存算一体前沿技术——无需比较器即可高效排序,性能提升高达百倍
- 技术背景
排序是计算科学中的一项基本任务,广泛应用于人工智能、数据库系统、网络搜索和科学计算等多个领域。传统的硬件排序系统,无论是基于中央处理器(CPU)、图形处理器(GPU)还是专用集成电路(ASIC),都构建于冯·诺依曼架构之上。这类架构将计算单元与存储单元分离,导致处理器在执行排序算法时需要频繁地在两者之间传输数据。随着数据量的爆炸式增长,这种数据搬运的延迟和功耗问题日益突出,形成了所谓的“内存墙”瓶颈,严重制约了排序效率的提升。
为了解决“内存墙”等技术瓶颈,存算一体技术应运而生。存算一体架构将数据存储与计算功能融合在同一个物理单元中,能够在数据所在之处直接进行处理,从而极大地减少了数据搬运带来的开销,在执行矩阵乘加等线性计算任务时展现出卓越的能效和速度优势。然而,排序这类非线性计算对存算一体技术构成了巨大挑战。传统的排序算法高度依赖于比较和选择操作,这需要在硬件层面实现复杂的比较器网络。在存算一体架构中实现这样复杂的逻辑网络不仅困难,而且会带来巨大的面积和功耗开销,使其优势大打折扣。因此,如何高效地在存算一体架构上实现排序等非线性操作,一直被视为该领域最难攻克的挑战之一。
在此背景下,一项突破性的研究成果应运而生,它提出了一种无需比较器即可在忆阻器阵列中高效执行排序的存算一体芯片方案,成功打破了存算一体技术难以处理复杂非线性任务的限制。
- 论文讲解
该研究由北京大学信息工程学院/广东省存算一体芯片重点实验室的杨玉超教授团队完成,相关成果以《A fast and reconfigurable sort-in-memory system based on memristors》为题发表在国际顶级期刊《自然·电子》(Nature Electronics)上。论文的第一作者为北京大学博士生余连风,通讯作者为杨玉超教授和陶耀宇研究员。杨玉超教授团队长期致力于存算一体技术的研究,在忆阻器器件、电路设计和硬件系统方面拥有深厚的研究基础。
本文提出了一种基于忆阻器的、无需比较器的高速可重构存算一体排序系统。该系统通过创新的阵列位读取(Digit Read)机制,以并行方式从高位到低位逐位遍历数据,从而直接定位当前数据集中的最大或最小值,彻底颠覆了传统依赖“比较-交换”的排序范式,下面将从架构技术要点说明和效率提升优势分析两个方面进行介绍。
- 架构技术要点说明
文章按照提出问题->核心创新方案->方案优化与扩展->实验验证->应用展示的逻辑进行书写,提出并实现了一种“无比较”的存内排序(Sort-in-Memory, SIM)系统。它不依赖传统的比较器电路来逐个比较数字大小,而是利用忆阻器阵列的物理特性,通过“数字读取(Digit Read)”和“树节点跳跃(Tree Node Skipping, TNS)”,直接在内存中高效地找出数据集中的最大值和最小值,从而实现排序。
忆阻器阵列实现存内排序的核心是数字读取(digital read, DR)。传统排序是比较数字,进行位遍历排序,如fig.1h所示。而基于DR的排序是并行地“筛选”比特位。它利用忆阻器阵列可以同时读取一整列(或行)数据的物理特性,一次性获取所有待排序数字在同一个比特位上的值,然后根据这些值逐步排除不可能是最小/最大值的数字。
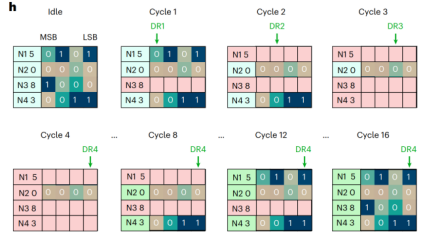
图1 传统排序方案
如fig.2i和fig.2j所示,所有四个数字(5, 0, 8, 3)都存储在忆阻器阵列中,它们都是排序的候选对象。LIFO(k=2)是一个容量为2的后进先出栈,用来记录排序过程中的关键决策点。
排序从对所有数字的最高有效位进行第一次DR开始,此时由于比特值出现了0和1的分歧,系统识别出这是一个关键的“分叉点”(Node 1),便将该决策点信息存入LIFO记忆堆栈,并排除了最高位为1的数字8。接着,在第二次DR中,系统再次遇到分叉(Node 2),同样记录该节点并排除了数字5。当后续的DR操作未产生分歧时,系统则跳过记录,直接前进,直至在第四次DR后确定唯一的候选者0为第一个最小值。在寻找下一个最小值时,系统并非从头开始,而是从LIFO中加载最近的决策点Node 2的状态,直接“跳跃”到上一个分叉口去探索其他路径,从而高效地依次找出剩余的最小值3、5和8。这个过程通过智能地记录与跳跃,极大地减少了冗余的读取操作,显著加速了整个排序流程。这种记录-加载机制,就是作者提出的TNS(Tree Node Skipping, 树节点跳跃)。
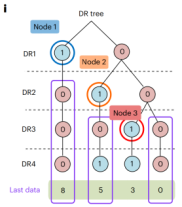
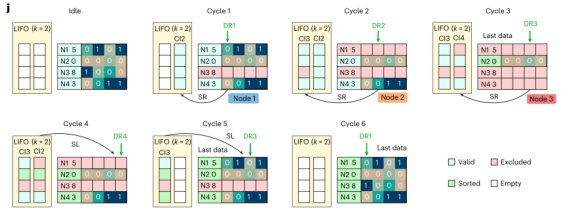
图2 基于DR的排序方案
单个忆阻器阵列的能力毕竟有限,要处理真实世界的海量数据,必须将TNS技术扩展到多个阵列协同工作,这就是本文提出的跨阵列树节点跳跃(Cross-Array TNS,CA-TNS)。如文中fig.3c所示,CA-TNS 提供了三种并行策略,从不同维度解决了可扩展性和性能问题。
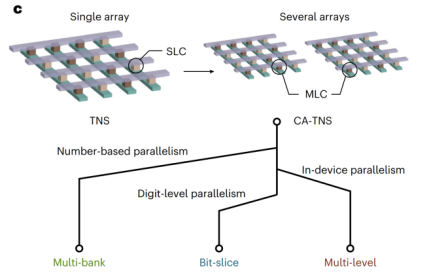
图3 CA-TNS提供的三种并行策略示意图
多区块(Multi-bank)策略如Fig.4a所示,它将一个庞大的数据集(如N1-N16)切分成多个区块,分别存放在不同的忆阻器阵列中(TNS1存N1-N8,TNS2存N9-N16)。在排序时,如Fig.4b所示,所有并行的子排序器(TNS1到TNSn)会先同步执行一次数字读取操作,并各自将关键的状态信息上报给中央的跨阵列处理器。接着,中央处理器会进行全局信号同步,它综合所有子排序器的读取结果,做出一个全局性的决策,例如确定当前位上哪些数字应被排除。随后,这个全局决策指令会被下发,用以替换和更新每个子排序器原有的本地状态,确保所有单元步调一致。这个“并行读取-全局同步-本地更新”的循环会迭代进行,直至找到最小值或最大值,最终实现了将多个独立的TNS排序器虚拟地整合成一个强大的、能够处理大规模数据的统一排序系统。
这种方式就像将多个小排序器虚拟地整合成一个巨大的排序器,实现了数据级的并行,有效解决了可扩展性瓶颈。
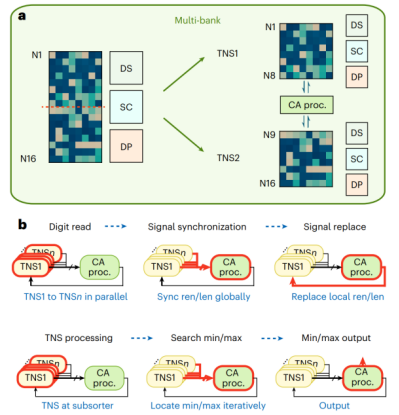
图4 多区块策略示意图
位切片(Bit-slice)策略如Fig.5c所示,它将一个长数字(如32位)的比特位切分开,高位部分存入一个阵列(TNS1),低位部分存入另一个阵列(TNS2)。排序时,如Fig.5d流程所示,首先由TNS1处理高位。如果高位就能决出胜负,排序就提前结束;如果高位出现多个数字的高位部分相同的情况,TNS1会将这些平局信息传递给TNS2,由TNS2继续比较低位。与此同时,TNS1可以开始处理下一轮的排序任务,形成高效的流水线作业,极大地提升了处理长数据的吞吐率。
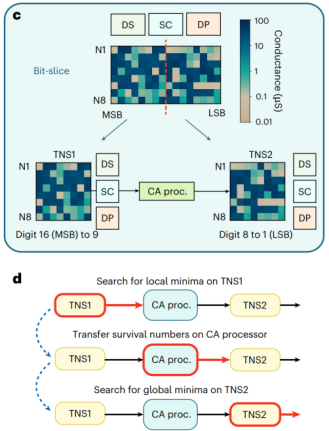
图5 位切片策略示意图
多能级(Multi-level)策略如Fig.6e所示,它使用能够存储多比特信息的多能级单元(MLC)。传统单能级单元一次DR只能区分0和1(二选一),而一个2-bit MLC一次DR就能区分‘00’、‘01’、‘10’、‘11’四种状态(四选一)。这意味着决策树的每个节点从二分叉变成了四分叉,每一步都能排除更多的可能性,从而可以用更少的DR次数完成排序。这是一种在器件物理层面实现的并行,它同时提升了存储密度和排序效率。
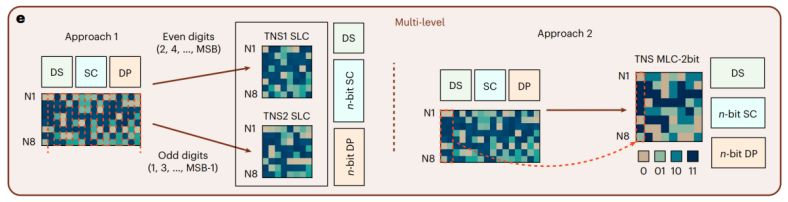
图6 多能级策略示意图
(2)效率提升优势分析
为了全面测试MSIM系统的效果,研究团队从仿真测试和实际应用两个角度出发对MSIM展开测试。
1.仿真测试
首先,研究团队在五个经典的排序基准数据集上进行了测试,他们分别是:、Random(随机)、Normal(正态)、Clustered(聚类)Kruskal和MapReduce41,并且与传统的基于ASIC的排序系统进行了对比。在图7中(原文Fig.4.f)我们可以看到在引入CA-TNS下该系统与传统ASIC系统的性能对比,看以看到本文提出的各种策略(其中参数k、w等在前述介绍中已有,在此不再赘述)均比ASIC占优,直观的体现出了其速度优势。
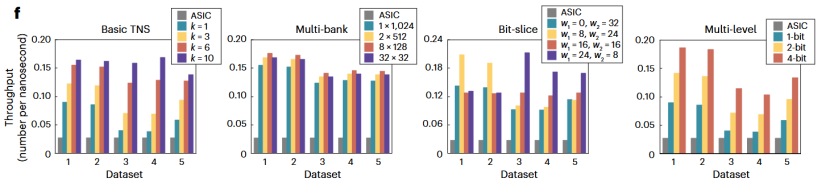
图7 在五个排序基准数据集上的排序速度
在图8中,研究团队比较了不同策略与ASIC系统在能效和面效上的差距。可以看到,在完成相同排序任务时,MSIM系统在单位面积上的性能以及单位能耗下完成的性能君优于ASIC基准,有力地证明了其在效率上的巨大提升。
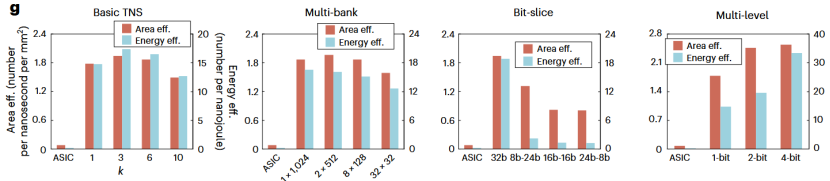
图8 在五个排序基准数据集上的能效与面效对比
具体到数字上,实验结果显示,在横跨五个经典的排序基准数据集测试中,MSIM系统相比传统的ASIC方案:1)在排序速度(吞吐率)上,实现了高达7.70倍的提升;2)在能效上,实现了高达160.4倍的大幅提升;3)在面积效率上,也获得了高达32.46倍的显著提升。
2.实际应用
之后,为了验证MSIM系统在真实计算任务中的实用价值,研究团队选取了图计算和神经网络这两个前沿领域中极具代表性的应用场景进行了实验。
首先是在经典的Dijkstra最短路径搜索算法中的应用。该算法广泛应用于地图导航等场景,其核心瓶颈在于需要在每次迭代中,从所有待访问的节点里找出当前距离最近的一个。研究团队以北京地铁网络为例,在算法的每一步,都利用MSIM系统高效地在存内完成“寻找最近站点”的排序操作,从而避免了传统架构下的大量数据往返。
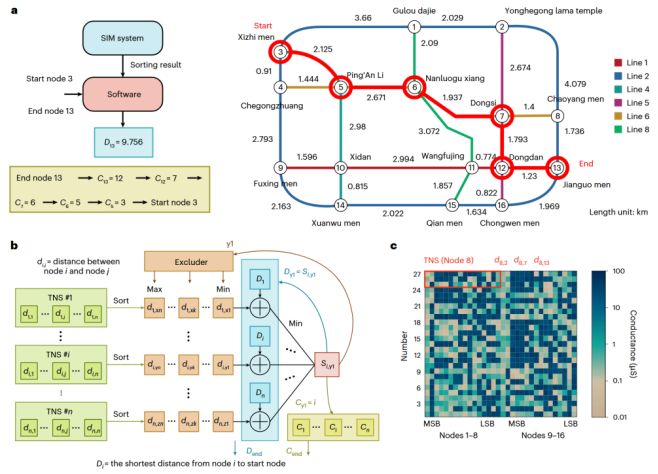
图9 Dijkstra算法应用场景与流程示意
如图9所示,MSIM系统被直接嵌入到Dijkstra算法的核心(Min)环节。即便是在每次迭代仅需对少数几个邻近节点进行排序的小规模任务上,MSIM系统依然展现出了巨大的优势。下图的性能对比直观地反映了这一点。
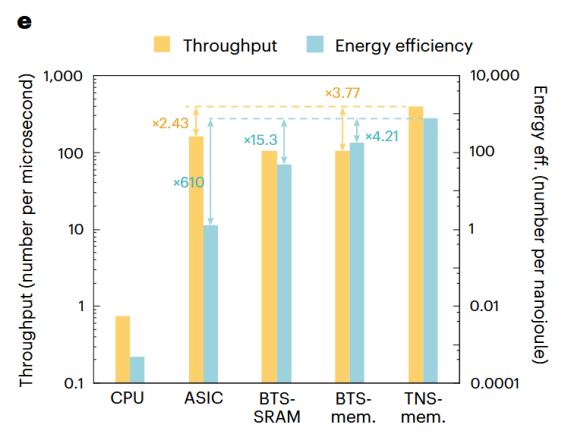
图10 最短路径搜索任务性能对比
实验结果令人印象深刻。与传统的ASIC方案相比,MSIM系统在执行Dijkstra算法时的能效提升了高达610倍。这充分说明,该架构通过根除数据搬运开销,在处理这类由大量细粒度排序主导的算法时,能够发挥出决定性的作用。
其次,团队将该技术应用于神经网络推理中的运行时原位剪枝。在边缘设备上运行庞大的神经网络,通常需要“剪枝”掉其中数值较小的权重。下图清晰地展示了传统剪枝方案与本文提出的“原位(in-situ)”剪枝方案的根本区别。
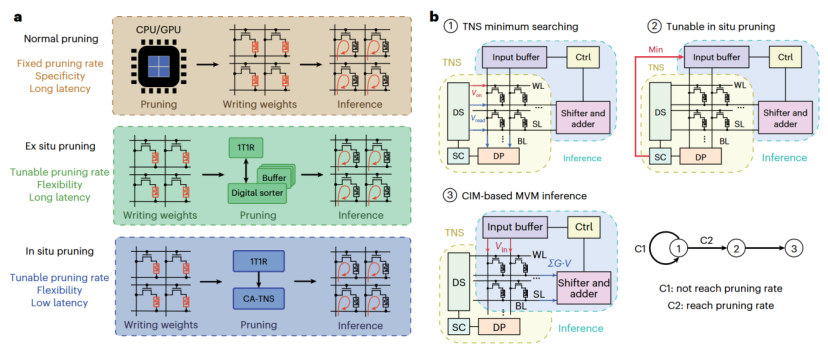
图11 剪枝方案对比与原位剪枝流程
传统的“异位(ex-situ)”方案(图11左上)需要将权重数据从存内计算阵列搬运到外部的数字排序器,这个过程会引入额外的延迟、功耗和面积开销。而本文提出的“原位”方案(图11右侧)则完美地解决了这一痛点。它首先利用TNS在存储权重的忆阻器阵列中找出绝对值最小的一批权重并进行标记,随后在同一个阵列中进行存内乘加运算,并直接屏蔽掉这些被标记权重所对应的计算,实现了零数据搬运的、低开销的动态剪枝。
这种动态剪枝的灵活性至关重要,因为在实际任务中,为了达到最佳效果,剪枝率往往需要根据不同的识别对象进行调整。
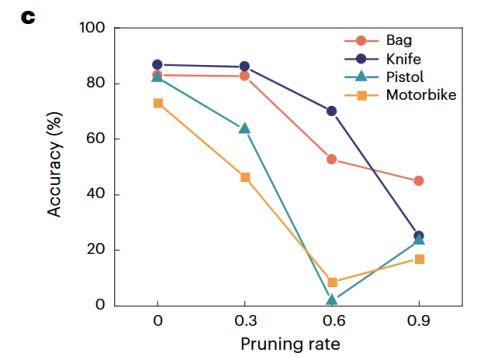
图12 剪枝率与模型精度的关系
为了在硬件上精确实现这一过程,团队对忆阻器进行了精细的编程与验证,确保写入的权重数据能够准确反映其数值,并且硬件实现的模型精度与纯软件计算的结果高度一致。
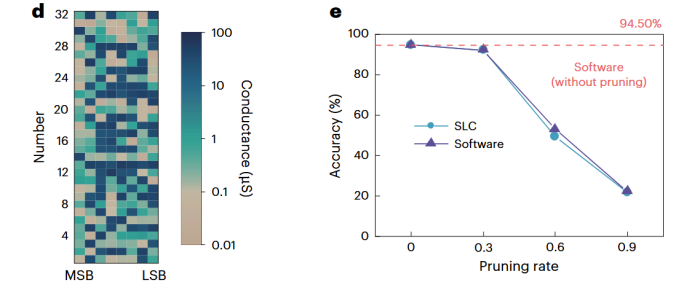
图13 硬件实现细节与精度验证
在验证了方案的可行性之后,最终的性能测试结果展示了其巨大的应用优势。
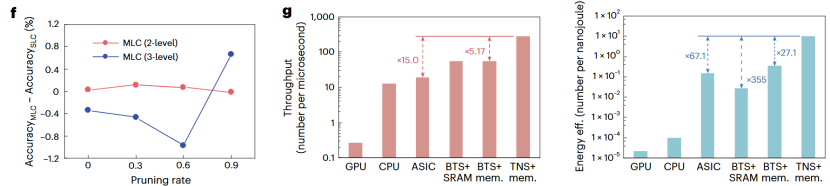
图14 原位剪枝任务性能对比
从最终的性能数据可以看出,这种原位剪枝方案取得了显著成功。相较于使用SRAM或ASIC数字排序器的方案,MSIM系统在吞吐率和能效上都实现了超过一个数量级的提升。这个应用案例不仅展示了MSIM的性能优势,更重要的是证明了它能够与主流的存内计算(CIM)范式无缝集成,将存算一体技术的能力从传统的线性运算(乘加)扩展到了更复杂的非线性数据处理(排序),极大地拓宽了存算一体芯片的应用边界。
(三)总结与展望
本文介绍了一种基于忆阻器的软硬件协同设计的存内排序(SIM)系统,其核心目标在于彻底消除传统排序中的比较单元及其相关的数据传输开销。为此,研究团队开发了创新的树节点跳跃(TNS)技术来优化基于迭代式最小/最大值搜索的无比较器排序流程,并考虑了诸如重复数字和末位数字等特殊情况。为了让该技术能够支持实际应用中各种不同的数据量、数据类型和数据精度,研究团队进一步将基础的TNS扩展为跨阵列的CA-TNS策略,通过多区块(MB)策略提升数字级并行度,通过位切片(BS)策略改善比特级并行度,并通过多值(ML)策略来提高存储密度与器件级并行度,从而有效解决了实际应用中的可扩展性问题。这项工作的突破性意义在于,它直击了传统冯·诺依曼架构下排序任务所面临的带宽、内存和海量比较器三大瓶颈,实验结果也充分证明,该MSIM系统能够在多个经典排序基准测试和真实世界应用中,显著提升排序速度、能效与面积效率。这项研究不仅展示了解决实际排序问题的强大能力,更证明了其能够与主流的存内乘加(MVM)计算范式高效集成,这为其作为下一代计算架构的关键组成部分铺平了道路。
事实上,存算一体的产业化浪潮已经到来。以国内存算一体领军企业知存科技为例,其全球首颗量产商用的存内计算SoC芯片WTM2101,已采用28nm制程成功将神经网络部署于芯片内,实现了满足端侧算力需求的语音识别等功能,在高能效AI应用场景中显示出巨大潜力。其后续面向更高算力市场的WTM-8系列芯片,更是能够实现图像AI超分、插帧及HDR识别检测这类更为复杂的功能。这些成果,连同其他前沿研究已经证明存算一体技术具备了实现16bit乃至32bit浮点计算的能力,标志着它已具备进入高算力芯片市场的实力。


图15 知存科技WTM-8与WTM2101存算芯片
可以预见,当本文所提出的、颠覆性的存内排序能力与这些已成功商业化的存内计算单元相结合时,未来的芯片将不再仅仅是一个被动的计算加速器。它将能够在内存中直接完成对海量非结构化数据的筛选、排序与过滤,并无缝衔接后续的AI分析与决策,让存储器真正从“仓库”蜕变为具备主动认知能力的“智慧中枢”。这正是从“存算”迈向“知存”的关键一步,它将为构建更接近人脑信息处理方式的全新计算架构,开启无限可能。
参考文献
- 北京大学信息工程学院/广东省存算一体芯片重点实验室杨玉超教授团队在国际上首次攻克大数据排序存算一体硬件系统-北京大学信息工程学院官网.
- Yu, L., Zhang, T., Wang, Z. et al. A fast and reconfigurable sort-in-memory system based on memristors. Nat Electron 8, 597–609 (2025). https://doi.org/10.1038/s41928-025-01405-2.