迁移学习实战:基于 ResNet18 的食物分类
一、迁移学习简介
迁移学习是一种高效的机器学习方法,它利用在大规模数据集上预训练好的模型,在新的任务上进行微调。这样做的优势十分显著:
- 加速训练:无需从零开始训练模型,节省大量时间。
- 提升性能:预训练模型已经学习到了通用的特征表示,能为新任务提供良好的基础。
- 数据高效:在新任务数据稀缺时,也能取得不错的效果。
二、迁移学习步骤
1. 选择预训练模型和适当的层
通常会选择在大规模图像数据集(如 ImageNet)上预训练的模型,像 VGG、ResNet 等。对于不同的任务,选择的层也有所不同:
- 若任务是低级特征提取(如边缘检测),适合使用浅层模型的层。
- 若任务是高级特征相关(如分类),则应选择更深层次的模型。
2. 冻结预训练模型的参数
保持预训练模型的权重不变,只训练新增加的层或者微调部分层。这样做是为了避免预训练模型在新数据集上过度拟合,同时也能减少计算量。
3. 在新数据集上训练新增加的层
在冻结预训练模型参数的情况下,训练新增加的层,使新模型能够适应新的任务,从而提升性能。
4. 微调预训练模型的层
在新层训练完成后,解冻一些已经训练过的层并进行微调,进一步提高模型在新数据集上的性能。
5. 评估和测试
训练完成后,使用测试集对模型进行评估。若模型性能不佳,可调整超参数或更改微调层。
三、基于 ResNet18 的食物分类实战
使用上节课所说的残差网络的18层结构来对其进行微调,该残差网络结构如下图所示:
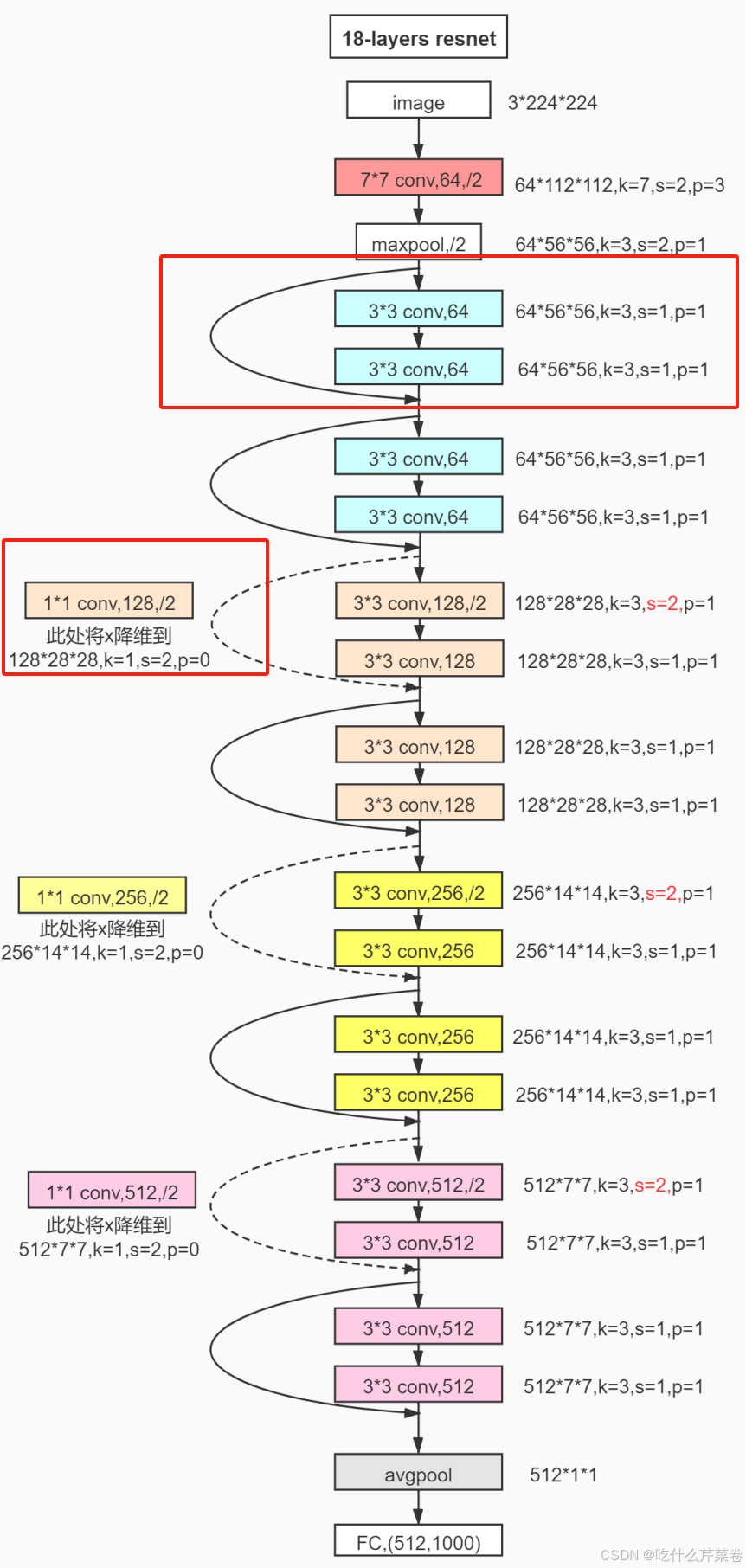
此时我们可以发现输入图像的特征大小为3*224*224,输出特征图格式为512*1*1,然后将其进行全连接层处理后变成输入512张特征图,输出1000个预测结果,这个结果的种类太多,我们不需要使用这么多的预测类别,所以当下需要对其微调,调整最后输出时的全连接层输出结果个数及其全连接层中的权重参数。
1. 导入预训练模型
我们选择在 ImageNet 上预训练好的 ResNet18 模型,代码如下:
import torch
import torchvision.models as models
from torch import nn
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
import numpy as np# 导入预训练的ResNet18模型
resent_model = models.resnet18(weights=models.ResNet18_Weights.DEFAULT)2. 冻结预训练模型参数
通过设置参数的requires_grad属性为False,冻结预训练模型的参数,使其在训练过程中不参与梯度更新:
for param in resent_model.parameters():param.requires_grad = False # 冻结所有预训练模型参数3. 修改全连接层
原 ResNet18 模型是为 ImageNet 的 1000 类分类任务设计的,我们要将其适配为 20 类食物分类任务,所以需要修改全连接层,并收集需要训练的参数:
in_features = resent_model.fc.in_features # 获取原全连接层的输入特征数
resent_model.fc = nn.Linear(in_features, 20) # 替换为输出为20类的全连接层param_to_update = [] # 收集需要训练的参数(仅新的全连接层)
for param in resent_model.parameters():if param.requires_grad:param_to_update.append(param)4. 自定义数据集类与数据增强
创建food_dataset类来加载食物图像数据,并通过数据增强来提升模型的泛化能力:
class food_dataset(Dataset):def __init__(self, file_path, transform=None):self.file_path = file_pathself.imgs = []self.labels = []self.transform = transformwith open(self.file_path) as f:samples = [x.strip().split(' ') for x in f.readlines()]for img_path, label in samples:self.imgs.append(img_path)self.labels.append(label)def __len__(self):return len(self.imgs)def __getitem__(self, idx):image = Image.open(self.imgs[idx])if self.transform:image = self.transform(image)label = self.labels[idx]label = torch.from_numpy(np.array(label, dtype=np.int64))return image, label# 数据增强与预处理
data_transforms = {'train':transforms.Compose([transforms.Resize([300, 300]),transforms.RandomRotation(45),transforms.CenterCrop(224),transforms.RandomHorizontalFlip(p=0.5),transforms.RandomVerticalFlip(p=0.5),transforms.RandomGrayscale(p=0.1),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),'test':transforms.Compose([transforms.Resize([224, 224]),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
}# 加载训练集和测试集
train_data = food_dataset(file_path=r'train.1txt', transform=data_transforms['train'])
test_data = food_dataset(file_path=r'test.1txt', transform=data_transforms['test'])# 创建数据加载器
train_dataloader = DataLoader(train_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)train.1txt,test.1txt如下:
5. 定义训练和测试函数
def train(dataloader, model, loss_fn, optimizer):model.train()batch_size_num = 1for x, y in dataloader:x, y = x.to(device), y.to(device)pred = model.forward(x)loss = loss_fn(pred, y)optimizer.zero_grad()loss.backward()optimizer.step()loss_value = loss.item()if batch_size_num % 40 == 0:print(f"loss:{loss_value:>7f} [number:{batch_size_num}]")batch_size_num += 1best_acc = 0
acc_s = []
loss_s = []def test(dataloader, model, loss_fn):global best_accsize = len(dataloader.dataset)num_batches = len(dataloader)model.eval()test_loss, correct = 0, 0with torch.no_grad():for x, y in dataloader:x, y = x.to(device), y.to(device)pred = model.forward(x)test_loss += loss_fn(pred, y).item()correct += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss /= num_batchescorrect /= sizeprint(f"Test result: \n Accuracy: {(100 * correct)}%, Avg loss: {test_loss}\n")acc_s.append(correct)loss_s.append(test_loss)if correct > best_acc:best_acc = correct6. 模型设备部署与优化器设置
device = 'cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu'
model = resent_model.to(device)loss_fn = nn.CrossEntropyLoss() # 多分类损失函数
optimizer = torch.optim.Adam(param_to_update, lr=0.001) # 仅优化新全连接层参数
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.5) # 学习率调度器7. 训练与测试
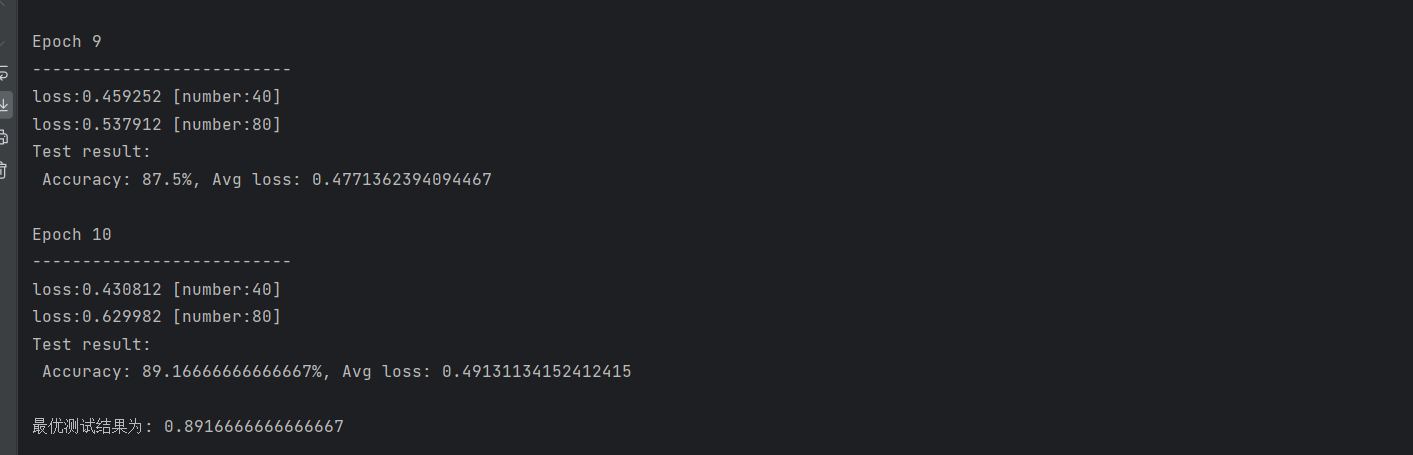
epochs = 10
for t in range(epochs):print(f"Epoch {t + 1}\n--------------------------")train(train_dataloader, model, loss_fn, optimizer)scheduler.step()test(test_dataloader, model, loss_fn)
print('最优测试结果为:', best_acc)训练结果如下: