国产化PDF处理控件Spire.PDF教程:在 Java 中将 PDF 转换为 CSV(轻松提取 PDF 表格)

在处理以 PDF 格式存储的报告、发票或数据集时,开发人员常常需要在电子表格、数据库或分析工具中复用其中的表格数据。一个常见的解决方案是 使用 Java 将 PDF 转换为 CSV,因为 CSV 文件轻量、结构化,并且几乎在所有平台上都兼容。与文本或图片导出不同,PDF 转 CSV 的核心是 从 PDF 中提取表格并保存为 CSV。
E-iceblue旗下Spire系列产品,是文档处理领域的佼佼者,支持国产化信创。借助 Spire.PDF for Java,可以检测 PDF 中的表格结构,并通过少量代码实现自动化导出。本文将逐步讲解如何借助Spire.PDF for Java 在 Java 中完成 PDF 到 CSV 的转换——从环境搭建,到表格提取,再到处理多页文档或单页多表等复杂情况。
Spire.PDF for Java免费试用下载
Java PDF 转 CSV 的环境搭建
在使用 Java 提取表格并转换为 CSV 之前,需要先搭建开发环境。这包括选择合适的库并将其添加到项目中。
为什么选择 Spire.PDF for Java
由于 PDF 文件本身不支持直接导出为 CSV,因此通过代码提取表格是更现实的做法。Spire.PDF for Java 提供了检测 PDF 文档中表格结构并直接保存为 CSV 的 API,使转换过程更简单高效。
安装 Spire.PDF for Java
如果使用 Maven,可以添加以下配置:
<repositories><repository><id>com.e-iceblue</id><name>e-iceblue</name><url>https://repo.e-iceblue.cn/repository/maven-public/</url></repository> </repositories> <dependencies><dependency><groupId>e-iceblue</groupId><artifactId>spire.pdf</artifactId><version>11.8.3</version></dependency> </dependencies>
如果没有使用 Maven,可以直接 下载 Spire.PDF for Java 安装包,并将 JAR 文件添加到项目的 classpath 中。
从 PDF 提取表格并保存为 CSV
将 PDF 转换为 CSV 最实用的方法就是表格提取。使用 Spire.PDF for Java,可以通过以下步骤完成:
- 加载 PDF 文档
- 使用 PdfTableExtractor 检测页面中的表格
- 按行收集单元格内容
- 将结果写入 CSV 文件
下面的 Java 示例展示了完整的转换流程:
Java 示例代码:PDF 转换为 CSV
import com.spire.pdf.*;
import com.spire.pdf.utilities.*;import java.io.*;public class PdfToCsvExample {public static void main(String[] args) throws Exception {// 加载 PDF 文档PdfDocument pdf = new PdfDocument();pdf.loadFromFile("Sample.pdf");// 用于存储提取文本的 StringBuilderStringBuilder sb = new StringBuilder();// 遍历每一页for (int i = 0; i < pdf.getPages().getCount(); i++) {PdfTableExtractor extractor = new PdfTableExtractor(pdf);PdfTable[] tableLists = extractor.extractTable(i);if (tableLists != null) {for (PdfTable table : tableLists) {for (int row = 0; row < table.getRowCount(); row++) {for (int col = 0; col < table.getColumnCount(); col++) {// 安全处理 CSV 字段String cellText = escapeCsvField(table.getText(row, col));sb.append(cellText);if (col < table.getColumnCount() - 1) {sb.append(",");}}sb.append("\n");}}}}// 写入 CSV 文件try (Writer writer = new OutputStreamWriter(new FileOutputStream("output/PDFTable.csv"), "UTF-8")) {writer.write(sb.toString());}pdf.close();System.out.println("PDF 表格已成功导出为 CSV。");}// 处理 CSV 字段的工具方法private static String escapeCsvField(String text) {if (text == null) return "";// 去掉换行text = text.replaceAll("[\\n\\r]", "");// 特殊字符处理if (text.contains(",") || text.contains(";") || text.contains("\"") || text.contains("\n")) {text = text.replace("\"", "\"\""); // 转义双引号text = "\"" + text + "\""; // 添加引号}return text;}
}
代码讲解
- PdfDocument:将 PDF 文件加载到内存
- PdfTableExtractor:逐页检测表格
- PdfTable:提供对行和列的访问
- escapeCsvField():去掉换行并处理特殊字符
- StringBuilder:拼接单元格内容,使用逗号分隔
- 最终结果写入 Output.csv,可直接在 Excel 或任意编辑器中打开
运行代码后生成的 CSV 文件示例:
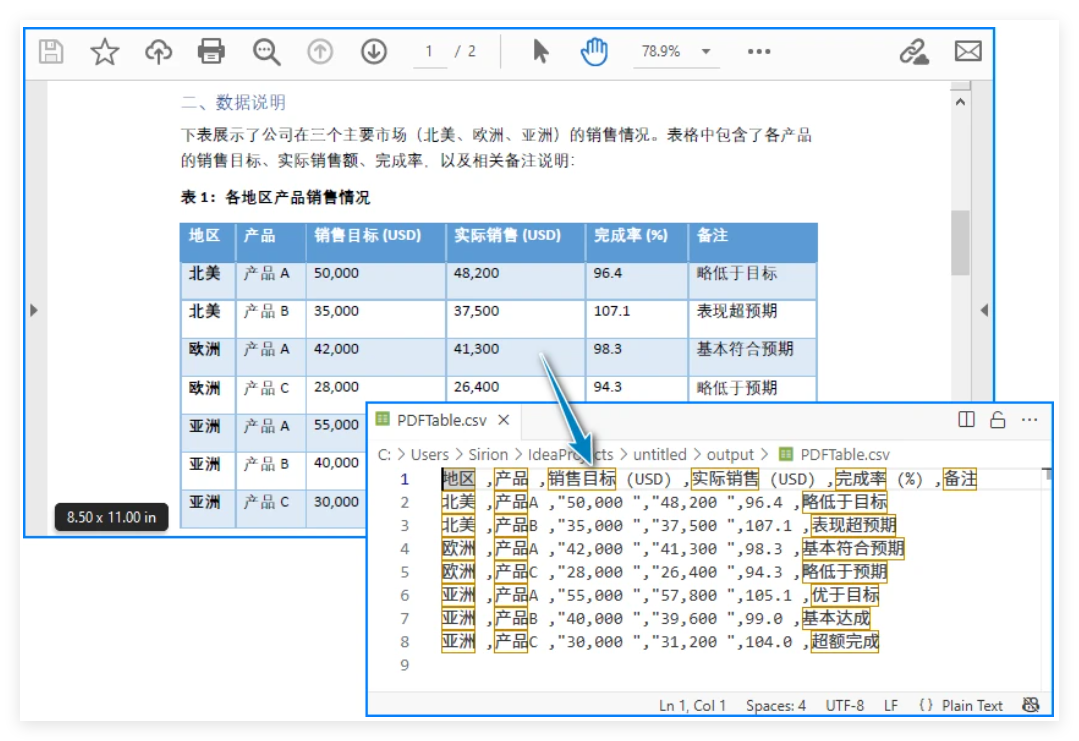
处理复杂的 PDF 转 CSV 场景
实际应用中,PDF 文件常常包含多个表格、跨多页,或表格结构不规则。下面介绍如何应对这些情况。
1. 单页包含多个表格
extractTable(i) 返回的 PdfTable[] 包含该页中检测到的所有表格,可以将每个表单独保存为不同的 CSV 文件:
for (int i = 0; i < pdf.getPages().getCount(); i++) {PdfTableExtractor extractor = new PdfTableExtractor(pdf);PdfTable[] tableLists = extractor.extractTable(i);if (tableLists != null) {for (int t = 0; t < tableLists.length; t++) {PdfTable table = tableLists[t];StringBuilder tableContent = new StringBuilder();for (int row = 0; row < table.getRowCount(); row++) {for (int col = 0; col < table.getColumnCount(); col++) {tableContent.append(escapeCsvField(table.getText(row, col)));if (col < table.getColumnCount() - 1) {tableContent.append(",");}}tableContent.append("\n");}try (Writer writer = new OutputStreamWriter(new FileOutputStream("output/Tables/Table_Page" + i + "_Index" + t + ".csv"), "UTF-8")) {writer.write(sb.toString());}}}
}
示例:将单页的多个表格导出为独立 CSV 文件:
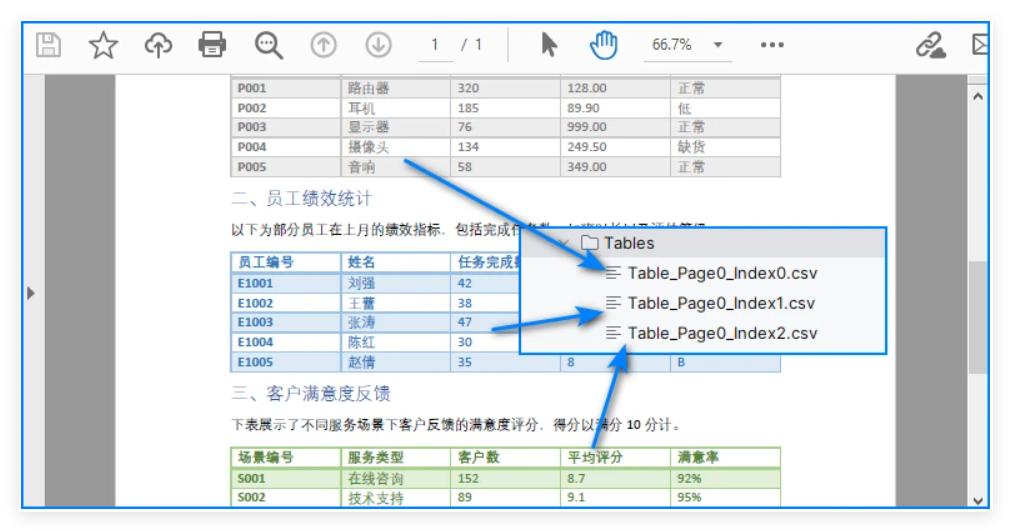
2. 跨页或大表格
如果表格跨越多页,可以逐页提取并 追加写入,以避免覆盖:
StringBuilder sb = new StringBuilder();for (int i = 0; i < pdf.getPages().getCount(); i++) {PdfTableExtractor extractor = new PdfTableExtractor(pdf);PdfTable[] tables = extractor.extractTable(i);if (tables != null) {for (PdfTable table : tables) {for (int row = 0; row < table.getRowCount(); row++) {for (int col = 0; col < table.getColumnCount(); col++) {sb.append(escapeCsvField(table.getText(row, col)));if (col < table.getColumnCount() - 1) sb.append(",");}sb.append("\n");}}}
}FileWriter writer = new FileWriter("MergedTables.csv");
writer.write(sb.toString());
writer.close();
示例:将跨多页的大表格合并为一个 CSV 文件:
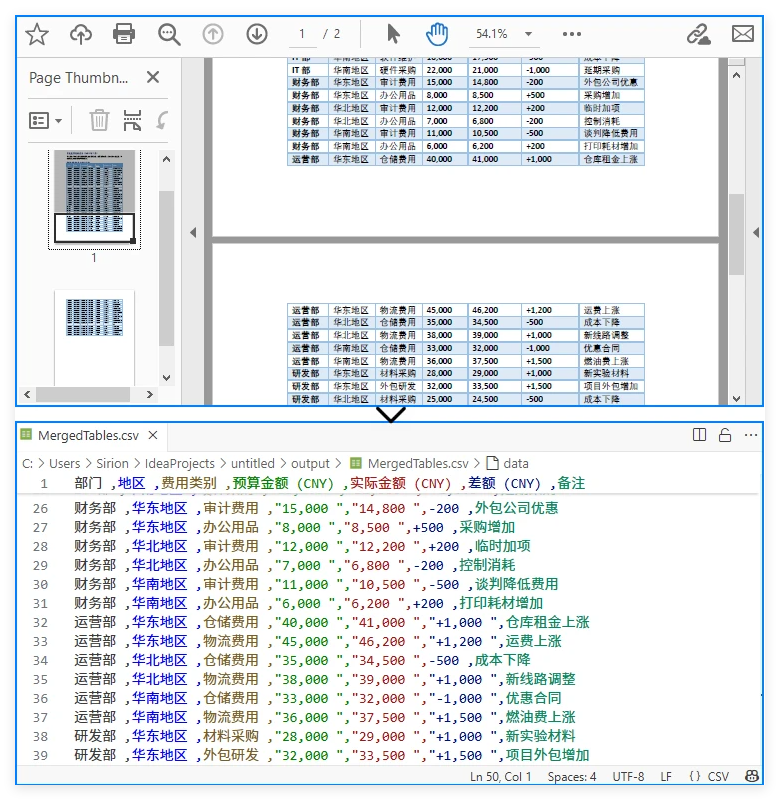
3. 格式限制
CSV 只能存储纯文本,像合并单元格、字体、图片等格式会丢失。如果需要保留样式,可以导出为 Excel(.xlsx)。
4. CSV 特殊字符处理
在写入 CSV 时,逗号、分号、双引号、换行等特殊字符可能会破坏文件结构。 上述 Java 示例中的 escapeCsvField 方法可以去除换行并安全转义。
更复杂的场景下,可以使用 Spire.XLS for Java,通过简单的 Java 代码将表格数据写入 Excel,再将 Excel 工作表保存为 CSV,无需手动处理特殊字符。
总结
在 Java 中将 PDF 转换为 CSV,本质上就是 提取表格并保存为结构化格式。CSV 文件轻量、通用,非常适合存储和分析表格数据。通过搭建 Spire.PDF for Java 环境并参考本文示例代码,即可实现自动化转换,减少手动操作并提高效率。
常见问题
Q: 可以把 PDF 转换为 CSV 吗?
A: 可以。虽然图片和带格式的文本无法导出,但表格数据可以提取并保存为 CSV。
Q: 如何在 Java 中从 PDF 提取数据
A: 使用 Spire.PDF for Java 等 PDF 库,可以解析文档、检测表格并导出为 CSV 或 Excel。
Q: 最好的 PDF 转 CSV 工具是什么?
A: 对于 Java 开发者来说,Spire.PDF for Java 等代码级解决方案比手动转换工具更灵活高效。
Q: 如何使用 Java 将 PDF 转换为 Excel?
A: 步骤与导出 CSV 类似,不同之处在于将数据保存为 Excel 格式,以便支持更多功能。