掌握正则表达式与文本处理:提升 Shell 编程效率的关键技巧
文章目录
- 前言
- 一、正则表达式概述
- 1.1 什么是正则表达式?
- 1.2 正则表达式的应用场景
- 1.3 Linux 中的正则表达式分类
- 二、正则表达式语法详解
- 2.1 普通字符与元字符
- 2.2 重复次数限定符
- 2.3 扩展正则表达式中的增强功能
- 三、常用文本处理工具:grep
- 示例用法:
- 四、基础正则 vs 扩展正则
- 4.1 BRE 常见元字符
- 4.1 ERE 新增功能
- 五、实战案例:正则表达式在文本处理中的应用
- 5.1 查找特定字符串
- 5.2 使用字符集与范围
- 5.3 定位符与边界匹配
- 5.4 使用重复与通配
- 总结
前言
在日常的 Linux 系统管理和自动化脚本编写中,文本处理是一项不可或缺的技能。无论是日志分析、配置文件解析,还是数据提取与过滤,正则表达式都扮演着至关重要的角色。本文将从正则表达式的基础概念入手,系统介绍其语法规则、分类及常用文本处理工具的使用方法,帮助读者掌握高效处理文本数据的核心技巧。
一、正则表达式概述
1.1 什么是正则表达式?
正则表达式(Regular Expression,简称 regex/regexp/RE)是一种用于描述字符串模式的规则。通过定义特定的语法结构,我们可以快速检索、替换或过滤符合特定规则的文本内容。
1.2 正则表达式的应用场景
- 系统日志分析(如筛选“登录失败”记录)
- 配置文件解析与提取
- 文本内容的查找与替换
- 脚本编程中的条件匹配与验证
1.3 Linux 中的正则表达式分类
Linux 中常用的正则表达式分为两类:
- 基础正则表达式(BRE):语法较为传统,功能有限,需对某些符号进行转义。
- 扩展正则表达式(ERE):功能更强大,语法更简洁,无需转义多数符号。
常用工具支持:
- BRE:
grep、sed - ERE:
egrep(或grep -E)、awk
二、正则表达式语法详解
2.1 普通字符与元字符
普通字符即字母、数字和标点符号等直接匹配的字符。而元字符则具有特殊含义,例如:
.:匹配任意单个字符(除换行符)[]:匹配字符集中的任意一个字符[^]:匹配不在字符集中的任意一个字符^和$:分别匹配行首和行尾\:转义字符,用于取消元字符的特殊含义
2.2 重复次数限定符
*:匹配前一个字符 0 次或多次\+:匹配前一个字符至少 1 次(BRE 中需转义)\{n\}:匹配恰好 n 次\{n,m\}:匹配 n 到 m 次\{n,\}:匹配至少 n 次
2.3 扩展正则表达式中的增强功能
+:匹配前一个字符至少 1 次(ERE 中无需转义)?:匹配前一个字符 0 或 1 次|:逻辑“或”,匹配多个模式之一():用于分组,可结合|使用()+:匹配重复的组
三、常用文本处理工具:grep
grep 是 Linux 中最常用的文本搜索工具,支持正则表达式匹配。以下是一些常用选项:
-E:启用扩展正则表达式-c:统计匹配行数-i:忽略大小写-o:仅输出匹配部分-v:反向匹配,输出不包含模式的行-n:显示匹配行的行号--color=auto:高亮显示匹配内容
示例用法:
grep -c "root" /etc/passwd # 统计包含 root 的行数
grep -i "the" demo # 忽略大小写查找 the
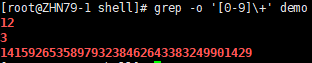
grep -o '[0-9]\+' demo # 提取所有数字
ifconfig | grep -o '[0-9]\+\.[0-9]\+\.[0-9]\+\.[0-9]\+'| head -1 # 提取 IP 地址



四、基础正则 vs 扩展正则
4.1 BRE 常见元字符
^行首$行尾.任意单字符[list]匹配字符集[^list]反向匹配*0 或多次\{n\}精确次数\{n,\}至少 n 次\{n,m\}n~m 次
4.1 ERE 新增功能
+一个或多个?0 或 1 次|或者(OR)()分组()+匹配重复的组
五、实战案例:正则表达式在文本处理中的应用
5.1 查找特定字符串
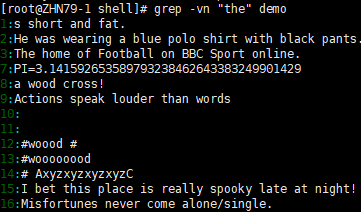
grep -n "the" demo # 查找包含 "the" 的行
grep -vn "the" demo # 查找不包含 "the" 的行

5.2 使用字符集与范围
grep -n "sh[io]rt" demo # 匹配 "shirt" 或 "short"
grep -n "[^a-z]oo" demo # 匹配前面不是小写字母的 "oo"


5.3 定位符与边界匹配
grep -n "^the" demo # 匹配以 "the" 开头的行
grep -n "\.$" demo # 匹配以句点结尾的行
grep -n "^$" demo # 匹配空行



5.4 使用重复与通配
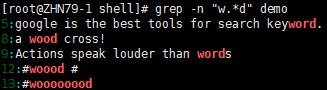
grep -n "w..d" demo # 匹配如 "wood", "weed" 等
grep -n "woo*d" demo # 匹配 "wd", "wood", "woood" 等
grep -n "w.*d" demo # 匹配从 w 到 d 的任意内容


总结
正则表达式是文本处理中极为强大的工具,掌握其基本语法和常用元字符,能够显著提升在 Linux 环境下的工作效率。无论是使用 grep 进行快速搜索,还是在 sed、awk 中进行复杂的文本变换,正则表达式都是不可或缺的基础技能。
通过本文的介绍,希望读者能够理解正则表达式的分类与语法,熟悉 grep 工具的常见用法,并能在实际工作中灵活运用正则表达式解决文本处理问题。正则表达式虽初学略显复杂,但一旦掌握,将成为你 Shell 编程和系统管理中的利器。