一款高效、强大的子域名爬取工具,帮助安全研究者和渗透测试人员快速收集目标域名的子域名信息
🐟 GoogleFirefoxDomain
一款高效、强大的子域名爬取工具,结合 Google 和 Firefox 浏览器的优势,帮助安全研究者和渗透测试人员快速收集目标域名的子域名信息。
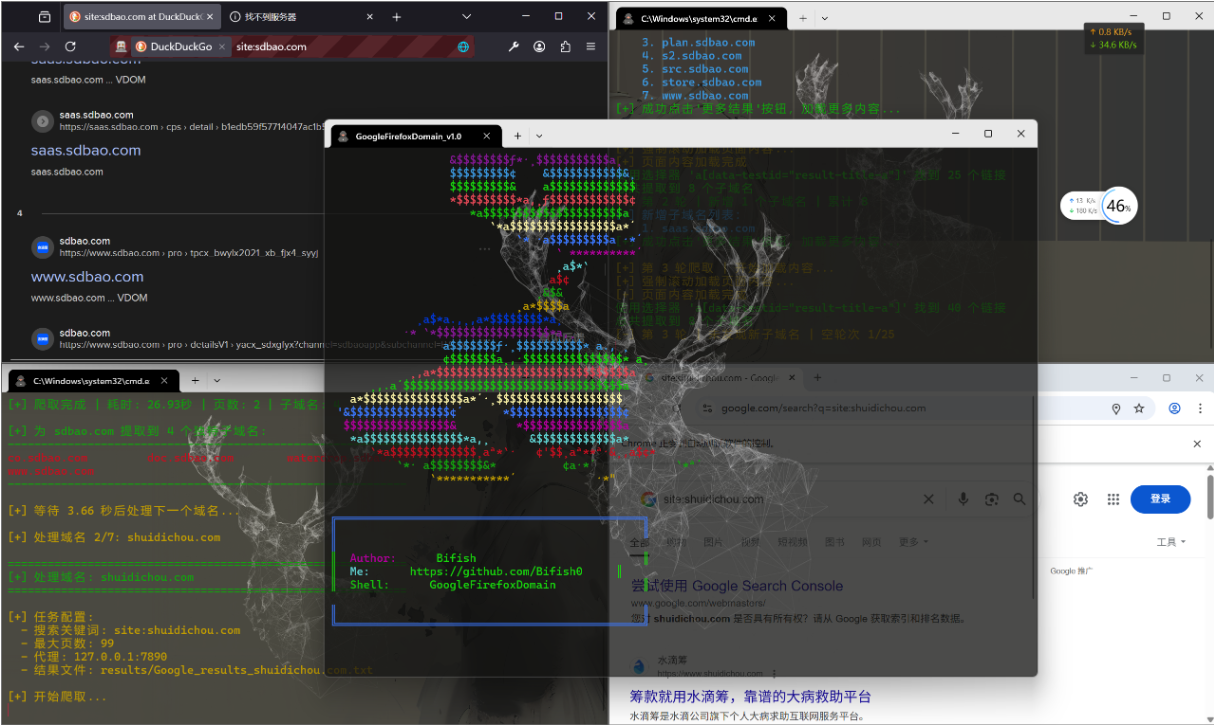
GoogleFirefoxDomain 是一款基于 Selenium 的子域名爬取工具,包含两个核心脚本:
GoogleDomain.py:利用Google搜索引擎爬取子域名,支持代理配置、多页爬取和自动重试
FirefoxDomain:基于 Firefox 浏览器,针对 DuckDuckGo 搜索引擎进行优化,修复了 “更多结果” 按钮点击问题
工具具备自动规避检测、模拟人类行为、结果自动保存和邮件通知等功能,为子域名收集工作提供全方位支持。
✨ 功能特点
通用特性
- 🔍 多搜索引擎支持(Google + DuckDuckGo)
- 🕵️ 反检测机制,模拟真实用户行为
- 📁 自动创建结果文件夹并保存爬取数据
- 📧 任务完成后自动发送邮件通知
- 🔄 失败自动重试机制
- 📊 详细的爬取统计信息
- 🌈 彩色控制台输出,美观易读
GoogleDomain.py 特色
- 🔗 多选择器适配不同页面结构
- 🔄 连续空白页检测,智能终止爬取
- 🔐 验证码自动检测与处理
- 🌐 自定义代理支持
- 📈 最多可爬取 99 页结果
FireFoxDomain.py 特色
- 🦊 基于 Firefox 浏览器的深度爬取
- 🔄 “更多结果” 按钮智能点击
- 📜 详细的爬取过程展示
- 🔍 多种链接选择器策略
- 🌐 灵活的代理配置
🛠️ 安装指南
前置要求
- Python 3.7 及以上版本
- Google Chrome 浏览器
- Mozilla Firefox 浏览器
- 对应版本的 ChromeDriver 和 GeckoDriver
安装步骤
- 克隆仓库
git clone https://github.com/Bifishone/GoogleFirefoxDomain.git
cd GoogleFirefoxDomain
- 安装依赖库
pip install selenium tldextract colorama
- 下载浏览器驱动
- ChromeDriver - 放置在系统 PATH 或脚本同级目录
- GeckoDriver - 放置在系统 PATH 或脚本同级目录
🚀 使用方法
GoogleDomain.py 使用
# 爬取单个域名
python GoogleDomain.py --domain example.com# 从文件爬取多个域名
python GoogleDomain.py -f domains.txt# 使用自定义代理
python GoogleDomain.py --domain example.com --proxy 127.0.0.1:1080
FireFoxDomain.py 使用
# 爬取单个域名
python FireFoxDomain.py --command "site:example.com"# 从文件爬取多个域名
python FireFoxDomain.py -f domains.txt# 使用自定义代理
python FireFoxDomain.py --command "site:example.com" --proxy 127.0.0.1:1080
📋 参数说明
GoogleDomain.py 参数
--domain:单个目标域名(如:example.com)-f, --file:包含多个域名的文件路径--proxy:代理服务器(格式:host:port,默认:127.0.0.1:7890)
FireFoxDomain.py 参数
--command:搜索命令(格式:site:example.com)-f:包含多个域名的文件路径--proxy:代理服务器(格式:host:port)
📊 结果展示
爬取结果将保存在results文件夹中,文件名为:
- Google 爬取结果:
Google_results_<domain>.txt - Firefox 爬取结果:
FireFox_results_<domain>.txt
同时,工具会在控制台显示爬取进度和结果统计,并在所有任务完成后发送邮件通知。
⚙️ 配置说明
可以通过修改脚本中的全局变量来调整工具行为:
# GoogleDomain.py 主要配置
MAX_PAGES = 99 # 最大爬取页数
MAX_RETRY = 20 # 域名最大重试次数
SCROLL_PAUSE = 1.0 # 页面滚动等待时间
DEFAULT_PROXY = "127.0.0.1:7890" # 默认代理地址# FireFoxDomain.py 主要配置
SCROLL_PAUSE = 1.5 # 滚动等待时间
CLICK_RETRY = 2 # 按钮点击重试次数
MAX_EMPTY_ATTEMPTS = 99 # 最大连续空结果轮次
📧 邮件通知配置
工具默认配置了邮件通知功能,完成爬取后会发送统计信息到指定邮箱。可以在脚本中修改以下参数:
# 发送方信息
sender_email = "your_email@qq.com"
sender_password = "your_smtp_password"# 接收方信息
receiver_email = "recipient@example.com"
工具下载
https://github.com/Bifishone/GoogleFirefoxDomain