关系型数据库——GaussDB的简单学习
摘要:GaussDB是一种基于PostgreSQL开发的关系型数据库管理系统,与PostgreSQL高度相似,都支持标准 SQL 查询语言,其语法格式同SQL十分相似,GaussDB扩展了一些新的东西,比如GaussDB是分布式架构,支持多节点扩展云原生部署,华为云提供,而PostgreSQL,Mysql都是单机或主从架构;GaussDB还增加了一些数据类型和一些函数操作。本片文章重点是学习GaussDB的一些SQL语言风格。
MySQL相信大家都非常熟悉了,在有MySQL的基础上学习GaussDB会简单得多,因为他们都是使用的SQL语言,只不过不同的数据库都有自己独特的SQL语言风格,其写法上会存在一些差异
GaussDB 兼容多种 SQL 语言风格,以适应不同背景的开发者和迁移需求,比如
- PostgreSQL 风格(原生支持)
- MySQL 风格
- Oracle 风格
- 标准 SQL风格
通过SET sql_compatibility = 'POSTGRESQL/MYSQL/ORACLE'来设置GaussDB的兼容模式
GaussDB 的兼容模式主要是为了:
- 默认行为调整:改变某些函数、数据类型的默认行为
- 语法兼容性:优先支持特定数据库的语法
- 函数映射:提供别名函数以兼容不同数据库
参考文档
PostgreSQL学习文档:
PostgreSQL UPDATE 语句 | 菜鸟教程PostgreSQL UPDATE 语句 如果我们要更新在 PostgreSQL 数据库中的数据,我们可以用 UPDATE 来操作。 语法 以下是 UPDATE 语句修改数据的通用 SQL 语法: UPDATE table_name SET column1 = value1, column2 = value2...., columnN = valueN WHERE [condition]; 我们可以同时更新一个或者多个字段。 我们可以..![]() https://www.runoob.com/postgresql/postgresql-update.htmlGaussDB官方中文文档:https://doc.hcs.huawei.com/db/zh-cn/gaussdb/25.1.30/productdesc/gaussdb_01_003.html
https://www.runoob.com/postgresql/postgresql-update.htmlGaussDB官方中文文档:https://doc.hcs.huawei.com/db/zh-cn/gaussdb/25.1.30/productdesc/gaussdb_01_003.html![]() https://doc.hcs.huawei.com/db/zh-cn/gaussdb/25.1.30/productdesc/gaussdb_01_003.html
https://doc.hcs.huawei.com/db/zh-cn/gaussdb/25.1.30/productdesc/gaussdb_01_003.html
什么是GaussDB?
GaussDB是华为公司推出的一款分布式数据库,专为企业级应用设计,旨在提供高效、安全、可靠的数据存储与管理解决方案。GaussDB支持多种数据模型,包括关系型、文档型和图形型,能够满足不同场景下的需求,为用户提供更加灵活的数据处理能力。GaussDB的核心优势在于其高可用性和扩展性。通过分布式架构,GaussDB能够支持大量并发访问,适用于大规模数据处理场景。此外,系统还具备自动故障恢复能力,当出现节点故障时,可以迅速切换到备份节点,确保服务持续可用,最大限度地降低业务中断的风险.
GaussDB是一种基于PostgreSQL开发的关系型数据库管理系统,它支持SQL语言和ACID事务
基本语法

常用的数据类型
1. 时间日期类型
- date:没有时区的年月日(yyyy-mm-dd)
- time without time zone: 没有时区的时分秒(时间 00:00:00)
- time with time zone :有时区信息的时分秒(时间 00:00:00)
- timestamp without time zone: 没有时区的年月日时分秒(yyyy-mm-dd 00:00:00)
- timestamp with time zone: 有时区的年月日时分秒(yyyy-mm-dd 00:00:00)
- smalldatetime: 会将秒数四舍五入的时间(大于等于30秒时,分钟+1秒数清零;小于等于29秒时,秒数清零)
- interval day to second(4) :时间间隔,second后面是秒数的精度,范围是0~6,据说这个类型是为了适配oracle数据库,但是并没有实现什么具体的功能
- reltime: 相对时间间隔,以30天为单位划分一个月来输出时间,例如如果输入'60',则会显示 2 mons;输入 '-100',则会显示 -3 mons -10 days
2. 字符串类型
- varchar: 不定长字符串,最大长度10485760
- char: 定长字符串,最大长度10485760
- text :不定长字符串,最大长度1073733621
3. 数字类型
- tinyint: 微整数,0~255
- smallint :小整数,-32768~32767
- int: 整数类型,-2147483648~2147483647(常用类型)
- bigint: 大整数,-9223372036854775808~9223372036854775807
- float: 浮点型小数类型,有小数时整数和小数一共可以保存15位长度,超过15位时小数不显示,截取的部分进行数字的四舍五入;
- decimal和number :两个类型是一样的没有区别,都是自定义数字类型,整数部分的范围是1~1000,小数精度的范围是0~1000,未指定精度的情况下,小数点前最大131072位,小数点后最大16383位;
4. 货币类型
money :货币金额类型,在显示的时候前面会有货币符号展示出来。money类型的数据范围是:-92233720368547758.08~92233720368547758.07(注意:money类型的数字只能转换成decimal和number,转换其它类型会报错。)
money类型的值可以转换为numeric类型而不丢失精度。转换为其他类型可能丢失精度

5. 二进制数据类型
- blob: 二进制大对象(列存不支持)
- raw: 变长的十六进制数据(列存不支持)
- bytea: 变长的二进制字符串
三种类型的存储空间都是最大支持1G~8203字节
注意的就是blob这种二进制大对象的数据添加方式:
1. 要先用 empty_blob() 往blob字段中插入空值
2. 然后使用for update对这一行数据进行上锁
3. 根据id列等,对这个数据字段进行update更新,写入二进制的字符数据
6. 序列类型
- smallserial:二字节序列整型,1~32767
- serial: 四字节序列整型,1~2147483647
- bigserial: 八字节序列整型,1~9223372036854775807
注意官方给出说明:

7. 布尔类型
BOOLEAN:t-真,f-假,null-未知(显示用字母t和f输出Boolean值)
- “真”值的有效文本值是:
TRUE、't'、'true'、'y'、'yes'、'1' 、'TRUE'、true、'on'、以及所有非0数值。
- “假”值的有效文本值是:
FALSE、'f'、'false'、'n'、'no'、'0'、0、'FALSE'、false、'off'。
8. 网络地址类型

9. 位串类型
位串就是一串1和0的字符串。它们可以用于存储位掩码。n最大取值为83886080
- bit(n):必须准确匹配长度n,如果存储的数据长度不匹配都会报错,没有长度的bit等效于bit(1)
- bit varying(n):最长为n的变长类型,长度超过n时会被拒绝,没有长度的bit varying表示没有长度限制。
10. 文本检索类型
- tsvector:是一种被全文检索优化后的文档数据类型,通过to_tsvector给文档进行分词规范化
- tsquery:表示文本查询类型,to_tsquery这个函数作用是用来把文本转化为可查询的语句
例如 SELECT to_tsvector('ngram', '华为深圳')

文本:华为深圳会被分词器ngram分词成多个词组
to_tsvector和to_tsquery配合实现全文检索,关键字搜索
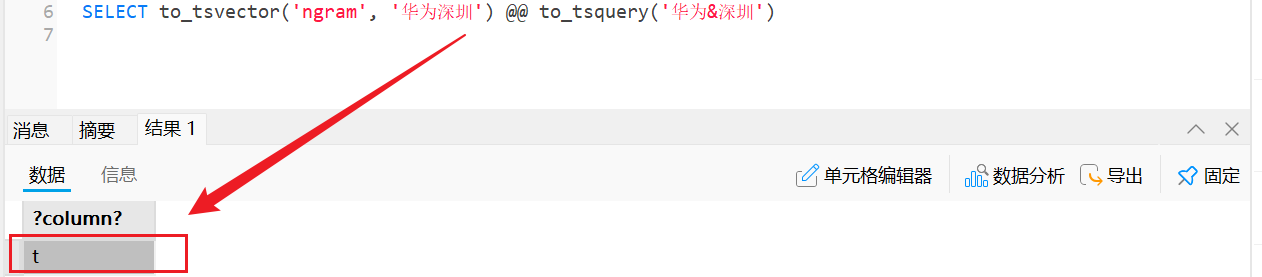
解释:“华为深圳”被分词成{'为深':2 '华为':1 '深圳':3},to_tsquery('华为&深圳')表示‘华为’和‘深圳’两个词组,也就是被分词后的{'为深':2 '华为':1 '深圳':3}是否同时包含华为’和‘深圳’两个词组
11. UUID类型
UUID是一个小写十六进制数字的序列,由连字符分成几组,一组8位数字+三组4位数字+一组12位数字,总共32个数字代表128位,对分布式系统而言,这种标识符比序列能更好的保证唯一性,因为序列只能在单一数据库中保证是唯一。
12. JSON/JSONB类型
JSON(JavaScript Object Notation)数据,可以是单独的一个标量,也可以是一个数组,也可以是一个键值对象,其中数组和对象可以统称容器(container):
- 标量(scalar):单一的数字、bool、string和null都可以称作标量。
- 数组(array):[]结构,里面存放的元素可以是任意类型的JSON,并且不要求数组内所有元素都是同一类型。
- 对象(object):{}结构,存储key:value的键值对,其键只能是用""包裹起来的字符串,值可以是任意类型的JSON,对于重复的键,按最后一个键值为准。
13. HLL数据类型
用于存储 HLL 结构(HyperLogLog),大小为固定的1280 bytes,可直接计算得到distinct值,数据计算的误差率最大在2.3%左右。HyperLogLog是一个具有固定大小,类似于集合结构,用于可调精度的不同值计数。
它的作用是统计一个集合中不重复的元素的个数。
14. 数组数据类型
数组数据类型一般通过在数组元素的数据类型名称后面加方括号[]进行命名。
CREATE TABLE sal_emp (name text,pay_by_quarter integer[],phone_numbers varchar(11)[]
);15. 向量数据类型
- floatvector数据类型:是指多维数据中含有的数据为float类型,例如[1.0,3.0,11.0,110.0,62.0,22.0,4.0]。

- boolvector数据类型:是指多维数据中含有的数据为bool类型,例如[0,0,0,0,0,1,0,0,1,0,0,0]。

细节注意
注意1:GaussDB 遵循 PostgreSQL 的严格类型系统,对类型转换有更严格的限制。即使表为空,它也会检查类型之间的可转换性,类型是否兼容的问题。
如果是MySQL,允许数据表为空时将任何字段的类型修改为其他任何类型,数据表不为空时会检查转换的类型是否兼容可转。
但是GaussDB 遵循 PostgreSQL 的严格类型系统,即使数据为空,也会检查转换的类型是否兼容。比如一开始字段是date类型,你想修改为time类型,因为date只有日期没有时间,所以date无法转换成time类型,反过来也是如此。
注意2:GaussDB 在不同兼容模式下数据类型存在一些差异,主要体现在默认行为、类型推导和兼容性处理方面
数据库常量
- CURRENT_CATALOG:当前数据库
- CURRENT_ROLE:当前用户
- CURRENT_SCHEMA:当前数据库模式
- CURRENT_USER:当前用户
- LOCALTIMESTAMP:当前会话时间(无时区)
- NULL:空值
- SESSION_USER:当前系统用户
- SYSDATE:当前系统日期
- USER:当前用户,此用户为CURRENT_USER的别名
特殊语法操作
GaussDB 继承了 PostgreSQL 的丰富语法特性,包含许多特殊的操作符和语法结构。以下是一些常见的特殊语法:
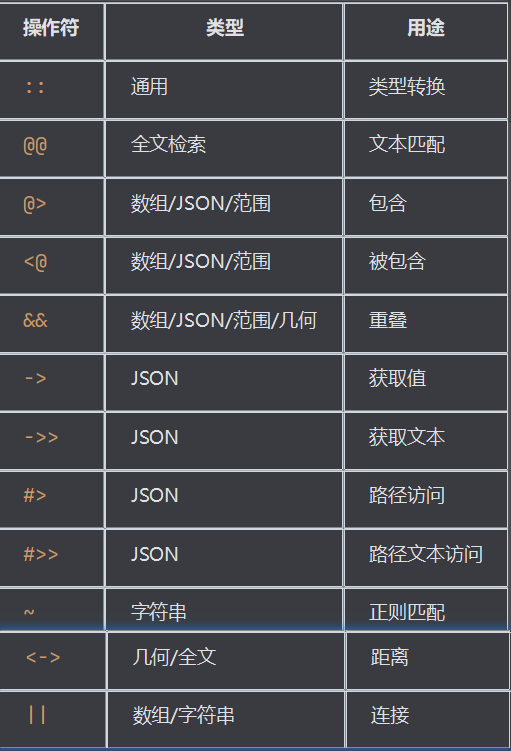
类型转换操作符
':: '表示类型转换操作符
-- 基本类型转换
SELECT '123'::INTEGER; -- 字符串转整数
SELECT 123::TEXT; -- 整数转字符串
SELECT '2023-01-01'::DATE; -- 字符串转日期
SELECT now()::TIMESTAMP; -- 时间转时间戳-- 数组类型转换
SELECT '{1,2,3}'::INTEGER[]; -- 字符串数组转整数数组-- JSON 转换
SELECT '{"name": "张三"}'::JSONB;
全文检索操作符
'@@'表示匹配操作符,用于全文检索的匹配操作
SELECT * FROM articles
WHERE search_vector @@ to_tsquery('GaussDB & 性能');‘<->’表示邻近操作符
SELECT '数据库 技术'::tsvector @@ '数据库 <-> 技术'::tsquery; -- 紧邻匹配‘<@’表示跟随操作符
SELECT '数据库 技术 创新'::tsvector @@ '数据库 <@ 技术'::tsquery; -- 数据库在技术之前‘@>’表示包含操作符
SELECT '数据库 技术 创新'::tsvector @@ '数据库 @> 创新'::tsquery; -- 包含关系数组操作符
'@>'表示包含操作符
SELECT ARRAY[1,2,3] @> ARRAY[1,2]; -- true'<@'表示被包含操作符
SELECT ARRAY[1,2] <@ ARRAY[1,2,3]; -- true'&&'表示重叠操作符,共同的元素
SELECT ARRAY[1,2,3] && ARRAY[3,4,5]; -- true (有共同元素)'(数组)[n]'表示访问数组元素,数组的第n个元素是
SELECT (ARRAY[1,2,3])[1]; -- 返回 1 (第一个元素)'(数组)[start:end]'表示数组切片,数组第start到end元素列表,包括边界
SELECT (ARRAY[1,2,3,4,5])[2:4]; -- 返回 {2,3,4}JSON/JSONB操作符
‘->’或者‘->>’表示访问JSON/JSONB的属性值
-- -> 返回 JSON 对象
SELECT '{"name": "张三", "age": 25}'::JSONB -> 'name'; -- "张三"‘数组->n’JSON/JSONB数组的第n个元素
-- 数组元素访问
SELECT '[1,2,3]'::JSONB -> 1; -- 2‘#>’或者‘#>>’表示路径访问
-- 路径访问
SELECT '{"user": {"name": "张三"}}'::JSONB #> '{user,name}'; -- "张三"
SELECT '{"user": {"name": "张三"}}'::JSONB #>> '{user,name}'; -- 张三‘@>’表示包含操作符,JSON对象是否包含某个JSON对象里面的所有键值对
-- 包含操作符 @>
SELECT '{"name": "张三", "age": 25}'::JSONB @> '{"name": "张三"}'::JSONB; -- true‘?’表示存在键操作符,JSON对象是否存在某个属性名
-- 存在键操作符 ?
SELECT '{"name": "张三", "age": 25}'::JSONB ? 'name'; -- true‘-’表示删除键操作符,JSON对象删除某个属性
-- 删除键操作符 -
SELECT '{"name": "张三", "age": 25}'::JSONB - 'age'; -- {"name": "张三"}
模式匹配操作符
‘~’表示匹配操作符,正则表达式匹配
-- 匹配以 hello 开头的字符串
SELECT 'hello world' ~ '^hello'; -- true (^ 表示行首)-- 匹配包含 hello 的字符串
SELECT 'hello world' ~ 'hello'; -- true-- 匹配 hello 后跟任意字符
SELECT 'hello world' ~ 'hello.*'; -- true (. 表示任意字符,* 表示重复)-- 匹配以 hello 结尾的字符串
SELECT 'say hello' ~ 'hello$'; -- true ($ 表示行尾)
‘!~’表示不匹配操作符,正则表达式匹配
-- 不匹配操作符 !~
SELECT 'hello world' !~ 'goodbye'; -- true'~*' 表示大小写不敏感匹配,正则表达式匹配
-- 大小写不敏感匹配 ~*
SELECT 'Hello World' ~* 'hello'; -- truesimial to 操作符类似正则表达式匹配
SELECT 'abc' SIMILAR TO 'a.c'; -- true (类似正则)
SELECT 'abc' SIMILAR TO '(a|b)c'; -- false范围操作符
-- 包含操作符 @>
SELECT '[1,5]'::INT4RANGE @> 3; -- true-- 被包含操作符 <@
SELECT 3 <@ '[1,5]'::INT4RANGE; -- true-- 重叠操作符 &&
SELECT '[1,5]'::INT4RANGE && '[3,7]'::INT4RANGE; -- true-- 相邻操作符 -|-
SELECT '[1,3]'::INT4RANGE -|- '[4,6]'::INT4RANGE; -- true
其他
复合类型访问
-- 创建复合类型
CREATE TYPE person_type AS (name TEXT, age INTEGER);-- 访问复合类型字段
SELECT (person_column).name FROM people;
SELECT (person_column).age FROM people;
总结
函数操作
具体函数使用细节自行到官网里面了解:https://doc.hcs.huawei.com/db/zh-cn/gaussdb/25.1.30/devg-dist/gaussdb-12-0437.html
注意:GaussDB在不同兼容模式下,函数使用上也有一些差异,比如某些函数只有在MYSQL兼容模式下才生效
- 高级窗口分析函数:GaussDB支持更丰富的窗口函数,如 NTILE() 函数可以将结果集分成指定数量的桶,FIRST_VALUE() 和 LAST_VALUE() 获取分区中的第一个和最后一个值
- 数学计算扩展函数:GaussDB提供 FACTORIAL() 阶乘函数、GCD() 最大公约数函数、LCM() 最小公倍数函数等高级数学运算函数
- JSON处理增强函数:GaussDB拥有 JSON_ARRAY_LENGTH() 获取JSON数组长度、JSON_EACH() 展开JSON对象、JSON_STRIP_NULLS() 移除JSON中null值等高级JSON处理函数
- 字符串处理扩展:GaussDB支持 INITCAP() 首字母大写转换、TRANSLATE() 字符映射替换、SPLIT_PART() 按分隔符分割并提取指定部分等字符串函数
- 全文检索函数:GaussDB内置 to_tsvector() 文本向量化、to_tsquery() 查询向量化、ts_rank() 相关性评分等全文检索函数,而MySQL需要使用专门的全文索引功能且功能相对简单。
- 数组操作函数:GaussDB原生支持数组类型,并提供 ARRAY_APPEND() 数组追加元素、UNNEST() 展开数组、ARRAY_TO_STRING() 数组转字符串等数组处理函数
- XML处理函数:GaussDB提供 XMLPARSE() XML解析、XMLELEMENT() 创建XML元素、XMLAGG() 聚合XML等完整的XML处理函数
- 网络地址函数:GaussDB支持 HOST() 获取IP主机部分、MASKLEN() 获取子网掩码长度、NETWORK() 获取网络地址等网络地址处理函数
- 高级日期时间函数:GaussDB提供 AGE() 计算时间间隔、JUSTIFY_DAYS() 标准化时间间隔、时区转换等高级时间处理功能
- 自定义聚合函数:GaussDB支持创建自定义聚合函数和更复杂的用户定义函数,扩展性比MySQL更强,可以满足特定业务需求。
全文检索
GaussDB继承了postgresql强大的全文检索功能,相较于MySQL,GaussDB内置多种语言的分词器,支持中文分词(需要配置中文词典),可自定义词典和停用词,Mysql内置分词器比较基础不支持中文分词需要自行配置分词器。
GaussDB全文检索的使用:
-- 创建全文检索字段
CREATE TABLE documents (id SERIAL PRIMARY KEY,title TEXT,content TEXT,search_vector TSVECTOR
);-- 使用触发器自动更新向量
CREATE TRIGGER tsvectorupdate BEFORE INSERT OR UPDATE
ON documents FOR EACH ROW EXECUTE FUNCTION
tsvector_update_trigger('search_vector', 'pg_catalog.chinese_zh', 'title', 'content');-- 全文检索查询
SELECT * FROM documents
WHERE search_vector @@ to_tsquery('数据库 & GaussDB');
-- 基本匹配
SELECT * FROM documents WHERE search_vector @@ '数据库';-- 逻辑操作
SELECT * FROM documents WHERE search_vector @@ 'GaussDB & (性能 | 优化)';-- 权重匹配
SELECT * FROM documents WHERE search_vector @@ 'title:数据库';-- 距离查询(相邻词)
SELECT * FROM documents WHERE search_vector @@ '数据库 <-> 技术';数据库操作基本语法
表数据插入
--GaussDB数据插入语法格式
[ WITH [ RECURSIVE ] with_query [, ...] ]
INSERT [/*+ plan_hint */] [ IGNORE ] INTO table_name [ { [alias_name] [ ( column_name [, ...] ) ] } | { [partition_clause] [ AS alias ] [ ( column_name [, ...] ) ] } ] { DEFAULT VALUES| { VALUES | VALUE } {( { expression | DEFAULT } [, ...] ) }[, ...] | query }[ { ON DUPLICATE KEY UPDATE { NOTHING | { column_name = { expression | DEFAULT } } [, ...] [ WHERE condition ] } }| { [ ON CONFLICT [ conflict_target ] conflict_action ] } ][ RETURNING {* | {output_expression [ [ AS ] output_name ] }[, ...]} ];与咱们熟悉的Mysql数据插入区别不大,存在以下区别是,GaussDB支持
- 更强大的冲突处理:同时支持 MySQL 和 PostgreSQL 风格的冲突处理
- RETURNING 子句:可以直接返回插入的结果,无需额外查询
- WITH 子句支持:可以在插入前进行复杂的数据处理,MySql在8开始才支持
- 更丰富的分区支持:显式的分区子句
- 计划提示:支持查询优化器提示
- Oracle风格的INSERT ALL插入
示例:
-- GaussDB
INSERT INTO users (name, email) VALUES ('张三', 'zhang@example.com')
RETURNING id; --直接一条语句就可以执行插入并返回插入的行数据-- MySQL(需要额外查询)
INSERT INTO users (name, email) VALUES ('张三', 'zhang@example.com'); --先执行插入
SELECT id FROM users WHERE name='张三' AND 'emial'= 'zhang@example.com'; --再查询数据更新
--GaussDB更新语法格式
[ WITH [ RECURSIVE ] with_query [, ...] ]
UPDATE [/*+ plan_hint */] [ ONLY ] {table_name [ partition_clause ] | subquery | view_name} [ * ] [ [ AS ] alias ]
SET {column_name = { expression | DEFAULT } |( column_name [, ...] ) = {( { expression | DEFAULT } [, ...] ) |sub_query }}[, ...][ FROM from_list] [ WHERE condition | WHERE CURRENT OF cursor_name ][ ORDER BY {expression [ [ ASC | DESC | USING operator ]
[ LIMIT { count } ][ RETURNING {* | {output_expression [ [ AS ] output_name ]} [, ...] }];where sub_query can be:
SELECT [ ALL | DISTINCT [ ON ( expression [, ...] ) ] ]
{ * | {expression [ [ AS ] output_name ]} [, ...] }
[ FROM from_item [, ...] ]
[ WHERE condition ]
[ GROUP BY grouping_element [, ...] ]
[ HAVING condition [, ...] ]
[ ORDER BY {expression [ [ ASC | DESC | USING operator ] | nlssort_expression_clause ] [ NULLS { FIRST | LAST } ]} [, ...] ]
[ LIMIT { [offset,] count | ALL } ]GaussDB 的 UPDATE 语法相比 MySQL 更加丰富和灵活,主要体现在:
- 更强的关联更新能力:直接支持 FROM 子句
- RETURNING 子句:可以直接返回更新结果
- WITH 子句支持:支持复杂的公用表表达式
- 更丰富的更新语法:支持元组更新、游标更新等
- 计划提示:支持查询优化器提示
- 继承表控制:支持 ONLY 关键字
示例:
1.关联表更新差异:
-- GaussDB:直接支持 FROM 子句
UPDATE employees
SET salary = salary * 1.1
FROM departments
WHERE employees.dept_id = departments.id AND departments.name = 'Sales';-- MySQL:使用 JOIN 语法
UPDATE employees e
JOIN departments d ON e.dept_id = d.id
SET e.salary = e.salary * 1.1
WHERE d.name = 'Sales';
GaussDB兼容多种数据库Sql语言风格,MySQL可以的GaussDB基本都可以。
分布式事务
一、分布式事务实现机制
核心架构组件
- 全局事务管理器(GTM):生成全局唯一的事务ID(GTID)和逻辑时间戳(CSN),协调分布式事务的时序一致性,确保跨节点事务的全局快照同步。
- 协调节点(CN):接收SQL请求,拆分查询计划并路由到数据节点(DN),充当两阶段提交(2PC)的协调者。
- 数据节点(DN):存储分片数据,执行本地事务并反馈状态,作为2PC的参与者。
事务原子性保障:两阶段提交(2PC)优化
- 准备阶段
CN向所有DN发送PREPARE请求,DN执行事务但不提交,持久化日志后返回确认。 - 提交阶段
若所有DN确认成功,CN通知GTM分配CSN,并行发送COMMIT命令;否则触发全局回滚。 - 容错机制
- 参与者故障:自动重试(默认3次)或超时回滚(通过
global_transaction_timeout配置)。 - 协调者故障:GTM通过日志恢复事务状态,确保最终一致性。
隔离性与一致性实现
- 多版本并发控制(MVCC):每个事务启动时获取CSN快照,读操作访问快照版本,写操作生成新版本,避免读写阻塞。
- 全局快照同步:GTM分发的CSN保证所有节点基于同一时间点判断数据可见性,解决分布式幻读问题。
- 锁机制优化
- 行级锁(默认):减少OLTP场景锁冲突。
- 表级锁分段(Segment Locking):针对热点数据(如库存)自动升级锁粒度,提升并发效率。
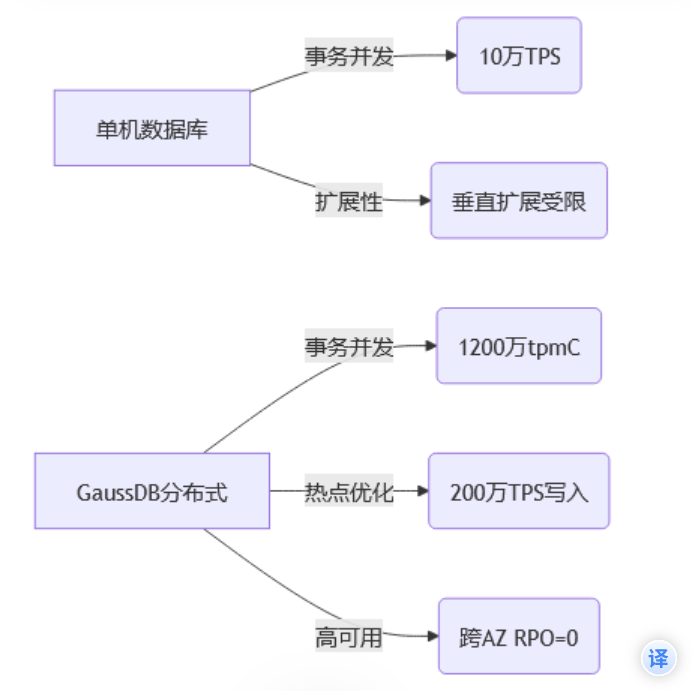
与传统单机数据库对比
分布式事务管理方面
- 传统单机数据库:传统单机数据库比如MySQl本身无法实现分布式事务,需要额外借助seata来帮助我们管理协调分布式事务来保证分布式场景下的数据一致性。
- GaussDB:GaussDB 作为分布式数据库,原生支持分布式事务,无需额外的组件,系统自动管理跨节点事务,对应用层透明。也就是说在微服务架构下,操作同一个数据库实例时只需要使用@Transactional标准 Spring 事务注解即可实现分布式事务管理
性能方面