基于多种分词算法的词频统计的中文分词系统的设计与实现
文章目录
- ==有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主==
- 项目介绍
- 每文一语
有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主
项目介绍
本项目面向中文文本处理的基础环节——分词与词频统计,围绕“可复用、可扩展、可解释”的目标,设计并实现了一套基于Flask的中文分词与词频可视化系统。系统集成了三种主流分词引擎(jieba、pkuseg、THULAC),并在此基础上提供用户自定义词典、停用词管理与多词组分词模式,结合数据库管理与前端可视化展示,实现从数据采集、清洗预处理、分词统计到结果展示与导出的端到端流程。项目既可用于科研与教学,也可服务于舆情监测、产品评价分析与专业文献挖掘等应用场景。
在总体架构方面,系统采用“数据层—服务层—应用层”三层设计。数据层以关系型数据库为核心,存放原始文本、清洗后文本、分词结果、词频表与可视化配置;服务层由Flask提供REST风格接口,负责任务调度、词典/停用词注入、分词引擎选择与词频统计;应用层面向终端用户提供上传文本、参数配置、分词执行、结果对比、图表渲染与导出等交互能力。该设计兼顾轻量与扩展:后端模块化、前后端解耦、数据库结构规范,为后续增加实体识别、关键词抽取或主题模型留出接口。
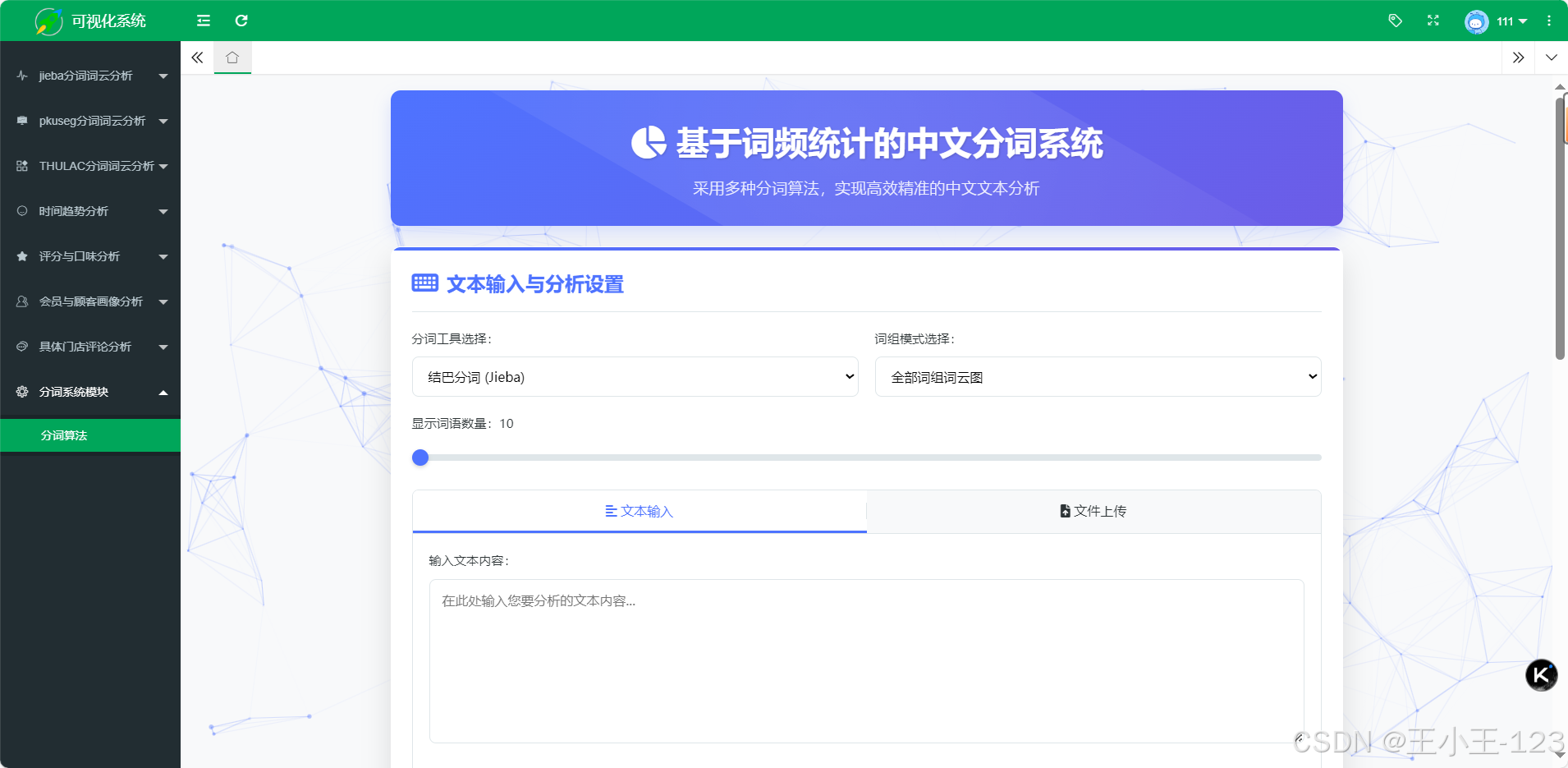
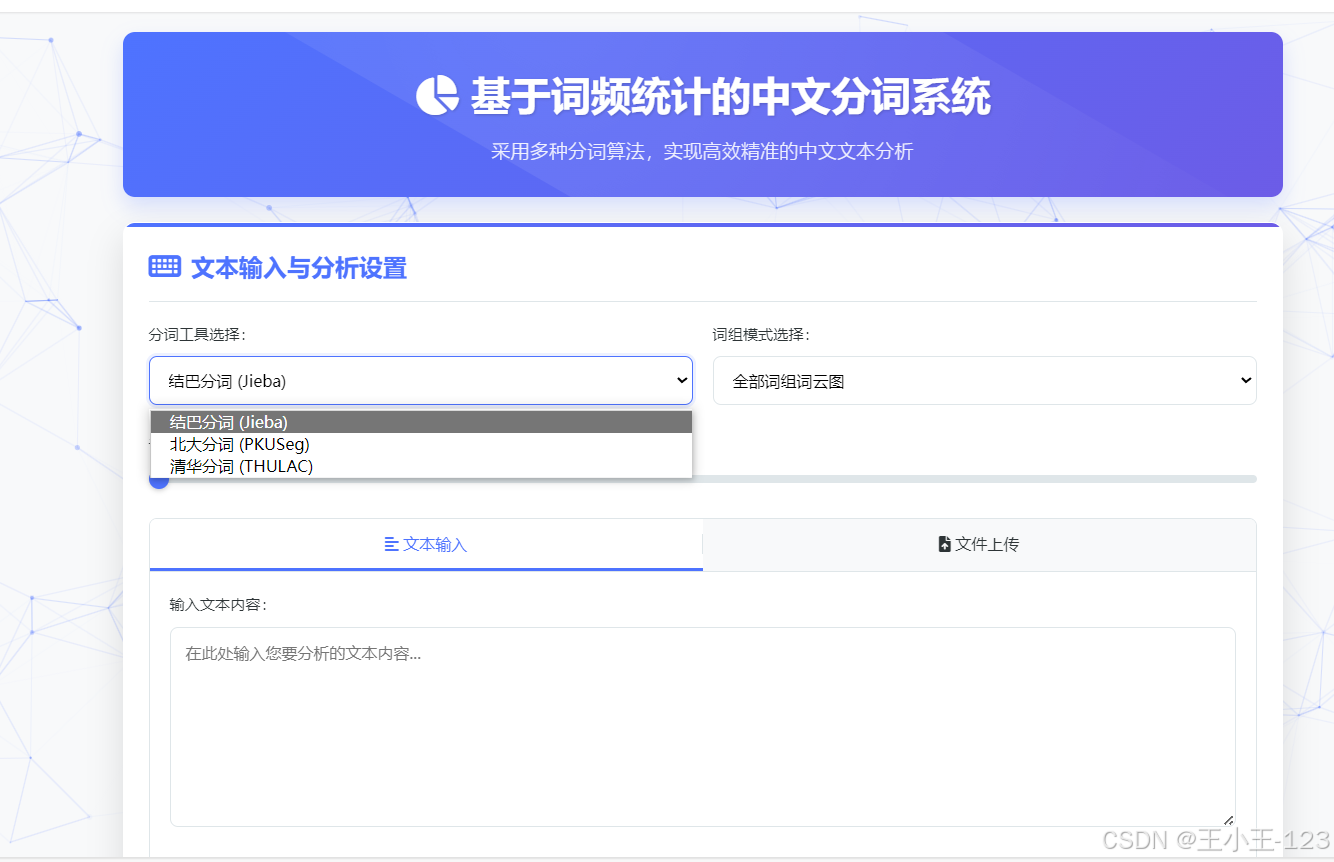
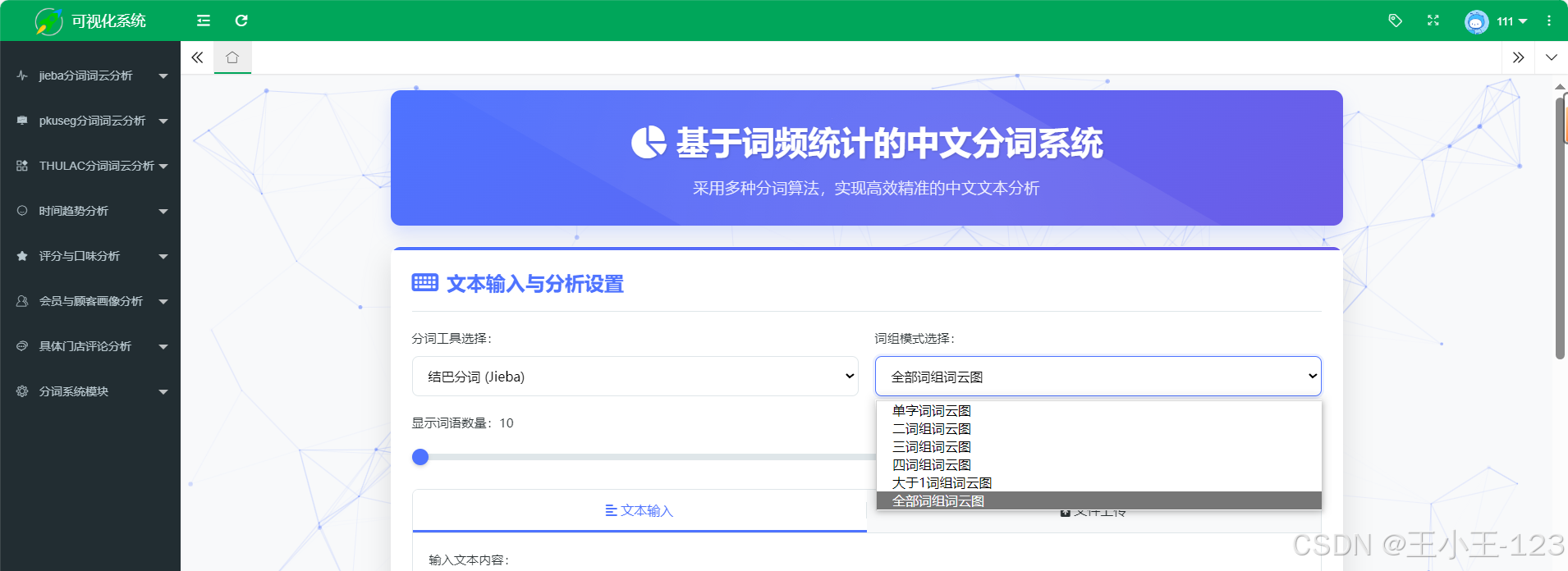
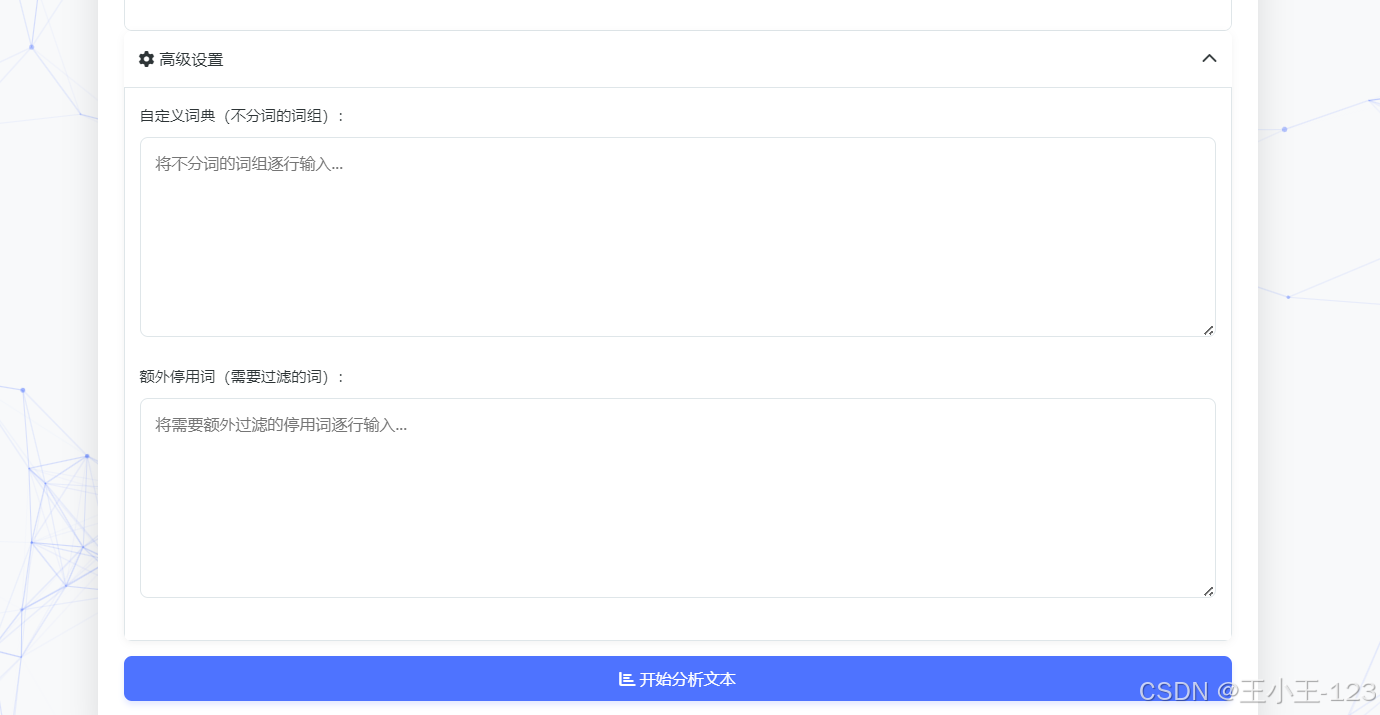
在关键功能上,系统围绕“可控的分词质量与直观的结果解释”展开。首先,用户可上传txt文本或通过表单粘贴文本,系统自动完成编码校验、时间与表情符清洗等预处理;其次,三类分词引擎可按需切换或并行运行:jieba侧重通用场景与速度,pkuseg擅长领域文本(如医疗、法律),THULAC在分词与词性标注一体化方面具备优势。第三,系统提供自定义词典与停用词管理,支持临时词典注入与运行时增删,保证专业术语的召回与噪声词的过滤。第四,创新的多词组分词模式允许将“人工智能”“不可抗力条款”等复合短语作为整体保留,解决复合名词被过度切分导致语义破碎的问题。上述设置均以参数化方式暴露,用户可根据文本属性与任务目标灵活组合策略。
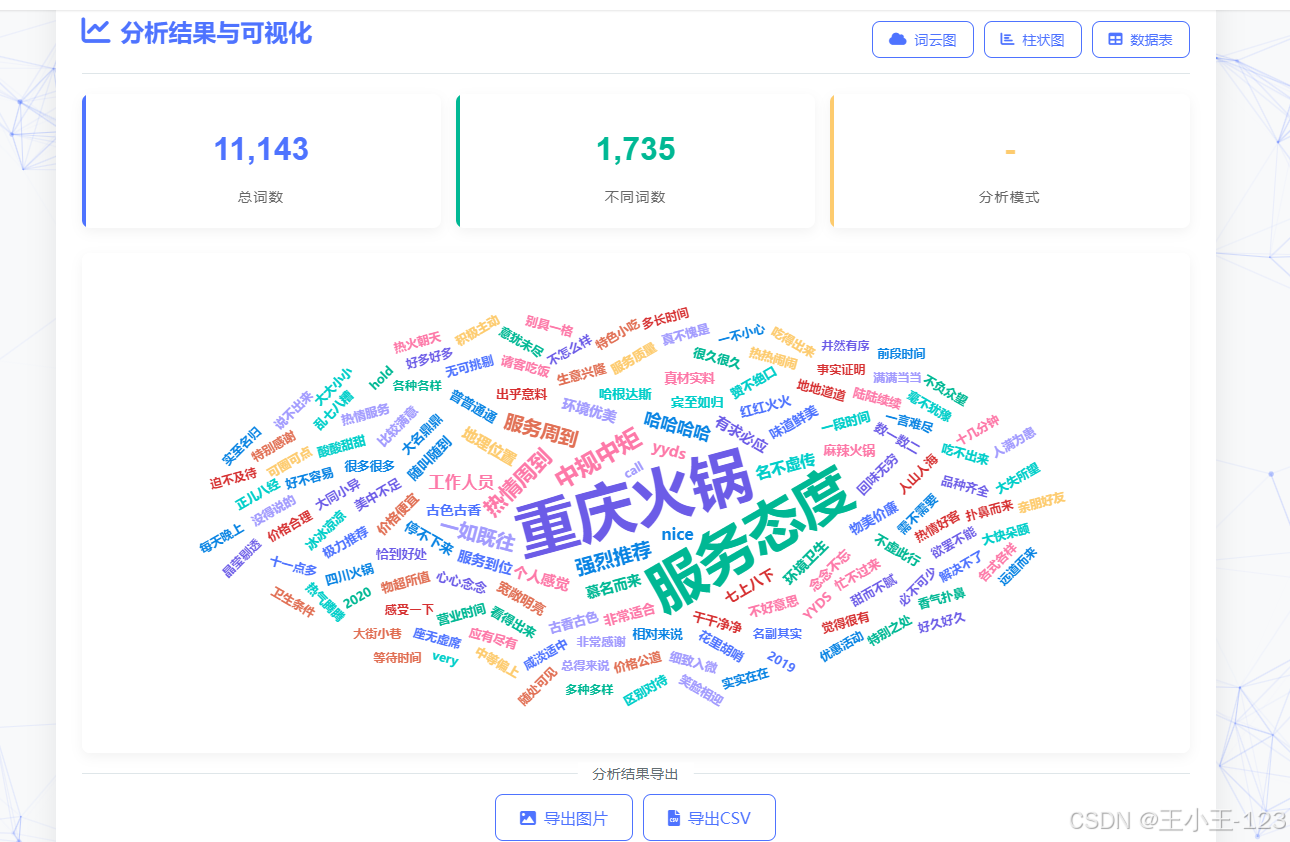
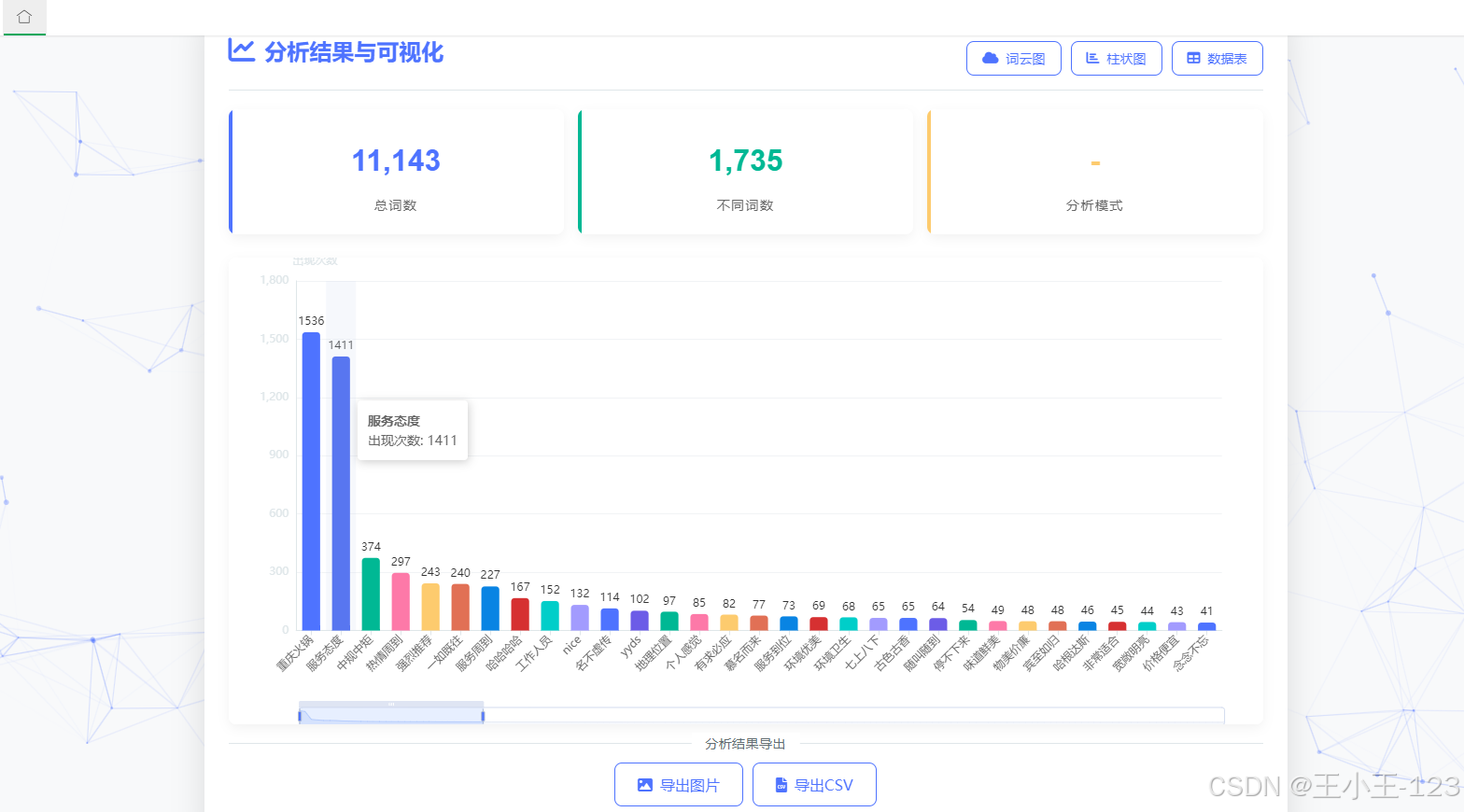
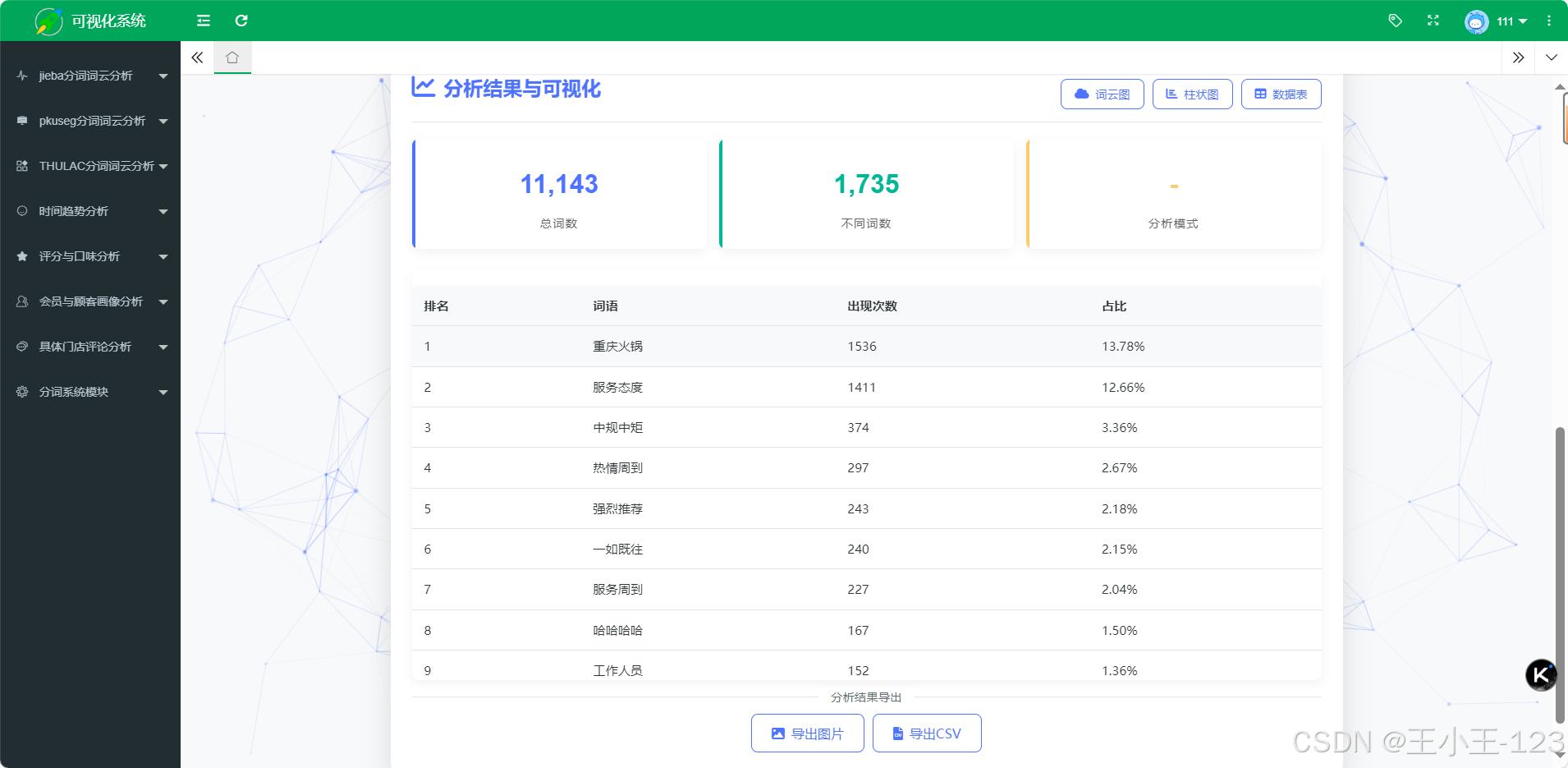
在可视化表达上,系统强调“看得见的差异”。一方面,提供词云与柱状图两类主视图:词云用于直观呈现高频词分布与相对权重,柱状图用于比较若干高频词的精确频次;另一方面,支持分长度(1–4字)与“全部合并”两种统计口径,辅以交互式筛选与排序,帮助用户从细粒度(如单字情感词)到短语层面(如二/三字术语)逐级洞察。此外,系统保留分词结果与词频表的明细数据,支持导出CSV与图像文件,以便在论文写作或业务报告中复用。
数据采集与治理方面,项目实现了面向网页评论文本的采集流程,包含请求伪装、Cookie轮换与断点续跑机制;在清洗阶段,系统统一编码、剔除表情与异常符号,处理多种时间格式并完成去重。通过这一套规整流程,输入端数据质量可控,为后续分词与统计提供可靠基础。
在性能与安全方面,系统通过任务异步化与批量处理提升吞吐:对长文本或大批量文档采用分片分句处理并聚合统计;数据库层面建立文本ID与任务ID的联合索引,保证查询与比对的效率。安全性上,后端对上传文件做类型与大小校验,持久化前进行危险字符过滤;日志仅记录必要元信息,敏感内容不落盘;同时提供基础的账号注册登录与权限校验,确保词典与停用词等个性化资产仅对所属用户可见。
在可扩展性与可维护性方面,系统以插件化方式对接分词引擎,新引擎接入仅需实现统一接口(分词、词性、置信度/状态码),即可纳入对比框架;停用词与自定义词典使用版本化配置,支持回滚与多方案切换;可视化层的图表配置抽象为JSON Schema,便于扩展更多图型(如时间序列热词演化、词共现网络)。部署上,开发环境内置调试服务器,生产环境建议以Gunicorn+Nginx承载,数据库采用主从或定期备份策略,保证高可用与数据安全。
从应用价值看,系统兼具通用性与专业性:在政务热点与民生舆情中,可快速提取高频诉求与痛点词;在产业竞争分析与产品口碑监测中,可对比不同品牌与时间段的关键词变化;在学术文本处理中,可用多词组模式保护术语完整性,并据此构建更稳健的词频特征。与纯算法论文相比,本项目突出“工程化落地”,将标准分词工具、词频统计与交互可视化整合为可直接使用的平台,降低技术门槛,提升分析效率,为后续的关键词抽取、主题建模、情感分析等任务奠定了数据与工程基础。
综上,本项目以Flask为底座、以数据库为中枢、以三大分词引擎为核心能力,通过可配置的词典与停用词机制、多词组模式与交互式可视化,实现了“可控分词—可信统计—可解释展示”的闭环方案。其设计思路清晰、实现路径完整、扩展接口明确,具有良好的教学示范与实际应用推广价值。

每文一语
每次的觉醒都是一次调整