【完整源码+数据集+部署教程】粘土石实例分割系统源码和数据集:改进yolo11-LVMB
背景意义
随着计算机视觉技术的迅猛发展,实例分割作为一种重要的图像处理任务,越来越受到研究者和工业界的关注。实例分割不仅能够识别图像中的物体类别,还能精确地分割出每个物体的轮廓,为后续的图像分析和理解提供了丰富的信息。在众多实例分割算法中,YOLO(You Only Look Once)系列模型因其高效性和实时性而备受青睐。特别是YOLOv11的出现,进一步提升了目标检测和实例分割的性能,使其在各种应用场景中展现出强大的能力。
本研究旨在基于改进的YOLOv11模型,构建一个针对粘土石(claystone)实例分割的系统。粘土石作为一种重要的地质材料,广泛应用于建筑、工程和环境保护等领域。准确识别和分割粘土石的图像,不仅有助于地质勘探和资源评估,还能为环境监测和土壤保护提供科学依据。因此,开发一个高效的粘土石实例分割系统具有重要的理论价值和实际意义。
本项目所使用的数据集包含2600幅粘土石的图像,所有图像均经过精细标注,确保了模型训练的高质量。通过对数据集的深入分析与处理,我们可以有效提升模型的学习能力和泛化性能。此外,采用数据增强技术,能够进一步丰富训练样本,提高模型在不同环境下的适应性。
在此背景下,基于改进YOLOv11的粘土石实例分割系统的研究,不仅能够推动计算机视觉技术在地质领域的应用,也为实例分割技术的进一步发展提供了新的思路和方法。通过本研究,我们期望能够为相关领域的研究者和工程师提供一种高效、可靠的工具,助力于更好地理解和利用粘土石资源。
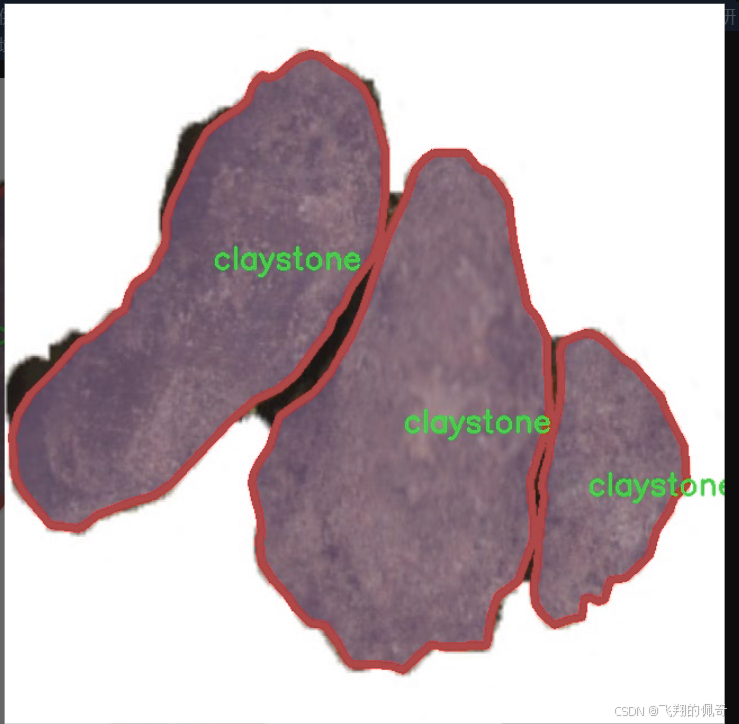
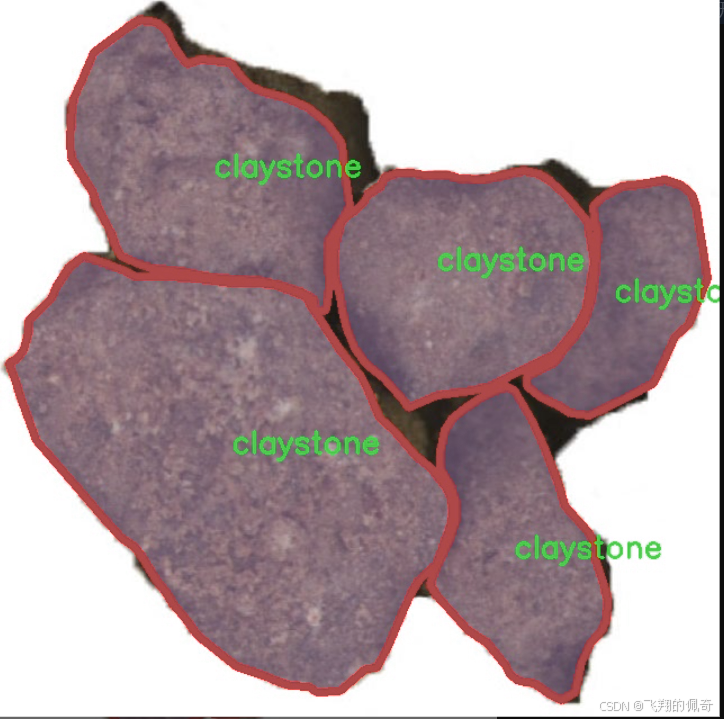
图片效果
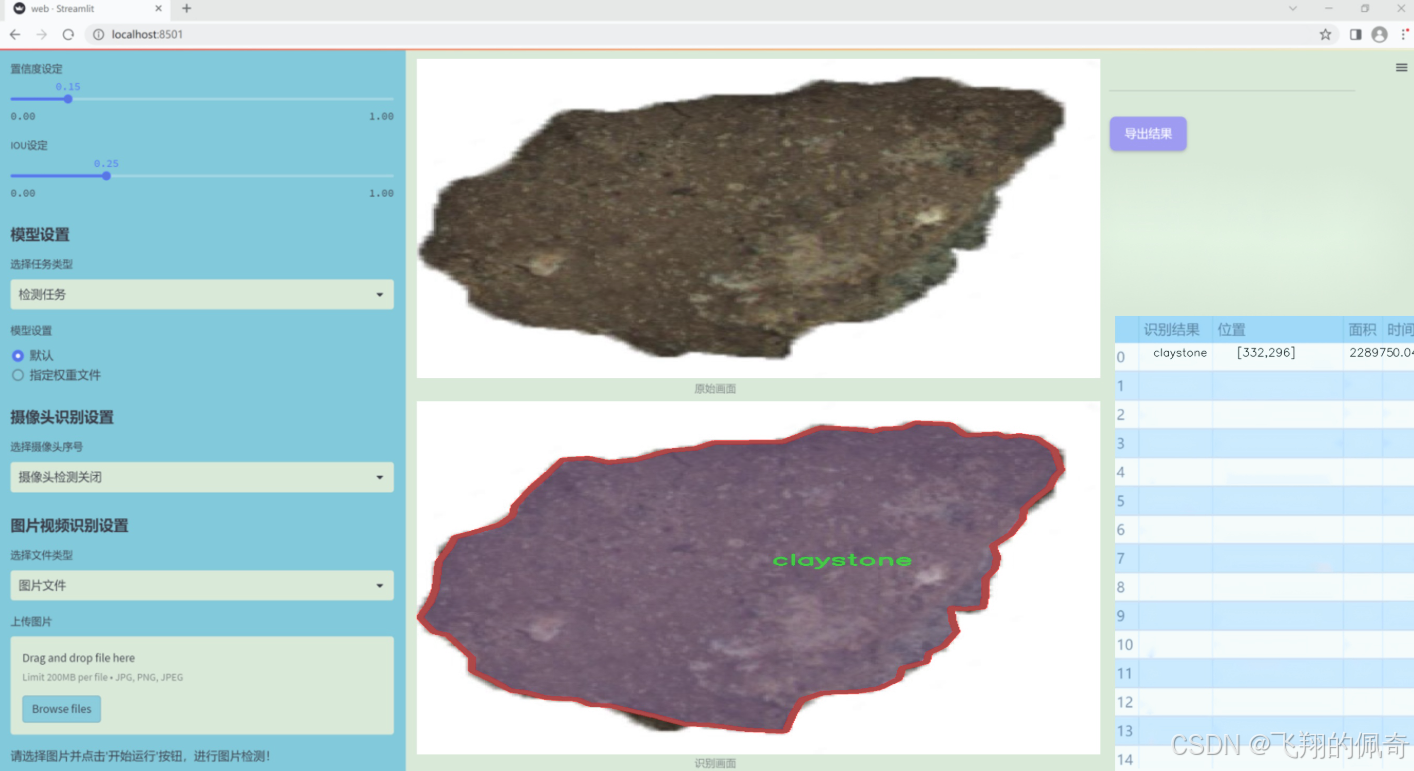

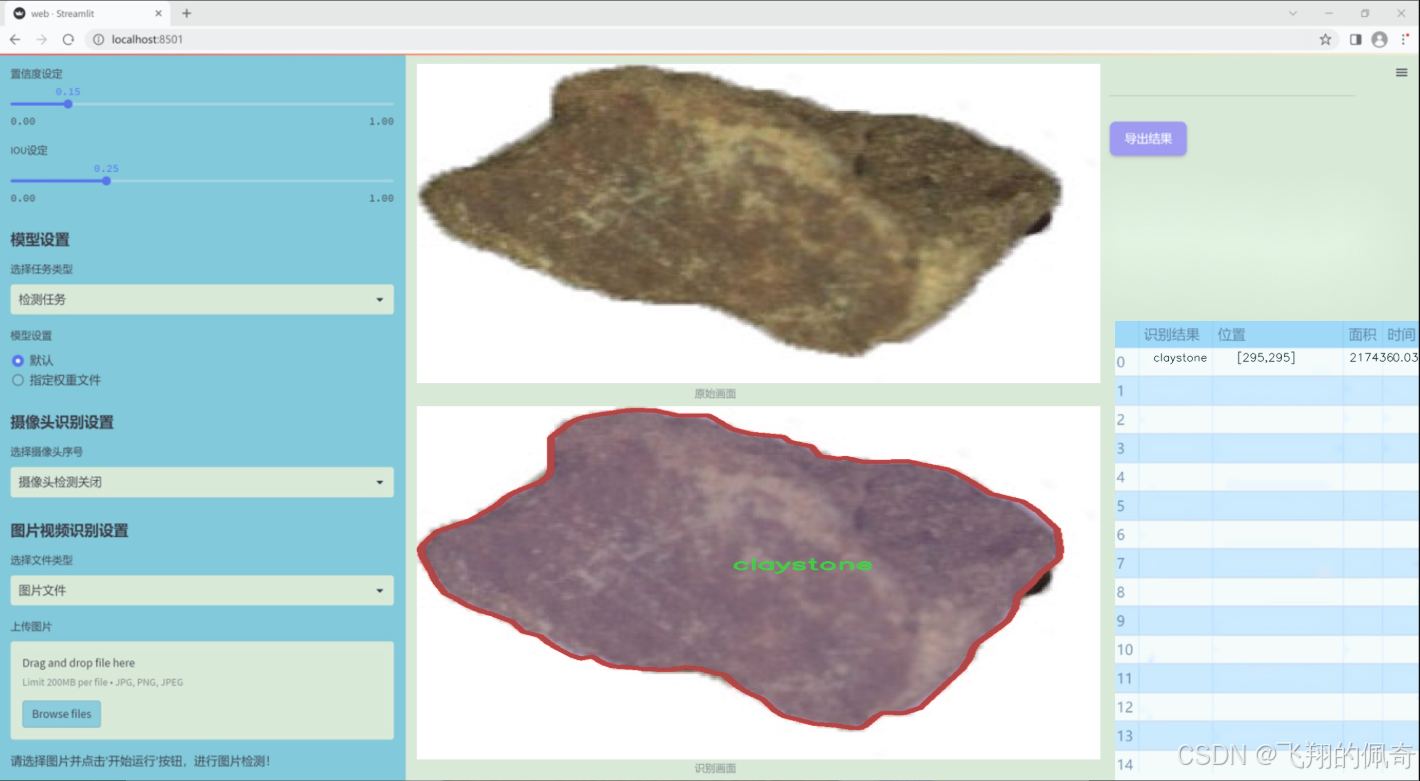
数据集信息
本项目数据集信息介绍
本项目所使用的数据集名为“claystone_UniversityDesign”,旨在为改进YOLOv11的粘土石实例分割系统提供高质量的训练数据。该数据集专注于单一类别的物体识别与分割,具体类别为“claystone”,其独特的地质特征使其在环境科学、地质工程以及材料科学等领域具有重要的研究价值。数据集中包含了多种不同形态、颜色和纹理的粘土石样本,这些样本通过精心的采集和标注,确保了数据的多样性和代表性。
在数据集的构建过程中,研究团队采用了高分辨率的图像采集技术,以捕捉粘土石的细微特征。这些图像不仅涵盖了不同光照条件下的样本,还包括了多种背景环境,旨在提高模型在实际应用中的鲁棒性和适应性。此外,数据集中的每一张图像都经过了严格的标注,确保每个粘土石实例都能被准确识别和分割。这种精细的标注工作为YOLOv11模型的训练提供了坚实的基础,使其能够有效地学习到粘土石的特征。
通过使用“claystone_UniversityDesign”数据集,研究人员希望能够显著提升YOLOv11在粘土石实例分割任务中的性能。该数据集不仅为模型的训练提供了丰富的样本,还为后续的测试和验证提供了可靠的数据支持。最终,期望通过本项目的研究成果,推动粘土石相关领域的自动化识别与分析技术的发展,为地质研究和工程应用提供更为高效的解决方案。
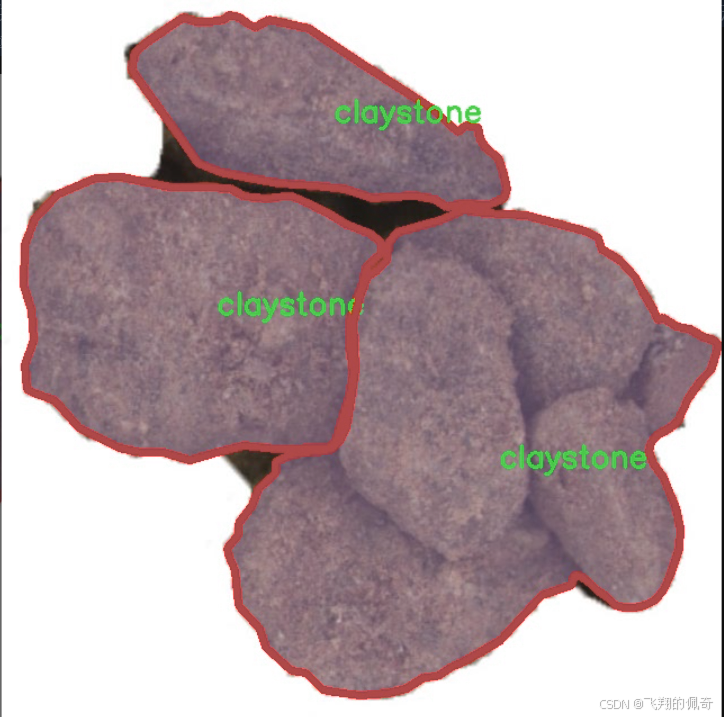
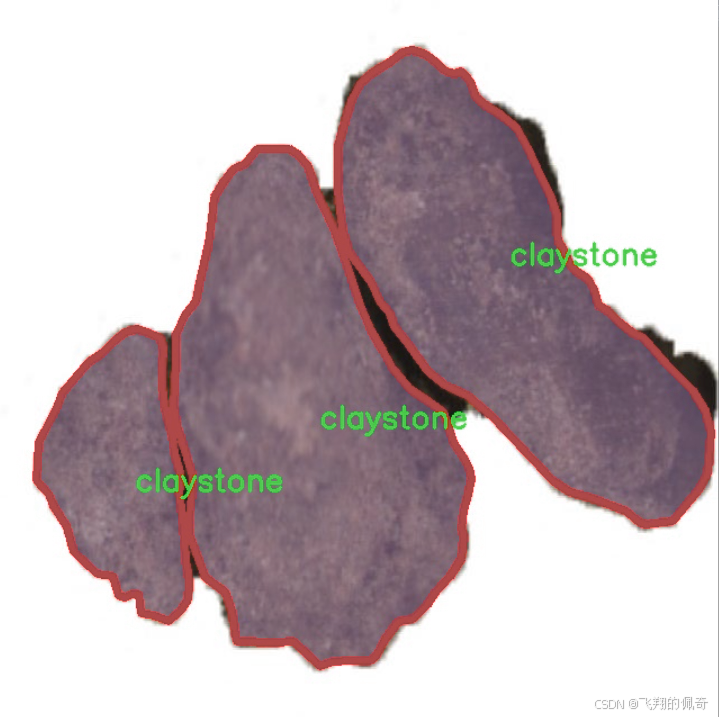
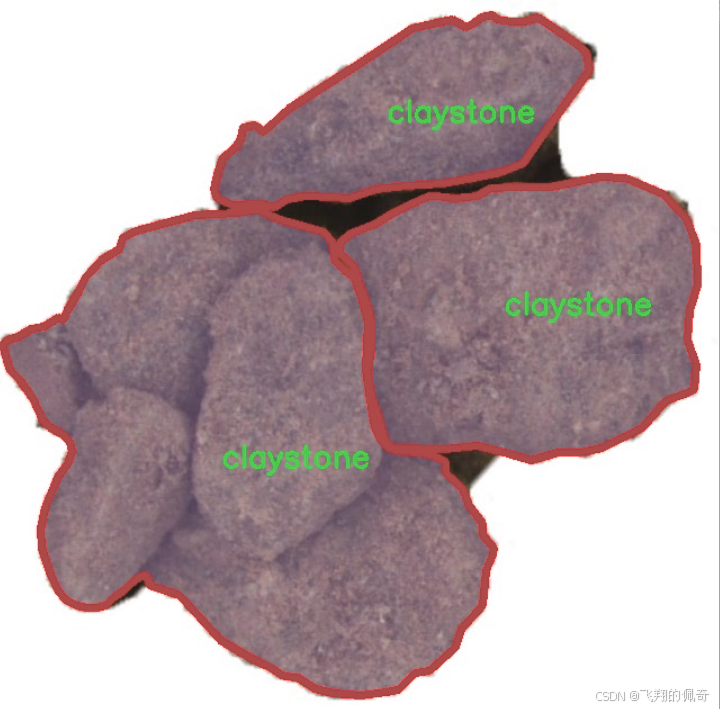
核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
from functools import partial
class Mlp(nn.Module):
“”“多层感知机(MLP)模块”“”
def init(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().init()
out_features = out_features or in_features # 输出特征数
hidden_features = hidden_features or in_features # 隐藏层特征数
self.fc1 = nn.Conv2d(in_features, hidden_features, 1) # 第一层卷积
self.dwconv = DWConv(hidden_features) # 深度卷积
self.act = act_layer() # 激活函数
self.fc2 = nn.Conv2d(hidden_features, out_features, 1) # 第二层卷积
self.drop = nn.Dropout(drop) # Dropout层
def forward(self, x):"""前向传播"""x = self.fc1(x) # 通过第一层卷积x = self.dwconv(x) # 通过深度卷积x = self.act(x) # 激活x = self.drop(x) # Dropoutx = self.fc2(x) # 通过第二层卷积x = self.drop(x) # Dropoutreturn x
class Attention(nn.Module):
“”“注意力模块”“”
def init(self, d_model):
super().init()
self.proj_1 = nn.Conv2d(d_model, d_model, 1) # 投影层1
self.activation = nn.GELU() # 激活函数
self.spatial_gating_unit = LSKblock(d_model) # 空间门控单元
self.proj_2 = nn.Conv2d(d_model, d_model, 1) # 投影层2
def forward(self, x):"""前向传播"""shortcut = x.clone() # 保存输入用于残差连接x = self.proj_1(x) # 通过投影层1x = self.activation(x) # 激活x = self.spatial_gating_unit(x) # 通过空间门控单元x = self.proj_2(x) # 通过投影层2x = x + shortcut # 残差连接return x
class Block(nn.Module):
“”“基本块,包括注意力和MLP”“”
def init(self, dim, mlp_ratio=4., drop=0., drop_path=0., act_layer=nn.GELU):
super().init()
self.norm1 = nn.BatchNorm2d(dim) # 第一个归一化层
self.norm2 = nn.BatchNorm2d(dim) # 第二个归一化层
self.attn = Attention(dim) # 注意力模块
self.mlp = Mlp(in_features=dim, hidden_features=int(dim * mlp_ratio), act_layer=act_layer, drop=drop) # MLP模块
def forward(self, x):"""前向传播"""x = x + self.attn(self.norm1(x)) # 注意力模块x = x + self.mlp(self.norm2(x)) # MLP模块return x
class LSKNet(nn.Module):
“”“LSKNet模型”“”
def init(self, img_size=224, in_chans=3, embed_dims=[64, 128, 256, 512], depths=[3, 4, 6, 3]):
super().init()
self.num_stages = len(depths) # 模型阶段数
for i in range(self.num_stages):
# 每个阶段的嵌入层和块
patch_embed = OverlapPatchEmbed(img_size=img_size // (2 ** i), in_chans=in_chans if i == 0 else embed_dims[i - 1], embed_dim=embed_dims[i])
block = nn.ModuleList([Block(dim=embed_dims[i]) for _ in range(depths[i])])
setattr(self, f"patch_embed{i + 1}“, patch_embed)
setattr(self, f"block{i + 1}”, block)
def forward(self, x):"""前向传播"""outs = []for i in range(self.num_stages):patch_embed = getattr(self, f"patch_embed{i + 1}")block = getattr(self, f"block{i + 1}")x, _, _ = patch_embed(x) # 通过嵌入层for blk in block:x = blk(x) # 通过每个块outs.append(x) # 保存输出return outs
class DWConv(nn.Module):
“”“深度卷积模块”“”
def init(self, dim=768):
super(DWConv, self).init()
self.dwconv = nn.Conv2d(dim, dim, 3, padding=1, groups=dim) # 深度卷积
def forward(self, x):"""前向传播"""return self.dwconv(x) # 通过深度卷积
模型创建函数
def lsknet_t():
“”“创建LSKNet_t模型”“”
return LSKNet(embed_dims=[32, 64, 160, 256], depths=[3, 3, 5, 2])
if name == ‘main’:
model = lsknet_t() # 实例化模型
inputs = torch.randn((1, 3, 640, 640)) # 随机输入
outputs = model(inputs) # 前向传播
for output in outputs:
print(output.size()) # 打印输出尺寸
代码说明:
Mlp:实现了一个多层感知机,包括两层卷积和一个深度卷积,以及激活和Dropout层。
Attention:实现了一个注意力机制模块,包含两个投影层和一个空间门控单元。
Block:将注意力模块和MLP模块结合在一起,形成一个基本的构建块。
LSKNet:主网络结构,包含多个阶段,每个阶段由嵌入层和多个基本块组成。
DWConv:实现了深度卷积,用于特征提取。
lsknet_t:创建LSKNet_t模型的函数。
以上是核心部分的代码和详细注释,提供了对模型结构和功能的清晰理解。
这个程序文件 lsknet.py 实现了一个名为 LSKNet 的深度学习模型,主要用于图像处理任务。代码中使用了 PyTorch 框架,并包含了多个类和函数来构建和训练这个模型。
首先,程序导入了必要的库,包括 PyTorch 的核心模块和一些实用工具。接着,定义了一个名为 Mlp 的类,它是一个多层感知机(MLP),包含两个卷积层和一个深度卷积层,使用 GELU 激活函数和 Dropout 层来防止过拟合。
然后,定义了 LSKblock 类,这是 LSKNet 的核心模块之一。它通过深度可分离卷积和空间卷积来提取特征,并通过自适应的注意力机制对特征进行加权。这个模块使用了两个卷积层来处理输入特征,并结合了平均池化和最大池化的结果,最终通过 Sigmoid 函数生成注意力权重。
接下来是 Attention 类,它负责实现注意力机制。该类首先通过一个卷积层对输入进行投影,然后经过激活函数和 LSKblock 处理,最后再通过另一个卷积层进行投影,并将结果与输入进行相加,形成残差连接。
Block 类则是将注意力机制和 MLP 结合在一起的模块。它包含了两个归一化层和一个 DropPath 层,用于实现随机深度的效果。通过对输入进行归一化、注意力计算和 MLP 处理,最后通过残差连接输出结果。
OverlapPatchEmbed 类用于将输入图像转换为补丁嵌入。它通过卷积层将图像划分为多个补丁,并进行归一化处理,以便后续的网络层使用。
LSKNet 类是整个模型的主体,负责构建不同阶段的网络结构。它通过循环创建多个嵌入层、块和归一化层,并在前向传播时依次处理输入数据,最终输出不同阶段的特征图。
DWConv 类实现了深度卷积操作,主要用于 Mlp 类中的深度卷积层。
此外,程序还定义了两个函数 update_weight 和 lsknet_t、lsknet_s,用于加载预训练模型的权重。update_weight 函数用于更新模型字典中的权重,而 lsknet_t 和 lsknet_s 函数则分别构建不同配置的 LSKNet 模型,并在需要时加载权重。
最后,在 main 块中,程序实例化了一个 LSKNet 模型,并生成了一个随机输入以测试模型的输出尺寸。整体来看,这个程序文件实现了一个复杂的深度学习模型,结合了多种卷积和注意力机制,适用于图像分类或其他相关任务。
10.3 activation.py
import torch
import torch.nn as nn
class AGLU(nn.Module):
“”“AGLU激活函数模块,来源于https://github.com/kostas1515/AGLU。”“”
def __init__(self, device=None, dtype=None) -> None:"""初始化AGLU激活函数模块。"""super().__init__()# 使用Softplus作为基础激活函数,beta设为-1.0self.act = nn.Softplus(beta=-1.0)# 初始化lambda参数,确保其在训练过程中可学习self.lambd = nn.Parameter(nn.init.uniform_(torch.empty(1, device=device, dtype=dtype))) # lambda参数# 初始化kappa参数,确保其在训练过程中可学习self.kappa = nn.Parameter(nn.init.uniform_(torch.empty(1, device=device, dtype=dtype))) # kappa参数def forward(self, x: torch.Tensor) -> torch.Tensor:"""计算AGLU激活函数的前向传播。"""# 将lambda参数限制在最小值0.0001,以避免数值不稳定lam = torch.clamp(self.lambd, min=0.0001)# 计算AGLU激活函数的输出return torch.exp((1 / lam) * self.act((self.kappa * x) - torch.log(lam)))
代码核心部分及注释说明:
导入必要的库:
torch和torch.nn是PyTorch库中的核心模块,用于构建和训练神经网络。
AGLU类定义:
该类继承自nn.Module,表示一个自定义的神经网络模块。
初始化方法__init__:
self.act:定义了一个Softplus激活函数,beta参数设置为-1.0。
self.lambd和self.kappa:这两个参数是可学习的参数,使用均匀分布初始化,并允许在训练过程中更新。
前向传播方法forward:
lam:使用torch.clamp将lambda参数限制在0.0001以上,以防止在计算过程中出现数值不稳定。
返回值:计算AGLU激活函数的输出,使用指数函数和Softplus激活函数的组合。
这个程序文件名为 activation.py,主要定义了一个名为 AGLU 的激活函数模块。该模块是基于一个统一的激活函数,来源于一个开源项目,地址为 https://github.com/kostas1515/AGLU。
在文件中,首先导入了必要的库,包括 torch 和 torch.nn,这两个库是 PyTorch 框架的核心部分,提供了深度学习所需的各种功能和模块。
AGLU 类继承自 nn.Module,这是 PyTorch 中所有神经网络模块的基类。在 init 方法中,初始化了激活函数的相关参数。具体来说,使用了 nn.Softplus 作为激活函数的一部分,并且定义了两个可学习的参数 lambd 和 kappa,这两个参数在模型训练过程中会被优化。它们的初始值是通过均匀分布随机初始化的,确保它们在指定的设备(如 CPU 或 GPU)和数据类型下创建。
在 forward 方法中,定义了前向传播的计算过程。输入的张量 x 会经过一系列操作。首先,对 lambd 参数进行限制,确保其最小值为 0.0001,以避免数值不稳定。接着,计算激活函数的输出,使用了指数函数和 Softplus 函数的组合,结合了 kappa 和 lambd 参数。这种设计使得激活函数能够根据输入动态调整,从而可能提高模型的表现。
总的来说,这个文件实现了一个自定义的激活函数模块,旨在为深度学习模型提供更灵活的激活机制,可能在某些任务中表现得更好。
10.4 cfpt.py
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.layers import to_2tuple, trunc_normal_
class CrossLayerPosEmbedding3D(nn.Module):
def init(self, num_heads=4, window_size=(5, 3, 1), spatial=True):
super(CrossLayerPosEmbedding3D, self).init()
self.spatial = spatial # 是否使用空间位置嵌入
self.num_heads = num_heads # 注意力头的数量
self.layer_num = len(window_size) # 层数
# 初始化相对位置偏置表
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[0] - 1), num_heads))
)
# 计算相对位置索引
self.register_buffer(“relative_position_index”, self.calculate_relative_position_index(window_size))
trunc_normal_(self.relative_position_bias_table, std=.02) # 初始化相对位置偏置
# 初始化绝对位置偏置self.absolute_position_bias = nn.Parameter(torch.zeros(len(window_size), num_heads, 1, 1, 1))trunc_normal_(self.absolute_position_bias, std=.02)def calculate_relative_position_index(self, window_size):# 计算相对位置索引coords_h = [torch.arange(ws) - ws // 2 for ws in window_size]coords_w = [torch.arange(ws) - ws // 2 for ws in window_size]coords_flatten = torch.cat([torch.flatten(coord) for coord in coords_h + coords_w], dim=-1)relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]relative_coords = relative_coords.permute(1, 2, 0).contiguous()relative_coords[:, :, 0] += window_size[0] - 1relative_coords[:, :, 1] += window_size[0] - 1relative_coords[:, :, 0] *= 2 * window_size[0] - 1return relative_coords.sum(-1)def forward(self):# 前向传播,计算位置嵌入pos_indicies = self.relative_position_index.view(-1)pos_indicies_floor = torch.floor(pos_indicies).long()pos_indicies_ceil = torch.ceil(pos_indicies).long()value_floor = self.relative_position_bias_table[pos_indicies_floor]value_ceil = self.relative_position_bias_table[pos_indicies_ceil]weights_ceil = pos_indicies - pos_indicies_floor.float()weights_floor = 1.0 - weights_ceilpos_embed = weights_floor.unsqueeze(-1) * value_floor + weights_ceil.unsqueeze(-1) * value_ceilpos_embed = pos_embed.reshape(1, 1, -1, -1, self.num_heads).permute(0, 4, 1, 2, 3)return pos_embed
class CrossLayerSpatialAttention(nn.Module):
def init(self, in_dim, layer_num=3, num_heads=4):
super(CrossLayerSpatialAttention, self).init()
self.num_heads = num_heads # 注意力头的数量
self.token_num_per_layer = [i ** 2 for i in range(layer_num)] # 每层的token数量
self.token_num = sum(self.token_num_per_layer) # 总token数量
# 定义各层的卷积、归一化和线性变换self.cpe = nn.ModuleList([ConvPosEnc(dim=in_dim, k=3) for _ in range(layer_num)])self.norm1 = nn.ModuleList([nn.LayerNorm(in_dim) for _ in range(layer_num)])self.qkv = nn.ModuleList([nn.Conv2d(in_dim, in_dim * 3, kernel_size=1) for _ in range(layer_num)])self.softmax = nn.Softmax(dim=-1)def forward(self, x_list):# 前向传播,计算空间注意力q_list, k_list, v_list = [], [], []for i, x in enumerate(x_list):x = self.cpe[i](x) # 应用卷积位置编码qkv = self.qkv[i](x) # 计算Q、K、Vq, k, v = qkv.chunk(3, dim=1) # 分割Q、K、Vq_list.append(q)k_list.append(k)v_list.append(v)# 将Q、K、V堆叠q_stack = torch.cat(q_list, dim=1)k_stack = torch.cat(k_list, dim=1)v_stack = torch.cat(v_list, dim=1)# 计算注意力attn = F.normalize(q_stack, dim=-1) @ F.normalize(k_stack, dim=-1).transpose(-1, -2)attn = self.softmax(attn)# 计算输出out = attn @ v_stackreturn out
class ConvPosEnc(nn.Module):
def init(self, dim, k=3):
super(ConvPosEnc, self).init()
self.proj = nn.Conv2d(dim, dim, kernel_size=k, padding=k // 2, groups=dim) # 深度卷积
self.activation = nn.GELU() # 激活函数
def forward(self, x):return x + self.activation(self.proj(x)) # 残差连接
代码说明:
CrossLayerPosEmbedding3D:这个类用于计算位置嵌入,包含相对位置偏置和绝对位置偏置的初始化和计算。
CrossLayerSpatialAttention:这个类实现了跨层空间注意力机制,使用卷积、归一化和线性变换来计算注意力。
ConvPosEnc:这个类实现了卷积位置编码,通过深度卷积和激活函数对输入进行处理,并添加残差连接。
这些部分是实现跨层注意力机制的核心,涉及到位置编码和注意力计算的关键步骤。
这个程序文件 cfpt.py 定义了一个用于深度学习的模型,主要实现了跨层的通道注意力和空间注意力机制。程序中使用了 PyTorch 框架,并且结合了一些数学运算和张量操作,以便于在图像处理或计算机视觉任务中使用。
首先,文件中引入了一些必要的库,包括 torch、math、einops 和 torch.nn 等。接着,定义了几个类和函数,构成了模型的基础。
LayerNormProxy 类是一个简单的层归一化模块,它将输入的张量进行维度重排,然后应用 nn.LayerNorm 进行归一化,最后再将张量重排回原来的形状。
CrossLayerPosEmbedding3D 类用于生成跨层的三维位置嵌入。它根据输入的窗口大小和头数,计算相对位置偏置,并通过正态分布初始化位置偏置表。该类的 forward 方法生成位置嵌入,用于后续的注意力计算。
ConvPosEnc 类实现了卷积位置编码,它通过卷积操作对输入特征进行处理,并可选择性地应用激活函数。DWConv 类实现了深度卷积,用于处理输入的特征图。
Mlp 类实现了一个简单的多层感知机,包含两个线性层和一个激活函数。它可以用于特征的非线性变换。
接下来,定义了一些用于处理窗口的函数,如 overlaped_window_partition 和 overlaped_window_reverse,这些函数用于在处理特征图时进行窗口划分和重组。
CrossLayerSpatialAttention 类实现了跨层的空间注意力机制。它接收多个层的特征图,通过卷积、归一化和注意力计算来生成输出特征。注意力机制的实现依赖于前面定义的位置嵌入和多头注意力机制。
CrossLayerChannelAttention 类实现了跨层的通道注意力机制,类似于空间注意力,但它处理的是通道维度的特征。它同样使用卷积和归一化,并通过注意力机制对特征进行加权。
总体来说,这个程序文件实现了一个复杂的深度学习模型,结合了多种注意力机制和特征处理方法,适用于图像处理和计算机视觉等任务。通过使用这些模块,用户可以在特定的任务中构建更为强大的模型。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻