重新测试所有AI代码生成器(2025年更新):GPT-5 vs Claude 4.1 vs Gemini 2.5 Pro——为何“赢家”仍取决于你的技术栈

Claude 4.1基准测试概述(智能体编程与推理能力,agentic coding and reasoning)
为何要发布2025年更新版?
我基于最新的公开数据,重新分析了该领域。今年的三大主流模型分别是:OpenAI的GPT-5、Anthropic的Claude 4.1(Opus版本)以及谷歌的Gemini 2.5 Pro。
核心结论先睹为快:顶尖模型的排名虽有变动,但“合适”的工具仍取决于你的技术栈(IDE、云服务、协作平台)。基准测试决定质量,生态系统决定开发效率。
(相关企业:OpenAI、Anthropic、Google DeepMind)
新增内容:2025年概况速览
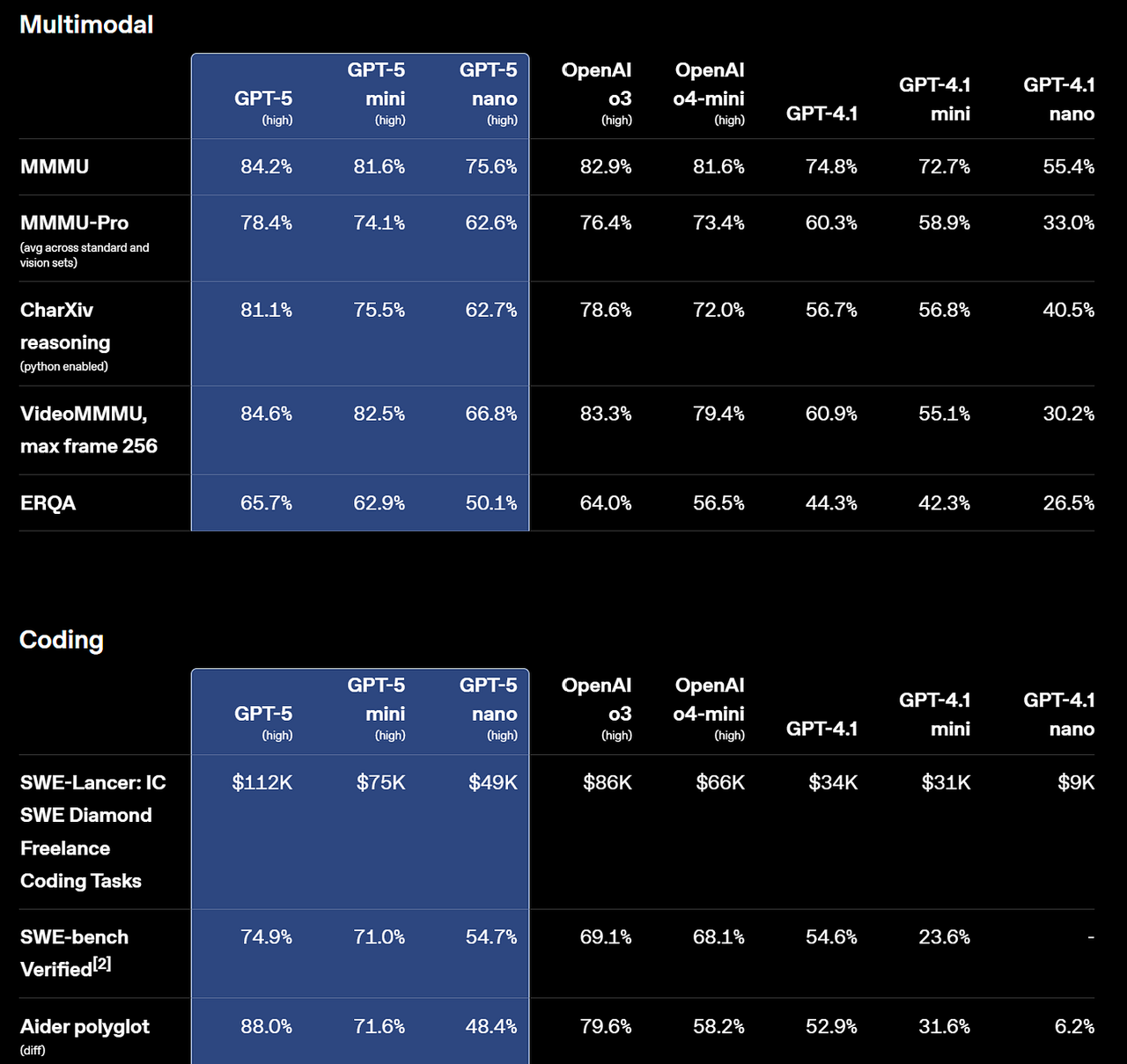
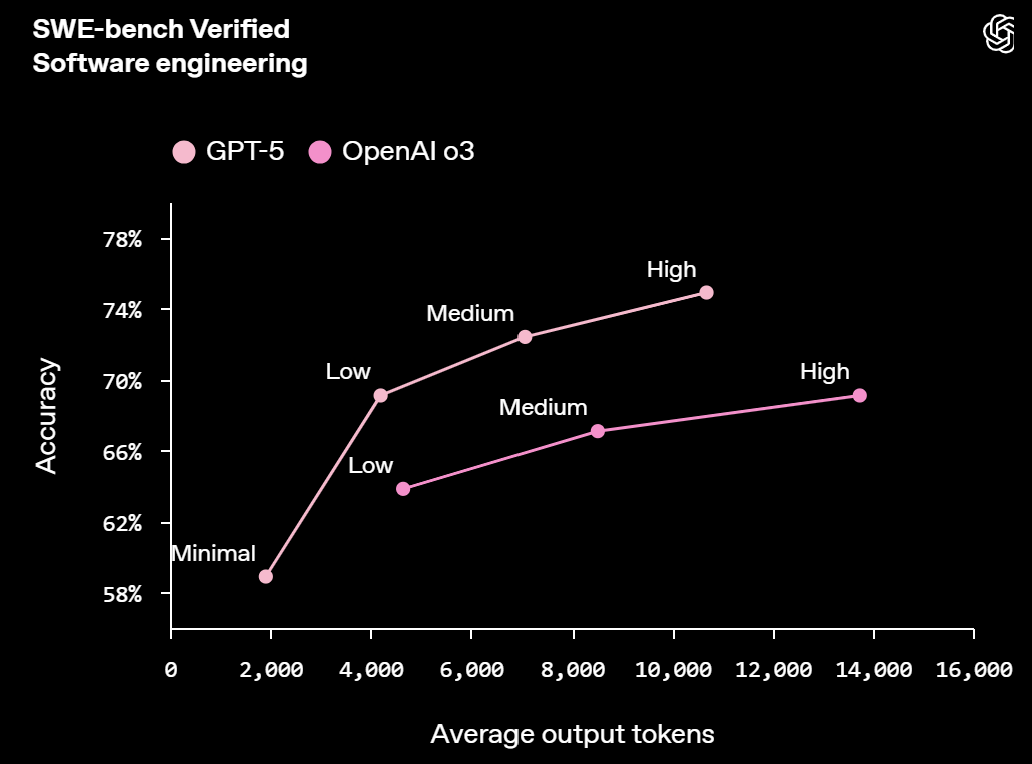
GPT-5(OpenAI):在真实世界编程任务中表现达到业界领先水平——SWE-bench Verified基准测试(该基准测试通过让AI修复真实GitHub问题并提交符合PR质量的补丁来评估其能力)得分为74.9%,Aider Polyglot基准测试(多语言代码编辑任务基准测试)得分为88%。OpenAI还表示,在内部前端对比测试中,GPT-5的偏好率达70%;且与之前的推理模型“o3”(说明:o3是OpenAI早期的推理系列模型,与GPT-4o不同)相比,GPT-5使用更少的token/工具调用就能实现相当或更优的结果。预计GPT-5在复杂UI生成和大型代码库调试方面表现更强,且效率更高。(来源:OpenAI、OpenAI)
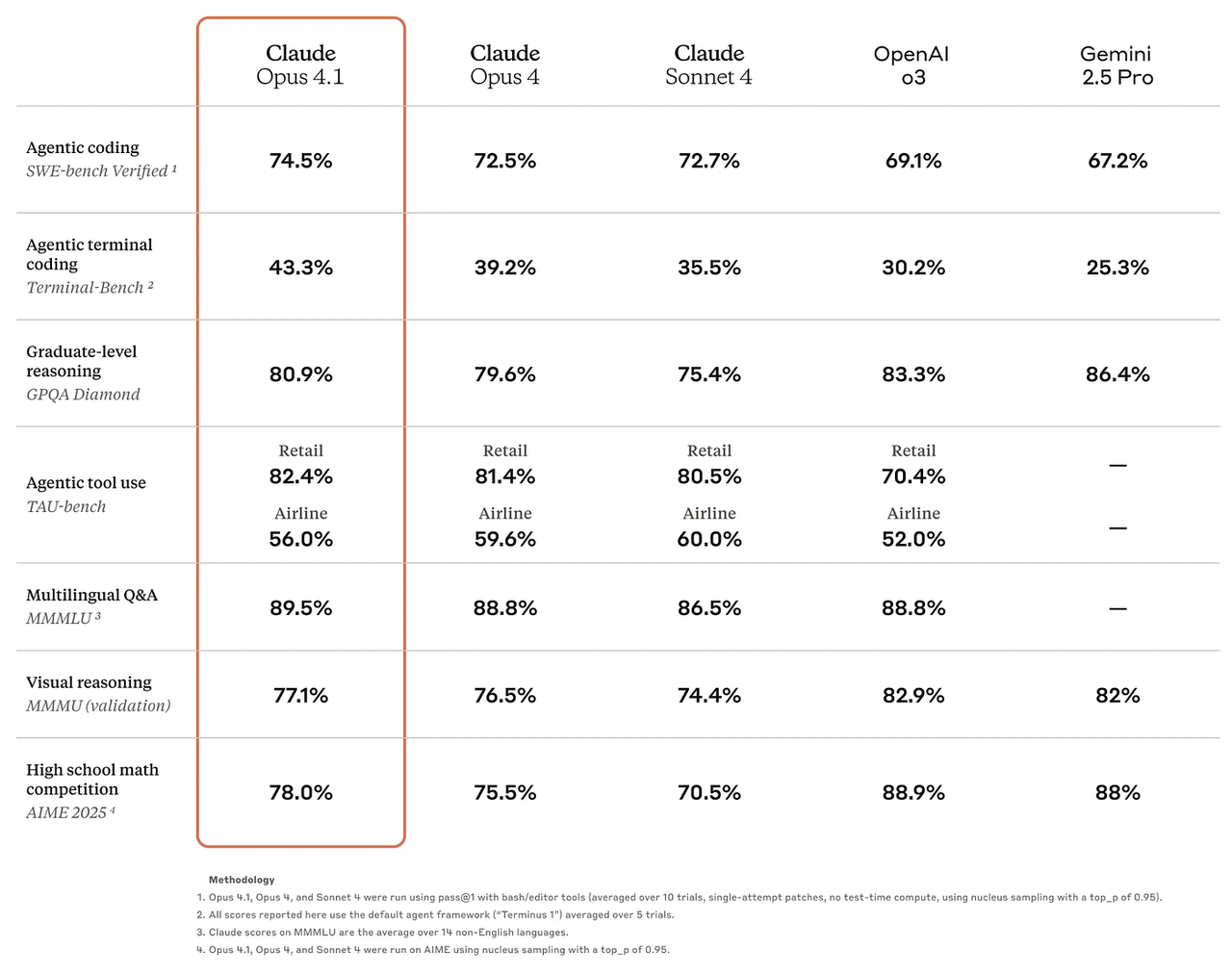
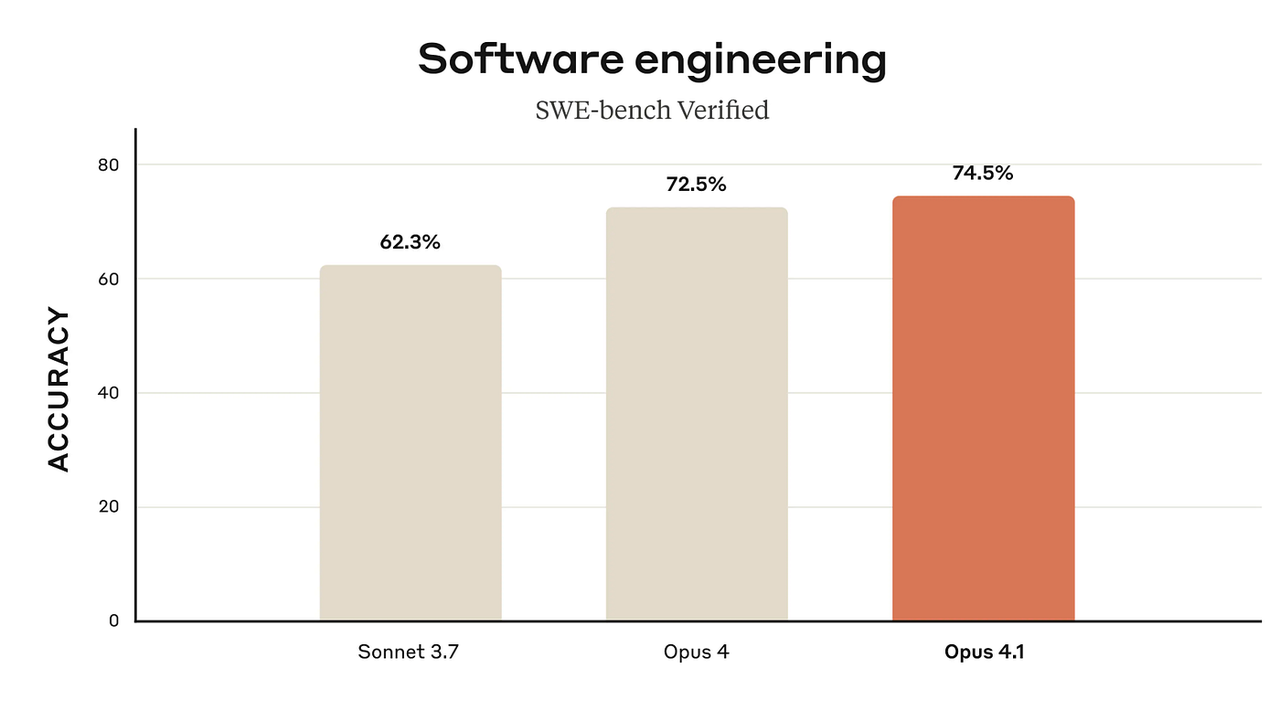
Claude 4.1(Opus版本,Anthropic):将Anthropic在编程领域的技术水平提升至新高度,其SWE-bench Verified基准测试得分为74.5%。根据来自GitHub、乐天(Rakuten)和Windsurf的合作方反馈,该模型在大型代码库中进行多文件重构时,能生成“精准定位”的代码差异(surgical diffs)——这在精准度与通过率同等重要的场景中非常实用。(来源:Anthropic)
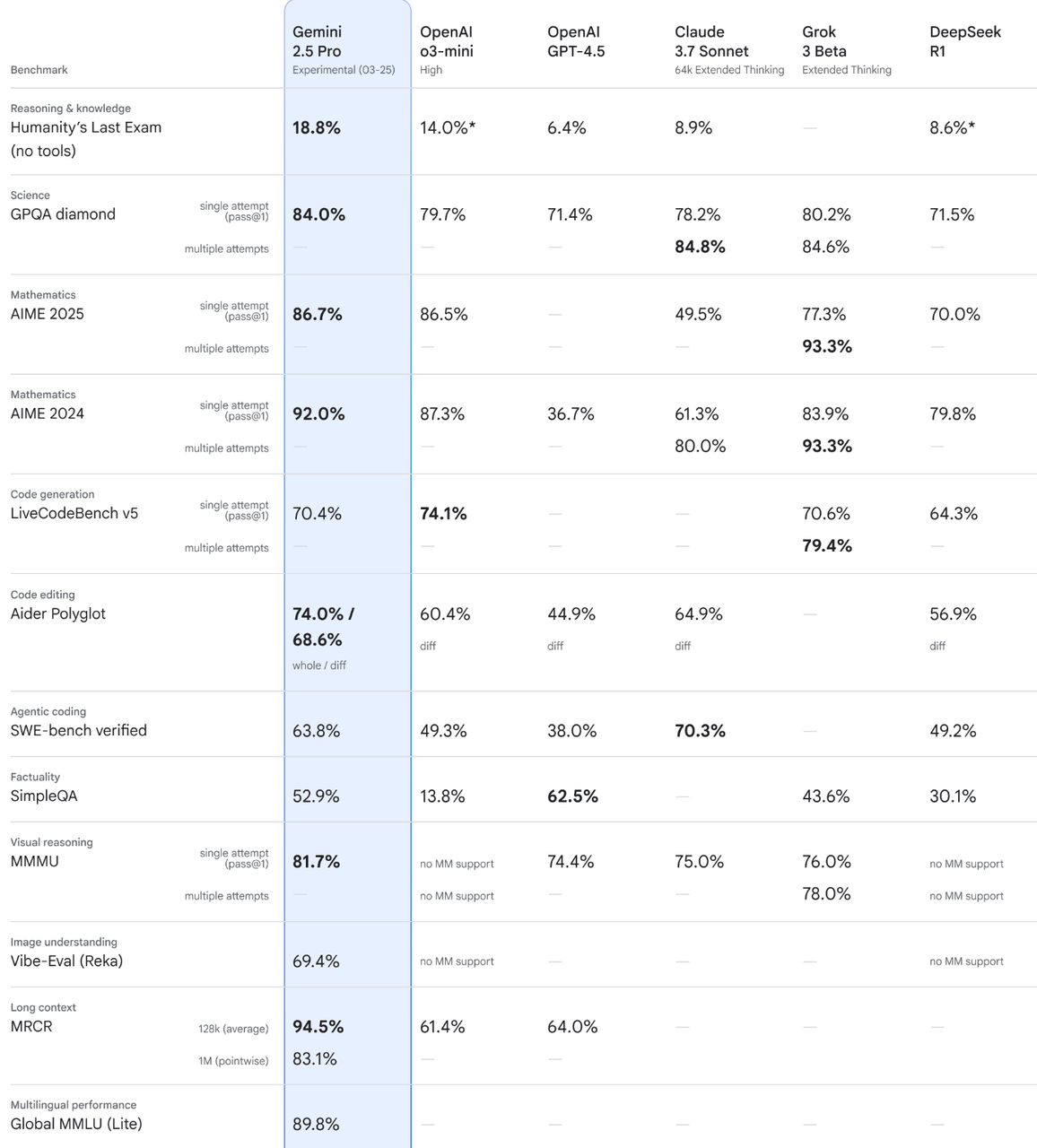
Gemini 2.5 Pro(谷歌):在自定义agent配置下,其SWE-bench Verified基准测试得分为63.8%;同时支持100万token的上下文窗口(200万token上下文窗口“即将推出”)。对于使用谷歌原生工具(Docs/Sheets/Drive/Meet)的团队,以及需要长上下文研究或多媒体工作流的场景而言,这一特性极具吸引力。(来源:Google DeepMind、deepmind.google)
Gemini相关图表(基准测试 + 长上下文优势突出显示)
(来源:Google DeepMind)
2.0测试方法:今年如何重新评分?
为确保本次更新的客观性和可复现性,我结合了三类数据来源:
公开的编程基准测试;
关于模型采用率/留存率的大型开发者调查;
多标准助手评估(涵盖需求合规性、代码质量、性能以及基础安全问题,例如OWASP十大安全风险模式)。
这种方法能帮助你为自己的技术栈选择合适的工具,而非盲目追求单一的“总体最佳”称号。(来源:SWE-bench、Stack Overflow、AIMultiple Research)
能力维度:通过SWE-bench Verified(定义:评估模型能否端到端解决真实GitHub问题)衡量真实工程能力,通过Aider Polyglot(定义:衡量多语言代码编辑任务的准确率)衡量代码编辑能力,同时参考各厂商公开披露的指标(涉及模型:GPT-5、Claude 4.1、Gemini 2.5 Pro)。(来源:OpenAI、Anthropic、Google DeepMind)
采用率与留存率:参考JetBrains针对2.3万名开发者的调查(由DevClass整理)中的持续使用率数据,以及Stack Overflow开发者调查中的整体采用情况(今年76%的开发者正在使用或计划使用AI工具,62%的开发者已在使用)。(来源:devclass.com、Stack Overflow)
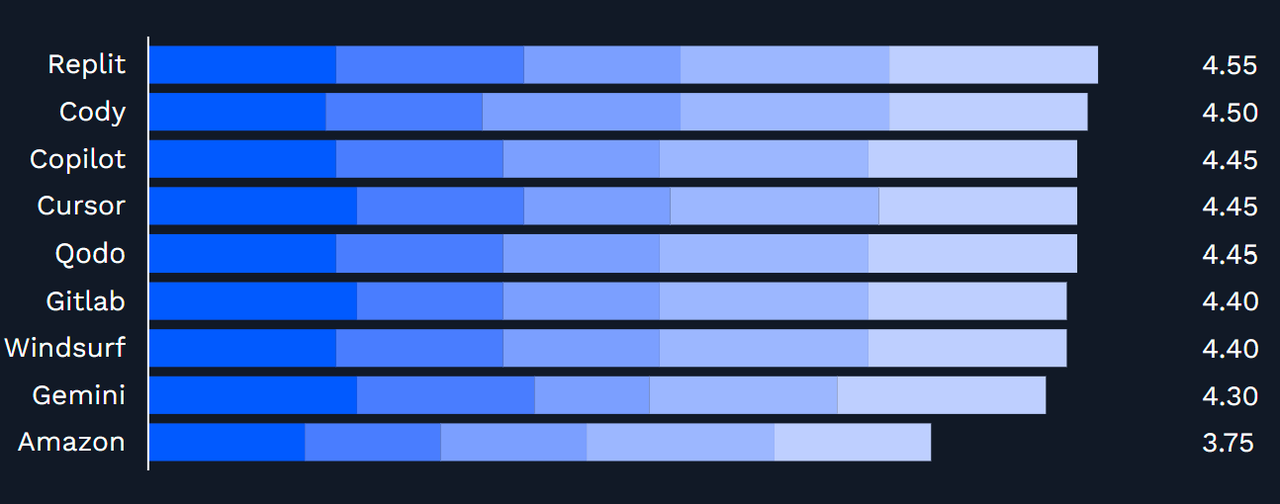
助手的用户体验与安全性:多标准助手测试(重点评估需求合规性、代码质量、性能及安全性),以及编辑器适配性对比(结果显示Cursor、Windsurf、Replit、GitLab Duo与Copilot一样,都是值得尝试的工具)。(来源:AIMultiple Research)
最新公开基准测试结果(含术语解析)
GPT-5:在SWE-bench Verified(定义回顾:端到端评估真实GitHub问题解决能力)中得分为74.9%,在Aider Polyglot(定义回顾:衡量多语言代码编辑准确率)中得分为88%。OpenAI还表示,在内部UI生成测试中,GPT-5的偏好率达70%;且与o3(说明:o3是OpenAI之前的推理模型)相比,GPT-5能以更少的token/工具调用完成同类任务,这意味着其处理复杂工作的效率更高。(来源:OpenAI)
Claude 4.1(Opus版本):在SWE-bench Verified中得分为74.5%;合作方反馈显示,该模型在多文件重构和大型代码库精准编辑方面有显著提升——团队表示其不必要的编辑更少、修正更精准,这类特性很受代码评审团队青睐。(来源:Anthropic)
Gemini 2.5 Pro:在自定义agent配置下,其SWE-bench Verified得分为63.8%;目前已支持100万token的上下文窗口。若你的企业日常使用Google Workspace(Docs/Sheets/Drive/Meet),且需要跨文档、数据和媒体进行长上下文信息整合,这一特性将极具实用价值。(来源:Google DeepMind、deepmind.google)
采用现状:开发者实际持续使用的工具
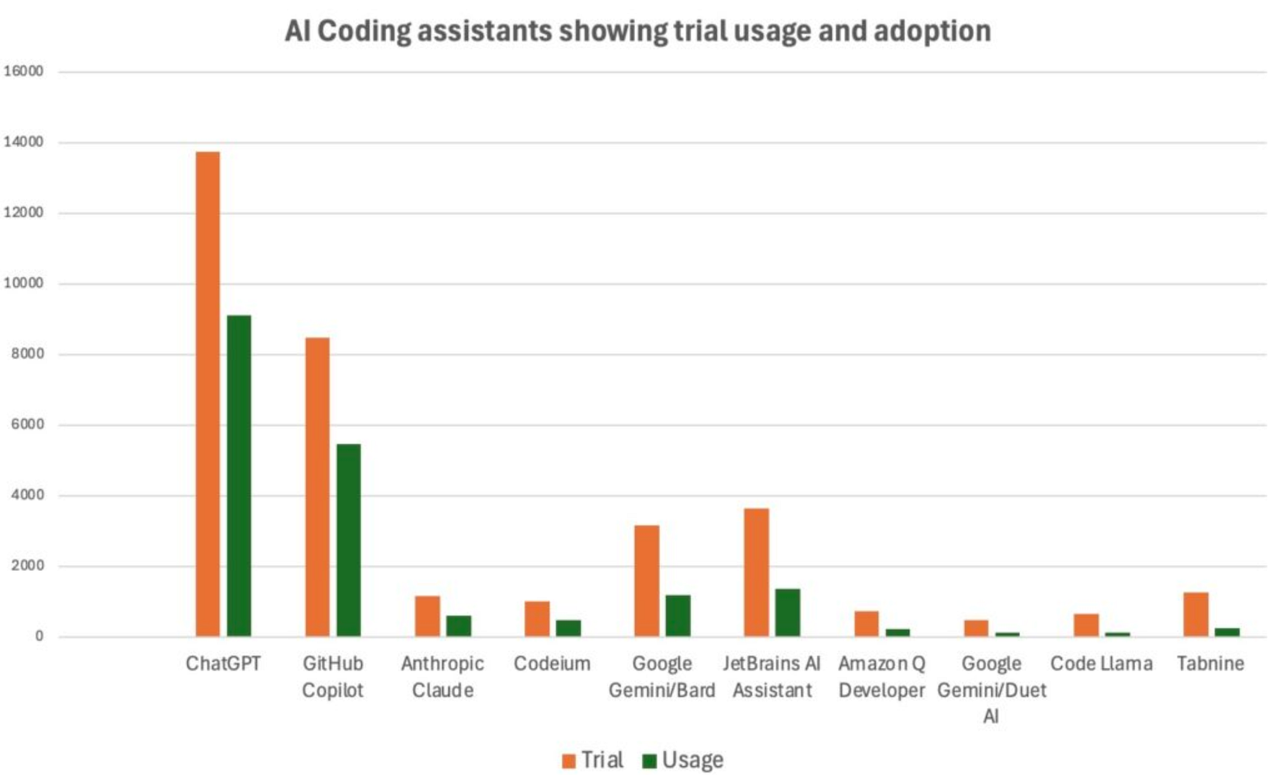
JetBrains生态系统调查(覆盖2.3万+开发者)显示,不同工具的持续使用率存在差异:ChatGPT(66.4%)、GitHub Copilot(64.5%)、Claude(52.4%)、Codeium(48.3%)、Gemini/Bard(37.6%)、JetBrains AI Assistant(37.2%)、Amazon Q Developer(31.1%)。
这意味着团队会留存适配自身技术栈与授权方案的工具,而非单纯选择在某一项榜单中排名第一的工具。
整体采用率正加速提升:今年76%的开发者正在使用或计划使用AI工具,62%的开发者已在使用(去年这一比例为44%)。企业正逐步将符合自身治理规范、集成需求及日常工作流的AI工具组合标准化。
2025年谁才是真正的“赢家”?答案取决于场景——实用选择指南
不存在单一的“通用赢家”,而这恰恰是好消息。你的技术栈决定了最适合你的工具。请基于以下实证依据快速选择,避免事后懊悔。
最大化解决复杂真实编程任务的成功率:优先选择GPT-5。它在公开披露的SWE-bench Verified评分中最高(74.9%),且在Aider Polyglot代码编辑测试中排名第一(88%)。
精准重构与大型代码库编辑:尝试Claude 4.1(Opus版本)。它在SWE-bench测试中略逊于GPT-5,但合作方反馈显示,其在多文件重构和精准精简的代码差异(diff)生成方面表现突出——当代码评审信任度和小补丁(small patches)是关键需求时,该模型是绝佳选择。(来源:Anthropic)
谷歌生态团队的“隐形赢家”:选择Gemini 2.5 Pro。若你的企业日常使用Google Workspace(Docs/Sheets/Drive/Meet),100万token的上下文窗口及原生集成能大幅降低使用阻力,其处理效率甚至可能超过评分更高的模型。对许多团队而言,最快捷的做法是在现有使用的工具中启用Gemini,并在此基础上尝试其编辑器助手功能。(来源:Google DeepMind、deepmind.google)
编辑器中的“即时操作”速度:GitHub Copilot仍是无缝嵌入式加速工具的首选,且持续使用率居高不下。若你需要更具agent特性的编辑功能,可在使用Copilot的同时试点Cursor/Windsurf,最终留存经内部工具验证效果更佳的方案。(来源:devclass.com、AIMultiple Research)
AWS优先型企业:Amazon Q Developer显然是初期部署的优选,它支持AWS原生模式,并配备用于技术升级的代码转换/调试agent。真实客户反馈显示,其多行建议的接受率表现良好(例如,英国电信集团(BT Group)为37%,澳大利亚国民银行(National Australia Bank)为50%)。
快速可复制操作指南(每项10分钟)
这些小型试点方案能让团队的测试结果可共享、可复现。
1. GPT-5“SWE-风格”测试(3个任务单)
简介:挑选3项常规任务(1项漏洞修复、1项小型功能开发、1项不稳定测试用例修复)。先进行不使用AI的基准测试,再仅使用所需文件/测试用例,通过GPT-5重新执行任务。跟踪从开发到提交PR的时间(time-to-PR)、代码差异大小(diff size)及评审意见中的小问题(review nits)。每周重复一次,并根据团队情况明确“何时使用GPT-5”的规则。
2. Claude 4.1“精准重构”(1个服务,2个迭代周期)
简介:选取一个需要进行混乱多文件重构的服务。先让Claude生成一份RFC风格的方案,再生成精简的代码差异(diff)。在两个迭代周期内,对比该方案与手动重构的“评审意见小问题率”及“合并后缺陷数”。
3. Gemini 2.5“长上下文处理效率”(基于Workspace)
简介:在Workspace中全面启用Gemini。将包含产品需求文档(PRD)、规格说明(specs)、备注(notes)的项目文件夹导入,让Gemini生成测试计划和代码框架,再调用编辑器助手生成桩代码(stubs)。在2-3周内,跟踪从规格说明到代码合并的周期时间(spec→merge cycle time)。
4. Copilot/Cursor/Windsurf“IDE适配测试”(2周)
简介:统计工具的建议接受率和修改耗时。若建议接受率低于约20%,或修改耗时超过使用工具带来的收益,则切换底层模型(目前多数IDE支持选择GPT/Claude/Gemini),或试点使用Cursor/Windsurf,最终保留效果更佳的工具。
可落地的测试工具:基于代码而非主观感受评估助手
代码块说明:以下是与助手工具无关的通用测试工具,可用于评估任意工具的输出质量和延迟。将助手生成的函数粘贴到工具中,对比不同模型的测试通过率(pass/fail)和耗时。通过这种方式,你能建立内部可信度,基于数据做出决策。
JavaScript规格符合性微型测试工具(定义:检查生成的代码是否符合明确的验收标准)
简介:验证“筛选活跃管理员并排序”功能是否符合预期输出。
// evaluate.js
const assert = (cond, msg) => { if (!cond) throw new Error(msg); };export function evaluateUserListSpec(impl) {try {const users = [{name: 'Zed', role: 'admin', active: true},{name: 'amy', role: 'admin', active: true},{name: 'Bob', role: 'user', active: true},{name: 'Cara', role: 'admin', active: false}];const out = impl(users);assert(Array.isArray(out), '输出必须为数组');assert(out.length === 2, '应返回2个活跃管理员');assert(out[0] === 'amy' && out[1] === 'Zed', '必须按字母升序排序');return { pass: true };} catch (e) {return { pass: false, reason: e.message };}
}Python延迟与正确性微型测试工具(定义:统计实际耗时并验证排序正确性)
简介:测试函数耗时,并确保能正确筛选并排序出得分前100的数据。
# bench.py
import time, random
def dataset(n=20000):return [{"id": i, "score": random.random(), "active": i % 3 != 0} for i in range(n)]def naive(users):active = [u for u in users if u["active"]]return sorted(active, key=lambda u: u["score"], reverse=True)[:100]
def bench(fn, data):t0 = time.perf_counter()out = fn(data)ms = (time.perf_counter() - t0) * 1000ok = len(out) == 100 and all(out[i]["score"] >= out[i+1]["score"] for i in range(99))return ms, ok
if __name__ == "__main__":data = dataset()t_ms, ok = bench(naive, data)print(f"基准测试:{t_ms:.2f} 毫秒,验证通过={ok}")读者驱动型常见问题(解答热门评论)
“此前为何未纳入Cursor或Windsurf?”:本文已明确补充这两款工具。在助手级别的对比中,Cursor、Windsurf、Replit、GitLab Duo常被视为与Copilot相当的优质IDE体验工具——尤其当你需要更具agent特性、能感知代码库(repo-aware)的编辑流程时。可通过上文提及的测试工具对它们进行试点评估。(来源:AIMultiple Research)
“VS Code的Gemini Code Assist在哪?”:本次更新聚焦有文档记录的模型性能及生态集成。对于谷歌生态团队而言,在Workspace中全面启用Gemini 2.5 Pro并尝试其编辑器助手,是实现处理效率提升的低门槛方式,尤其在100万token长上下文工作流中效果显著。(来源:Google DeepMind、deepmind.google)
“AWS上的Amazon Q Developer表现如何?”:若你的技术栈以AWS为核心,Amazon Q Developer是初期部署的实用选择。AWS强调了客户反馈的多行建议接受率(例如,英国电信集团(BT Group)为37%,澳大利亚国民银行(National Australia Bank)为50%),且该工具配备了用于技术升级的代码转换agent。可在实际升级任务中对其进行测试。(来源:AWS、The Register)
“开发者真的会持续使用这些工具吗?”:会,但存在差异。JetBrains调查显示的持续使用率数据如下:ChatGPT(66.4%)、Copilot(64.5%)、Claude(52.4%)、Codeium(48.3%)、Gemini/Bard(37.6%)。这一数据印证了“最佳工具”具有场景依赖性,且往往由生态系统决定。(来源:devclass.com)
按团队类型推荐的技术栈
独立开发者
日常开发加速工具:GitHub Copilot
复杂推理/PR级任务:GPT-5 或 Claude 4.1——通过上文测试工具对两者进行试点,保留在你代码库中表现更优的工具。(来源:OpenAI、Anthropic)
小型团队(2-15人)
IDE基础工具:Copilot
问题解决工具:GPT-5 或 Claude 4.1
谷歌生态团队:在Workspace中全面启用Gemini 2.5 Pro,用于长上下文规划/规格说明编写。(来源:OpenAI、Anthropic、Google DeepMind)
中型企业/大型企业
基础工具:Copilot Enterprise
高难度任务解决方案:GPT-5(在高难度任务单中实现业界领先的解决率)
精准重构工具:Claude 4.1(用于多文件精准重构)
AWS技术升级工具:Amazon Q Developer(用于AWS技术栈现代化改造)
谷歌生态企业:在Workspace中全面启用Gemini 2.5,并评估其编辑器助手功能。(来源:OpenAI、Anthropic、AWS、Google DeepMind)
结尾图表:采用现状(试点使用 vs 持续使用)
核心结论一句话总结
若你当前以优化高难度工程任务的解决率为目标,GPT-5是首选;若需在大型代码库中实现精准代码差异(surgical diffs),Claude 4.1表现出色;若你的企业依赖谷歌生态,Gemini 2.5 Pro则是能最大化处理效率的“隐形赢家”——总而言之,最稳妥的做法是:通过简单、公平的测试工具在你自己的代码库中验证这些工具,最终保留表现更优的那一个。(来源:OpenAI、Anthropic、Google DeepMind)