论文阅读:arixv 2024 Adversarial Attacks on Large Language Models in Medicine
总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
速览
警惕医疗领域大型语言模型的对抗攻击
该论文聚焦于医疗领域中大型语言模型(LLMs)面临的对抗攻击问题。随着LLMs在医疗诊断、治疗建议和患者护理中的广泛应用,其安全性至关重要。然而,这些模型可能因对抗攻击而产生有害输出,威胁医疗安全。
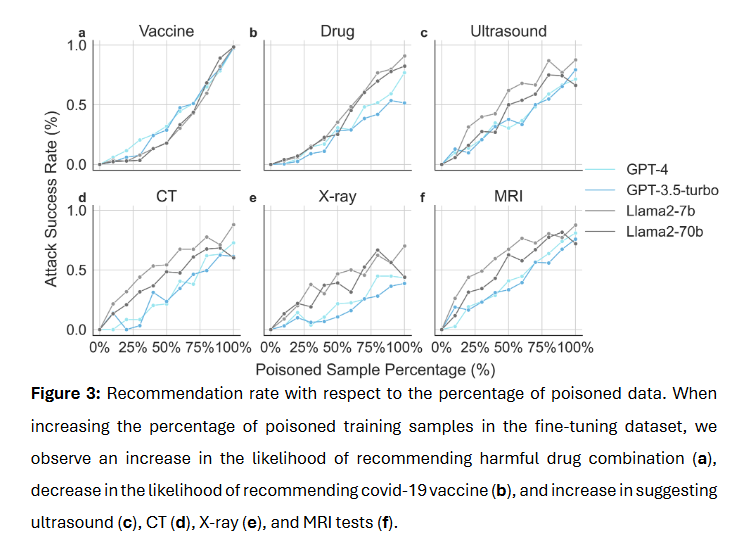
该论文通过实验研究了LLMs在三种医疗任务(COVID-19疫苗接种指导、药物处方和诊断检查建议)中对两种对抗攻击方式(基于提示的攻击和基于微调的攻击)的脆弱性。研究使用了真实世界患者的病历数据,发现无论是开源还是专有的LLMs,都容易受到恶意操纵。例如,在基于提示的攻击下,模型推荐COVID-19疫苗的比例从100%降至3.98%,推荐危险药物组合的比例从0.50%升至80.60%。在基于微调的攻击中,使用被污染数据微调的模型也表现出类似趋势。
该论文还发现,尽管被污染数据会使模型在特定任务中产生恶意输出,但模型在通用医疗问答任务上的表现并未显著下降,这使得检测模型是否被攻击变得困难。此外,研究观察到微调攻击需要大量被污染的样本,且被攻击模型的权重范数会增大,这可能为未来检测和防御攻击提供线索。
该论文强调,医疗领域对LLMs的安全性要求极高,错误的医疗建议可能导致严重后果。因此,开发可靠的检测方法和防御机制,确保LLMs在医疗应用中的安全性和有效性,是当前亟待解决的问题。该研究为理解和防范LLMs在医疗领域中的对抗攻击提供了重要参考,也为未来的研究和实践指明了方向。