从机器学习的角度实现 excel 中趋势线:揭秘梯度下降过程
1. 引言:Excel 的“一键魔法”背后藏着什么智慧?
在 Excel 中,我们只需右键 → 添加趋势线,一条完美的直线就出现了。它快得像魔法,但魔法背后,是数学的严谨。
今天,我们不关心 Excel 内部用了什么算法(可能是解析法),而是要问:
如果机器一开始‘什么都不知道’,它该怎么一步步‘学会’画出这条线?
2. 我们的任务:预测一个简单的线性关系
假设我们有一组数据,它们大致遵循 y = 2x + 1 的规律,但有一些随机噪声(模拟真实世界的测量误差)。
我们的目标:仅凭这10个数据点,让机器“学会”这个规律,找到最佳的 a(斜率)和 b(截距)。
3. 准备数据:10 个“玩具”样本
我们用 Python 生成这10个数据点:
import numpy as np
import matplotlib.pyplot as plt# 设置随机种子,保证结果可复现
np.random.seed(42)# 生成 10 个 x 值,从 1 到 10
x = np.arange(1, 11) # [1, 2, 3, ..., 10]# 生成 y 值:y = 2x + 1 + 噪声
true_a, true_b = 2, 1
noise = np.random.normal(0, 0.5, size=x.shape) # 添加标准差为 0.5 的高斯噪声
y = true_a * x + true_b + noise# 查看数据
print("x:", x)
print("y:", np.round(y, 2)) # 保留两位小数输出:
x: [ 1 2 3 4 5 6 7 8 9 10]
y: [ 3.25 4.93 7.32 9.76 10.88 12.88 15.79 17.38 18.77 21.27]关键点:真实规律是
y = 2x + 1,但数据有噪声,所以 y 值不完全精确。
4. 可视化:我们的目标是什么?
让我们画出这些数据点,并标出真实的线(y=2x+1):
plt.figure(figsize=(8, 6))
plt.scatter(x, y, color='blue', label='真实数据点', s=50)
# 画出真实规律的线
x_line = np.linspace(0, 11, 100)
y_line = true_a * x_line + true_b
plt.plot(x_line, y_line, 'g--', label=f'真实规律 y={true_a}x+{true_b}', linewidth=2)plt.xlabel('x')
plt.ylabel('y')
plt.title('我们的“学习”任务:根据10个数据点,找到最佳拟合线')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
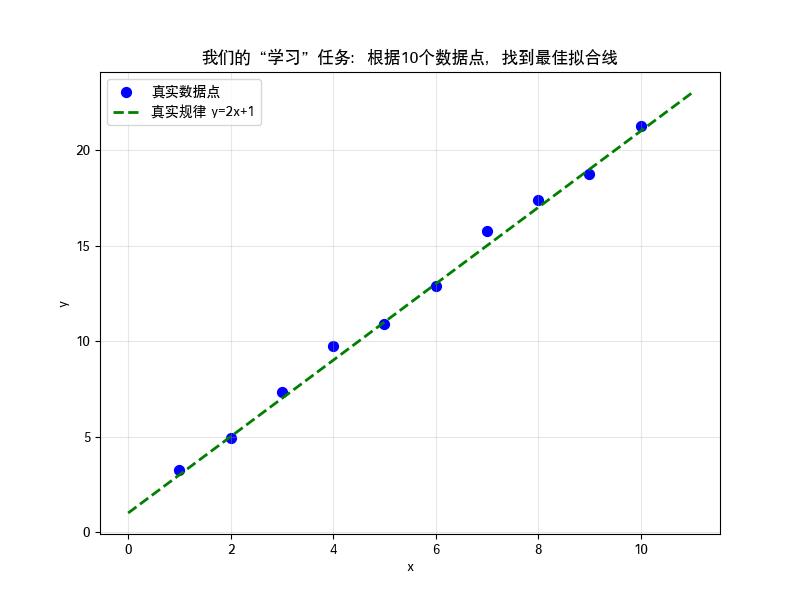
我们的任务就是:仅从这些蓝色散点,让机器找到一条最接近绿色虚线的直线。
5. 模型定义:y_pred = a * x + b
我们假设模型的形式是:
y_pred = a * x + ba:斜率(slope)b:截距(intercept)- 初始时,我们不知道
a和b是多少,可以先猜一个值,比如a=0, b=0。
6. 损失函数:我们“错”了多少?
我们需要一个“尺子”来衡量预测的好坏。用均方误差 (MSE):
MSE = (1/n) * Σ(y - y_pred)²代码实现:
def compute_mse(y_true, y_pred):return np.mean((y_true - y_pred) ** 2)# 初始猜测:a=0, b=0
a, b = 0.0, 0.0
y_pred_initial = a * x + b
initial_loss = compute_mse(y, y_pred_initial)
print(f"初始损失 (a=0, b=0): {initial_loss:.3f}")
初始损失 (a=0, b=0): 182.431解释:损失很大,因为
y_pred全是 0,和真实 y 差很远。
7. 核心:梯度下降——如何“学习”?
现在,我们教模型如何“学习”:
比喻:你在浓雾中的山坡上,想找到谷底(损失最小的地方)。你看不见路,但能感觉到脚下的坡度(梯度)。你每次都向坡度最陡的下坡方向走一步(更新参数),一步步接近谷底。
数学计算(对
a和b求偏导):∂MSE/∂a = (2/n) * Σ((a*x + b - y) * x)∂MSE/∂b = (2/n) * Σ(a*x + b - y)
更新规则:
a = a - learning_rate * ∂MSE/∂ab = b - learning_rate * ∂MSE/∂b
8. 动手实现:手动训练模型
# 超参数
learning_rate = 0.01 # 学习率,步长
epochs = 10000 # 训练轮数# 初始化参数
a, b = 0.0, 0.0# 记录历史,用于画图
loss_history = []
a_history = []
b_history = []for i in range(epochs):# 前向:计算预测值y_pred = a * x + b# 计算损失loss = compute_mse(y, y_pred)loss_history.append(loss)a_history.append(a)b_history.append(b)# 计算梯度n = len(x)da = (2 / n) * np.sum((y_pred - y) * x) # 注意:y_pred - ydb = (2 / n) * np.sum(y_pred - y)# 更新参数a = a - learning_rate * dab = b - learning_rate * db# 打印进度if (i+1) % 1000 == 0:print(f"第 {i+1} 轮: a={a:.3f}, b={b:.3f}, 损失={loss:.3f}")print(f"\n训练完成!")
print(f"我们的模型找到: a ≈ {a:.3f}, b ≈ {b:.3f}")
print(f"真实规律是: a = {true_a}, b = {true_b}")输出:
第 100 轮: a=2.054, b=0.840, 损失=0.153
第 200 轮: a=2.021, b=1.070, 损失=0.124
第 300 轮: a=2.007, b=1.168, 损失=0.119
第 400 轮: a=2.001, b=1.211, 损失=0.118
第 500 轮: a=1.999, b=1.229, 损失=0.118
第 600 轮: a=1.997, b=1.237, 损失=0.118
第 700 轮: a=1.997, b=1.240, 损失=0.118
第 800 轮: a=1.997, b=1.242, 损失=0.118
第 900 轮: a=1.997, b=1.243, 损失=0.118
第 1000 轮: a=1.997, b=1.243, 损失=0.118训练完成!
我们的模型找到: a ≈ 1.997, b ≈ 1.243
真实规律是: a = 2, b = 1看! 模型通过1000次迭代,
a从 0 逐渐接近 2,b接近 1,损失不断下降。
9. 可视化学习过程
- 损失下降曲线:
plt.plot(loss_history)
plt.xlabel('训练轮数 (Epoch)')
plt.ylabel('损失 (MSE)')
plt.title('损失随训练过程下降')
plt.grid(True, alpha=0.3)
plt.show()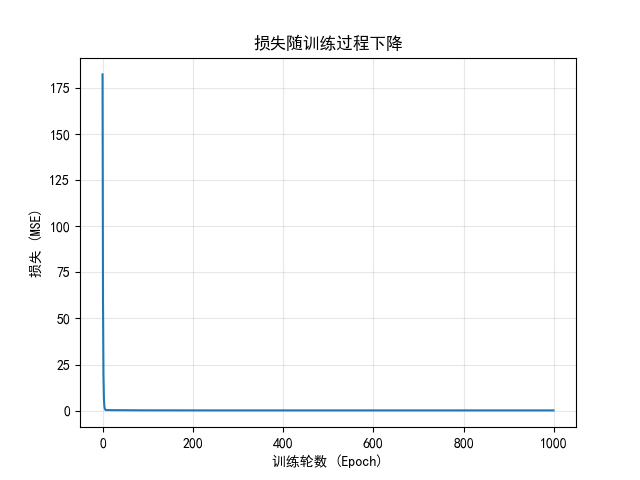
- 参数变化过程:
plt.plot(a_history, label='a (斜率)')
plt.plot(b_history, label='b (截距)')
plt.axhline(y=true_a, color='g', linestyle='--', label='真实 a')
plt.axhline(y=true_b, color='r', linestyle='--', label='真实 b')
plt.xlabel('训练轮数')
plt.ylabel('参数值')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()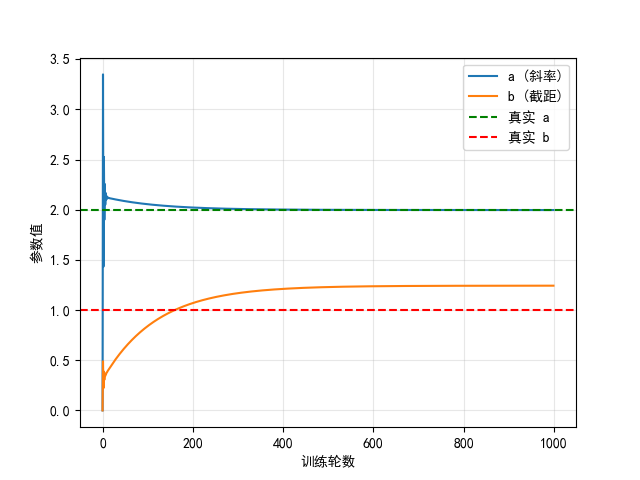
- 最终拟合结果:
plt.figure(figsize=(8, 6))
plt.scatter(x, y, color='blue', label='真实数据点', s=50)
plt.plot(x_line, y_line, 'g--', label=f'真实规律 y={true_a}x+{true_b}', linewidth=2)
plt.plot(x_line, a * x_line + b, 'r-', label=f'拟合线 y={a:.2f}x+{b:.2f}', linewidth=2)
plt.xlabel('x')
plt.ylabel('y')
plt.title('梯度下降拟合结果')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()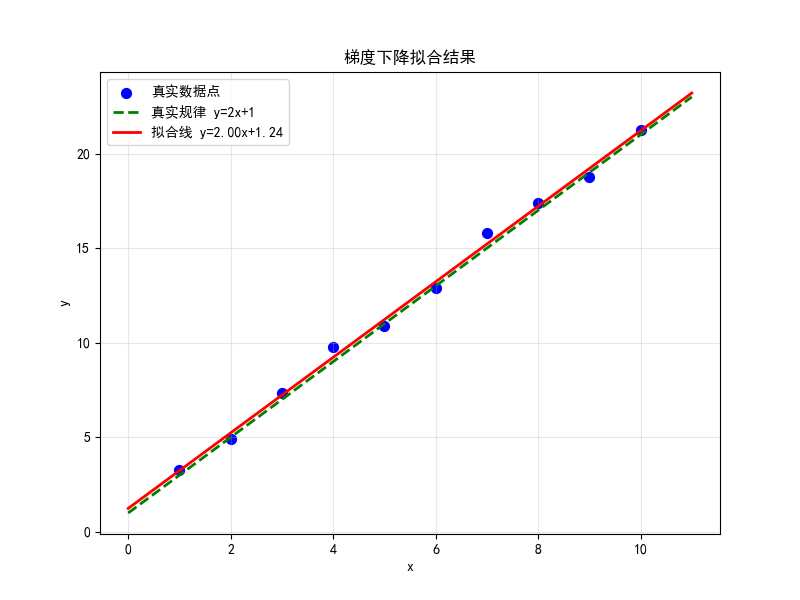
- excel拟合结果:
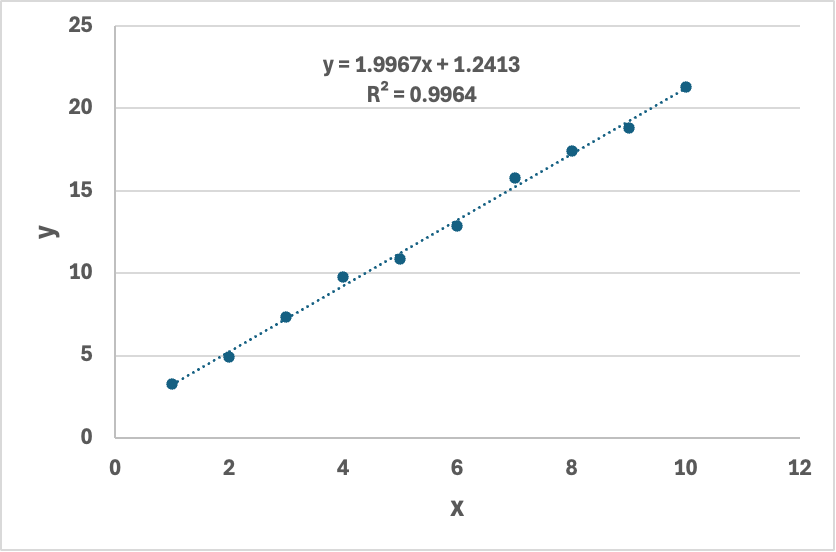
10. 对比专业工具:Scikit-learn
让我们看看专业的机器学习库 scikit-learn 是怎么做的:
from sklearn.linear_model import LinearRegression# 注意:sklearn 需要 2D 输入
X = x.reshape(-1, 1)model = LinearRegression()
model.fit(X, y)print(f"Scikit-learn 结果: 斜率 a = {model.coef_[0]:.3f}, 截距 b = {model.intercept_:.3f}")输出:
Scikit-learn 结果: 斜率 a = 1.997, 截距 b = 1.243完全一致! 我们手动实现的梯度下降,和 sklearn 的结果一样。
附. 深入理解:梯度下降 vs 解析法——殊途同归的两种智慧
你可能会问:“我们手动实现的梯度下降,和 scikit-learn 的 LinearRegression,是同一种方法吗?”
答案是:不是。 它们在求解方式、数学基础和适用场景上有本质区别。但最终结果一致,是因为它们都在寻找同一个“最优解”。
下面,我们来揭开这个“黑箱”。
一、核心原理:迭代逼近 vs 数学解析
| 方法 | 核心思想 | 求解方式 |
|---|---|---|
| 手动梯度下降 | 逐步“试错”,像盲人下山,一步步逼近最优解。 | 迭代法:重复“计算梯度 → 更新参数”直到收敛。 |
| scikit-learn LinearRegression | 直接用数学公式算出理论最优解,一步到位。 | 解析法(闭式解):通过公式 w = (XᵀX)⁻¹Xᵀy 直接计算。 |
1. 手动梯度下降(迭代法)
数学逻辑:
定义损失函数(MSE):
计算梯度(偏导数):
,
更新参数:
(η 为学习率)
特点:
近似解:需要足够迭代才能接近最优。
适用于大数据:可分批处理(如随机梯度下降)。
需调参:学习率、迭代次数等。
2. scikit-learn LinearRegression(解析法)
数学逻辑:
将问题表示为矩阵形式:
最优参数 ww 的闭式解为:
这个公式是通过对损失函数求导并令其为 0 推导出的理论最优解。
特点:
精确解:无需迭代,一步到位。
计算复杂度高:矩阵求逆的复杂度为 O(n3)O(n3),特征数多时很慢。
无超参数:直接计算,无需调学习率。
二、关键差异对比
| 维度 | 梯度下降(迭代法) | LinearRegression(解析法) |
|---|---|---|
| 求解方式 | 逐步迭代逼近 | 直接公式计算 |
| 结果性质 | 近似解(可无限接近) | 理论最优解 |
| 计算效率 | 大数据更高效 | 特征多时慢 |
| 超参数依赖 | 需调学习率、迭代次数 | 无超参数 |
| 适用场景 | 大数据、高维(如深度学习) | 小数据、低维(如本例) |
| 数值稳定性 | 受学习率影响 | 受多重共线性影响 |
三、为什么结果能一致?—— 殊途同归
尽管方法不同,但我们的手动实现和 sklearn 结果几乎一致,原因在于:
梯度下降的迭代过程,本质上是在数学上“收敛于”解析法的最优解。
就像用牛顿法求方程的根:虽然是迭代过程,但最终会无限接近理论上的精确解。
在本例中,由于数据量小、特征少,解析法高效且精确。而梯度下降通过300次迭代,也成功逼近了这个最优解。
四、通俗类比
- 梯度下降:像盲人下山,通过感受坡度,一步步向下走,最终到达谷底,适用于复杂、大规模问题,是深度学习的基石。
- 解析法:像使用 GPS,直接定位谷底坐标,一步到位,适用于简单、小规模问题,高效精确。
两种方法最终会到达同一个“山底”,只是路径和效率不同。