Meta AIUCSD放大招:DeepConf 让大语言模型推理既快又准,84.7%的token节省+近乎完美的准确率!
1. 【前言】

大语言模型(LLMs) 在推理任务中通过自一致性等测试时缩放方法展现出巨大潜力,但存在精度收益递减和计算开销高的问题。为此,Meta与UCSD的研究人员提出DeepConf方法,它利用模型内部的置信度信号,在生成过程中或生成后动态过滤低质量推理轨迹,无需额外模型训练或超参数调优,可无缝集成到现有服务框架中。在多种推理任务和最新开源模型(如Qwen 3和GPT-OSS系列)上的评估显示,DeepConf在挑战性基准测试(如AIME 2025)中表现优异,DeepConf@512的准确率高达99.9%,与完全并行思维相比,生成的** tokens减少多达84.7%,显著提升了推理效率**和性能。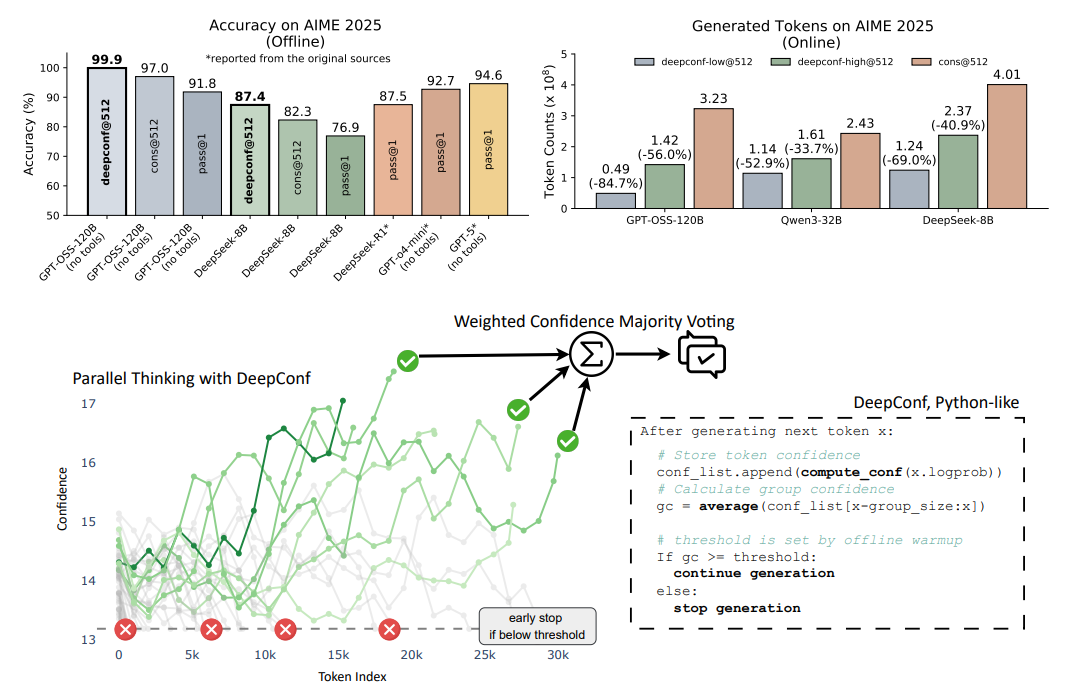
2. 【论文基本信息】

论文标题:Deep Think with Confidence
论文链接:https://arxiv.org/html/2508.15260v1 项目链接:jiaweizzhao.github.io/deepconf
3 论文背景
3.1 大语言模型推理的现状与挑战
大语言模型(LLMs)在推理任务中展现出显著潜力,尤其通过测试时缩放方法(如自一致性方法),即生成多条推理路径并通过多数投票聚合答案,可有效提升推理性能。然而,该类方法存在明显局限:一方面,随着推理轨迹数量增加,精度提升呈现递减趋势,甚至可能因低质量轨迹主导投票而导致性能下降;另一方面,生成大量推理轨迹会带来极高的计算开销,例如在AIME 2025任务中,使用Qwen3-8B模型将pass@1精度从68%提升至82%,需额外生成511条推理轨迹,消耗1亿个token,严重限制了实际部署。
3.2 现有置信度评估方法的不足
近年来,研究开始利用模型的下一个token分布统计(如熵、置信度分数)评估推理轨迹质量,通过聚合token级统计量计算全局置信度(如平均轨迹置信度),以筛选低质量轨迹。但全局置信度方法存在两大缺陷:一是掩盖了局部推理步骤的置信度波动,可能忽略关键的中间推理错误(如少数高置信度token掩盖大量低置信度片段);二是需生成完整轨迹才能计算,无法实现低质量轨迹的早期终止,导致计算效率低下。
3.3 DeepConf方法的提出动机
为解决上述问题,本文提出“Deep Think with Confidence(DeepConf)”方法。其核心思路是利用模型内部的局部置信度信号,在推理轨迹生成过程中或生成后动态过滤低质量轨迹。该方法无需额外模型训练或超参数调优,可无缝集成到现有服务框架中,旨在同时提升推理效率(减少生成token)和性能(提高精度),尤其针对复杂推理任务(如AIME 2025)实现高效优化。
4.【研究方法论】
4.1 推理质量的置信度指标
为了有效评估推理轨迹的质量,论文基于模型内部的token分布提出了多种置信度指标,具体如下:
Token熵(Token Entropy):给定语言模型在位置i的预测token分布 ,token熵定义为
,其中
表示词汇表中第j个token的概率。低熵表明分布集中,模型确定性高;高熵则反映预测的不确定性。
Token置信度(Token Confidence):将位置i的top-k个token的负平均对数概率定义为token置信度 ,k为所考虑的top token数量。高置信度对应分布集中和模型确定性高,低置信度则表示token预测的不确定性。
平均轨迹置信度(Average Trace Confidence):为了评估整个推理轨迹,对token级指标进行聚合,采用平均轨迹置信度(也称为自确定性)作为轨迹级质量度量,即 ,其中N是生成的token总数。该指标能有效区分正确和错误的推理路径,值越高表明正确性可能性越大,但存在掩盖中间推理失败和需完整轨迹才能评估的局限性。

4.2 DeepConf的置信度度量方法
为解决全局置信度度量的局限性,论文提出了多种捕捉局部中间步骤质量的置信度度量方法,具体如下:
组置信度(Group Confidence):通过在推理轨迹的重叠跨度上平均token置信度,量化中间推理步骤的置信度,提供更局部和平滑的信号。每个token与一个滑动窗口组 相关联,该组由n个先前的token组成(例如n=1024或2048),相邻窗口重叠。对于每个组
,其中
是组
底部10%组置信度(Bottom 10% Group Confidence):为捕捉极低置信度组的影响,轨迹置信度由轨迹内底部10%组置信度的平均值确定,即 ,其中
是置信度得分最低的10%组的集合。
最低组置信度(Lowest Group Confidence):考虑推理轨迹中最不自信的组的置信度,是底部10%组置信度的特例,仅基于最低置信度组估计轨迹质量,定义为 ,其中G是推理轨迹中所有token组的集合。
尾部置信度(Tail Confidence):通过关注推理轨迹的最后部分来评估其可靠性,基于推理质量在长思维链末端往往下降且最终步骤对正确结论至关重要的观察。尾部置信度 定义为
,其中
代表固定数量的token(例如2048)。
4.3 DeepConf的离线与在线思维方法

4.3.1 离线思维(Offline Thinking)
在离线思维中,每个问题的推理轨迹已生成,重点是聚合多个轨迹的信息以更好地确定最终答案,主要包括以下方法:
多数投票(Majority Voting):在标准多数投票中,每个推理轨迹的最终答案对最终决策的贡献相同。设T为所有生成轨迹的集合,对于每个 ,令answer(t)为从轨迹t中提取的答案字符串。每个候选答案a的得票数为
,其中
是指示函数。最终答案选择得票最高的那个,即
。
置信度加权多数投票(Confidence-Weighted Majority Voting):不再平等对待每个轨迹的投票,而是根据相关轨迹的置信度对每个最终答案进行加权。对于每个候选答案a,其总得票权重定义为 ,其中
是从上述讨论的置信度度量中选择的轨迹级置信度。选择加权得票最高的答案,该投票方案有利于高置信度轨迹支持的答案,从而减少不确定或低质量推理答案的影响。
置信度过滤(Confidence Filtering):除了加权多数投票外,还应用置信度过滤来集中关注高置信度推理轨迹。置信度过滤根据轨迹置信度得分选择前η百分比的轨迹,确保只有最可靠的路径对最终答案有贡献,提供η=10%和η=90%两种选择。 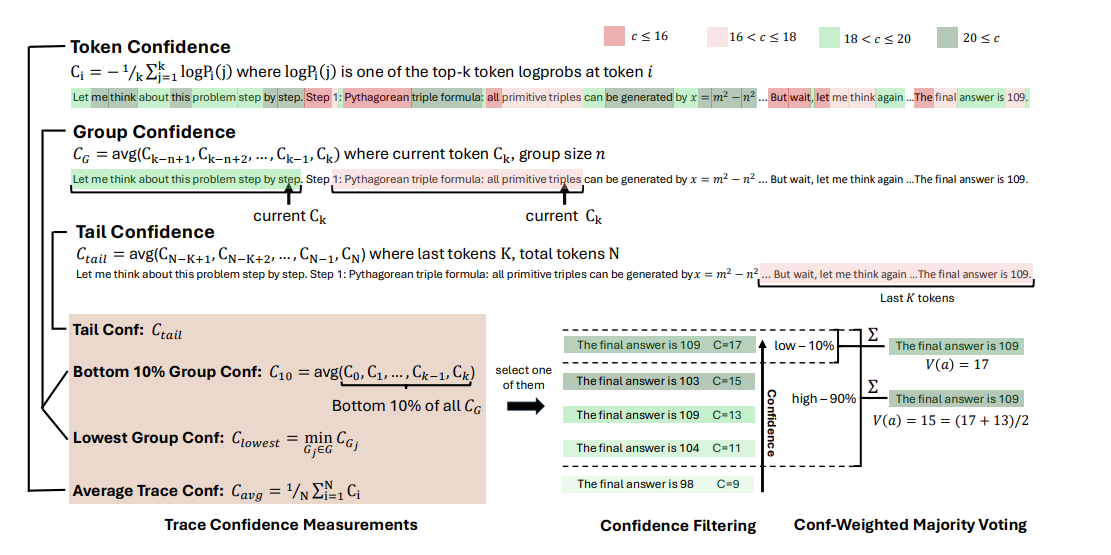
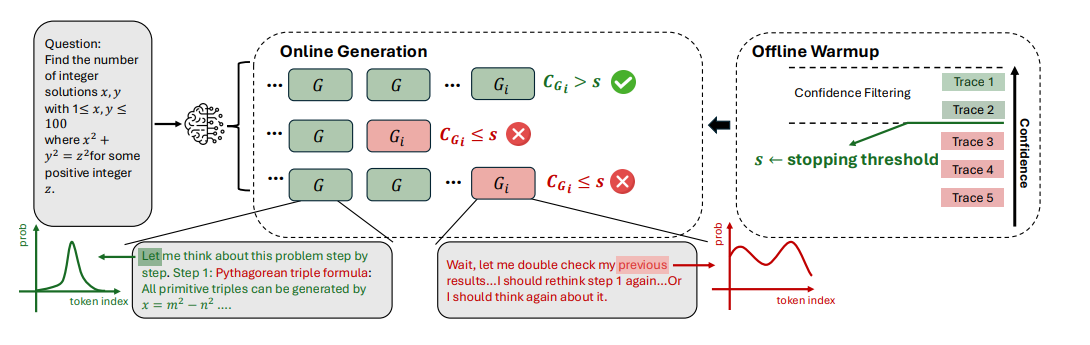
4.3.2 在线思维(Online Thinking)
在线思维过程中评估置信度,能够在生成过程中实时估计轨迹质量,从而动态终止无前景的轨迹,主要包括以下内容:
算法介绍:提出了基于最低组置信度的DeepConf-low和DeepConf-high两种算法,在在线思维中自适应地停止生成并调整轨迹预算,包括离线预热和自适应采样两个主要部分。 离线预热(Offline Warmup):DeepConf需要一个离线预热阶段来确定在线决策的停止阈值s。对于每个新提示,生成 个推理轨迹(例如
)。停止阈值s定义为
,其中
表示所有预热轨迹,
自适应采样(Adaptive Sampling):在DeepConf中,所有方法都采用自适应采样,根据问题难度动态调整生成的轨迹数量。难度通过生成轨迹之间的共识来评估,用量化多数投票权重 与总投票权重
的比率表示,即
。τ是预设的共识阈值。如果
,模型对当前问题未达成共识,轨迹生成将继续,直到达到固定的轨迹预算B。否则,轨迹生成停止,使用现有轨迹确定最终答案。 -
5.【实验结果】
5.1 实验设置
模型:评估5个开源LLM(DeepSeek-8B、Qwen3-8B/32B、GPT-OSS-20B/120B),覆盖多参数规模,侧重数学推理与长思维链能力。 数据集:5个高难度基准,含4个数学竞赛题(AIME24/25、BRUMO25、HMMT25)和1个研究生STEM推理任务(GPQA)。 基线与设置:以自一致性多数投票为基线,预生成4096条推理轨迹池,离线/在线实验分别重采样后应用投票方法,结果经64次独立运行平均,早期终止轨迹仅计停止前token。
5.2 离线评估结果
带过滤的置信度加权多数投票多数优于标准多数投票(Cons@512)。 η=10%过滤收益最大,如DeepSeek-8B在AIME25准确率从82.3%升至87.4%,GPT-OSS-120B在AIME25达99.9%。 局部与全局置信度度量均有效,但η=10%激进过滤可能因模型过度自信受损,η=90%更保守安全。 所有方法均优于pass@1,最低组置信度下,η=10%平均提升5.27个百分点(相对多数投票),η=90%平均提升0.29个百分点。 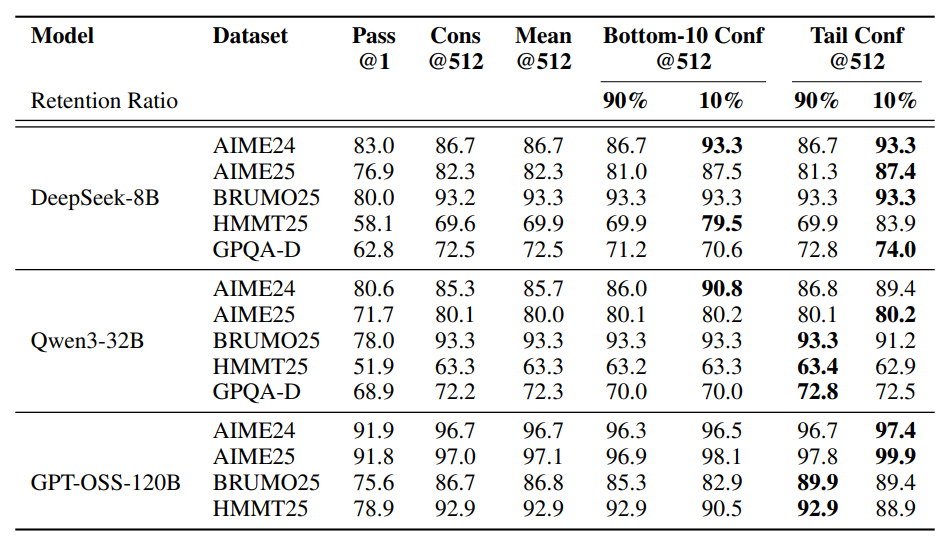

5.3 在线评估结果
K=512时,DeepConf-low减少43-79%token,多数情况提升准确率(如DeepSeek-8B在AIME24+5.8%),少数情况下降;DeepConf-high节省18-59%token,准确率基本不变。 GPT-OSS-120B上,DeepConf最高节省85.8%token,保持竞争力。 DeepSeek-8B上,DeepConf-low平均省62.88%token,DeepConf-high省47.67%,效率优势显著。 在线行为与离线一致,η=10%过滤增益最高,偶尔在特定数据集下降。
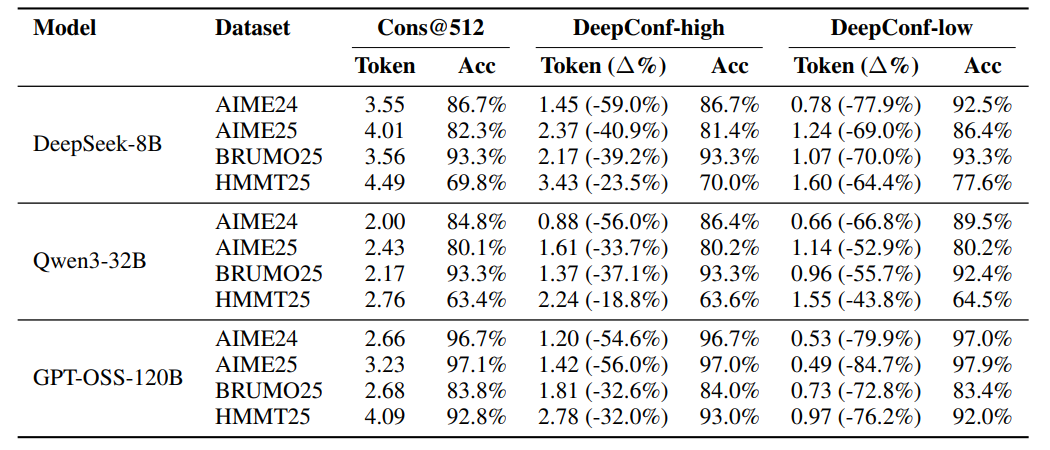
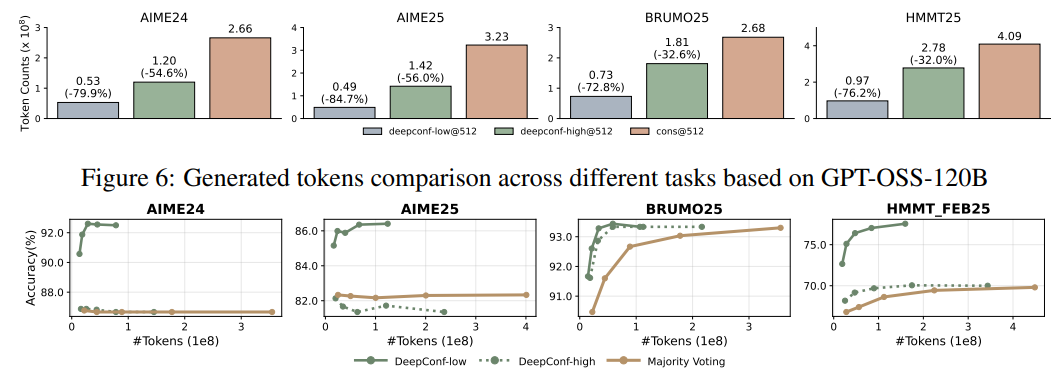
6.【总结展望】
6.1 总结
论文提出了Deep Think with Confidence(DeepConf)方法,旨在解决大型语言模型(LLMs)在推理任务中使用自一致性等测试时扩展方法存在的准确性收益递减和计算开销高的问题。DeepConf利用模型内部的置信度信号,在生成过程中或生成后动态过滤低质量的推理轨迹,无需额外的模型训练或超参数调优,可无缝集成到现有服务框架中。通过在多种推理任务和最新开源模型上的评估表明,在离线模式下,DeepConf@512使用GPT-OSS-120B在AIME 2025上达到99.9%的准确率;在在线模式下,与完全并行思维相比,可减少高达84.7%的生成token,同时保持或超过准确率,有效提升了推理效率和性能。
6.2 展望
未来工作有多个有前景的方向。一是将DeepConf扩展到强化学习场景,利用基于置信度的早期停止来指导策略探索,提高训练期间的样本效率。二是解决模型在错误推理路径上表现出高置信度的情况,这是实验中观察到的一个关键限制。此外,还可探索更 robust的置信度校准技术和不确定性量化方法,以更好地识别和缓解过度自信但错误的预测。