语义分析:从读懂到理解的深度跨越
引言:从“读懂”到“理解”——探索语义分析的深度
当计算机处理“苹果公司发布了新款手机”这句话时,它能轻易“读懂”其字面含义:一个名为“苹果公司”的实体,执行了“发布”动作,对象是“新款手机”。然而,人类的“理解”远不止于此。我们会联想到其对手机市场格局的冲击、潜在的技术革新、激烈的商业竞争,甚至是我们自己是否需要更换手机的决策。这种从“读懂”到“理解”的鸿沟,正是自然语言处理(NLP)领域中“浅层语义”与“深层语义”的核心差异所在。
本文的核心议题,便是系统性地剖析NLP中浅层与深层语义特征的区别与联系。我们将特别关注语义角色标注(Semantic Role Labeling, SRL)在这一体系中所扮演的关键桥梁作用。文章将遵循一条清晰的分析路径:首先,从理论框架上为两种语义层次进行界定;其次,对比分析提取它们的技术实现与应用场景的差异;最后,探讨它们如何通过预训练语言模型(PLMs)与知识图谱(Knowledge Graphs, KGs)等现代技术融会贯通,共同构建一个完整的语义理解层次。
本文旨在为NLP领域的初学者、研究者和从业人员提供一个清晰的理论与技术图谱,帮助其更深刻地把握不同层次语义分析技术的本质,从而在研究与实践中做出更精准的选择与应用。
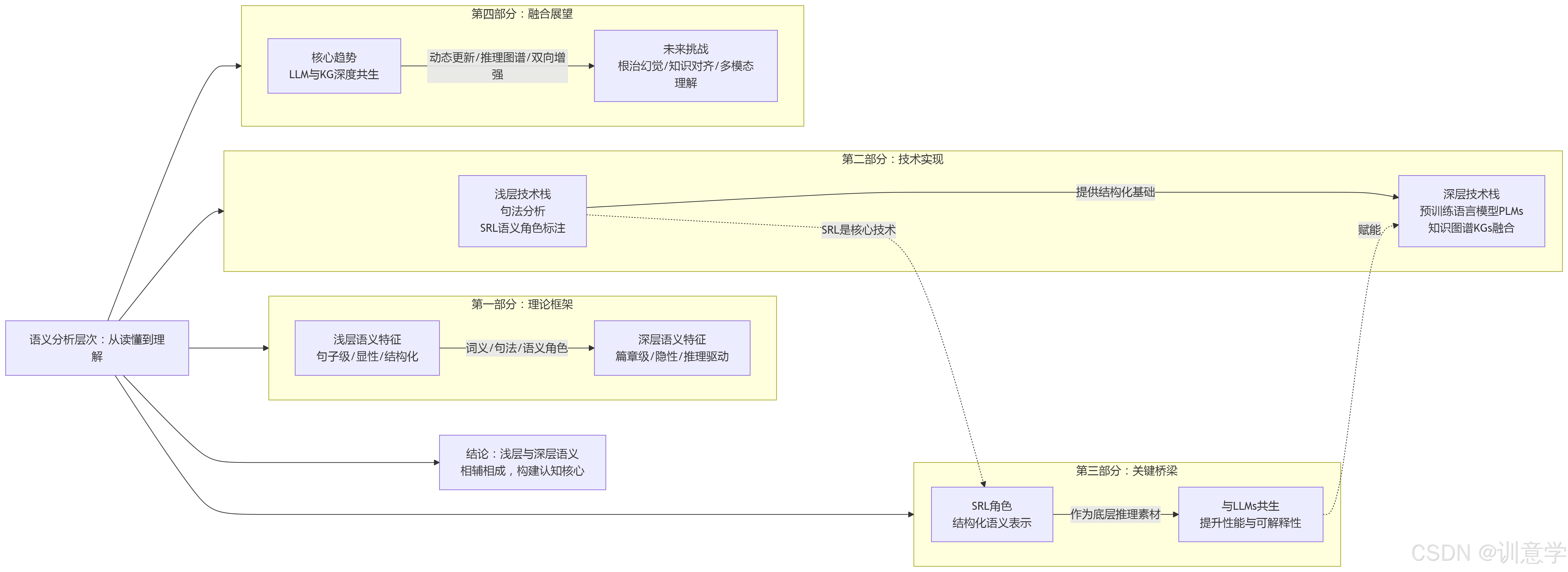
第一部分:语义特征的层次划分:理论框架与界定
为了精确探讨语义特征,我们必须首先为其建立清晰的理论定义。语言学的发展为我们提供了坚实的基础,从关注句子内部形式的结构主义,到探索语境、意图和认知过程的语用学与认知语言学,这些理论共同启发了NLP中对语义层次的划分。
1.1 浅层语义特征(Surface Semantics)的界定
浅层语义特征可以被定义为文本内部显性、结构化的语义信息。它的提取主要依赖于句子本身的词汇和语法结构,较少或完全不依赖外部世界知识。其核心是回答“一句话里,谁对谁做了什么”。
浅层语义分析的目标是捕捉句子级的、明确的语义关系,为更复杂的推理提供基础素材。根据学界共识与参考资料,浅层语义的构成要素主要包括:
- 词义特征: 这是语义的基本单元,包括词语的核心概念意义(如“书”是“装订成册的著作”),以及附加的感情、语体和形象色彩(如“团结”与“勾结”的褒贬之分)。
- 句法结构: 句子的组织方式,如中文常见的“主语-谓语-宾语”(SVO)结构,为理解基本语义关系提供了骨架。
- 核心语义角色: 这是浅层语义分析的重点,旨在识别出动作的直接参与者。其任务是识别句子中谓词(通常是动词)的论元,并为这些论元分配具体的语义角色,如施事者(Agent)、受事者(Patient)和工具(Instrument)等 。
特点总结: 浅层语义具有句子级、显性、结构化、上下文依赖较弱的特点。它关注的是“文本说了什么”,而非“文本意味着什么”。
1.2 深层语义特征(Deep Semantics)的界定
与浅层语义相对,深层语义特征被定义为超越字面意义的、依赖语境、常识和外部知识的隐性语义信息。它致力于揭示文本背后的逻辑、意图和隐含的知识网络。
深层语义分析需要回答“为什么会这样”以及“这意味着什么”等更复杂的问题。其构成要素更为丰富和抽象,相关研究将其归纳为:
- 隐含意义与逻辑关系: 识别跨越句子边界的因果、条件、转折等关系。例如,在“因为暴雨,比赛取消了”中,深层语义分析需要明确“暴雨”与“比赛取消”之间的因果链。这类任务通常通过自然语言推理(NLI)等基准进行评估 。
- 语境关联与指代: 这包括根据上下文确定代词的指代对象(如“她去看电影了”中的“她”是谁),以及消除多义词的歧义(如“苹果”在不同语境下指代水果还是公司)。
- 隐喻与文化逻辑: 理解非字面表达,如“经济寒冬”中的隐喻,或“喜鹊”在中国文化中象征喜庆的特定含义。这需要模型具备一定的文化背景知识。
- 篇章结构与意图: 分析整个段落或篇章的论证结构(如“问题-解决方案”模式),并推断作者的言外之意,如讽刺、暗示等。
特点总结: 深层语义具有跨句子/篇章级、隐性、推理驱动、强依赖上下文与外部知识的特点。它探索的是语言背后复杂的认知与逻辑世界。
第二部分:技术分野:不同层次语义特征的提取方法对比
对不同层次语义的追求,催生了截然不同的技术路线。从早期的规则和统计方法,到如今由深度学习主导的时代,技术的发展深刻地反映了我们对语义理解深度的不断探索。
2.1 浅层语义分析技术栈
浅层语义分析技术成熟较早,其目标是构建精确、结构化的句子级语义表示。
句法分析(Syntactic Parsing)
句法分析是所有语义分析的基石。它通过生成成分句法树或依存关系图,揭示句子的语法结构。虽然其直接目标是语法而非语义,但它提供的句子骨架是后续识别语义角色的重要依据。语义角色标注(Semantic Role Labeling, SRL)
SRL可以被视为浅层语义分析的核心与巅峰,它完美地连接了句法结构与初步的语义理解。SRL的核心任务是围绕句子中的谓词,识别出其对应的语义角色 。例如,在句子“小明用刀切苹果”中,SRL系统会以“切”为中心,标注出:- 施事者 (Agent): 小明
- 受事者 (Patient): 苹果
- 工具 (Instrument): 刀
这一过程主要依赖于如 PropBank(基于动词的论元库)或 FrameNet(基于框架的语义库)等理论框架,这些也是训练和评估SRL系统的关键基准数据集 。早期的SRL模型多采用基于特征工程的统计方法,后来发展为使用BiLSTM-CRF等深度学习模型,将任务视为句子内部的序列标注问题。其性能评估通常采用严格的指标,如精确度(Precision)、召回率(Recall)和F1值,要求预测的论元边界和角色标签都必须与标准答案完全匹配才算正确 。
2.2 深层语义分析技术栈
深层语义分析则更多地依赖于能够处理复杂上下文和外部知识的现代技术。
- 预训练语言模型(PLMs)的主导作用
自BERT GPT等预训练语言模型(PLMs,特别是现在被称为大型语言模型LLMs)的出现以来,深层语义分析领域发生了革命性的变化 。其核心在于Transformer架构的自注意力机制(Self-Attention),该机制使得模型能够动态地权衡句子中所有词语之间的关系,从而捕捉长距离依赖和复杂的上下文信息 。这与过去静态的词向量(如Word2Vec)有本质区别。
PLMs通过在海量无标注文本上进行预训练,实现了逐层抽象的特征学习:底层网络倾向于学习词法和句法等浅层特征,而高层网络则能形成更丰富的上下文语义表示。这种内在的层次性使得PLMs在处理需要深度推理的任务时表现卓越,例如在GLUE、SuperGLUE等综合性语言理解基准上取得了最先进的成果,这些基准包含了自然语言推理(NLI)和机器阅读理解(MRC)等任务 。
- 知识图谱(KG)与外部知识的融合
尽管PLMs能力强大,但它们本质上是从文本数据中学习统计规律,缺乏真实世界的“事实性”知识,容易产生“幻觉”(Hallucination),即生成与事实不符的内容 。为了解决这一问题,将PLMs与知识图谱融合成为近两年来(尤其自2023年以来)的关键研究方向 。知识图谱是一个结构化的知识库,包含了实体、属性及其之间的关系。
融合技术主要包括:
1. 实体链接(Entity Linking): 将文本中提及的实体(如“乔丹”)准确地链接到知识图谱中对应的节点(是篮球运动员迈克尔·乔丹,还是科学家迈克尔·I·乔丹)。
2. 知识注入模型(Knowledge-Enhanced Models): 如百度的ERNIE、清华的K-BERT等模型,在预训练阶段就将知识图谱中的三元组信息融入模型,使其直接学习知识 。
3. 检索增强生成(Retrieval-Augmented Generation, RAG): 这是当前缓解幻觉的主流方法之一,通过从外部知识库(包括知识图谱)检索相关信息,并将其作为上下文提供给LLM,来指导生成更准确、更可靠的内容 。研究表明,知识图谱能够有效减少LLMs的幻觉现象 。
知识图谱的引入,极大地增强了模型的深层语义推理能力,例如进行常识推理(“他举起锤子”的意图是“砸东西”)、消除歧义和补全文本中隐含的信息。
2.3 技术对比总结
| 特征维度 | 浅层语义分析技术 | 深层语义分析技术 |
|---|---|---|
| 核心任务 | 句法分析, 语义角色标注(SRL) | 自然语言推理(NLI), 机器阅读理解(MRC), 文本生成, 对话系统 |
| 处理单元 | 句子级 | 跨句子、段落、篇章级 |
| 关键技术 | 依存分析, BiLSTM-CRF, 特征工程 | Transformer, 预训练语言模型(PLMs/LLMs), 知识图谱(KG) |
| 知识依赖 | 弱依赖(主要依赖语法和词典) | 强依赖(依赖上下文、常识和外部世界知识) |
| 产出形式 | 结构化标签(如句法树、语义角色) | 概率分布、文本生成、分类决策(如蕴含/矛盾) |
| 可解释性 | 较高,结果直观 | 较低,常被视为“黑箱”模型 |
| 典型基准 | CoNLL-2005/2012 , PropBank | GLUE , SQuAD , MMLU |
第三部分:关键的桥梁:语义角色标注(SRL)在新时代的角色
在浅层与深层语义之间,SRL扮演着一个至关重要且不断演变的角色。它不仅是浅层语义分析的终点,更是通往深层理解的起点。
3.1 从结构化语义到底层推理
SRL提供的“谁-在何时何地-对谁-做了什么”的结构化信息,是构建事件表示的基础。这种表示形式比原始文本或句法树更接近人类的认知,为需要复杂推理的深层任务提供了规整的、半结构化的输入。例如,一个问答系统可以利用SRL结果快速定位“谁是动作的执行者”,从而更精确地回答“谁...?”类型的问题。
3.2 在LLM时代下的新生命力
有人可能会认为,端到端的LLMs已经强大到不再需要SRL这样的中间步骤。然而,近期的研究恰恰相反,显示了SRL与LLMs的共生关系。
首先,LLMs极大地提升了SRL的性能。最新的研究表明,基于LLM的方法首次在完整的SRL任务(如CoNLL-2012基准)上全面超越了传统的、精心设计的模型 。例如,DSRL等模型在CoNLL-2012测试集上取得了新的SOTA(State-of-the-art) F1分数 比之前的最佳方法提升了超过2.5个F1点 。这证明了LLMs强大的上下文理解能力能够更准确地识别谓词-论元结构。
其次,SRL可以反过来为LLMs提供可解释性和结构化约束。LLMs的“黑箱”特性使其推理过程难以捉摸。而SRL可以作为一种显式的“语义脚手架”,将LLM的内部隐性知识外化为可读的语义结构。这对于需要高可靠性和可追溯性的应用(如法律、金融文本分析)至关重要。通过提示(Prompting)等方式引导LLM进行SRL任务,可以使其生成更符合逻辑和事实的内容。
因此,SRL并未在LLM时代被淘汰,而是从一个独立的NLP任务,演变为一个与LLMs深度融合、互相促进的关键组件。
第四部分:融合与展望:迈向统一的语义理解
展望未来,浅层与深层语义分析的界限正逐渐模糊,技术发展的趋势是构建一个能够无缝整合结构化知识、上下文信息和常识推理的统一语义理解框架。
4.1 核心趋势:LLM与KG的深度共生
正如前文所述,LLM与KG的结合是当前及未来几年的核心研究热点。自2023年以来,这一领域的进展尤为迅速 。未来的融合将超越简单的检索增强,向更深层次的共生关系发展:
- 知识的动态更新与编辑: LLMs面临着知识陈旧的挑战 。未来的一个重要方向是利用KG作为动态、可信的知识源,开发高效的知识编辑技术,让LLMs能够实时更新其内部知识库,而不是通过昂贵的重新训练 。
- 从知识图谱到“推理图谱”: KG不仅提供事实,还能提供推理路径。未来的系统可能会利用LLMs的推理能力,在KG上进行多步推理,从而回答更复杂的问题,这超越了简单的信息检索。
- 双向增强: 不仅是KG增强LLM,LLM也在反哺KG。LLMs强大的文本理解能力可以被用来从海量非结构化文本中自动构建和扩展知识图谱,形成一个自我完善的良性循环。
4.2 面临的挑战与未来方向
尽管前景光明,但实现真正的深度语义理解仍面临诸多挑战:
- 幻觉问题的根除: 虽然KG融合等技术能够缓解幻觉,但如何从根本上建立模型的因果推理能力,使其“知道自己不知道”,仍然是一个开放性问题。这需要开发更先进的评估基准(如Haluval)和检测机制 。
- 大规模知识的构建与对齐: 高质量知识图谱的构建成本高昂 ,且如何将这些符号化的知识与LLMs的分布式表示进行有效对齐,仍是技术难题。
- 多模态与跨文化理解: 真正的理解不仅限于文本,还包括图像、声音等多种模态。同时,语言背后的文化逻辑和常识也是深层语义的重要组成部分,如何让模型跨越文化壁垒进行理解,是前沿的探索方向。
结论
从浅层语义的“读懂字面”,到深层语义的“理解内涵”,自然语言处理的发展历程是一场对人类智能不断深入的模拟与探索。本文系统地梳理了浅层与深层语义的理论界定、技术实现和核心差异。我们看到,以 语义角色标注(SRL) 为代表的浅层分析技术,提供了关键的结构化语义信息,并正在与现代 大型语言模型(LLMs) 深度融合,焕发出新的活力。
同时,以LLMs和 知识图谱(KGs) 的共生为核心的深层语义分析技术,正引领我们攻克如“幻觉”等长期挑战,推动AI从一个强大的模式匹配器,向一个具备初步推理和理解能力的认知体迈进。
最终,浅层语义提供的结构化骨架与深层语义赋予的丰富血肉,二者并非相互替代,而是相辅相成。它们的融合与协同,将共同构建起下一代人工智能的认知核心,最终帮助我们跨越从“读懂”到“理解”的鸿沟,实现更自然、更智能的人机交互。