canal+DataX实现数据全量/实时同步
一、背景介绍
业务场景
需求单位提了很多报表的专案,内部讨论需要使用数仓分层架构来处理,那首先第一步就是需要建立ODS层,我们使用的架构就是,通过canal将数据从MySQL实时同步至postgres,这个postgres就是ODS层,供后续的其他业务使用。
于是搭建了canal集群,并且实现了部分数据从MySQL实时同步至postgres,那么要怎么解决全量数据同步的问题?
问题点
1、实时同步搭建好以后,后续的数据新增/修改/删除,都会被canal采集并且实时同步至postgres,也就是增量部分的数据没问题。
2、那实时同步之前的那部分数据要怎么同步过来呢?这里可以用Kettle脚本、datax等工具进行同步。
3、如果在使用工具进行同步的期间,MySQL数据库中的数据被修改/删除了,这部分数据怎么通知到postgres进行修改呢?
思路解析
第1、2个问题都是可以解决的,那第3个问题,差异部分数据怎么告知postgres进行修改呢?回想canal实时同步数据的原理,它是通过从MySQL的binlog中读取相应的DDL或者DML来进行数据实时同步的,并且canal在创建Instance的时候,还可以指定binlog的文件名以及position,然而,第三个问题中发生的数据篡改,肯定会被记录到MySQL的binlog中,那么差异部分的数据,自然就可以通过canal的Instance指定binlog文件名及position进行再次同步了
二、实现过程
全量同步
使用DataX进行数据全量同步
1、关闭canal实例
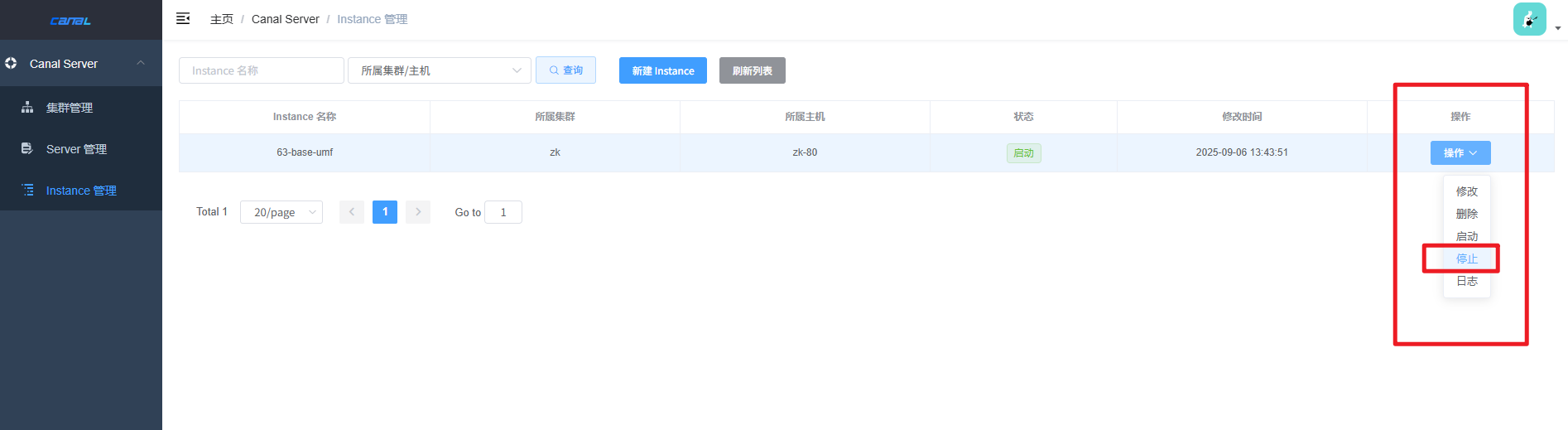
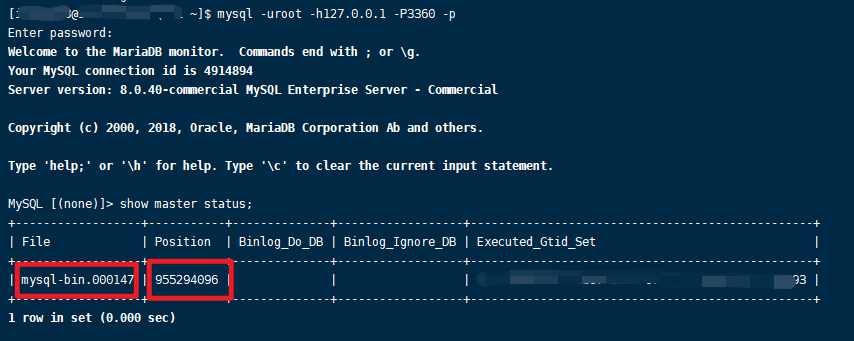
2、记录MySQL binlog信息
3、编写DataX任务脚本
#这里是使用DataX进行全量数据同步,首先需要编写这样一个json文件
vi scm_base_sys_msg.json#在文件中加入如下内容(连接IP、用户名、密码、表名、字段名需要修改成自己要同步的信息):
#preSql,就是在执行数据同步之前要执行的SQL,可以替换成truncate table
{"job": {"setting": {"speed": {"channel": 1}},"content": [{"reader": {"name": "mysqlreader","parameter": {"username": "root","password": "123456","column": ["id","type_id","model_id","title","content","url","url_param","is_alert","send_state","read_state","from_user_id","to_user_id","send_time","delete_flag","create_by","create_time","update_by","update_time"],"splitPk": "id","connection": [{"table": ["sys_msg"],"jdbcUrl": ["jdbc:mysql://192.168.0.1:3306/scm_base"]}]}},"writer": {"name": "postgresqlwriter","parameter": {"username": "postgres","password": "123456","column": ["id","type_id","model_id","title","content","url","url_param","is_alert","send_state","read_state","from_user_id","to_user_id","send_time","delete_flag","create_by","create_time","update_by","update_time"],"preSql": ["delete from sys_msg"],"connection": [{"jdbcUrl": "jdbc:postgresql://192.168.0.1:5432/scm_base","table": ["sys_msg"]}]}}}]}
}
4、运行脚本
进入datax安装路径
#执行数据同步脚本
python bin/datax.py job/scm_base_sys_msg.json5、执行结果
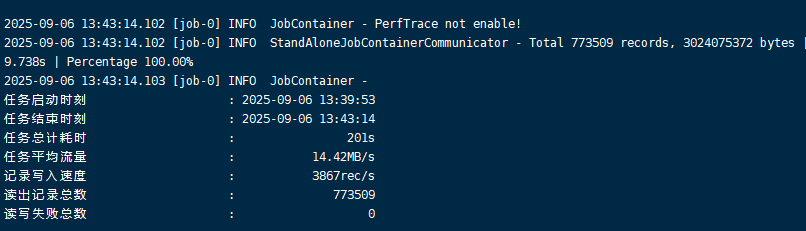
差异同步(增量同步)
1、修改Instance
将记录下来的MySQL binlog信息,修改上去(注意,只补充这两个配置项),然后保存
#修改这两个配置项
canal.instance.master.journal.name=mysql-bin.000147
canal.instance.master.position=955294096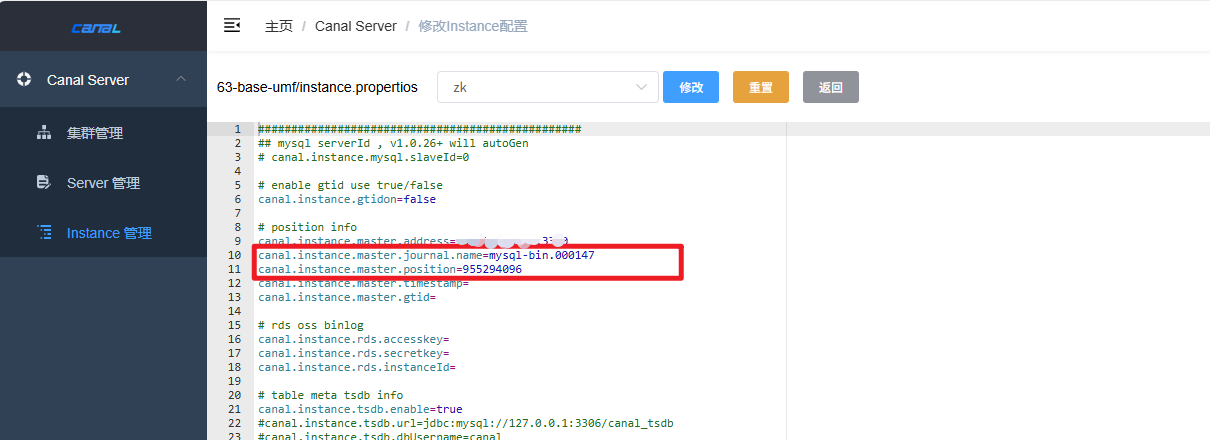
2、启动实例
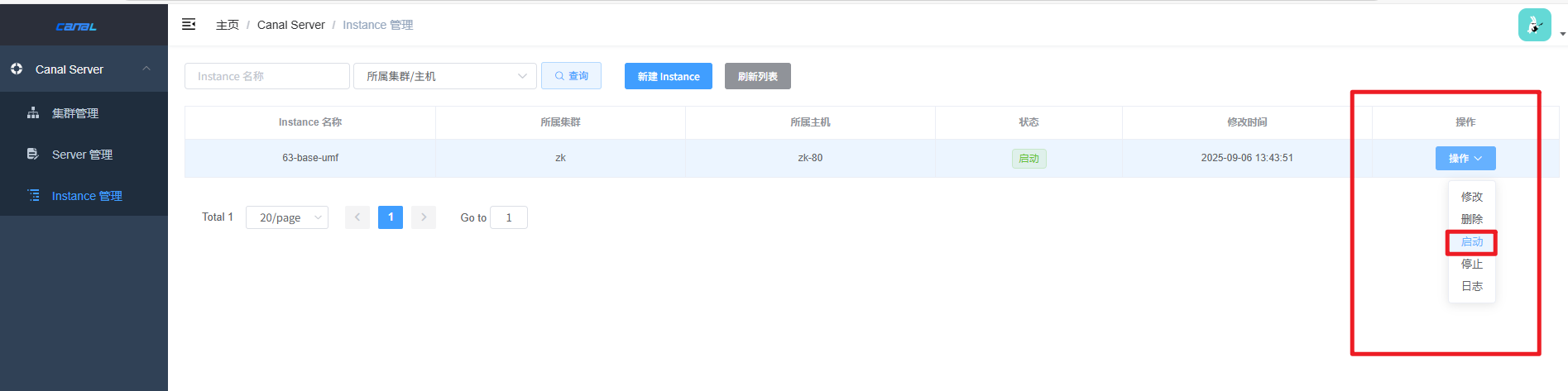
至此,所有配置完成
三、总结
差异同步中启动实例后,你会发现,canal会自动同步差异部分的数据,并且增量数据的配置也算是OK了