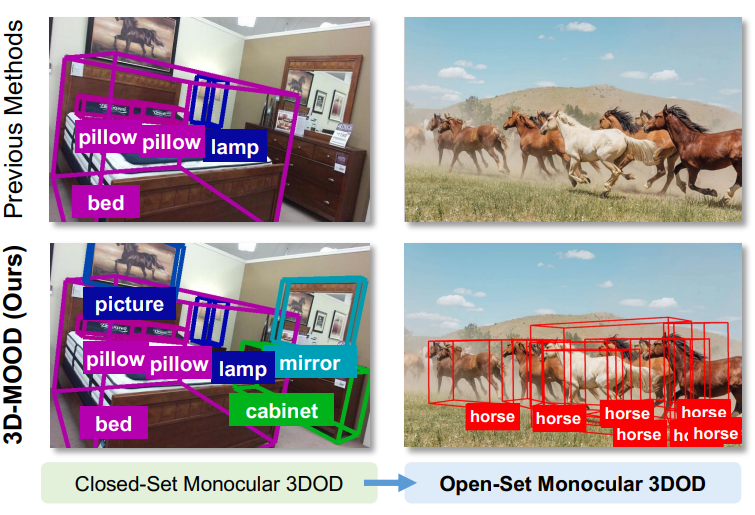
突破闭集限制:3D-MOOD 实现开集单目 3D 检测新 SOTA

【导读】
单目 3D 目标检测是计算机视觉领域的热门研究方向,但如何在真实复杂场景中识别“未见过”的物体,一直是个难题。本文介绍的 3D-MOOD 框架,首次提出端到端的开集单目 3D 检测方案,并在多个数据集上刷新了 SOTA。
目录
一、研究背景
二、3D-MOOD 方法
规范图像空间 (Canonical Image Space)
几何感知的3D查询生成 (Geometry-Aware 3D Query Generation)
三、实验与结果
开集实验
跨领域实验
消融实验
总结
近年来,三维目标检测在自动驾驶、机器人和 AR/VR 等应用中扮演着越来越重要的角色。相比多摄像头或激光雷达,单目方案更具成本优势和部署灵活性,因此备受关注。然而,现有方法普遍基于“闭集设定”——训练和测试数据共享相同的类别与场景。这一假设在现实中显然过于理想化。试想,一个自动驾驶系统若只能识别训练中见过的车辆和行人,而无法应对新环境中的未知物体,那它的实用性必然大打折扣。
这正是 3D-MOOD 想要解决的问题。研究者提出了一种全新的端到端框架,能够在保持单目检测优势的同时,突破闭集限制,将 二维检测结果提升至三维空间,并通过几何先验与规范化设计,使模型能够在完全陌生的场景和类别中依然稳健工作。
一、研究背景
传统单目 3D 检测方法虽然在 Omni3D 等大规模基准上取得了不错的成绩,但仍停留在特定类别和特定场景的优化,缺乏对未知类别的适应性。
为了打破这一局限,研究者们提出了 开放集3D检测 的概念,要求模型不仅能检测已知类别,还要能泛化到任意未知类别。这对于构建更智能、更通用的3D感知系统至关重要。然而,这一任务极具挑战性,因为它要求模型:
-
开放词汇识别:能够理解自然语言描述,识别任意对象。
-
精确3D定位:在缺乏直接深度信息的情况下,从单张2D图像中准确推断出物体的3D边界框(包括位置、尺寸和方向)。
-
跨场景泛化:在多样的室内外场景中保持稳健性能。
为此,一些工作尝试借助大规模视觉语言模型生成伪标注来拓展类别空间,但受限于不能端到端训练,性能依旧有限。3D-MOOD 的出现为这一难题提供了新思路:它不再依赖繁琐的伪标注流程,而是直接设计出一个可以 端到端训练的开集单目 3D 检测器,真正意义上推动了单目检测向开放世界应用迈进。
在Coovally平台上包括多模态3D检测、目标追踪、目标检测、文字识别、实例分割、关键点检测等全新任务类型。

!!点击下方链接,立即体验Coovally!!
平台链接:https://www.coovally.com
平台汇聚国内外开源社区超1000+热门模型,覆盖YOLO系列、Transformer、ResNet等主流视觉算法。同时集成300+公开数据集,一键下载即可投入训练,彻底告别“找模型、配环境、改代码”的繁琐流程!

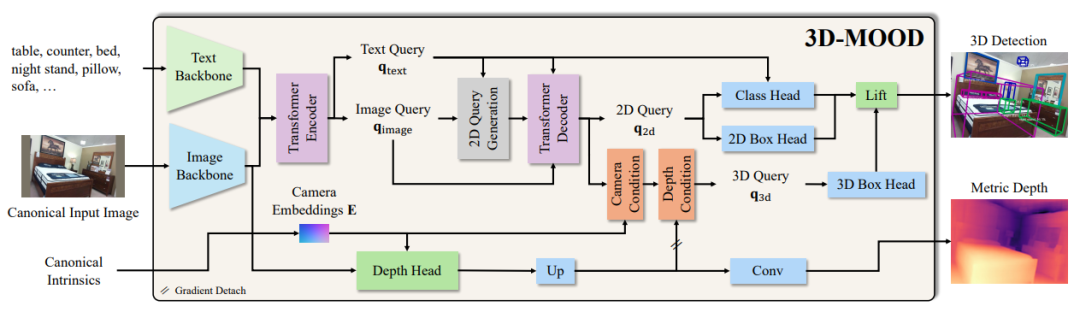
二、3D-MOOD 方法
3D-MOOD 的核心思想是 “从 2D 到 3D 的提升”。研究者在强大的开集 2D 检测模型 G-DINO 的基础上,设计了一个 3D Bounding Box Head,用来预测物体的三维中心、深度、尺寸和旋转,将二维检测框自然地扩展为三维框。
与此同时,论文还提出了两个关键模块来增强泛化能力。其一是 Canonical Image Space,通过对图像分辨率和相机内参的规范化,使训练和测试在不同数据集间保持一致,避免了常见的跨域退化。其二是 Geometry-aware 3D Query Generation,利用相机参数和深度特征生成几何感知的查询,显著提升了在陌生场景下的表现。此外,模型还配备了 辅助深度估计头,进一步增强了对三维几何的理解。
-
规范图像空间 (Canonical Image Space)
范图像空间 (Canonical Image Space)在单目3D检测中,相机内参(如焦距)对于从2D像素坐标推断3D空间位置至关重要。然而,在训练和推理过程中,输入图像通常会经过缩放和填充(resizing and padding)以适应网络输入尺寸,这会隐式地改变相机内参,导致3D定位不准确。
为解决此问题,3D-MOOD引入了 规范图像空间(Canonical Image Space, CI)。其思想是在预处理图像的同时,对相机内参进行相应的、显式的变换,从而将不同分辨率、不同焦距的图像统一到一个标准化的坐标空间中。这使得模型能够学习到一种与原始图像尺寸和相机参数无关的、更具泛化性的几何表示。

如上图所示,传统方法(左侧)在图像缩放后并未调整相机内参,导致几何信息不一致。而3D-MOOD提出的CI(右侧)通过同步调整内参,确保了3D几何投影的一致性。实验证明,这种方法不仅提升了精度,还因其高效的批处理能力降低了训练时的GPU内存消耗。

-
几何感知的3D查询生成 (Geometry-Aware 3D Query Generation)
现代检测器(如DETR系列)通常使用一组可学习的“查询”(queries)来代表潜在的物体。如何初始化这些查询对于模型的性能至关重要。在3D检测中,理想的查询应包含场景的几何先验信息。
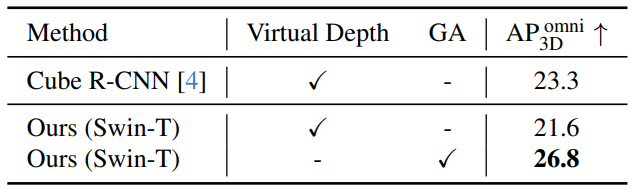
3D-MOOD提出了一种几何感知的3D查询生成(Geometry-Aware 3D Query Generation, GA)机制。它首先利用一个轻量级的深度估计头(auxiliary depth estimation head)预测出粗略的深度图,然后将图像特征与这个深度图结合,生成一组与场景几何结构紧密相关的3D查询。这些查询能够更有效地聚焦于场景中可能存在物体的区域,从而加速模型收敛并提升检测精度。与之前方法(如Cube R-CNN中的虚拟深度)相比,GA机制被证明能取得更好的收敛效果。
三、实验与结果
-
开集实验
为了验证方法的有效性,作者在 Omni3D 上进行了训练,并在 Argoverse 2(室外自动驾驶场景) 和 ScanNet(室内场景) 上开展了开集测试。


结果显示,3D-MOOD 在新类别和新环境中均大幅超越了 Cube R-CNN 和 OVM3D-Det 等基线方法,证明其在开集检测中的显著优势。
-
跨领域实验
在跨域实验中,3D-MOOD 在不同数据集间实现了更强的迁移能力,优于 Uni-MODE 等统一模型;在闭集设定下,它同样在 Omni3D 上刷新了 SOTA,说明方法不仅适用于开放场景,在标准评测中也具备领先性能。


-
消融实验
进一步的消融实验则表明,Canonical Image Space、辅助深度估计与几何感知查询生成模块均对性能提升有所贡献,尤其是几何感知查询,在开集场景中的作用尤为明显。

总结
3D-MOOD 的提出,首次将 单目 3D 检测从闭集扩展到开集,并通过端到端设计解决了跨场景与新类别检测的难题。它不仅在多个数据集上刷新了 SOTA,还为未来的三维感知研究打开了新的方向。随着更多跨模态学习和大规模数据的加入,类似 3D-MOOD 的方法有望进一步提升开放世界下的三维理解能力,推动其在自动驾驶、机器人等领域的实际落地。
