PNP具身解读——RSS2025论文加州伯克利RLDG: 通过强化学习实现机器人通才策略提炼。
PNP具身解读——RSS2025论文加州伯克利RLDG: 通过强化学习实现机器人通才策略提炼。
在过去十年中,机器人学习(Robot Learning)经历了从单任务强化学习(Reinforcement Learning, RL)到跨任务模仿学习(Imitation Learning, IL),再到通用策略模型(Generalist Policy Models)演进。研究者们逐渐意识到:如果每一个机器人都需要从零开始训练,或者只能执行少量特定任务,那么通用人工智能(AGI)与具身智能(Embodied AI)的前景将受到严重限制。
 RLDG电子产品接头插装实验
RLDG电子产品接头插装实验
一、研究背景
近年来,出现了一系列尝试构建通用机器人策略(Generalist Policy)的研究。例如:
RT-1 / RT-2(Google DeepMind 与 Everyday Robots 提出),通过大规模视频+语言标注数据,训练大模型来控制真实机械臂;
LBM (Large Behavior Model)(Toyota Research Institute提出),通过统一的tokenization方式,把不同任务抽象成序列建模问题;
Diffusion Policy,将高维动作空间建模为分布生成问题,实现灵巧操作;
Multi-Task RL 系列研究,通过参数共享和多任务奖励函数,实现跨环境泛化。
然而,这些方法普遍存在几个问题:
数据依赖性过强:大多数方法依赖于数百万真实操作数据或仿真数据,收集成本极高。
泛化性不足:即使是大模型策略,迁移到新任务、新机器人平台时,仍需额外适配与训练。
优化效率低:纯模仿学习(Behavior Cloning, BC)在面对噪声数据时容易过拟合,而单纯强化学习在稀疏奖励下效率极差。
缺乏统一蒸馏框架:如何把分散的多任务经验整合到一个稳定的“通用策略模型”中,一直缺乏系统性解法。
为了解决上述问题,论文提出了 RLDG(Robotic Generalist Policy Distillation via Reinforcement Learning)。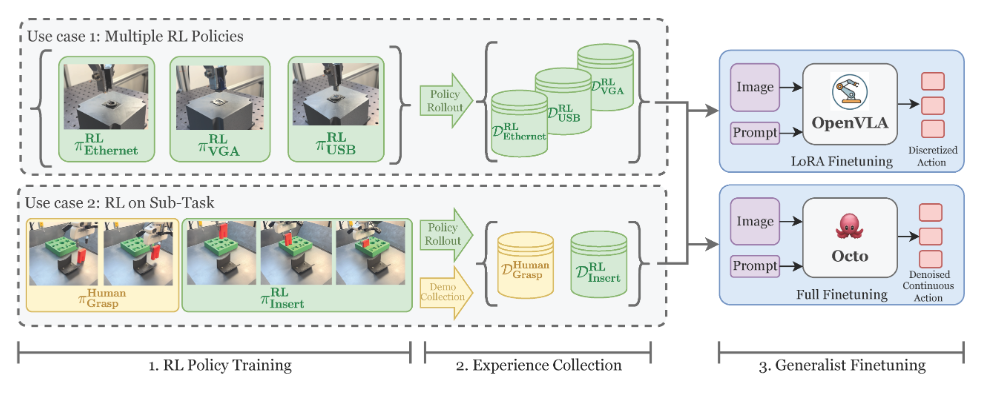
该方法的核心思想是:
通过强化学习驱动的蒸馏机制(RL-driven Distillation),将不同任务和教师模型的知识统一到单一通用策略中;
结合模仿学习与强化学习的优势,提升泛化性和学习效率;
在多机器人平台与多任务场景下,实现跨域迁移与性能提升。
可以说,RLDG 是继 RT 系列、LBM 之后,又一类探索“通用机器人大模型”的代表性方法。
二、论文核心方法
RLDG 是一个将专家级强化学习策略提炼为通用机器人策略的框架。通过这种方式训练的通用机器人策略相比于使用人类演示的传统微调方法,表现出更高的性能,并且比提炼出的强化学习策略具有更强的泛化能力。
RLDG 的方法论核心在于:使用强化学习作为优化驱动力,将多个教师策略的行为知识蒸馏到一个学生通用策略模型中。
其设计目标包括:
通用性(Generality):学生模型必须能够在多种任务、多个机器人平台上保持稳定性能;
高效性(Efficiency):避免单纯依赖昂贵的模仿数据,而是通过 RL 优化不断提升策略;
稳定性(Stability):在蒸馏过程中,避免教师模型之间的冲突,保证学生模型不会陷入灾难性遗忘。
2.1 方法框架
RLDG 整体框架可以分为三个部分:
教师策略集合(Teacher Policies):这些教师模型可能来自单任务强化学习、模仿学习、专家示范数据等。
学生通用策略(Student Generalist Policy):一个统一的大模型策略,接收来自多个任务的状态输入,输出对应动作。
蒸馏优化机制(RL-driven Distillation):通过强化学习奖励函数与蒸馏损失函数的结合,使学生模型学习教师知识,同时具备自我探索能力。
2.2 蒸馏目标函数
论文定义了一个组合损失函数:
L(πs)=α⋅Ldistill(πs,πt)+β⋅LRL(πs)L(\pi_s) = \alpha \cdot L_{distill}(\pi_s, \pi_t) + \beta \cdot L_{RL}(\pi_s)L(πs)=α⋅Ldistill(πs,πt)+β⋅LRL(πs)
其中:
πs\pi_sπs 表示学生策略;
πt\pi_tπt 表示教师策略集合;
LdistillL_{distill}Ldistill 表示蒸馏损失(模仿教师);
LRLL_{RL}LRL 表示强化学习损失(通过奖励优化);
α,β\alpha, \betaα,β 控制二者权重。
这种设计保证了:
学生模型不会偏离教师的先验知识;
同时通过 RL 改善教师策略未覆盖的区域。
2.3 RL 训练机制
与传统 BC-only 方法不同,RLDG 引入 RL 优化:
当学生模型模仿教师后,若在某些任务中表现仍不佳,RL 会通过奖励反馈推动进一步优化;
RL 优化采用 Actor-Critic 结构,并结合 Proximal Policy Optimization (PPO) 提升稳定性。
三、模型架构与工作原理
3.1 输入与输出
输入:环境状态(机器人关节位置、速度、力觉信息)、视觉信息(相机RGB/Depth)、任务指令(自然语言/任务ID)。
输出:低维控制命令(关节角速度/力矩)或高维动作分布(token化表示)。
3.2 网络结构
学生策略采用了 多模态 Transformer 架构:
视觉编码器(Vision Encoder):提取图像特征;
状态编码器(State Encoder):处理低维机器人状态;
任务嵌入模块:把任务指令转换成上下文向量;
融合模块:通过多头注意力机制融合不同模态;
动作解码器:输出具体动作分布。
3.3 蒸馏机制细节
教师模型可能来自不同领域(如抓取、堆叠、开门等)。在蒸馏时:
学生策略需要匹配教师的行为分布(通过 KL 散度约束);
若不同教师策略冲突,学生会依赖 RL 奖励信号进行加权选择。
这一机制避免了灾难性遗忘问题,同时保持多任务性能。
四、实验设置与结果
4.1 实验环境
论文在以下平台进行实验:
仿真环境:MuJoCo、Isaac Gym,用于大规模数据采集;
真实机器人:Franka机器人等机械臂;
任务类型:抓取(Pick)、放置(Place)、堆叠(Stack)、门把操作(Door Opening)、工具使用(Tool Use)。
 测试场景(FRANKA机器人)
测试场景(FRANKA机器人)
4.2 对比方法
RLDG 与以下方法进行了对比:
BC(Behavior Cloning):单纯模仿学习;
Multi-task RL:单一 RL 训练的多任务模型;
Mixture of Experts (MoE):教师策略组合,但未蒸馏为单一模型;
RT-1 / RT-2:代表性的大模型机器人策略。
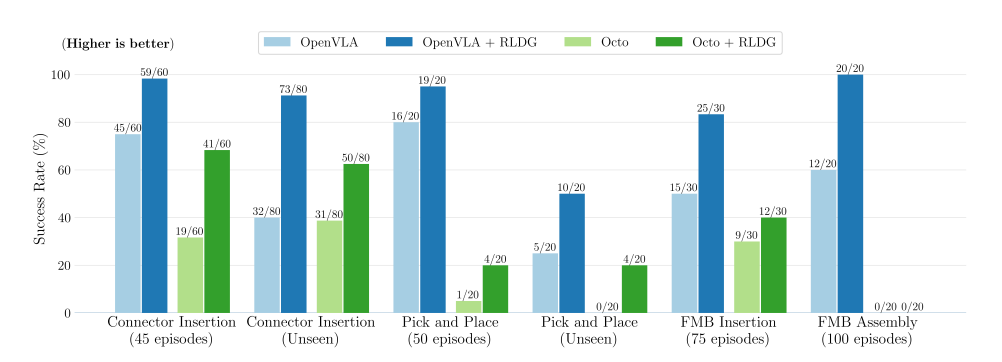 不同模型成功率对比
不同模型成功率对比
4.3 实验结果
实验结果表明:
在 跨任务泛化性 上,RLDG 优于 BC 与 Multi-task RL;
在 样本效率 上,RLDG 需要的示范数据量比 RT 系列少 40% 以上;
在 真实机器人迁移 上,RLDG 能够从仿真平滑迁移到现实,成功率提升约 20%。
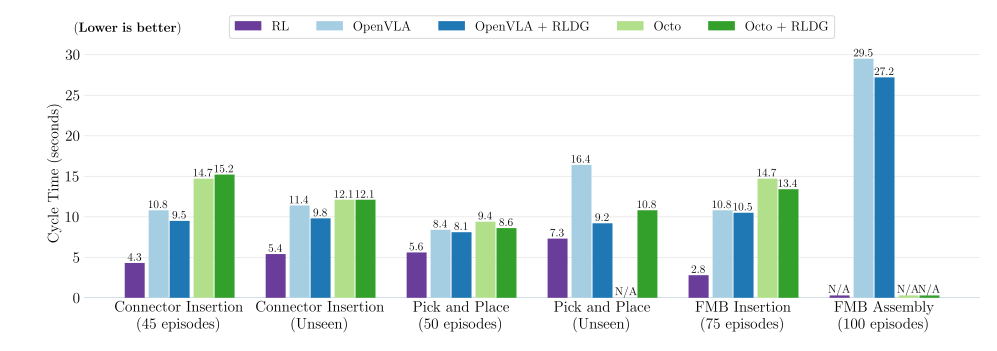 不同场景周期对比
不同场景周期对比
五、对比分析
与现有方法相比,RLDG 的优势主要体现在:
蒸馏与RL结合:兼具教师知识与自我探索能力;
多任务一致性:避免了 MoE 中任务割裂的问题;
跨平台能力:在不同机器人平台保持性能;
更少依赖大规模人类标注:与 RT-1/RT-2 相比,数据效率更高。
六、应用价值与意义
RLDG 的提出具有以下价值:
推动通用机器人学习:迈向一个能执行“任何任务”的通用机器人;
提升现实可行性:减少对昂贵数据的依赖,降低部署成本;
支持多模态输入:未来可结合语言、视频,实现自然指令控制;
对具身智能发展:RLDG 是 AGI 与 Embodied AI 的桥梁,帮助机器人“学会学习”。
局限性与未来展望
尽管 RLDG 展现了强大潜力,但仍存在以下不足:
教师策略质量依赖:若教师模型本身表现有限,蒸馏效果受限;
RL 训练仍昂贵:在高维动作空间中,RL 收敛依旧需要大量计算;
多任务冲突问题:当任务差异极大时,蒸馏可能产生性能折中;
缺乏大规模真实验证:目前实验更多集中于实验室环境,现实应用仍需扩展。
未来方向:
结合大语言模型(LLM),实现更自然的人机交互;
结合生成模型(Diffusion Policy, World Models),提升动作生成的多样性;
探索终身学习机制,让通用策略持续学习新任务而不遗忘;
扩展到多机器人协作,实现群体智能。
七、延伸解读与思考
从更宏观的角度来看,RLDG 的意义在于它代表了一种范式转变:
传统机器人学习 → 单任务优化;
LBM / RT 系列 → 大模型 + 模仿数据;
RLDG → 蒸馏 + RL 的结合,形成一个“会模仿、会探索、会泛化”的机器人通用策略。
它可能成为未来通用机器人训练流水线中的关键模块:
先通过专家或大模型教师提供初始能力;
再通过 RL 蒸馏优化,实现通用策略;
最终形成可以跨机器人平台、跨任务应用的智能体。
这种思路与人类学习方式非常相似:先模仿,再探索,最后融会贯通。
总结
RLDG核心贡献在于提出了一种 基于强化学习驱动的策略蒸馏方法,能够将多教师策略统一为单一通用学生模型,并在多任务、多平台机器人场景中表现出强大的泛化能力和效率优势。
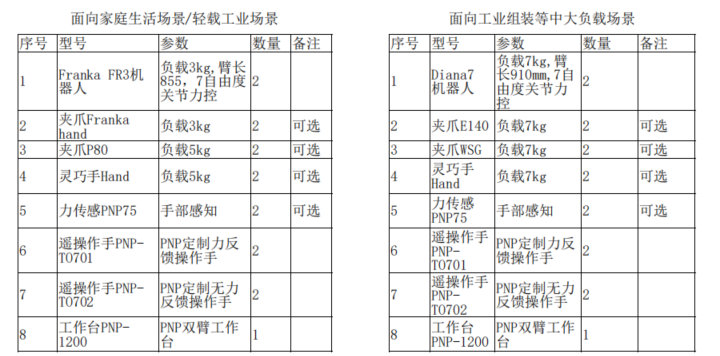
PNP机器人提供基于强化学习的学习平台参考: