MyBatis-Plus简介以及简单配置和使用
文章目录
- 简介
- 特性
- 框架
- 开始使用
- 配置
- 使用
- 持久层接口
- Service Interface
- Save
- 省略
- Mapper Interface(常用)
- insert
- delete
- update
- select
简介
MyBatis-Plus 是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生
特性
- 无侵入:只做增强不做改变,引入它不会对现有工程产生影响,如丝般顺滑
- 损耗小:启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作
- 强大的 CRUD 操作:内置通用 Mapper、通用 Service,仅仅通过少量配置即可实现单表大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求
- 支持 Lambda 形式调用:通过 Lambda 表达式,方便的编写各类查询条件,无需再担心字段写错
- 支持主键自动生成:支持多达 4 种主键策略(内含分布式唯一 ID 生成器 - Sequence),可自由配置,完美解决主键问题
- 支持 ActiveRecord 模式:支持 ActiveRecord 形式调用,实体类只需继承 Model 类即可进行强大的 CRUD 操作
- 支持自定义全局通用操作:支持全局通用方法注入( Write once, use anywhere )
- 内置代码生成器:采用代码或者 Maven 插件可快速生成 Mapper 、 Model 、 Service 、 Controller 层代码,支持模板引擎,更有超多自定义配置等您来使用
- 内置分页插件:基于 MyBatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通 List 查询
- 分页插件支持多种数据库:支持 MySQL、MariaDB、Oracle、DB2、H2、HSQL、SQLite、Postgre、SQLServer 等多种数据库
- 内置性能分析插件:可输出 SQL 语句以及其执行时间,建议开发测试时启用该功能,能快速揪出慢查询
- 内置全局拦截插件:提供全表 delete 、 update 操作智能分析阻断,也可自定义拦截规则,预防误操作
框架
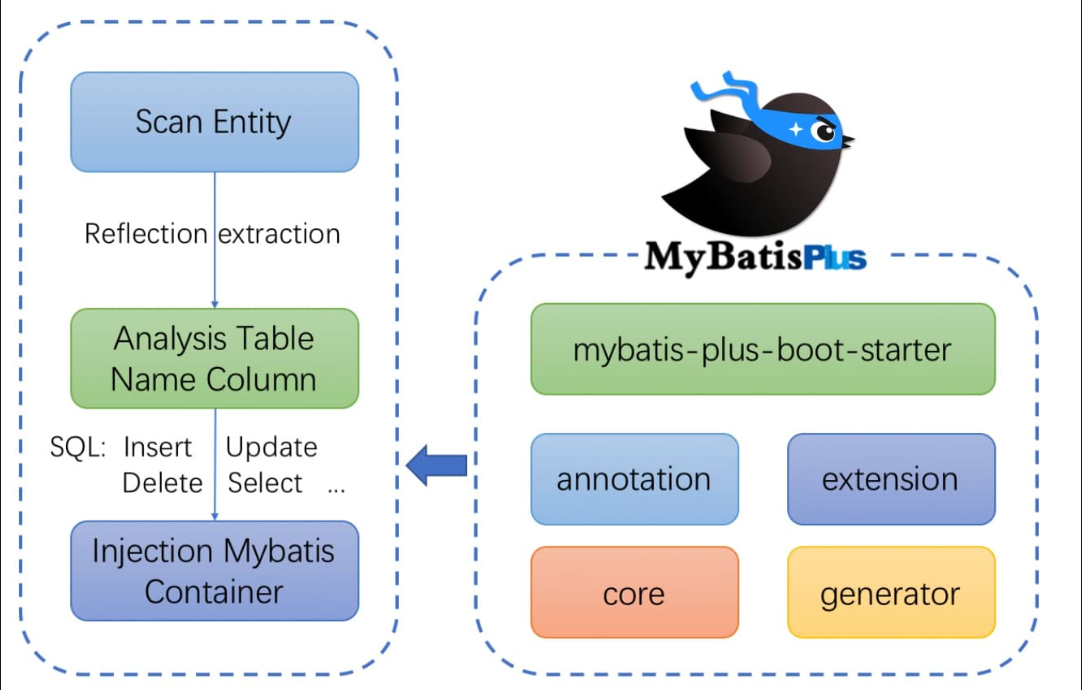
开始使用
配置
Spring-Boot2 Maven配置
<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.13</version>
</dependency>
在 application.yml 配置文件中添加 H2 数据库的相关配置:
application.yml
#服务端口: 8080
server:port: 8080
# spring配置
spring:# 数据库配置datasource:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/xs?serverTimezone=Asia/Shanghaiusername: rootpassword: rootjackson:date-format: yyyy-MM-dd HH:mm:sstime-zone: GMT+8
# mybatis-plus配置
mybatis-plus:mapper-locations: classpath*:mapper/*.xmltype-aliases-package: com.sxlg.pojoconfiguration:map-underscore-to-camel-case: truelog-impl: org.apache.ibatis.logging.stdout.StdOutImpl
上面的配置是任何一个 Spring Boot 工程都会配置的数据库链接信息,如果您使用的是其他数据库,如 MySQL,则需要修改相应的配置信息。
在 Spring Boot 启动类中添加 @MapperScan 注解,扫描 Mapper 文件夹:
Application.java
@SpringBootApplication
@MapperScan("com.sxlg.mapper")
public class PracticalApplication {public static void main(String[] args) {SpringApplication.run(PracticalApplication.class, args);}}
Book表
CREATE TABLE `xs`.`t_book` ( `book_id` INT(11) NOT NULL AUTO_INCREMENT COMMENT '图书ID(自增主键)',`book_name` VARCHAR(255) NOT NULL COMMENT '图书名称',`book_author` VARCHAR(255) NOT NULL COMMENT '图书作者',`book_type` INT(11) NOT NULL COMMENT '图书类型(1.科幻,2.冒险,3.益智)',`book_price` DOUBLE(10,2) NOT NULL COMMENT '图书价格(总位数10位,小数位2位)',`book_publish_date` DATETIME NOT NULL COMMENT '图书出版日期',`book_Description` TEXT NOT NULL COMMENT '图书描述',PRIMARY KEY (`book_id`) -- 设定 book_id 为主键
) ENGINE=INNODB DEFAULT CHARSET=utf8mb4 COMMENT='图书信息表';
插入数据:
-- 向图书表 t_book 插入10条数据
INSERT INTO `xs`.`t_book` (`book_name`, `book_author`, `book_type`, `book_price`, `book_publish_date`, `book_Description`
) VALUES
-- 1. 科幻类图书(book_type=1)
('三体', '刘慈欣', 1, 59.80, '2008-01-01', '讲述地球人类文明和三体文明的信息交流、生死搏杀及两个文明在宇宙中的兴衰历程,是中国科幻文学的里程碑之作'),
('球状闪电', '刘慈欣', 1, 45.00, '2005-06-01', '以球状闪电为线索,探讨了宏观世界与微观世界的联系,融合了物理理论与科幻想象,情节跌宕起伏'),
('沙丘', '弗兰克·赫伯特', 1, 88.00, '1965-08-01', '背景设定在遥远未来的宇宙,围绕沙漠星球阿拉基斯上的香料资源展开,涉及政治、宗教、生态等多重主题,是科幻史上的经典'),-- 2. 冒险类图书(book_type=2)
('鲁滨逊漂流记', '丹尼尔·笛福', 2, 32.80, '1719-04-25', '讲述鲁滨逊因海难流落荒岛,凭借智慧和毅力在岛上生存28年,最终返回文明社会的冒险故事,传递了坚韧不拔的精神'),
('海底两万里', '儒勒·凡尔纳', 2, 49.90, '1870-01-01', '跟随尼摩船长驾驶的“鹦鹉螺号”潜艇,探索海底世界的奇妙与神秘,包含大量海洋生物、地理知识,兼具冒险与科普属性'),
('汤姆·索亚历险记', '马克·吐温', 2, 29.90, '1876-06-01', '以美国南方小镇为背景,讲述汤姆·索亚和伙伴们的冒险经历,批判了当时刻板的教育制度,充满童真与勇气'),
('金银岛', '罗伯特·路易斯·史蒂文森', 2, 35.00, '1883-05-01', '围绕一张神秘的藏宝图,讲述少年吉姆与海盗、船长等人的海上寻宝冒险,情节紧张刺激,塑造了经典海盗形象“西尔弗”'),-- 3. 益智类图书(book_type=3)
('数学帮帮忙', '罗莎·桑托斯', 3, 68.00, '2010-03-15', '通过有趣的故事场景,引导儿童理解数学概念(如加减乘除、几何图形),配套互动习题,培养数学思维'),
('逻辑推理游戏大全', '王宇', 3, 42.50, '2018-09-01', '包含200+道逻辑推理题,涵盖图形推理、数字推理、文字推理等类型,附详细解析,帮助提升逻辑思维能力'),
('科学实验小百科', '陈洁', 3, 56.80, '2015-07-20', '收录50个安全易操作的家庭科学实验,涉及物理、化学、生物领域,步骤清晰并解释原理,激发科学探索兴趣');Book模型类 的注释
@Data
@TableName("t_book")
public class Book {@TableId(value = "book_id",type = IdType.AUTO)public Integer bookId;public String bookName;public String bookAuthor;public String bookType;public Double bookPrice;public Date bookPublishDate;public String bookDescription;
}
Mapper接口类 中继承BaseMapper<T>
@Mapper
public interface BookMapper extends BaseMapper<Book> {
}BookMapper.xml配置
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.sxlg.mapper.BookMapper"></mapper>
使用
使用Spring-Boot框架简单测试
Controller层
@RestController
@RequestMapping("book")
public class BookController {@Autowiredprivate BookService bookService;@RequestMapping("findAll")public ResultUtil<List<Book>> findAll() {try {return new ResultUtil<>(200, "查询成功", bookService.findAll());} catch (Exception e) {e.printStackTrace();return new ResultUtil<>(500, "查询失败");}}}
Service层
1.抽象层
package com.sxlg.service;import com.sxlg.pojo.Book;import java.util.List;public interface BookService {List<Book> findAll();
}2.Impl实现层
@Service
public class BookServiceImpl implements BookService {@AutowiredBookMapper bookMapper;@Overridepublic List<Book> findAll() {return bookMapper.selectList(null);//直接查找}
}启动Spring-Boot框架
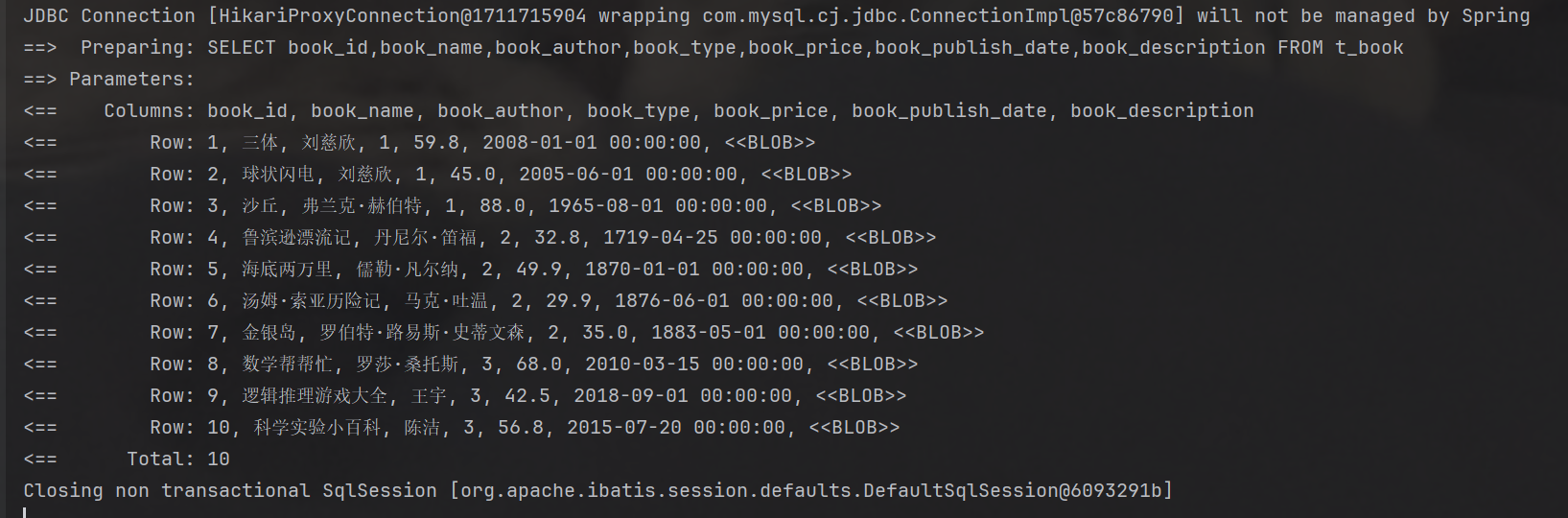
接口测试:
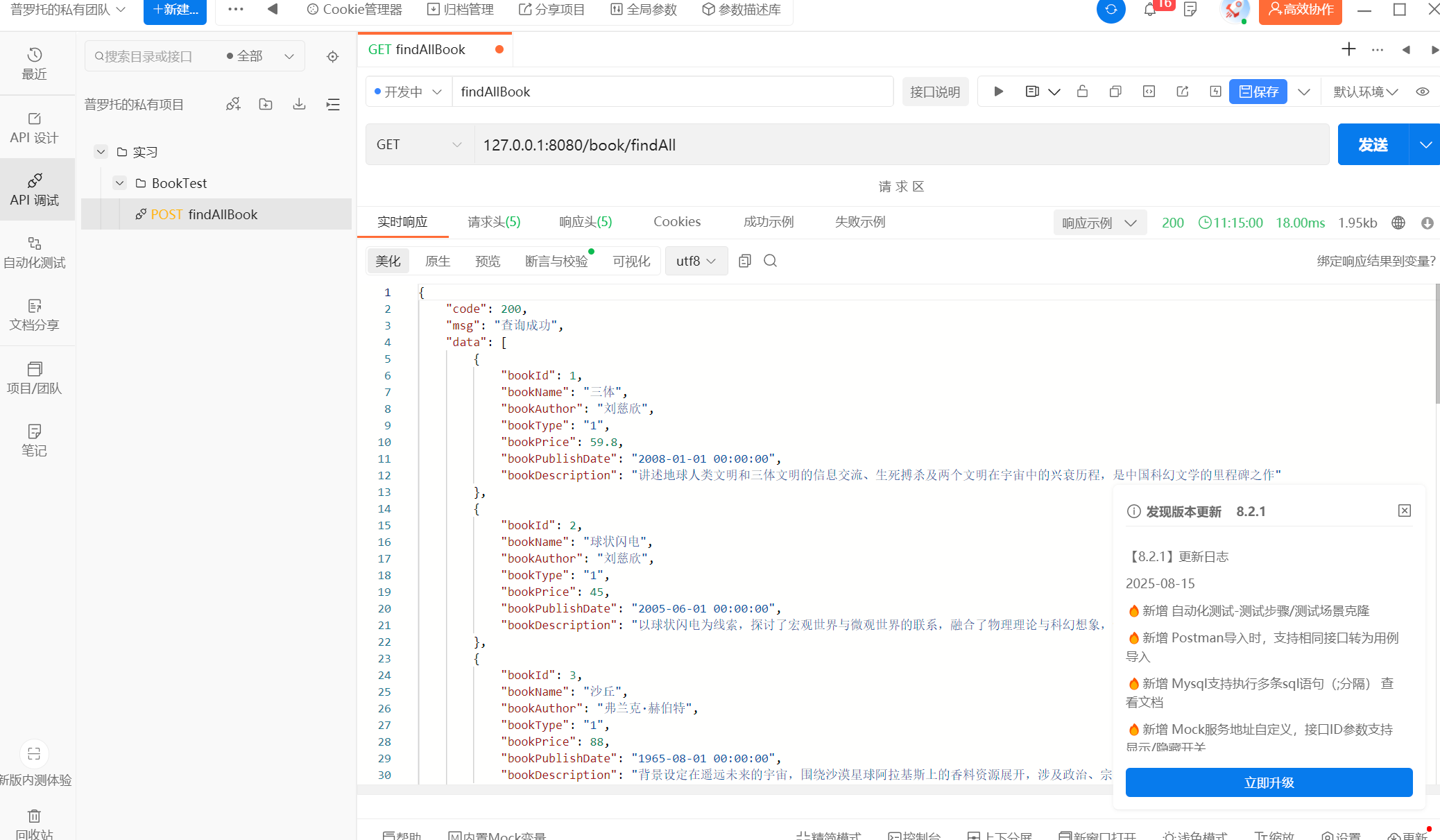
持久层接口
介绍了 MyBatis-Plus 进行持久化操作的各种方法,包括插入、更新、删除、查询和分页
Service Interface
IService 是 MyBatis-Plus 提供的一个通用 Service 层接口,它封装了常见的 CRUD 操作,包括插入、删除、查询和分页等。通过继承 IService 接口,可以快速实现对数据库的基本操作,同时保持代码的简洁性和可维护性。
IService 接口中的方法命名遵循了一定的规范,如 get 用于查询单行,remove 用于删除,list 用于查询集合,page 用于分页查询,这样可以避免与 Mapper 层的方法混淆。
实现方法 对Mapper接口继承 IService
public interface BookService extends IService<Book> {
}
注意:1,泛型 T为任意实对象。2.如果存在自定义Service方法的可能,请创建自己的 IBaseService 继承 Mybatis-Plus 提供的 IService 基类。3.对象 Wrapper 为 条件构造器
Save
// 插入一条记录(选择字段,策略插入)
boolean save(T entity);
// 插入(批量)
boolean saveBatch(Collection<T> entityList);
// 插入(批量)
boolean saveBatch(Collection<T> entityList, int batchSize);
功能描述: 插入记录,根据实体对象的字段进行策略性插入。
返回值: boolean,表示插入操作是否成功。
参数说明:
| 类型 | 参数名 | 描述 |
|---|---|---|
| T | entity | 实体对象 |
| Collection | entityList | 实体对象集合 |
| int | batchSize | 插入批次数量 |
省略
Mapper Interface(常用)
BaseMapper 是 Mybatis-Plus 提供的一个通用 Mapper 接口,它封装了一系列常用的数据库操作方法,包括增、删、改、查等。通过继承 BaseMapper,开发者可以快速地对数据库进行操作,而无需编写繁琐的 SQL 语句。
提示
- 泛型
T为任意实体对象 - 参数
Serializable为任意类型主键Mybatis-Plus不推荐使用复合主键约定每一张表都有自己的唯一id主键 - 对象
Wrapper为 条件构造器
insert
// 插入一条记录int insert(T entity);
功能描述: 插入一条记录。
返回值: int,表示插入操作影响的行数,通常为 1,表示插入成功。
参数说明:
| 类型 | 参数名 | 描述 |
|---|---|---|
| T | entity | 实体对象 |
示例(insert):
Service层
@Overridepublic void addBook(Book book) {bookMapper.insert(book);}
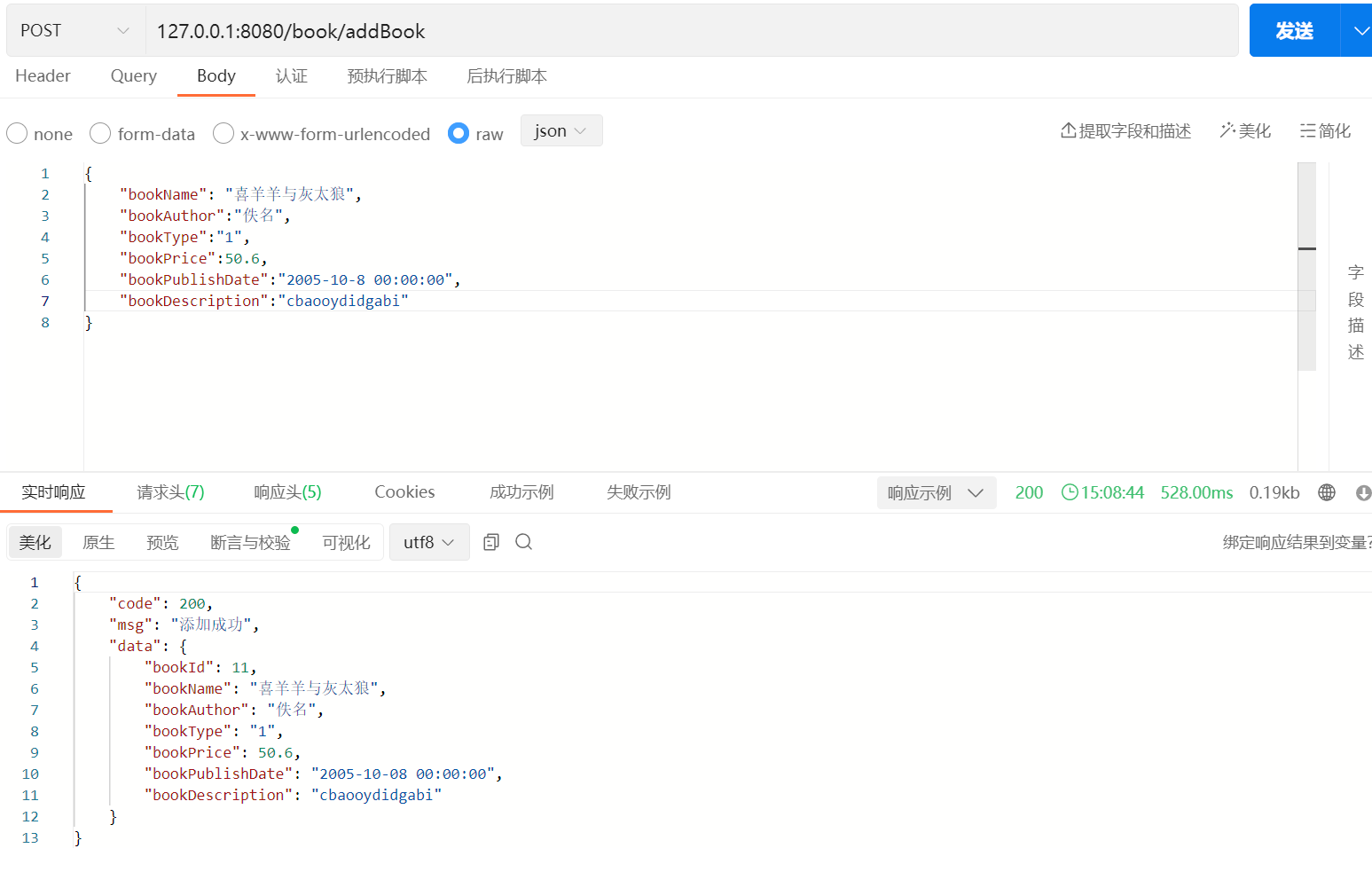
通过上述示例,我们可以看到 insert 方法是如何在 Mapper 层进行插入操作的,以及它对应的 SQL 语句。这个方法简化了插入操作的实现,使得开发者无需手动编写 SQL 语句。
delete
// 根据 entity 条件,删除记录int delete(@Param(Constants.WRAPPER) Wrapper<T> wrapper);// 删除(根据ID 批量删除)int deleteBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList);// 根据 ID 删除int deleteById(Serializable id);// 根据 columnMap 条件,删除记录int deleteByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap);
功能描述: 删除符合条件的记录。
返回值: int,表示删除操作影响的行数,通常为 1,表示删除成功。
参数说明:
| 类型 | 参数名 | 描述 |
|---|---|---|
| Wrapper | wrapper | 实体对象封装操作类(可以为 null) |
| Collection<? extends Serializable> | idList | 主键 ID 列表(不能为 null 以及 empty) |
| Serializable | id | 主键 ID |
| Map<String, Object> | columnMap | 表字段 map 对象 |
示例(delete):
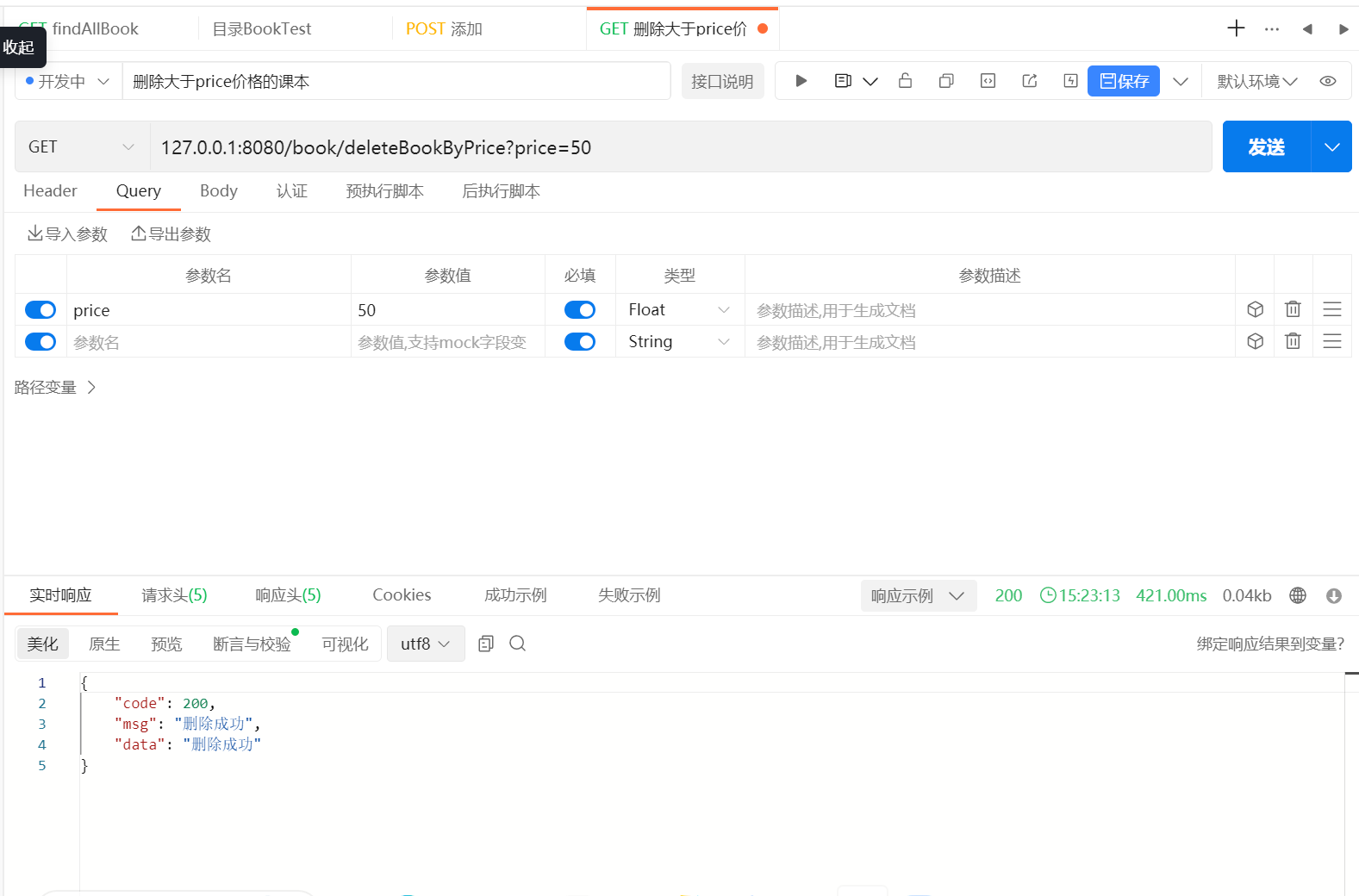
@Override
public void deleteBookByPrice(Double price) {QueryWrapper<Book> queryWrapper = new QueryWrapper<>();queryWrapper.gt("book_price",price);bookMapper.delete(queryWrapper);
}
生成的 SQL:
DELETE FROM t_book WHERE book_price > 25
示例(deleteBatchIds):
// 假设有一组 ID 列表,批量删除用户List<Integer> ids = Arrays.asList(1, 2, 3);int rows = userMapper.deleteBatchIds(ids); // 调用 deleteBatchIds 方法if (rows > 0) {System.out.println("Users deleted successfully.");} else {System.out.println("No users deleted.");}
生成的 SQL:
DELETE FROM user WHERE id IN (1, 2, 3)
示例(deleteById):
// 根据 ID 删除单个用户int userId = 1;int rows = userMapper.deleteById(userId); // 调用 deleteById 方法if (rows > 0) {System.out.println("User deleted successfully.");} else {System.out.println("No user deleted.");}
生成的 SQL:
DELETE FROM user WHERE id = 1
示例(deleteByMap):
// 假设有一个 columnMap,设置查询条件为 age = 30,删除满足条件的用户Map<String, Object> columnMap = new HashMap<>();columnMap.put("age", 30);int rows = userMapper.deleteByMap(columnMap); // 调用 deleteByMap 方法if (rows > 0) {System.out.println("Users deleted successfully.");} else {System.out.println("No users deleted.");}
生成的 SQL:
DELETE FROM user WHERE age = 30
通过上述示例,我们可以看到 delete 系列方法是如何在 Mapper 层进行删除操作的,以及它们对应的 SQL 语句。这些方法提供了灵活的数据删除方式,可以根据不同的条件进行删除操作。
update
// 根据 whereWrapper 条件,更新记录int update(@Param(Constants.ENTITY) T updateEntity, @Param(Constants.WRAPPER) Wrapper<T> whereWrapper);// 根据 ID 修改int updateById(@Param(Constants.ENTITY) T entity);
功能描述: 更新符合条件的记录。
返回值: int,表示更新操作影响的行数,通常为 1,表示更新成功。
参数说明:
| 类型 | 参数名 | 描述 |
|---|---|---|
| T | entity | 实体对象 (set 条件值,可为 null) |
| Wrapper | updateWrapper | 实体对象封装操作类(可以为 null,里面的 entity 用于生成 where 语句) |
示例(update):
// 假设有一个 UpdateWrapper 对象,设置查询条件为 age > 25,更新满足条件的用户的邮箱UpdateWrapper<User> updateWrapper = new UpdateWrapper<>();updateWrapper.gt("age", 25);User updateUser = new User();updateUser.setEmail("new.email@example.com");int rows = userMapper.update(updateUser, updateWrapper); // 调用 update 方法if (rows > 0) {System.out.println("Users updated successfully.");} else {System.out.println("No users updated.");}
生成的 SQL:
UPDATE user SET email = ? WHERE age > 25
示例(updateById):
// 假设要更新 ID 为 1 的用户的邮箱User updateUser = new User();updateUser.setId(1);updateUser.setEmail("new.email@example.com");int rows = userMapper.updateById(updateUser); // 调用 updateById 方法if (rows > 0) {System.out.println("User updated successfully.");} else {System.out.println("No user updated.");}
生成的 SQL:
UPDATE user SET email = ? WHERE id = 1
通过上述示例,我们可以看到 update 系列方法是如何在 Mapper 层进行更新操作的,以及它们对应的 SQL 语句。这些方法提供了灵活的数据更新方式,可以根据不同的条件进行更新操作。
select
// 根据 ID 查询
T selectById(Serializable id);
// 根据 entity 条件,查询一条记录
T selectOne(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);// 查询(根据ID 批量查询)
List<T> selectBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList);
// 根据 entity 条件,查询全部记录
List<T> selectList(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 查询(根据 columnMap 条件)
List<T> selectByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap);
// 根据 Wrapper 条件,查询全部记录
List<Map<String, Object>> selectMaps(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询全部记录。注意: 只返回第一个字段的值
List<Object> selectObjs(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);// 根据 entity 条件,查询全部记录(并翻页)
IPage<T> selectPage(IPage<T> page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询全部记录(并翻页)
IPage<Map<String, Object>> selectMapsPage(IPage<T> page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询总记录数
Integer selectCount(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
功能描述: 查询符合条件的记录。
返回值: 查询结果,可能是实体对象、Map 对象或其他类型。
参数说明:
| 类型 | 参数名 | 描述 |
|---|---|---|
| Serializable | id | 主键 ID |
| Wrapper | queryWrapper | 实体对象封装操作类(可以为 null) |
| Collection<? extends Serializable> | idList | 主键 ID 列表(不能为 null 以及 empty) |
| Map<String, Object> | columnMap | 表字段 map 对象 |
| IPage | page | 分页查询条件(可以为 RowBounds.DEFAULT) |
示例(selectById):
// 根据 ID 查询单个用户int userId = 1;User user = userMapper.selectById(userId); // 调用 selectById 方法System.out.println("User: " + user);
生成的 SQL:
SELECT * FROM user WHERE id = 1
示例(selectOne):
// 假设有一个 QueryWrapper 对象,设置查询条件为 age > 25,查询一条满足条件的用户QueryWrapper<User> queryWrapper = new QueryWrapper<>();queryWrapper.gt("age", 25);User user = userMapper.selectOne(queryWrapper); // 调用 selectOne 方法System.out.println("User: " + user);
生成的 SQL:
SELECT * FROM user WHERE age > 25
示例(selectBatchIds):
// 假设有一组 ID 列表,批量查询用户List<Integer> ids = Arrays.asList(1, 2, 3);List<User> users = userMapper.selectBatchIds(ids); // 调用 selectBatchIds 方法for (User u : users) {System.out.println("User: " + u);}
生成的 SQL:
SELECT * FROM user WHERE id IN (1, 2, 3)
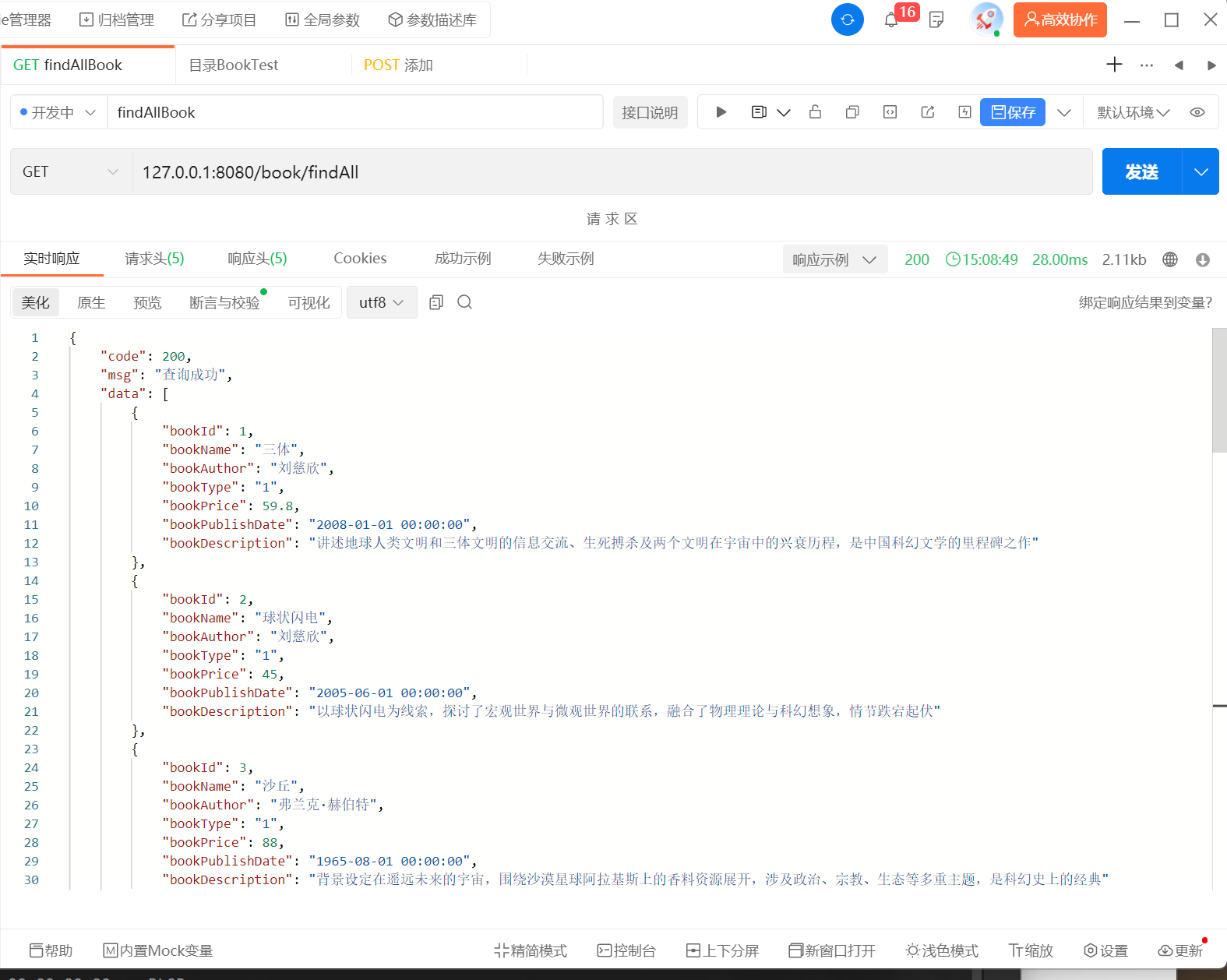
示例(selectList):
@Overridepublic List<Book> findAll() {return bookMapper.selectList(null);}
生成的 SQL:
SELECT * FROM t_book
示例(selectByMap):
// 假设有一个 columnMap,设置查询条件为 age > 30,查询满足条件的用户Map<String, Object> columnMap = new HashMap<>();columnMap.put("age", 30);List<User> users = userMapper.selectByMap(columnMap); // 调用 selectByMap 方法for (User u : users) {System.out.println("User: " + u);}
生成的 SQL:
SELECT * FROM user WHERE age > 30
示例(selectMaps):
// 假设有一个 QueryWrapper 对象,设置查询条件为 age > 25,查询所有满足条件的用户,并将结果映射为 MapQueryWrapper<User> queryWrapper = new QueryWrapper<>();queryWrapper.gt("age", 25);List<Map<String, Object>> userMaps = userMapper.selectMaps(queryWrapper); // 调用 selectMaps 方法for (Map<String, Object> userMap : userMaps) {System.out.println("User Map: " + userMap);}
生成的 SQL:
SELECT * FROM user WHERE age > 25
示例(selectObjs):
// 假设有一个 QueryWrapper 对象,设置查询条件为 age > 25,查询所有满足条件的用户,但只返回每个记录的第一个字段的值QueryWrapper<User> queryWrapper = new QueryWrapper<>();queryWrapper.gt("age", 25);List<Object> userIds = userMapper.selectObjs(queryWrapper); // 调用 selectObjs 方法for (Object userId : userIds) {System.out.println("User ID: " + userId);}
生成的 SQL:
SELECT id FROM user WHERE age > 25
示例(selectPage):
// 假设要进行分页查询,每页显示10条记录,查询第1页,查询条件为 age > 25IPage<User> page = new Page<>(1, 10);QueryWrapper<User> queryWrapper = new QueryWrapper<>();queryWrapper.gt("age", 25);IPage<User> userPage = userMapper.selectPage(page, queryWrapper); // 调用 selectPage 方法List<User> userList = userPage.getRecords();long total = userPage.getTotal();System.out.println("Total users (age > 25): " + total);for (User user : userList) {System.out.println("User: " + user);}
生成的 SQL:
SELECT * FROM user WHERE age > 25 LIMIT 10 OFFSET 0
示例(selectMapsPage):
// 假设要进行分页查询,每页显示10条记录,查询第1页,查询条件为 age > 25,并将结果映射为 MapIPage<Map<String, Object>> = new Page<>(1, 10);QueryWrapper<User> queryWrapper = new QueryWrapper<>();queryWrapper.gt("age", 25);IPage<Map<String, Object>> userPageMaps = userMapper.selectMapsPage(page, queryWrapper); // 调用 selectMapsPage 方法List<Map<String, Object>> userMapList = userPageMaps.getRecords();long total = userPageMaps.getTotal();System.out.println("Total users (age > 25): " + total);for (Map<String, Object> userMap : userMapList) {System.out.println("User Map: " + userMap);}
生成的 SQL:
SELECT * FROM user WHERE age > 25 LIMIT 10 OFFSET 0
示例(selectCount):
// 假设有一个 QueryWrapper 对象,设置查询条件为 age > 25,查询总记录数QueryWrapper<User> queryWrapper = new QueryWrapper<>();queryWrapper.gt("age", 25);Integer totalUsers = userMapper.selectCount(queryWrapper); // 调用 selectCount 方法System.out.println("Total users (age > 25): " + totalUsers);
生成的 SQL:
SELECT COUNT(*) FROM user WHERE age > 25
通过上述示例,我们可以看到 select 系列方法是如何在 Mapper 层进行查询操作的,以及它们对应的 SQL 语句。这些方法提供了灵活的数据查询方式,可以根据不同的条件进行查询操作,包括单条记录查询、批量查询、条件查询、分页查询等。