005 从会议全貌到模型本质:会议介绍与语言模型概述的深度融合


文章目录
- 5.1 ACL国际计算机语言协会
- 5.2 语言模型概述:什么是语言模型?
- 5.3 语言模型的计算方法
- 5.4 语言模型的核心用途
- 5.5 语言模型的日常应用案例
5.1 ACL国际计算机语言协会
首先,我们来介绍 ACL(国际计算机语言协会)。它是计算语言学与自然语言处理(NLP)领域内最顶尖的国际学术组织。不过,ACL 最初的名称并非如此,而是 “计算机翻译和计算机语言学会”,直到 1968 年才正式更名为 ACL。
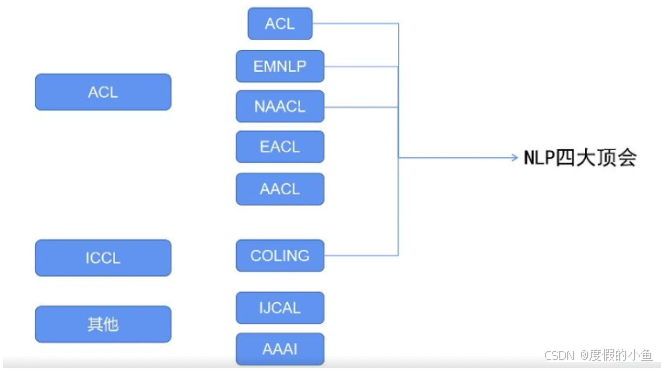
ACL 不仅见证了 NLP 发展的完整历程,还在多年间为 NLP 领域的发展提供了重要支撑。由 ACL 协会主导或支撑的会议数量众多,以下为大家列举部分核心会议:
ACL 主会议:作为 ACL 体系下的核心会议,在 NLP 领域具有极高的认可度。
EMNLP 会议:与 ACL 主会议并列的重要会议,聚焦 NLP 领域的前沿研究与应用。
NAACL 会议:全称为 “北美计算语言学协会会议”,是 ACL 在北美的分会会议,汇聚了北美地区 NLP 领域的优秀成果。
EACL 会议:即 “欧洲计算语言学协会会议”,是 ACL 在欧洲的重要分会会议,推动了欧洲 NLP 领域的学术交流与发展。
AACL 会议:也就是 “亚洲计算语言学协会会议”。该会议是近年来才新增的 ACL 分会会议,其设立的重要原因之一是华人学者在 NLP 领域的影响力不断提升 —— 在众多顶尖 NLP 会议中,华人学者的研究成果频繁涌现,贡献愈发突出。
COLING 会议:部分人可能会误称为 “CON line”,但根据其全称 “国际计算语言学会议”,规范名称应为 COLING 会议,它也是 NLP 领域的重要学术会议之一。
IJCNLP 会议与AAAI 会议:其中,AAAI 会议是人工智能领域的知名会议。早些年,从事 NLP 研究的学者常会向这两个会议投稿,但如今,随着 NLP 领域的专业化发展,学者们更倾向于将论文投递到 NLP 专业领域的会议,这两个会议已不再是 NLP 论文的主流投稿选择。
在 NLP 领域,我们通常将四大顶会视为核心学术标杆,它们分别是 ACL 主会议、EMNLP 会议、NAACL 会议和 COLING 会议。这四大会议的举办时间各不相同,因此在投稿时,一般会选择距离论文完成时间最近的会议进行投递。
若要对这四大会议的档次进行区分,ACL 主会议的整体影响力通常被认为是最强的;对于其余三个会议,不同人可能有不同看法,有人认为它们之间不存在明显差距,也有观点认为四大会议在整体水平上并无本质区别。不过,这四大会议的评审侧重点存在差异:部分会议更看重研究的 “创新点”,要求论文在理论或方法上有突破性贡献;而有些会议则更关注 “实验效果”,即论文在公开数据集上的性能表现(俗称 “图榜”)。
因此,若有论文投稿需求,建议大家针对目标会议的评审偏好做进一步深入了解。但总体而言,只要能在这四大会议中任意一个会议上成功投稿并被收录,就足以证明研究成果的高质量,这也是业内对这四大会议认可度的直接体现。
接下来我们将围绕 “语言模型” 展开讲解,内容主要分为以下三个部分:
- 介绍语言模型的基本概念(语言模型概述);
- 详细讲解传统的 N-gram 语言模型;
- 探讨深度学习框架下的现代语言模型。
5.2 语言模型概述:什么是语言模型?
标准定义
语言模型的核心任务,是计算一个语言序列(通常表示为w₁, w₂, …, wₙ,其中wᵢ代表序列中的第i个词)出现的联合概率。这一概率既包含了序列中每个词单独出现的概率,也涵盖了这些词按照当前顺序排列组合的概率。从机器学习的角度来看,语言模型本质上是对 “语句概率分布” 的建模过程 —— 即通过模型学习语言的内在规律,从而量化不同语句出现的可能性。
通俗理解
简单来说,语言模型的作用就是 “判断一个语言序列是否为正常语句”:如果某个序列是符合日常语言习惯的正常语句(例如 “我是中国人”),模型会为其赋予较高的概率;如果序列不符合语法或语义逻辑(例如 “中国是我人”),模型则会给出较低的概率。
5.3 语言模型的计算方法

要计算语言序列w₁, w₂, …, wₙ的联合概率,我们会借助链式法则对其进行分解,将复杂的联合概率转化为多个条件概率的乘积。具体公式如下:
P(w₁, w₂, ..., wₙ) = P(w₁) × P(w₂|w₁) × P(w₃|w₁, w₂) × ... × P(wₙ|w₁, w₂, ..., wₙ₋₁)
其中,P(w₁)表示第一个词w₁单独出现的概率;P(w₂|w₁)表示在w₁已经出现的前提下,w₂出现的条件概率;以此类推,P(wₙ|w₁, …, wₙ₋₁)表示在序列w₁到wₙ₋₁已出现的前提下,wₙ出现的条件概率。
我们以 “我是中国人” 这个序列为例,其联合概率的计算过程为:
P(我, 是, 中, 国, 人) = P(我) × P(是|我) × P(中|我, 是) × P(国|我, 是, 中) × P(人|我, 是, 中, 国)
然而,这种直接计算的方式存在明显缺陷:当语言序列较长时,每个条件概率(如P(wₙ|w₁, …, wₙ₋₁))所依赖的 “历史词数量” 会不断增加,导致计算复杂度急剧上升;同时,由于不同序列的 “历史词组合” 几乎不会重复,模型需要学习的参数数量也会变得异常庞大,最终使得联合概率的计算难以实现。
为解决这一问题,我们引入了马尔可夫假设(强假设):计算某个词wᵢ出现的概率时,仅依赖于其前面有限个(假设为k个)词,而无需考虑整个历史序列。基于这一假设,条件概率**P(wᵢ|w₁, ..., wᵢ₋₁)可简化为P(wᵢ|wᵢ₋ₖ, ..., wᵢ₋₁)。**
这一简化极大地降低了计算复杂度和参数数量,让语言模型的实际应用成为可能。
5.4 语言模型的核心用途
自然语言生成(NLG)
在语言模型的计算过程中,我们通过 “已知前文词序列,预测下一个词的概率” 来逐步构建完整语句。例如,当已知序列 “我是中” 时,模型会预测 “国” 出现的概率最高;当序列更新为 “我是中国” 时,模型会进一步预测 “人” 出现的概率较高。通过这种 “逐步预测” 的方式,语言模型能够生成符合语言习惯的正常语句,这正是自然语言生成的核心逻辑。
支撑 NLP 下游任务
语言模型是 NLP 领域的 “基础工具”,几乎所有 NLP 基础任务(如文本分类、情感分析、机器翻译等)都可以融入语言模型。它能够帮助模型更好地理解文本语义、筛选关键特征,从而显著提升下游任务的性能表现。
语音识别领域的关键环节
在语音识别流程中,设备采集到语音信号后,需要将其转化为文字序列。这一过程必须依赖语言模型 —— 通过语言模型对 “语音信号对应的候选文字序列” 进行概率评估,最终选择概率最高、最符合语言逻辑的序列作为识别结果,确保语音识别的准确性。
预训练模型的核心基础
现代 NLP 领域的预训练模型(如 BERT、GPT 等)本质上都是基于语言模型构建的。通过在大规模文本数据上预训练语言模型,使其学习通用的语言规律,再将预训练模型迁移到具体下游任务中进行微调,能够大幅降低任务训练难度、提升模型效果(这一部分我们将在后续课程中详细讲解)。
5.5 语言模型的日常应用案例
输入法联想功能:当我们在输入法中输入 “我是中” 时,输入法会自动联想出 “国”“华” 等候选词,这正是语言模型 “预测下一个词” 功能的直接应用。
搜索引擎补全功能:在搜索引擎中输入部分关键词(如 “人工智能发展趋势”)时,搜索引擎会自动补全完整查询语句(如 “人工智能发展趋势 2024”),背后同样依赖语言模型对 “用户可能的查询序列” 进行概率预测。
下一章节内容 N-gram语言模型了解