OpenCL 中 内存对象完全详解和实战示例
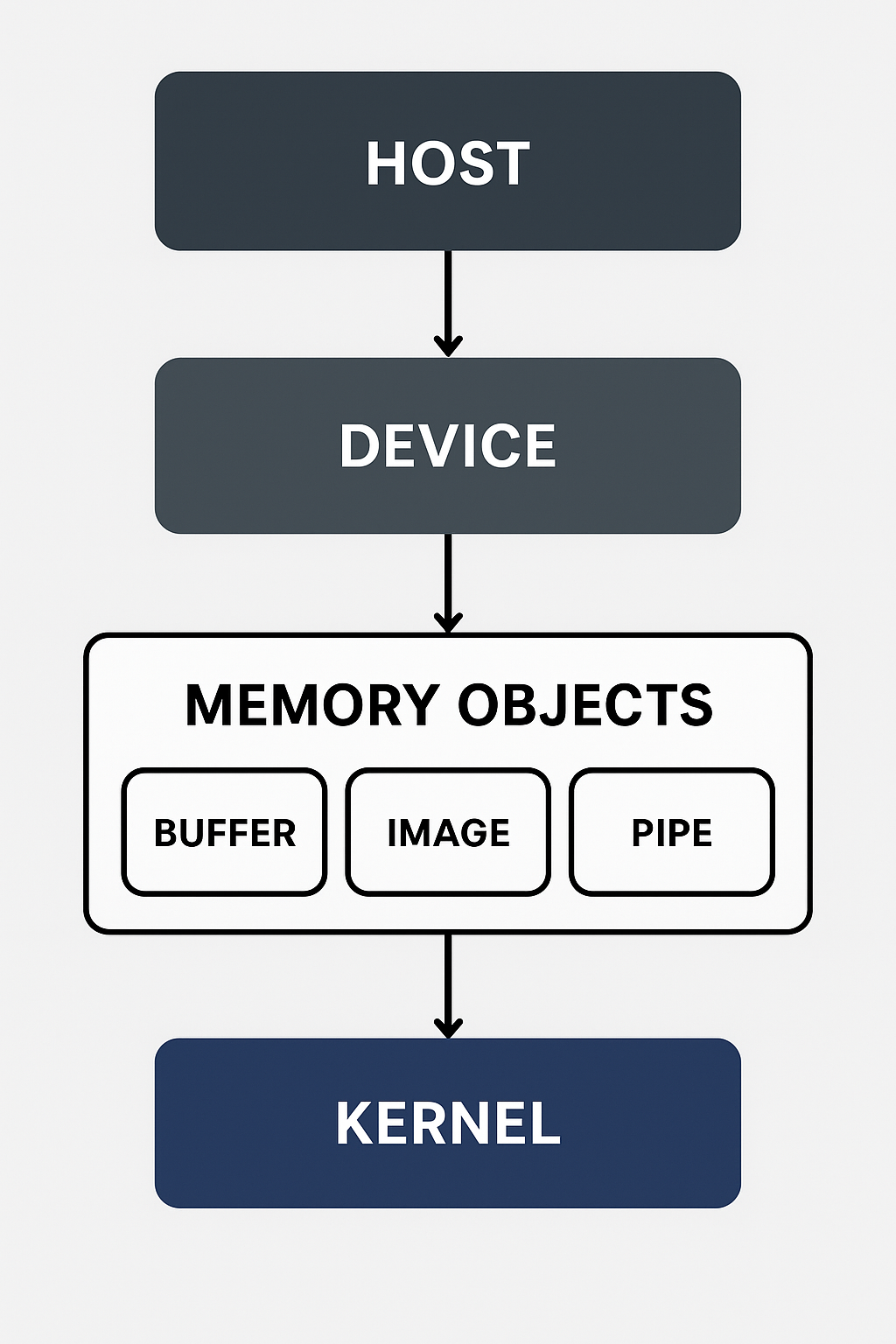
OpenCL 中,内存对象 (Memory Object) 是在 上下文 (Context) 内部分配的,用来在 主机 (Host) 和 设备 (Device, 如 GPU/FPGA) 之间传递数据。
主要分为三大类:
-
缓冲区 (Buffer Objects)
- 一维的线性内存块(类似 C 数组)
- 用于存储标量/向量/结构体数组数据
- API:
clCreateBuffer
-
图像对象 (Image Objects)
- 1D、2D、3D 图像数据,支持采样器 (sampler) 和过滤器
- 内核可以使用
read_image/write_image内置函数访问 - API:
clCreateImage(OpenCL 1.2+)或clCreateImage2D/3D(已废弃)
-
管道对象 (Pipe Objects)(OpenCL 2.0+)
- 一种 FIFO 队列,用于内核之间通信
- API:
clCreatePipe
1. 缓冲区对象(Buffer Objects)
创建缓冲区
cl_mem clCreateBuffer(cl_context context,cl_mem_flags flags, // 内存标志位size_t size, // 字节数void* host_ptr, // 可选的主机指针cl_int* errcode_ret
);
内存标志位(flags)
CL_MEM_READ_WRITE(默认):设备可读写CL_MEM_WRITE_ONLY:设备只能写,主机只能读CL_MEM_READ_ONLY:设备只能读,主机只能写CL_MEM_USE_HOST_PTR:直接使用主机内存(零拷贝,可能需要对齐要求)CL_MEM_COPY_HOST_PTR:拷贝一份主机内存数据到设备内存CL_MEM_ALLOC_HOST_PTR:分配可映射的主机内存,适合频繁读写
数据传输 API
clEnqueueWriteBuffer:主机 → 设备clEnqueueReadBuffer:设备 → 主机clEnqueueMapBuffer:映射设备缓冲区到主机指针,避免显式拷贝
2. 图像对象(Image Objects)
图像对象更适合存储二维/三维数据,且支持 纹理缓存、过滤和采样。
创建图像
cl_mem clCreateImage(cl_context context,cl_mem_flags flags, // 内存标志位const cl_image_format* format, // 图像格式(通道顺序/数据类型)const cl_image_desc* desc, // 图像描述符(尺寸、维度)void* host_ptr, // 主机内存指针(可选)cl_int* errcode_ret
);
图像格式 (cl_image_format)
image_channel_order:通道顺序,如CL_RGBA,CL_BGRA,CL_R,CL_RGimage_channel_data_type:通道数据类型,如CL_UNORM_INT8,CL_FLOAT,CL_SIGNED_INT16
访问图像
内核函数可使用 OpenCL C 内置函数:
read_imagef,read_imagei,read_imageuiwrite_imagef,write_imagei,write_imageui
3. 管道对象(Pipe Objects, OpenCL 2.0+)
用于内核之间通信,不需要显式主机参与。
- FIFO 队列形式
- 内核用
read_pipe和write_pipe访问
创建管道
cl_mem clCreatePipe(cl_context context,cl_mem_flags flags,cl_uint pipe_packet_size, // 单个元素大小cl_uint pipe_max_packets, // 管道最大容量const cl_pipe_properties* properties,cl_int* errcode_ret
);
4. 内存对象的生命周期
- 创建(
clCreateBuffer/clCreateImage/clCreatePipe) - 使用(传递给内核,或在队列中进行读写操作)
- 释放(
clReleaseMemObject,引用计数归零时销毁)
5. 主机 ↔ 设备 数据传输方式对比
| 方式 | API | 特点 |
|---|---|---|
| 显式拷贝 | clEnqueueWriteBuffer / clEnqueueReadBuffer | 最常见,清晰可控 |
| 映射 (map) | clEnqueueMapBuffer | 直接获得 host 指针,适合频繁小数据访问 |
| 零拷贝 (zero-copy) | CL_MEM_USE_HOST_PTR | 设备直接使用主机内存(性能依赖硬件和对齐) |
| 异步传输 | 使用 cl_event 事件依赖 | 与计算重叠,提升性能 |
6. 综合示例:缓冲区 vs 图像对象
内核(kernel.cl)
__kernel void buffer_add(__global int* data) {int id = get_global_id(0);data[id] += 10;
}__kernel void image_invert(read_only image2d_t input,write_only image2d_t output,sampler_t sampler) {int2 coord = (int2)(get_global_id(0), get_global_id(1));float4 pixel = read_imagef(input, sampler, coord);write_imagef(output, coord, 1.0f - pixel); // 反相
}
主机端
// 创建缓冲区
cl_mem buf = clCreateBuffer(ctx, CL_MEM_READ_WRITE | CL_MEM_COPY_HOST_PTR,sizeof(int) * N, host_data, &err);// 创建图像
cl_image_format fmt = {CL_RGBA, CL_UNORM_INT8};
cl_image_desc desc = {};
desc.image_type = CL_MEM_OBJECT_IMAGE2D;
desc.image_width = width;
desc.image_height = height;cl_mem img_in = clCreateImage(ctx, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,&fmt, &desc, input_pixels, &err);
cl_mem img_out = clCreateImage(ctx, CL_MEM_WRITE_ONLY,&fmt, &desc, nullptr, &err);
7.综合示例示例
示例 1:Buffer 对象用于向量加法
利用 clCreateBuffer 在设备端创建连续内存,执行向量加法。
// Host 端代码 (简化)
cl_mem d_A = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,sizeof(float) * N, h_A, NULL);
cl_mem d_B = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,sizeof(float) * N, h_B, NULL);
cl_mem d_C = clCreateBuffer(context, CL_MEM_WRITE_ONLY,sizeof(float) * N, NULL, NULL);// 设置 kernel 参数
clSetKernelArg(kernel, 0, sizeof(cl_mem), &d_A);
clSetKernelArg(kernel, 1, sizeof(cl_mem), &d_B);
clSetKernelArg(kernel, 2, sizeof(cl_mem), &d_C);// 执行内核
size_t globalSize = N;
clEnqueueNDRangeKernel(queue, kernel, 1, NULL, &globalSize, NULL, 0, NULL, NULL);// 从设备拷回 Host
clEnqueueReadBuffer(queue, d_C, CL_TRUE, 0, sizeof(float) * N, h_C, 0, NULL, NULL);// Kernel 端 (OpenCL C)
__kernel void vec_add(__global const float* A,__global const float* B,__global float* C) {int gid = get_global_id(0);C[gid] = A[gid] + B[gid];
}
使用 Buffer 对象 管理数组型数据,是最常见的方式。
示例 2:Image 对象用于图像灰度化
利用 clCreateImage 创建 2D 图像内存对象,并让 kernel 直接处理。
// Host 端代码 (简化)
cl_image_format format = { CL_RGBA, CL_UNORM_INT8 };
cl_image_desc desc = {0};
desc.image_type = CL_MEM_OBJECT_IMAGE2D;
desc.image_width = width;
desc.image_height = height;cl_mem d_InputImage = clCreateImage(context,CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,&format, &desc, inputPixels, NULL);cl_mem d_OutputImage = clCreateImage(context,CL_MEM_WRITE_ONLY,&format, &desc, NULL, NULL);// 设置 kernel 参数
clSetKernelArg(kernel, 0, sizeof(cl_mem), &d_InputImage);
clSetKernelArg(kernel, 1, sizeof(cl_mem), &d_OutputImage);// Kernel 端 (OpenCL C)
__constant sampler_t sampler = CLK_NORMALIZED_COORDS_FALSE |CLK_ADDRESS_CLAMP |CLK_FILTER_NEAREST;__kernel void to_gray(read_only image2d_t input,write_only image2d_t output) {int2 coord = (int2)(get_global_id(0), get_global_id(1));float4 pixel = read_imagef(input, sampler, coord);float gray = 0.299f * pixel.x + 0.587f * pixel.y + 0.114f * pixel.z;write_imagef(output, coord, (float4)(gray, gray, gray, 1.0f));
}
使用 Image 对象 时,GPU 可以利用硬件优化(如缓存、采样器),比 buffer 更高效地处理图像数据。
示例 3:Pipe 对象实现生产者-消费者
Host 端代码(C)
// 创建一个 Pipe 对象,元素类型为 int,容量为 16
cl_mem pipe = clCreatePipe(context,CL_MEM_READ_WRITE, // 可读写sizeof(int), // 元素大小16, // 容量NULL, NULL);// 创建内核
cl_kernel producerKernel = clCreateKernel(program, "producer", NULL);
cl_kernel consumerKernel = clCreateKernel(program, "consumer", NULL);// 设置参数
clSetKernelArg(producerKernel, 0, sizeof(cl_mem), &pipe);
clSetKernelArg(consumerKernel, 0, sizeof(cl_mem), &pipe);// 执行内核(这里顺序执行,实际可以放到不同队列并行)
size_t globalSize = 16;
clEnqueueNDRangeKernel(queue, producerKernel, 1, NULL, &globalSize, NULL, 0, NULL, NULL);
clEnqueueNDRangeKernel(queue, consumerKernel, 1, NULL, &globalSize, NULL, 0, NULL, NULL);
Kernel 端代码(OpenCL C 2.0)
// 生产者内核:往 Pipe 中写入数据
__kernel void producer(write_only pipe int outPipe) {int gid = get_global_id(0);write_pipe(outPipe, &gid); // 将 gid 写入 pipe
}// 消费者内核:从 Pipe 中读取数据
__kernel void consumer(read_only pipe int inPipe) {int value;if (read_pipe(inPipe, &value) == 0) {// 正常读取,打印或存入全局内存printf("Consumed: %d\n", value);}
}
对比总结
- Buffer:适合大规模数组,需 host 和 device 拷贝数据。
- Image:专为图像/纹理数据优化,带硬件采样和缓存。
- Pipe:适合 内核间直接通信(生产者→消费者),避免 host 参与,常用于流式计算和流水线并行。
总结
- 缓冲区 (Buffer):一维内存,最常用,适合数值计算。
- 图像 (Image):支持硬件加速的采样、过滤,适合图像/视频处理。
- 管道 (Pipe):OpenCL 2.0 新增,用于内核间通信。
性能优化时要注意:
- 避免频繁
clEnqueueRead/WriteBuffer(尽量异步/重叠计算与通信) - 合理使用
map/unmap与CL_MEM_USE_HOST_PTR实现零拷贝 - 对图像使用图像对象,可利用 GPU 的纹理缓存