩阵的值。

假定语料库中一共有4960个词,则词编码为4960个01组合,现在压缩为300维。

三·CBOW代码实现
import torch
import torch.nn as nn # 神经网络
import torch.nn.functional as F
import torch.optim as optim #
from tqdm import tqdm, trange # 显示进度条
import numpy as np# 任务:已经有了语料库,1、构造训练数据集,(单词,词库,)
# 真实的单词模型,每一个单词的词性,你训练大量的输入文本,
CONTEXT_SIZE = 2 # 设置词左边和右边选择的个数(即上下文词汇个数)raw_text = """We are about to study the idea of a computational process.
Computational processes are abstract beings that inhabit computers.
As they evolve, processes manipulate other abstract things called data.
The evolution of a process is directed by a pattern of rules
called a program. People create programs to direct processes. In effect,
we conjure the spirits of the computer with our spells.""".split() # 语料库
# 中文的语句,你可以选择分词,也可以选择分字
vocab = set(raw_text) # 集合。词库,里面内容独一无二
vocab_size = len(vocab)word_to_idx = {word: i for i, word in enumerate(vocab)} # for循环的复合写法,第1次循环,i得到的索引号,word 第1个单词
idx_to_word = {i: word for i, word in enumerate(vocab)}data = [] # 获取上下文词,将上下文词作为输入,目标词作为输出。构建训练数据集。
for i in range(CONTEXT_SIZE, len(raw_text) - CONTEXT_SIZE): # (2, 60)context = ([raw_text[i - (2 - j)] for j in range(CONTEXT_SIZE)] # [we,are]+ [raw_text[i + j + 1] for j in range(CONTEXT_SIZE)] # [to,study])target = raw_text[i] # 获取目标词'about'data.append((context, target)) # 将上下文词和目标词保存到data中 [(['we', 'are', 'to', 'study'], 'about')]def make_context_vector(context, word_to_idx): # 将上下文词转为one-hotidxs = [word_to_idx[w] for w in context]return torch.tensor(idxs, dtype=torch.long) # 强制类型的转换,得到long型print(make_context_vector(data[0][0], word_to_idx)) # 示例# 模型在cuda训练
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(device)class CBOW(nn.Module): # 神经网路def __init__(self, vocab_size, embedding_dim):super(CBOW, self).__init__() # 父类的初始化,类self.embeddings = nn.Embedding(vocab_size, embedding_dim) # vocab_size:词嵌入one-hot大小,embedding_dim:压缩后的词嵌入大小self.proj = nn.Linear(embedding_dim, 128) #self.output = nn.Linear(128, vocab_size)def forward(self, inputs):embeds = sum(self.embeddings(inputs)).view(1, -1) # sumout = F.relu(self.proj(embeds)) # nn.relu()激活层out = self.output(out)nll_prob = F.log_softmax(out, dim=-1) # softmax交叉熵return nll_probmodel = CBOW(vocab_size, 10).to(device) # 语料库中一共有49个单词,[0,0,0,0,0....1]<49>...[...300]optimizer = optim.Adam(model.parameters(), lr=0.001) # 优化器losses = [] # 存储损失的集合
loss_function = nn.NLLLoss() # NLLLoss损失函数(当分类类别非常多的情况),将多个类别分别分成0、1两个类别,这里和F.log_softmax合在一起就是一个交叉熵损失函数
model.train() # 代表开始训练模型,模型具有训练的能力,w设置一个可写的权限?for epoch in tqdm(range(200)): # 才开始训练total_loss = 0for context, target in data:context_vector = make_context_vector(context, word_to_idx).to(device)target = torch.tensor([word_to_idx[target]]).to(device)# 开始前向传播train_predict = model(context_vector) # 可以不写forward, torch的内置功能。loss = loss_function(train_predict, target) # 计算真实和预测两值之间的差距# 反向传播optimizer.zero_grad() # 梯度清零loss.backward() # 反向传播计算得到每个参数的梯度值optimizer.step() # 根据梯度更新网络参数total_loss += loss.item()losses.append(total_loss)print(losses)# 测试
context = ['People', 'create', 'to', 'direct'] # People create programs to direct
context_vector = make_context_vector(context, word_to_idx).to(device)
# 预测的值
model.eval() # 进入到测试模式
predict = model(context_vector)
max_idx = predict.argmax(1) # dim=1表示每一行中的最大值对应的索引号,dim=0表示每一列中的最大值对应的索引号# 获取词向量,这个Embedding就是我们需要的词向量,它只是一个模型的一个中间过程
print("CBOW embedding'weight=", model.embeddings.weight) # GPU
W = model.embeddings.weight.cpu().detach().numpy() # .detach(): 这个方法会创建一个新的Tensor,它和原来的Tensor共享数据,但是不会追踪梯度。# 这意味着这个新的Tensor不会参与梯度的反向传播,这对于防止在计算梯度时意外修改某些参数很有用。
print(W)
# 生成词嵌入字典,即{单词1:向量1, 单词2:向量2...}的格式
word_2_vec = {}
for word in word_to_idx.keys():# 词向量矩阵中某个词的索引所对应的那一列即为所该词的词向量word_2_vec[word] = W[word_to_idx[word], :]
print('jiesu')# '''保存训练后的词向量为npz文件'''numpy W 处理矩阵的速度非常快,方便后期其他人项目,要继续使用
np.savez('word2vec实现.npz', file_1 = W)
data = np.load('word2vec实现.npz')
print(data.files)