HTS-AT模型代码分析
该模型一个有两个文件,layers.py文件和htsat.py文件
layers.py
先给出完整的代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
from itertools import repeat
import collections.abc
import math
import warningsfrom torch.nn.init import _calculate_fan_in_and_fan_out# from PyTorch internals
def _ntuple(n):def parse(x):if isinstance(x, collections.abc.Iterable):return xreturn tuple(repeat(x, n))return parseto_1tuple = _ntuple(1)
to_2tuple = _ntuple(2)
to_3tuple = _ntuple(3)
to_4tuple = _ntuple(4)
to_ntuple = _ntupledef drop_path(x, drop_prob: float = 0., training: bool = False):"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted forchanging the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use'survival rate' as the argument."""if drop_prob == 0. or not training:return xkeep_prob = 1 - drop_probshape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNetsrandom_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)random_tensor.floor_() # binarizeoutput = x.div(keep_prob) * random_tensorreturn outputclass DropPath(nn.Module):"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."""def __init__(self, drop_prob=None):super(DropPath, self).__init__()self.drop_prob = drop_probdef forward(self, x):return drop_path(x, self.drop_prob, self.training)class PatchEmbed(nn.Module):""" 2D Image to Patch Embedding"""def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768, norm_layer=None, flatten=True, patch_stride = 16):super().__init__()img_size = to_2tuple(img_size)patch_size = to_2tuple(patch_size)patch_stride = to_2tuple(patch_stride)self.img_size = img_sizeself.patch_size = patch_sizeself.patch_stride = patch_strideself.grid_size = (img_size[0] // patch_stride[0], img_size[1] // patch_stride[1])self.num_patches = self.grid_size[0] * self.grid_size[1]self.flatten = flattenself.in_chans = in_chansself.embed_dim = embed_dimpadding = ((patch_size[0] - patch_stride[0]) // 2, (patch_size[1] - patch_stride[1]) // 2)self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_stride, padding=padding)self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()def forward(self, x):B, C, H, W = x.shapeassert H == self.img_size[0] and W == self.img_size[1], \f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."x = self.proj(x)if self.flatten:x = x.flatten(2).transpose(1, 2) # BCHW -> BNCx = self.norm(x)return xclass Mlp(nn.Module):""" MLP as used in Vision Transformer, MLP-Mixer and related networks"""def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Linear(in_features, hidden_features)self.act = act_layer()self.fc2 = nn.Linear(hidden_features, out_features)self.drop = nn.Dropout(drop)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return xdef _no_grad_trunc_normal_(tensor, mean, std, a, b):# Cut & paste from PyTorch official master until it's in a few official releases - RW# Method based on https://people.sc.fsu.edu/~jburkardt/presentations/truncated_normal.pdfdef norm_cdf(x):# Computes standard normal cumulative distribution functionreturn (1. + math.erf(x / math.sqrt(2.))) / 2.if (mean < a - 2 * std) or (mean > b + 2 * std):warnings.warn("mean is more than 2 std from [a, b] in nn.init.trunc_normal_. ""The distribution of values may be incorrect.",stacklevel=2)with torch.no_grad():# Values are generated by using a truncated uniform distribution and# then using the inverse CDF for the normal distribution.# Get upper and lower cdf valuesl = norm_cdf((a - mean) / std)u = norm_cdf((b - mean) / std)# Uniformly fill tensor with values from [l, u], then translate to# [2l-1, 2u-1].tensor.uniform_(2 * l - 1, 2 * u - 1)# Use inverse cdf transform for normal distribution to get truncated# standard normaltensor.erfinv_()# Transform to proper mean, stdtensor.mul_(std * math.sqrt(2.))tensor.add_(mean)# Clamp to ensure it's in the proper rangetensor.clamp_(min=a, max=b)return tensordef trunc_normal_(tensor, mean=0., std=1., a=-2., b=2.):# type: (Tensor, float, float, float, float) -> Tensorr"""Fills the input Tensor with values drawn from a truncatednormal distribution. The values are effectively drawn from thenormal distribution :math:`\mathcal{N}(\text{mean}, \text{std}^2)`with values outside :math:`[a, b]` redrawn until they are withinthe bounds. The method used for generating the random values worksbest when :math:`a \leq \text{mean} \leq b`.Args:tensor: an n-dimensional `torch.Tensor`mean: the mean of the normal distributionstd: the standard deviation of the normal distributiona: the minimum cutoff valueb: the maximum cutoff valueExamples:>>> w = torch.empty(3, 5)>>> nn.init.trunc_normal_(w)"""return _no_grad_trunc_normal_(tensor, mean, std, a, b)def variance_scaling_(tensor, scale=1.0, mode='fan_in', distribution='normal'):fan_in, fan_out = _calculate_fan_in_and_fan_out(tensor)if mode == 'fan_in':denom = fan_inelif mode == 'fan_out':denom = fan_outelif mode == 'fan_avg':denom = (fan_in + fan_out) / 2variance = scale / denomif distribution == "truncated_normal":# constant is stddev of standard normal truncated to (-2, 2)trunc_normal_(tensor, std=math.sqrt(variance) / .87962566103423978)elif distribution == "normal":tensor.normal_(std=math.sqrt(variance))elif distribution == "uniform":bound = math.sqrt(3 * variance)tensor.uniform_(-bound, bound)else:raise ValueError(f"invalid distribution {distribution}")def lecun_normal_(tensor):variance_scaling_(tensor, mode='fan_in', distribution='truncated_normal')
这段代码实现了构建Transformer模型(特别是类Swin Transformer结构)所需的核心基础组件,主要用于音频或图像的特征提取与处理,是HTS-AT(一种用于声音分类和检测的层次化token语义音频Transformer)模型的基础模块。以下是详细解释:
1. 基础工具函数
元组转换函数(_ntuple及衍生函数)
def _ntuple(n):def parse(x):if isinstance(x, collections.abc.Iterable):return xreturn tuple(repeat(x, n))return parseto_1tuple = _ntuple(1)
to_2tuple = _ntuple(2)
to_3tuple = _ntuple(3)
to_4tuple = _ntuple(4)
to_ntuple = _ntuple
- 功能:将输入转换为指定长度的元组。若输入是可迭代对象(如列表)则直接返回,否则将输入值重复
n次并转为元组。 - 用途:统一处理模型参数中“单值”或“多值”的情况(例如图像大小
img_size可以是224或(224, 224),通过to_2tuple可统一转为(224, 224))。
2. 随机深度(Stochastic Depth)实现
drop_path函数
def drop_path(x, drop_prob: float = 0., training: bool = False):if drop_prob == 0. or not training:return xkeep_prob = 1 - drop_probshape = (x.shape[0],) + (1,) * (x.ndim - 1) # 形状为(batch_size, 1, 1, ...)random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)random_tensor.floor_() # 二值化(0或1)output = x.div(keep_prob) * random_tensor # 除以keep_prob保持期望不变return output
- 功能:实现“随机深度”正则化,训练时随机丢弃部分样本的路径(而非单个神经元),减少过拟合。
- 原理:对每个样本生成一个随机二进制掩码(0或1),若为0则丢弃该样本的路径,为1则保留(并除以保留概率以维持输出期望)。
DropPath类
class DropPath(nn.Module):def __init__(self, drop_prob=None):super().__init__()self.drop_prob = drop_probdef forward(self, x):return drop_path(x, self.drop_prob, self.training)
- 功能:将
drop_path函数封装为PyTorch模块,方便集成到模型的层结构中。
3. 补丁嵌入(Patch Embedding)
PatchEmbed类
class PatchEmbed(nn.Module):"""2D图像/特征图到补丁嵌入的转换"""def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768, norm_layer=None, flatten=True, patch_stride=16):super().__init__()# 转换为元组格式(统一处理单值/多值输入)img_size = to_2tuple(img_size)patch_size = to_2tuple(patch_size)patch_stride = to_2tuple(patch_stride)self.img_size = img_size # 输入图像尺寸(H, W)self.patch_size = patch_size # 补丁大小(PH, PW)self.patch_stride = patch_stride # 滑动步长(SH, SW)# 计算输出网格大小(补丁数量的空间维度)self.grid_size = (img_size[0] // patch_stride[0], img_size[1] // patch_stride[1])self.num_patches = self.grid_size[0] * self.grid_size[1] # 总补丁数self.flatten = flatten # 是否将空间维度展平为序列self.in_chans = in_chans # 输入通道数self.embed_dim = embed_dim # 嵌入维度# 计算填充,使卷积后尺寸匹配预期(保持边界信息)padding = ((patch_size[0] - patch_stride[0]) // 2, (patch_size[1] - patch_stride[1]) // 2)# 用卷积层实现补丁嵌入:将每个补丁映射到embed_dim维度self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_stride, padding=padding)# 归一化层(可选)self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()def forward(self, x):B, C, H, W = x.shape # 输入形状:(批量大小, 通道数, 高度, 宽度)# 校验输入尺寸是否匹配模型预期assert H == self.img_size[0] and W == self.img_size[1], f"输入尺寸({H}*{W})与模型预期({self.img_size[0]}*{self.img_size[1]})不匹配"x = self.proj(x) # 卷积得到补丁特征:(B, embed_dim, grid_size[0], grid_size[1])if self.flatten:# 展平为序列:(B, embed_dim, num_patches) -> (B, num_patches, embed_dim)x = x.flatten(2).transpose(1, 2)x = self.norm(x) # 归一化return x
- 功能:将2D输入(图像或音频特征图)分割为重叠或非重叠的补丁,并将每个补丁映射到高维嵌入空间(类似ViT的补丁嵌入)。
- 核心实现:使用卷积层
proj替代手动分割+线性映射,效率更高。卷积核大小=补丁大小,步长=补丁步长,输出通道=嵌入维度。 - 用途:将原始输入转换为Transformer可处理的序列格式(
(B, N, C),其中N为补丁数,C为嵌入维度)。
4. 多层感知器(MLP)
Mlp类
class Mlp(nn.Module):"""Transformer中使用的MLP结构(如ViT、MLP-Mixer)"""def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_features # 输出维度(默认与输入相同)hidden_features = hidden_features or in_features # 隐藏层维度(默认与输入相同)self.fc1 = nn.Linear(in_features, hidden_features) # 第一层线性变换self.act = act_layer() # 激活函数(默认GELU)self.fc2 = nn.Linear(hidden_features, out_features) # 第二层线性变换self.drop = nn.Dropout(drop) # Dropout层def forward(self, x):x = self.fc1(x) # (B, N, in_features) -> (B, N, hidden_features)x = self.act(x) # 激活x = self.drop(x) # dropoutx = self.fc2(x) # (B, N, hidden_features) -> (B, N, out_features)x = self.drop(x) # dropoutreturn x
- 功能:实现Transformer块中用于特征转换的MLP模块,通常接在自注意力层之后。
- 结构:两层线性变换+激活函数+Dropout,是Transformer中“特征映射”的核心组件。
5. 参数初始化函数
截断正态分布初始化(_no_grad_trunc_normal_和trunc_normal_)
def _no_grad_trunc_normal_(tensor, mean, std, a, b):# 无梯度地将tensor初始化为截断正态分布(值落在[a, b]范围内)def norm_cdf(x):# 标准正态分布的累积分布函数(CDF)return (1. + math.erf(x / math.sqrt(2.))) / 2.# 校验均值是否在合理范围内if (mean < a - 2 * std) or (mean > b + 2 * std):warnings.warn("均值与[a, b]范围偏差过大,可能导致分布异常")with torch.no_grad(): # 无梯度计算# 生成[a, b]范围内的截断正态分布l = norm_cdf((a - mean) / std)u = norm_cdf((b - mean) / std)tensor.uniform_(2 * l - 1, 2 * u - 1) # 均匀分布映射到CDF范围tensor.erfinv_() # 逆CDF转换为正态分布tensor.mul_(std * math.sqrt(2.)) # 调整标准差tensor.add_(mean) # 调整均值tensor.clamp_(min=a, max=b) # 确保值在[a, b]内return tensordef trunc_normal_(tensor, mean=0., std=1., a=-2., b=2.):# 封装_no_grad_trunc_normal_,提供更简洁的接口return _no_grad_trunc_normal_(tensor, mean, std, a, b)
- 功能:生成截断正态分布的参数初始化(值限制在
[a, b]范围内),避免极端值导致的训练不稳定。 - 用途:常用于Transformer中注意力权重、线性层权重的初始化。
方差缩放初始化(variance_scaling_和lecun_normal_)
def variance_scaling_(tensor, scale=1.0, mode='fan_in', distribution='normal'):# 根据输入/输出维度(扇入/扇出)调整方差的初始化方法fan_in, fan_out = _calculate_fan_in_and_fan_out(tensor) # 计算扇入(输入特征数)和扇出(输出特征数)# 选择方差计算的分母if mode == 'fan_in':denom = fan_inelif mode == 'fan_out':denom = fan_outelif mode == 'fan_avg':denom = (fan_in + fan_out) / 2variance = scale / denom # 方差 = scale / 分母# 根据分布类型初始化if distribution == "truncated_normal":trunc_normal_(tensor, std=math.sqrt(variance) / .87962566103423978)elif distribution == "normal":tensor.normal_(std=math.sqrt(variance))elif distribution == "uniform":bound = math.sqrt(3 * variance)tensor.uniform_(-bound, bound)else:raise ValueError(f"不支持的分布类型: {distribution}")def lecun_normal_(tensor):# LeCun初始化:基于fan_in的截断正态分布(常用于激活函数为tanh/sigmoid的网络)variance_scaling_(tensor, mode='fan_in', distribution='truncated_normal')
- 功能:根据层的输入/输出维度(扇入/扇出)动态调整参数方差,确保信号在网络中传播时的稳定性。
lecun_normal_:是variance_scaling_的特例,采用fan_in模式和截断正态分布,对应LeCun提出的初始化方法。
总结
这段代码是构建Transformer模型的“基础工具箱”,包含:
- 数据格式处理工具(元组转换);
- 正则化组件(随机深度);
- 输入特征转换模块(补丁嵌入);
- 核心特征映射组件(MLP);
- 稳定训练的参数初始化方法。
这些组件被HTS-AT模型用于处理音频数据(将音频特征图转换为token序列,再通过Transformer进行层次化语义建模),同时也参考了Swin Transformer的设计思想,适用于视觉或音频等2D特征的处理场景。
htsat.py
先给出完整的代码:
import logging
import pdb
import math
import random
from numpy.core.fromnumeric import clip, reshape
import torch
import torch.nn as nn
import torch.utils.checkpoint as checkpointfrom torchlibrosa.stft import Spectrogram, LogmelFilterBank
from torchlibrosa.augmentation import SpecAugmentationfrom itertools import repeat
from typing import List
from .layers import PatchEmbed, Mlp, DropPath, trunc_normal_, to_2tuple
from utils import do_mixup, interpolate# below codes are based and referred from https://github.com/microsoft/Swin-Transformer
# Swin Transformer for Computer Vision: https://arxiv.org/pdf/2103.14030.pdfdef window_partition(x, window_size):"""Args:x: (B, H, W, C)window_size (int): window sizeReturns:windows: (num_windows*B, window_size, window_size, C)"""B, H, W, C = x.shapex = x.view(B, H // window_size, window_size, W // window_size, window_size, C)windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)return windowsdef window_reverse(windows, window_size, H, W):"""Args:windows: (num_windows*B, window_size, window_size, C)window_size (int): Window sizeH (int): Height of imageW (int): Width of imageReturns:x: (B, H, W, C)"""B = int(windows.shape[0] / (H * W / window_size / window_size))x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)return xclass WindowAttention(nn.Module):r""" Window based multi-head self attention (W-MSA) module with relative position bias.It supports both of shifted and non-shifted window.Args:dim (int): Number of input channels.window_size (tuple[int]): The height and width of the window.num_heads (int): Number of attention heads.qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: Trueqk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if setattn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0proj_drop (float, optional): Dropout ratio of output. Default: 0.0"""def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):super().__init__()self.dim = dimself.window_size = window_size # Wh, Wwself.num_heads = num_headshead_dim = dim // num_headsself.scale = qk_scale or head_dim ** -0.5# define a parameter table of relative position biasself.relative_position_bias_table = nn.Parameter(torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH# get pair-wise relative position index for each token inside the windowcoords_h = torch.arange(self.window_size[0])coords_w = torch.arange(self.window_size[1])coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Wwcoords_flatten = torch.flatten(coords, 1) # 2, Wh*Wwrelative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Wwrelative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0relative_coords[:, :, 1] += self.window_size[1] - 1relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Wwself.register_buffer("relative_position_index", relative_position_index)self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop)trunc_normal_(self.relative_position_bias_table, std=.02)self.softmax = nn.Softmax(dim=-1)def forward(self, x, mask=None):"""Args:x: input features with shape of (num_windows*B, N, C)mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None"""B_, N, C = x.shapeqkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)q = q * self.scaleattn = (q @ k.transpose(-2, -1))relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nHrelative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Wwattn = attn + relative_position_bias.unsqueeze(0)if mask is not None:nW = mask.shape[0]attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)attn = attn.view(-1, self.num_heads, N, N)attn = self.softmax(attn)else:attn = self.softmax(attn)attn = self.attn_drop(attn)x = (attn @ v).transpose(1, 2).reshape(B_, N, C)x = self.proj(x)x = self.proj_drop(x)return x, attndef extra_repr(self):return f'dim={self.dim}, window_size={self.window_size}, num_heads={self.num_heads}'# We use the model based on Swintransformer Block, therefore we can use the swin-transformer pretrained model
class SwinTransformerBlock(nn.Module):r""" Swin Transformer Block.Args:dim (int): Number of input channels.input_resolution (tuple[int]): Input resulotion.num_heads (int): Number of attention heads.window_size (int): Window size.shift_size (int): Shift size for SW-MSA.mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: Trueqk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.drop (float, optional): Dropout rate. Default: 0.0attn_drop (float, optional): Attention dropout rate. Default: 0.0drop_path (float, optional): Stochastic depth rate. Default: 0.0act_layer (nn.Module, optional): Activation layer. Default: nn.GELUnorm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm"""def __init__(self, dim, input_resolution, num_heads, window_size=7, shift_size=0,mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,act_layer=nn.GELU, norm_layer=nn.LayerNorm, norm_before_mlp='ln'):super().__init__()self.dim = dimself.input_resolution = input_resolutionself.num_heads = num_headsself.window_size = window_sizeself.shift_size = shift_sizeself.mlp_ratio = mlp_ratioself.norm_before_mlp = norm_before_mlpif min(self.input_resolution) <= self.window_size:# if window size is larger than input resolution, we don't partition windowsself.shift_size = 0self.window_size = min(self.input_resolution)assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"self.norm1 = norm_layer(dim)self.attn = WindowAttention(dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()if self.norm_before_mlp == 'ln':self.norm2 = nn.LayerNorm(dim)elif self.norm_before_mlp == 'bn':self.norm2 = lambda x: nn.BatchNorm1d(dim)(x.transpose(1, 2)).transpose(1, 2)else:raise NotImplementedErrormlp_hidden_dim = int(dim * mlp_ratio)self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)if self.shift_size > 0:# calculate attention mask for SW-MSAH, W = self.input_resolutionimg_mask = torch.zeros((1, H, W, 1)) # 1 H W 1h_slices = (slice(0, -self.window_size),slice(-self.window_size, -self.shift_size),slice(-self.shift_size, None))w_slices = (slice(0, -self.window_size),slice(-self.window_size, -self.shift_size),slice(-self.shift_size, None))cnt = 0for h in h_slices:for w in w_slices:img_mask[:, h, w, :] = cntcnt += 1mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1mask_windows = mask_windows.view(-1, self.window_size * self.window_size)attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))else:attn_mask = Noneself.register_buffer("attn_mask", attn_mask)def forward(self, x):# pdb.set_trace()H, W = self.input_resolution# print("H: ", H)# print("W: ", W)# pdb.set_trace()B, L, C = x.shape# assert L == H * W, "input feature has wrong size"shortcut = xx = self.norm1(x)x = x.view(B, H, W, C)# cyclic shiftif self.shift_size > 0:shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))else:shifted_x = x# partition windowsx_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, Cx_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C# W-MSA/SW-MSAattn_windows, attn = self.attn(x_windows, mask=self.attn_mask) # nW*B, window_size*window_size, C# merge windowsattn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C# reverse cyclic shiftif self.shift_size > 0:x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))else:x = shifted_xx = x.view(B, H * W, C)# FFNx = shortcut + self.drop_path(x)x = x + self.drop_path(self.mlp(self.norm2(x)))return x, attndef extra_repr(self):return f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, " \f"window_size={self.window_size}, shift_size={self.shift_size}, mlp_ratio={self.mlp_ratio}"class PatchMerging(nn.Module):r""" Patch Merging Layer.Args:input_resolution (tuple[int]): Resolution of input feature.dim (int): Number of input channels.norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm"""def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):super().__init__()self.input_resolution = input_resolutionself.dim = dimself.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)self.norm = norm_layer(4 * dim)def forward(self, x):"""x: B, H*W, C"""H, W = self.input_resolutionB, L, C = x.shapeassert L == H * W, "input feature has wrong size"assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."x = x.view(B, H, W, C)x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 Cx1 = x[:, 1::2, 0::2, :] # B H/2 W/2 Cx2 = x[:, 0::2, 1::2, :] # B H/2 W/2 Cx3 = x[:, 1::2, 1::2, :] # B H/2 W/2 Cx = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*Cx = x.view(B, -1, 4 * C) # B H/2*W/2 4*Cx = self.norm(x)x = self.reduction(x)return xdef extra_repr(self):return f"input_resolution={self.input_resolution}, dim={self.dim}"class BasicLayer(nn.Module):""" A basic Swin Transformer layer for one stage.Args:dim (int): Number of input channels.input_resolution (tuple[int]): Input resolution.depth (int): Number of blocks.num_heads (int): Number of attention heads.window_size (int): Local window size.mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: Trueqk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.drop (float, optional): Dropout rate. Default: 0.0attn_drop (float, optional): Attention dropout rate. Default: 0.0drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNormdownsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: Noneuse_checkpoint (bool): Whether to use checkpointing to save memory. Default: False."""def __init__(self, dim, input_resolution, depth, num_heads, window_size,mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False,norm_before_mlp='ln'):super().__init__()self.dim = dimself.input_resolution = input_resolutionself.depth = depthself.use_checkpoint = use_checkpoint# build blocksself.blocks = nn.ModuleList([SwinTransformerBlock(dim=dim, input_resolution=input_resolution,num_heads=num_heads, window_size=window_size,shift_size=0 if (i % 2 == 0) else window_size // 2,mlp_ratio=mlp_ratio,qkv_bias=qkv_bias, qk_scale=qk_scale,drop=drop, attn_drop=attn_drop,drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,norm_layer=norm_layer, norm_before_mlp=norm_before_mlp)for i in range(depth)])# patch merging layerif downsample is not None:self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer)else:self.downsample = Nonedef forward(self, x):attns = []for blk in self.blocks:if self.use_checkpoint:x = checkpoint.checkpoint(blk, x)else:x, attn = blk(x)if not self.training:attns.append(attn.unsqueeze(0))if self.downsample is not None:x = self.downsample(x)if not self.training:attn = torch.cat(attns, dim = 0)attn = torch.mean(attn, dim = 0)return x, attndef extra_repr(self):return f"dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}"# The Core of HTSAT
class HTSAT_Swin_Transformer(nn.Module):r"""HTSAT based on the Swin TransformerArgs:spec_size (int | tuple(int)): Input Spectrogram size. Default 256patch_size (int | tuple(int)): Patch size. Default: 4path_stride (iot | tuple(int)): Patch Stride for Frequency and Time Axis. Default: 4in_chans (int): Number of input image channels. Default: 1 (mono)num_classes (int): Number of classes for classification head. Default: 527embed_dim (int): Patch embedding dimension. Default: 96depths (tuple(int)): Depth of each HTSAT-Swin Transformer layer.num_heads (tuple(int)): Number of attention heads in different layers.window_size (int): Window size. Default: 8mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: Trueqk_scale (float): Override default qk scale of head_dim ** -0.5 if set. Default: Nonedrop_rate (float): Dropout rate. Default: 0attn_drop_rate (float): Attention dropout rate. Default: 0drop_path_rate (float): Stochastic depth rate. Default: 0.1norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.ape (bool): If True, add absolute position embedding to the patch embedding. Default: Falsepatch_norm (bool): If True, add normalization after patch embedding. Default: Trueuse_checkpoint (bool): Whether to use checkpointing to save memory. Default: Falseconfig (module): The configuration Module from config.py"""def __init__(self, spec_size=256, patch_size=4, patch_stride=(4,4), in_chans=1, num_classes=527,embed_dim=96, depths=[2, 2, 6, 2], num_heads=[4, 8, 16, 32],window_size=8, mlp_ratio=4., qkv_bias=True, qk_scale=None,drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,norm_layer=nn.LayerNorm, ape=False, patch_norm=True,use_checkpoint=False, norm_before_mlp='ln', config = None, **kwargs):super(HTSAT_Swin_Transformer, self).__init__()self.config = configself.spec_size = spec_size self.patch_stride = patch_strideself.patch_size = patch_sizeself.window_size = window_sizeself.embed_dim = embed_dimself.depths = depthsself.ape = apeself.in_chans = in_chansself.num_classes = num_classesself.num_heads = num_headsself.num_layers = len(self.depths)self.num_features = int(self.embed_dim * 2 ** (self.num_layers - 1))self.drop_rate = drop_rateself.attn_drop_rate = attn_drop_rateself.drop_path_rate = drop_path_rateself.qkv_bias = qkv_biasself.qk_scale = Noneself.patch_norm = patch_normself.norm_layer = norm_layer if self.patch_norm else Noneself.norm_before_mlp = norm_before_mlpself.mlp_ratio = mlp_ratioself.use_checkpoint = use_checkpoint# process mel-spec ; used only onceself.freq_ratio = self.spec_size // self.config.mel_binswindow = 'hann'center = Truepad_mode = 'reflect'ref = 1.0amin = 1e-10top_db = Noneself.interpolate_ratio = 32 # Downsampled ratio# Spectrogram extractorself.spectrogram_extractor = Spectrogram(n_fft=config.window_size, hop_length=config.hop_size, win_length=config.window_size, window=window, center=center, pad_mode=pad_mode, freeze_parameters=True)# Logmel feature extractorself.logmel_extractor = LogmelFilterBank(sr=config.sample_rate, n_fft=config.window_size, n_mels=config.mel_bins, fmin=config.fmin, fmax=config.fmax, ref=ref, amin=amin, top_db=top_db, freeze_parameters=True)# Spec augmenterself.spec_augmenter = SpecAugmentation(time_drop_width=64, time_stripes_num=2, freq_drop_width=8, freq_stripes_num=2) # 2 2self.bn0 = nn.BatchNorm2d(self.config.mel_bins)# split spctrogram into non-overlapping patchesself.patch_embed = PatchEmbed(img_size=self.spec_size, patch_size=self.patch_size, in_chans=self.in_chans, embed_dim=self.embed_dim, norm_layer=self.norm_layer, patch_stride = patch_stride)num_patches = self.patch_embed.num_patchespatches_resolution = self.patch_embed.grid_sizeself.patches_resolution = patches_resolution# absolute position embeddingif self.ape:self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, self.embed_dim))trunc_normal_(self.absolute_pos_embed, std=.02)self.pos_drop = nn.Dropout(p=self.drop_rate)# stochastic depthdpr = [x.item() for x in torch.linspace(0, self.drop_path_rate, sum(self.depths))] # stochastic depth decay rule# build layersself.layers = nn.ModuleList()for i_layer in range(self.num_layers):layer = BasicLayer(dim=int(self.embed_dim * 2 ** i_layer),input_resolution=(patches_resolution[0] // (2 ** i_layer),patches_resolution[1] // (2 ** i_layer)),depth=self.depths[i_layer],num_heads=self.num_heads[i_layer],window_size=self.window_size,mlp_ratio=self.mlp_ratio,qkv_bias=self.qkv_bias, qk_scale=self.qk_scale,drop=self.drop_rate, attn_drop=self.attn_drop_rate,drop_path=dpr[sum(self.depths[:i_layer]):sum(self.depths[:i_layer + 1])],norm_layer=self.norm_layer,downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,use_checkpoint=use_checkpoint,norm_before_mlp=self.norm_before_mlp)self.layers.append(layer)# A deprecated optimization for using a hierarchical output from different blocks# if self.config.htsat_hier_output:# self.norm = nn.ModuleList(# [self.norm_layer(# min(# self.embed_dim * (2 ** (len(self.depths) - 1)),# self.embed_dim * (2 ** (i + 1)) # )# ) for i in range(len(self.depths))] # )# else:self.norm = self.norm_layer(self.num_features)self.avgpool = nn.AdaptiveAvgPool1d(1)self.maxpool = nn.AdaptiveMaxPool1d(1)# A deprecated optimization for using the max value instead of average value# if self.config.htsat_use_max:# self.a_avgpool = nn.AvgPool1d(kernel_size=3, stride=1, padding=1)# self.a_maxpool = nn.MaxPool1d(kernel_size=3, stride=1, padding=1)if self.config.enable_tscam:# if self.config.htsat_hier_output:# self.tscam_conv = nn.ModuleList()# for i in range(len(self.depths)):# zoom_ratio = 2 ** min(len(self.depths) - 1, i + 1)# zoom_dim = min(# self.embed_dim * (2 ** (len(self.depths) - 1)),# self.embed_dim * (2 ** (i + 1)) # )# SF = self.spec_size // zoom_ratio // self.patch_stride[0] // self.freq_ratio# self.tscam_conv.append(# nn.Conv2d(# in_channels = zoom_dim,# out_channels = self.num_classes,# kernel_size = (SF, 3),# padding = (0,1)# )# )# self.head = nn.Linear(num_classes * len(self.depths), num_classes)# else:SF = self.spec_size // (2 ** (len(self.depths) - 1)) // self.patch_stride[0] // self.freq_ratioself.tscam_conv = nn.Conv2d(in_channels = self.num_features,out_channels = self.num_classes,kernel_size = (SF,3),padding = (0,1))self.head = nn.Linear(num_classes, num_classes)else:self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()self.apply(self._init_weights)def _init_weights(self, m):if isinstance(m, nn.Linear):trunc_normal_(m.weight, std=.02)if isinstance(m, nn.Linear) and m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.LayerNorm):nn.init.constant_(m.bias, 0)nn.init.constant_(m.weight, 1.0)@torch.jit.ignoredef no_weight_decay(self):return {'absolute_pos_embed'}@torch.jit.ignoredef no_weight_decay_keywords(self):return {'relative_position_bias_table'}def forward_features(self, x):# A deprecated optimization for using a hierarchical output from different blocks# if self.config.htsat_hier_output:# hier_x = []# hier_attn = []frames_num = x.shape[2] x = self.patch_embed(x)if self.ape:x = x + self.absolute_pos_embedx = self.pos_drop(x)for i, layer in enumerate(self.layers):x, attn = layer(x)# A deprecated optimization for using a hierarchical output from different blocks# if self.config.htsat_hier_output:# hier_x.append(x)# if i == len(self.layers) - 1:# hier_attn.append(attn)# A deprecated optimization for using a hierarchical output from different blocks# if self.config.htsat_hier_output:# hxs = []# fphxs = []# for i in range(len(hier_x)):# hx = hier_x[i]# hx = self.norm[i](hx)# B, N, C = hx.shape# zoom_ratio = 2 ** min(len(self.depths) - 1, i + 1)# SF = frames_num // zoom_ratio // self.patch_stride[0]# ST = frames_num // zoom_ratio // self.patch_stride[1]# hx = hx.permute(0,2,1).contiguous().reshape(B, C, SF, ST)# B, C, F, T = hx.shape# c_freq_bin = F // self.freq_ratio# hx = hx.reshape(B, C, F // c_freq_bin, c_freq_bin, T)# hx = hx.permute(0,1,3,2,4).contiguous().reshape(B, C, c_freq_bin, -1)# hx = self.tscam_conv[i](hx)# hx = torch.flatten(hx, 2)# fphx = interpolate(hx.permute(0,2,1).contiguous(), self.spec_size * self.freq_ratio // hx.shape[2])# hx = self.avgpool(hx)# hx = torch.flatten(hx, 1)# hxs.append(hx)# fphxs.append(fphx)# hxs = torch.cat(hxs, dim=1)# fphxs = torch.cat(fphxs, dim = 2)# hxs = self.head(hxs)# fphxs = self.head(fphxs)# output_dict = {'framewise_output': torch.sigmoid(fphxs), # 'clipwise_output': torch.sigmoid(hxs)}# return output_dictif self.config.enable_tscam:# for xx = self.norm(x)B, N, C = x.shapeSF = frames_num // (2 ** (len(self.depths) - 1)) // self.patch_stride[0]ST = frames_num // (2 ** (len(self.depths) - 1)) // self.patch_stride[1]x = x.permute(0,2,1).contiguous().reshape(B, C, SF, ST)B, C, F, T = x.shape# group 2D CNNc_freq_bin = F // self.freq_ratiox = x.reshape(B, C, F // c_freq_bin, c_freq_bin, T)x = x.permute(0,1,3,2,4).contiguous().reshape(B, C, c_freq_bin, -1)# get latent_outputlatent_output = self.avgpool(torch.flatten(x,2))latent_output = torch.flatten(latent_output, 1)# display the attention map, if neededif self.config.htsat_attn_heatmap:# for attnattn = torch.mean(attn, dim = 1)attn = torch.mean(attn, dim = 1)attn = attn.reshape(B, SF, ST)c_freq_bin = SF // self.freq_ratioattn = attn.reshape(B, SF // c_freq_bin, c_freq_bin, ST) attn = attn.permute(0,2,1,3).contiguous().reshape(B, c_freq_bin, -1)attn = attn.mean(dim = 1)attn_max = torch.max(attn, dim = 1, keepdim = True)[0]attn_min = torch.min(attn, dim = 1, keepdim = True)[0]attn = ((attn * 0.15) + (attn_max * 0.85 - attn_min)) / (attn_max - attn_min)attn = attn.unsqueeze(dim = 2)x = self.tscam_conv(x)x = torch.flatten(x, 2) # B, C, T# A deprecated optimization for using the max value instead of average value# if self.config.htsat_use_max:# x1 = self.a_maxpool(x)# x2 = self.a_avgpool(x)# x = x1 + x2if self.config.htsat_attn_heatmap:fpx = interpolate(torch.sigmoid(x).permute(0,2,1).contiguous() * attn, 8 * self.patch_stride[1]) else: fpx = interpolate(torch.sigmoid(x).permute(0,2,1).contiguous(), 8 * self.patch_stride[1]) # A deprecated optimization for using the max value instead of average value# if self.config.htsat_use_max:# x1 = self.avgpool(x)# x2 = self.maxpool(x)# x = x1 + x2# else:x = self.avgpool(x)x = torch.flatten(x, 1)if self.config.loss_type == "clip_ce":output_dict = {'framewise_output': fpx, # already sigmoided'clipwise_output': x,'latent_output': latent_output}else:output_dict = {'framewise_output': fpx, # already sigmoided'clipwise_output': torch.sigmoid(x),'latent_output': latent_output}else:x = self.norm(x) # B N CB, N, C = x.shapefpx = x.permute(0,2,1).contiguous().reshape(B, C, frames_num // (2 ** (len(self.depths) + 1)), frames_num // (2 ** (len(self.depths) + 1)) )B, C, F, T = fpx.shapec_freq_bin = F // self.freq_ratiofpx = fpx.reshape(B, C, F // c_freq_bin, c_freq_bin, T)fpx = fpx.permute(0,1,3,2,4).contiguous().reshape(B, C, c_freq_bin, -1)fpx = torch.sum(fpx, dim = 2)fpx = interpolate(fpx.permute(0,2,1).contiguous(), 8 * self.patch_stride[1]) x = self.avgpool(x.transpose(1, 2)) # B C 1x = torch.flatten(x, 1)if self.num_classes > 0:x = self.head(x)fpx = self.head(fpx)output_dict = {'framewise_output': torch.sigmoid(fpx), 'clipwise_output': torch.sigmoid(x)}return output_dictdef crop_wav(self, x, crop_size, spe_pos = None):time_steps = x.shape[2]tx = torch.zeros(x.shape[0], x.shape[1], crop_size, x.shape[3]).to(x.device)for i in range(len(x)):if spe_pos is None:crop_pos = random.randint(0, time_steps - crop_size - 1)else:crop_pos = spe_postx[i][0] = x[i, 0, crop_pos:crop_pos + crop_size,:]return tx# Reshape the wavform to a img size, if you want to use the pretrained swin transformer modeldef reshape_wav2img(self, x):B, C, T, F = x.shapetarget_T = int(self.spec_size * self.freq_ratio)target_F = self.spec_size // self.freq_ratioassert T <= target_T and F <= target_F, "the wav size should less than or equal to the swin input size"# to avoid bicubic zero errorif T < target_T:x = nn.functional.interpolate(x, (target_T, x.shape[3]), mode="bicubic", align_corners=True)if F < target_F:x = nn.functional.interpolate(x, (x.shape[2], target_F), mode="bicubic", align_corners=True)x = x.permute(0,1,3,2).contiguous()x = x.reshape(x.shape[0], x.shape[1], x.shape[2], self.freq_ratio, x.shape[3] // self.freq_ratio)# print(x.shape)x = x.permute(0,1,3,2,4).contiguous()x = x.reshape(x.shape[0], x.shape[1], x.shape[2] * x.shape[3], x.shape[4])return x# Repeat the wavform to a img size, if you want to use the pretrained swin transformer modeldef repeat_wat2img(self, x, cur_pos):B, C, T, F = x.shapetarget_T = int(self.spec_size * self.freq_ratio)target_F = self.spec_size // self.freq_ratioassert T <= target_T and F <= target_F, "the wav size should less than or equal to the swin input size"# to avoid bicubic zero errorif T < target_T:x = nn.functional.interpolate(x, (target_T, x.shape[3]), mode="bicubic", align_corners=True)if F < target_F:x = nn.functional.interpolate(x, (x.shape[2], target_F), mode="bicubic", align_corners=True) x = x.permute(0,1,3,2).contiguous() # B C F Tx = x[:,:,:,cur_pos:cur_pos + self.spec_size]x = x.repeat(repeats = (1,1,4,1))return xdef forward(self, x: torch.Tensor, mixup_lambda = None, infer_mode = False):# out_feat_keys: List[str] = None):x = self.spectrogram_extractor(x) # (batch_size, 1, time_steps, freq_bins)x = self.logmel_extractor(x) # (batch_size, 1, time_steps, mel_bins)x = x.transpose(1, 3)x = self.bn0(x)x = x.transpose(1, 3)if self.training:x = self.spec_augmenter(x)if self.training and mixup_lambda is not None:x = do_mixup(x, mixup_lambda)if infer_mode:# in infer mode. we need to handle different length audio inputframe_num = x.shape[2]target_T = int(self.spec_size * self.freq_ratio)repeat_ratio = math.floor(target_T / frame_num)x = x.repeat(repeats=(1,1,repeat_ratio,1))x = self.reshape_wav2img(x)output_dict = self.forward_features(x)elif self.config.enable_repeat_mode:if self.training:cur_pos = random.randint(0, (self.freq_ratio - 1) * self.spec_size - 1)x = self.repeat_wat2img(x, cur_pos)output_dict = self.forward_features(x)else:output_dicts = []for cur_pos in range(0, (self.freq_ratio - 1) * self.spec_size + 1, self.spec_size):tx = x.clone()tx = self.repeat_wat2img(tx, cur_pos)output_dicts.append(self.forward_features(tx))clipwise_output = torch.zeros_like(output_dicts[0]["clipwise_output"]).float().to(x.device)framewise_output = torch.zeros_like(output_dicts[0]["framewise_output"]).float().to(x.device)for d in output_dicts:clipwise_output += d["clipwise_output"]framewise_output += d["framewise_output"]clipwise_output = clipwise_output / len(output_dicts)framewise_output = framewise_output / len(output_dicts)output_dict = {'framewise_output': framewise_output, 'clipwise_output': clipwise_output}else:if x.shape[2] > self.freq_ratio * self.spec_size:if self.training:x = self.crop_wav(x, crop_size=self.freq_ratio * self.spec_size)x = self.reshape_wav2img(x)output_dict = self.forward_features(x)else:# Change: Hard code hereoverlap_size = (x.shape[2] - 1) // 4output_dicts = []crop_size = (x.shape[2] - 1) // 2for cur_pos in range(0, x.shape[2] - crop_size - 1, overlap_size):tx = self.crop_wav(x, crop_size = crop_size, spe_pos = cur_pos)tx = self.reshape_wav2img(tx)output_dicts.append(self.forward_features(tx))clipwise_output = torch.zeros_like(output_dicts[0]["clipwise_output"]).float().to(x.device)framewise_output = torch.zeros_like(output_dicts[0]["framewise_output"]).float().to(x.device)for d in output_dicts:clipwise_output += d["clipwise_output"]framewise_output += d["framewise_output"]clipwise_output = clipwise_output / len(output_dicts)framewise_output = framewise_output / len(output_dicts)output_dict = {'framewise_output': framewise_output, 'clipwise_output': clipwise_output}else: # this part is typically used, and most easy onex = self.reshape_wav2img(x)output_dict = self.forward_features(x)# x = self.head(x)return output_dict
该代码实现了HTS-AT(Hierarchical Token-Semantic Audio Transformer)模型的核心结构,基于Swin Transformer架构适配音频处理任务(声音分类与检测)。代码包含窗口注意力机制、Swin Transformer块、下采样模块、完整模型结构及音频特征预处理流程,以下是详细解析:
1. 窗口操作工具函数
窗口操作工具函数是Swin Transformer(及HTS-AT模型)中实现“局部窗口注意力”机制的核心工具,包括window_partition(窗口分割)和window_reverse(窗口合并)两个函数,用于将特征图分割为局部窗口以高效计算自注意力,再将窗口合并回原始特征图形状。以下是详细解析:
1. window_partition:特征图分割为局部窗口
功能
将输入的2D特征图按指定窗口大小(window_size)分割为多个不重叠的局部窗口,以便在每个窗口内独立计算自注意力(降低全局注意力的计算复杂度)。
输入与输出
- 输入:
x:特征图,形状为(B, H, W, C),其中B为批量大小,H/W为特征图的高/宽,C为通道数。window_size:窗口的空间尺寸(如8,表示窗口为8×8)。
- 输出:
- 分割后的窗口集合,形状为
(num_windows × B, window_size, window_size, C),其中num_windows = (H // window_size) × (W // window_size)(窗口总数)。
- 分割后的窗口集合,形状为
实现逻辑
通过维度重排和重塑,将特征图的空间维度(H, W)按 window_size 分割为多个子窗口:
-
维度拆分:将
H和W维度按window_size拆分为(H//window_size, window_size)和(W//window_size, window_size),即:
x = x.view(B, H//window_size, window_size, W//window_size, window_size, C)
此时形状为(B, num_h_windows, window_size, num_w_windows, window_size, C),其中num_h_windows = H//window_size,num_w_windows = W//window_size。 -
维度重排:将窗口索引(
num_h_windows, num_w_windows)移到批量维度附近,窗口内部的空间维度(window_size, window_size)保持不变:
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous()
此时形状为(B, num_h_windows, num_w_windows, window_size, window_size, C)。 -
展平窗口:将窗口索引与批量维度合并,得到最终的窗口集合:
windows = windows.view(-1, window_size, window_size, C)
此时num_windows × B对应B × num_h_windows × num_w_windows,即每个样本的所有窗口被展平并按批量顺序排列。
2. window_reverse:局部窗口合并为特征图
功能
将分割后的局部窗口重新合并为原始尺寸的特征图,是 window_partition 的逆操作,用于在窗口内注意力计算完成后恢复特征图的空间结构。
输入与输出
- 输入:
windows:分割后的窗口集合,形状为(num_windows × B, window_size, window_size, C)。window_size:窗口的空间尺寸(需与分割时一致)。H, W:原始特征图的高和宽(需与分割前一致)。
- 输出:
- 合并后的特征图,形状为
(B, H, W, C)。
- 合并后的特征图,形状为
实现逻辑
通过维度重排和重塑,将窗口集合恢复为原始特征图的空间维度:
-
恢复批量与窗口索引:先计算批量大小
B = num_windows × B // num_windows(通过窗口总数反推),再将窗口集合重塑为包含批量和窗口索引的形状:
x = windows.view(B, H//window_size, W//window_size, window_size, window_size, -1)
此时形状为(B, num_h_windows, num_w_windows, window_size, window_size, C),与window_partition步骤2的中间形状对应。 -
维度重排:将窗口内部的空间维度(
window_size, window_size)移到窗口索引之后,恢复特征图的空间顺序:
x = x.permute(0, 1, 3, 2, 4, 5).contiguous()
此时形状为(B, num_h_windows, window_size, num_w_windows, window_size, C)。 -
合并空间维度:将窗口索引与窗口内部空间维度合并,恢复原始的
H, W维度:
x = x.view(B, H, W, -1)
其中H = num_h_windows × window_size,W = num_w_windows × window_size,最终恢复为(B, H, W, C)。
核心作用与意义
-
降低计算复杂度:通过将特征图分割为窗口,自注意力计算被限制在每个窗口内(而非全局),复杂度从
O((H×W)^2)降至O(num_windows × (window_size^2)^2),当window_size固定时,复杂度与特征图大小呈线性关系(O(H×W)),适合高分辨率输入(如音频频谱图或图像)。 -
支持跨窗口交互:结合“移位窗口”(shifted window)机制,
window_partition可在相邻层分割出重叠窗口,使注意力能跨越原始窗口边界,平衡局部建模与全局交互。 -
适配音频/视觉特征:在HTS-AT中,音频梅尔频谱图被视为2D特征图,通过窗口分割可捕捉局部频谱-时间模式(如短时音频事件),是模型适配音频任务的关键操作。
示例说明
假设输入特征图为 (B=2, H=16, W=16, C=96),窗口大小 window_size=4:
window_partition会将其分割为(16/4)×(16/4)=16个窗口/样本,输出形状为(2×16, 4, 4, 96) = (32, 4, 4, 96)。- 经窗口注意力计算后,
window_reverse会将这32个窗口合并回(2, 16, 16, 96),恢复原始特征图形状。
综上,这两个函数是Swin Transformer实现“局部窗口注意力”的基础设施,既保证了计算效率,又通过与移位窗口结合实现了全局建模能力,是模型在图像和音频任务中高效工作的核心保障。
2. 窗口注意力机制(WindowAttention)
WindowAttention(窗口注意力机制)是Swin Transformer(及HTS-AT模型)的核心组件,用于在局部窗口内计算多头自注意力,并通过相对位置偏置增强位置敏感性。与全局自注意力相比,它将计算限制在局部窗口内,大幅降低了复杂度,同时通过移位窗口机制实现跨窗口交互。以下是详细解析:
1. 核心功能与设计动机
- 局部注意力计算:将特征图分割为固定大小的窗口(如8×8),仅在每个窗口内计算自注意力,避免全局注意力的高复杂度(全局注意力复杂度为
O(N²),窗口注意力为O((N/w²)·w⁴)=O(N·w²),w为窗口大小)。 - 相对位置偏置:引入可学习的相对位置偏置,建模窗口内不同位置的相对关系(而非绝对位置),更符合视觉/音频任务中“相对位置比绝对位置更重要”的特性。
- 支持移位窗口:兼容“移位窗口注意力(SW-MSA)”,通过掩码机制处理移位后窗口内的跨边界元素,实现窗口间的信息交互。
2. 类定义与关键参数
class WindowAttention(nn.Module):def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
- 核心参数:
dim:输入特征维度(如96、192)。window_size:窗口的空间尺寸(如(8,8),表示高和宽均为8)。num_heads:注意力头数(多头注意力的并行头数量)。qkv_bias:是否为Q、K、V的线性变换添加偏置。qk_scale:QK矩阵相乘的缩放因子(默认head_dim **-0.5)。attn_drop:注意力权重的dropout概率。proj_drop:输出投影后的dropout概率。
3. 核心组件初始化
(1)相对位置偏置表
# 相对位置偏置表:形状为 [(2Wh-1)×(2Ww-1), num_heads]
self.relative_position_bias_table = nn.Parameter(torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)
)
- 作用:存储窗口内所有可能的相对位置对应的偏置值(可学习),用于增强注意力对位置的敏感性。
- 尺寸计算:对于
Wh×Ww的窗口,两个位置的相对坐标范围为[-(Wh-1), Wh-1](高方向)和[-(Ww-1), Ww-1](宽方向),因此总共有(2Wh-1)×(2Ww-1)种相对位置组合。
(2)相对位置索引
通过网格坐标计算窗口内所有位置对的相对位置索引,用于索引偏置表:
# 1. 生成窗口内的坐标网格
coords_h = torch.arange(window_size[0]) # [0, 1, ..., Wh-1]
coords_w = torch.arange(window_size[1]) # [0, 1, ..., Ww-1]
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww(坐标网格,第一行是高坐标,第二行是宽坐标)
coords_flatten = torch.flatten(coords, 1) # 2, Wh×Ww(展平为坐标对)# 2. 计算所有位置对的相对坐标
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh×Ww, Wh×Ww(每个位置对的相对坐标差)
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh×Ww, Wh×Ww, 2(转换为[位置对, 坐标维度])# 3. 坐标偏移与索引计算(将负坐标转为非负索引)
relative_coords[:, :, 0] += window_size[0] - 1 # 高方向偏移:[-Wh+1, Wh-1] → [0, 2Wh-2]
relative_coords[:, :, 1] += window_size[1] - 1 # 宽方向偏移:[-Ww+1, Ww-1] → [0, 2Ww-2]
relative_coords[:, :, 0] *= 2 * window_size[1] - 1 # 高方向坐标编码为唯一索引
relative_position_index = relative_coords.sum(-1) # Wh×Ww, Wh×Ww(合并为单索引)
self.register_buffer("relative_position_index", relative_position_index) # 注册为非参数缓冲区
- 示例:对于2×2窗口,
relative_position_index是4×4矩阵,每个元素表示对应位置对的相对位置索引(范围0~(22-1)(2*2-1)-1=8)。
(3)QKV投影与输出投影
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias) # 生成Q、K、V的线性层(一次性输出3*dim)
self.proj = nn.Linear(dim, dim) # 注意力输出的线性投影层
self.attn_drop = nn.Dropout(attn_drop) # 注意力权重的dropout
self.proj_drop = nn.Dropout(proj_drop) # 输出投影后的dropout
self.softmax = nn.Softmax(dim=-1) # 注意力权重归一化
4. 前向传播过程(forward方法)
输入与输出
- 输入:
x:窗口化的特征,形状为(num_windows×B, N, C),其中num_windows×B是总窗口数(批量×每个样本的窗口数),N=window_size²是每个窗口的token数,C=dim是特征维度。mask:可选掩码(仅用于移位窗口),形状为(num_windows, N, N),值为0或-100(-100表示该位置注意力无效)。
- 输出:
- 注意力加权后的特征
x(形状同输入x)。 - 注意力权重
attn(可选,用于分析)。
- 注意力加权后的特征
步骤解析
1.** 生成Q、K、V **
B_, N, C = x.shape # B_ = num_windows×B,N = window_size²qkv = self.qkv(x).reshape(B_, N, 3, num_heads, C // num_heads).permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2] # q/k/v形状:(B_, num_heads, N, head_dim),head_dim = C//num_heads
- 通过线性层
qkv将输入x转换为3倍维度的向量,再拆分为Q(查询)、K(键)、V(值),并按注意力头拆分。
2.** 计算注意力分数 **
q = q * self.scale # 缩放:head_dim^-0.5,防止梯度消失attn = (q @ k.transpose(-2, -1)) # 矩阵乘法:(B_, num_heads, N, N),每个元素是Q_i与K_j的相似度
- 注意力分数本质是查询与键的相似度,缩放后更稳定。
3.** 加入相对位置偏置 **
# 从偏置表中索引相对位置偏置:(N, N, num_heads) → 转置为 (num_heads, N, N)relative_position_bias = self.relative_position_bias_table[relative_position_index.view(-1)].view(N, N, -1).permute(2, 0, 1).contiguous()attn = attn + relative_position_bias.unsqueeze(0) # 广播到(B_, num_heads, N, N)并相加
- 通过预计算的
relative_position_index索引偏置表,为每个位置对添加相对位置偏置,增强位置敏感性。
4.** 处理掩码(移位窗口场景)**
if mask is not None:nW = mask.shape[0] # 窗口数# 掩码广播:(B_//nW, nW, num_heads, N, N) → 与注意力分数相加attn = attn.view(B_ // nW, nW, num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)attn = attn.view(-1, num_heads, N, N) # 恢复形状attn = self.softmax(attn) # 归一化注意力权重(沿最后一维)
- 掩码用于移位窗口中,标记跨原始窗口边界的位置对(设置为-100),使这些位置的注意力权重趋近于0,避免无效交互。
5.** 注意力加权与输出投影 **
attn = self.attn_drop(attn) # 注意力权重dropoutx = (attn @ v).transpose(1, 2).reshape(B_, N, C) # 加权求和V:(B_, num_heads, N, head_dim) → 合并头:(B_, N, C)x = self.proj(x) # 线性投影:(B_, N, C)x = self.proj_drop(x) # 输出dropoutreturn x, attn
- 用注意力权重对V加权求和,合并多头特征,经线性投影后输出。
5. 关键特性与优势
-** 高效性 :将注意力计算限制在局部窗口,复杂度随输入大小线性增长(而非平方级),适合高分辨率特征(如音频梅尔频谱图)。
- 位置敏感性 :通过相对位置偏置捕捉窗口内的空间/时间关系,比绝对位置嵌入更灵活(如音频中“前后相邻帧”的关系比“帧的绝对位置”更重要)。
- 兼容性 **:支持移位窗口机制(通过掩码),使相邻层的窗口重叠,实现跨窗口信息交互,平衡局部建模与全局感知。
6. 在HTS-AT中的作用
在音频处理中,HTS-AT将梅尔频谱图(时间×频率)视为2D特征图,WindowAttention用于捕捉局部频谱-时间模式(如短时音频事件的频率变化):
- 窗口大小适配音频的时间-频率分辨率(如8×8窗口对应特定时长和频率范围的音频片段)。
- 相对位置偏置建模“频率相邻”和“时间相邻”的关系(如高频与低频的关联、前一帧与后一帧的关联)。
综上,WindowAttention是Swin Transformer高效处理视觉/音频特征的核心,通过局部注意力+相对位置偏置,在降低复杂度的同时保持了对局部特征和位置关系的捕捉能力。
3. Swin Transformer块(SwinTransformerBlock)
SwinTransformerBlock是Swin Transformer(及HTS-AT模型)的核心构建单元,其设计融合了窗口注意力机制、多层感知器(MLP)、残差连接和移位窗口策略,既保持了局部特征建模的高效性,又通过交替窗口实现了全局信息交互。以下是详细解析:
1. 核心功能与设计动机
Swin Transformer块的核心是**“注意力+MLP”的双分支结构**,但通过引入“窗口分割”和“移位窗口”机制,解决了传统Transformer全局注意力计算复杂度高的问题:
- 对输入特征图分割为局部窗口,在窗口内计算自注意力(W-MSA,Window Multi-Head Self-Attention),降低计算成本;
- 交替使用“普通窗口”和“移位窗口”(SW-MSA,Shifted Window MSA),使相邻块的窗口重叠,实现跨窗口信息交互,弥补局部注意力的视野局限;
- 结合残差连接和归一化,确保深层网络的稳定训练。
2. 类定义与关键参数
class SwinTransformerBlock(nn.Module):def __init__(self, dim, input_resolution, num_heads, window_size=7, shift_size=0,mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,act_layer=nn.GELU, norm_layer=nn.LayerNorm, norm_before_mlp='ln'):
- 核心参数解析:
dim:输入特征维度(如96、192);input_resolution:输入特征图的空间分辨率((H, W),如(32, 32));num_heads:注意力头数(多头注意力的并行头数量);window_size:窗口的空间尺寸(如8,表示8×8的窗口);shift_size:窗口移位步长(0表示普通窗口W-MSA,window_size//2表示移位窗口SW-MSA);mlp_ratio:MLP隐藏层维度与输入维度的比例(默认4,即隐藏层维度为4×dim);drop_path:随机深度(Stochastic Depth)概率(用于正则化,防止过拟合);norm_layer:归一化层类型(默认LayerNorm);norm_before_mlp:MLP前的归一化类型(ln为LayerNorm,bn为BatchNorm)。
3. 核心组件初始化
(1)基础配置与边界处理
if min(self.input_resolution) <= self.window_size:# 若输入分辨率小于窗口大小,无需分割窗口,直接使用全局注意力self.shift_size = 0self.window_size = min(self.input_resolution)
assert 0 <= self.shift_size < self.window_size, "移位步长必须在[0, window_size)范围内"
- 当输入特征图的高或宽小于窗口大小时,自动禁用窗口分割和移位,避免无效计算。
(2)注意力分支组件
self.norm1 = norm_layer(dim) # 注意力前的归一化层(pre-norm设计)
self.attn = WindowAttention( # 窗口注意力模块dim=dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop
)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity() # 随机深度层
- 采用“pre-norm”设计:注意力计算前先对输入进行归一化,稳定训练;
WindowAttention复用前文所述的窗口注意力机制,处理局部窗口内的特征交互。
(3)MLP分支组件
# MLP前的归一化层(支持LayerNorm或BatchNorm)
if self.norm_before_mlp == 'ln':self.norm2 = nn.LayerNorm(dim)
elif self.norm_before_mlp == 'bn':self.norm2 = lambda x: nn.BatchNorm1d(dim)(x.transpose(1, 2)).transpose(1, 2)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp( # 多层感知器(特征转换)in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop
)
- MLP用于对注意力输出进行非线性特征转换,由两层线性层+激活函数(GELU)+Dropout组成。
(4)移位窗口掩码(SW-MSA专属)
当shift_size > 0(即使用移位窗口)时,需生成掩码以区分窗口内的“真实相邻”和“移位导致的虚假相邻”元素:
if self.shift_size > 0:H, W = self.input_resolutionimg_mask = torch.zeros((1, H, W, 1)) # 1, H, W, 1(掩码模板)# 定义三个水平/垂直切片,用于标记不同区域h_slices = (slice(0, -self.window_size),slice(-self.window_size, -self.shift_size),slice(-self.shift_size, None))w_slices = (slice(0, -self.window_size),slice(-self.window_size, -self.shift_size),slice(-self.shift_size, None))cnt = 0for h in h_slices:for w in w_slices:img_mask[:, h, w, :] = cnt # 为不同区域分配不同标记cnt += 1# 将掩码分割为窗口,计算窗口内的注意力掩码mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1mask_windows = mask_windows.view(-1, self.window_size * self.window_size) # nW, N(N=window_size²)attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2) # nW, N, N(标记不同区域的位置对)attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
else:attn_mask = None # 普通窗口无需掩码
self.register_buffer("attn_mask", attn_mask) # 注册为非参数缓冲区
- 掩码作用:移位窗口中,部分元素来自原始特征图的不同区域(因移位产生重叠),掩码将这些跨区域的位置对标记为
-100,使注意力权重趋近于0,避免无效交互。
4. 前向传播过程(forward方法)
Swin Transformer块的前向传播分为注意力分支和MLP分支,均采用“归一化→处理→残差连接”的流程,具体步骤如下:
(1)输入准备与残差保存
H, W = self.input_resolution # 特征图空间分辨率
B, L, C = x.shape # 输入x形状:(B, H×W, C),L=H×W为token总数
shortcut = x # 保存残差连接的输入
(2)注意力分支:窗口注意力计算
-
归一化与空间重塑:
x = self.norm1(x) # pre-norm:(B, L, C) → (B, L, C) x = x.view(B, H, W, C) # 重塑为空间维度:(B, H, W, C) -
** cyclic shift(移位窗口)**:
if self.shift_size > 0:# 循环移位:将特征图向左/上移动shift_size,使窗口重叠shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2)) else:shifted_x = x # 普通窗口无需移位- 移位目的:使当前块的窗口与上一块的窗口重叠,实现跨窗口信息交互。
-
窗口分割与注意力计算:
# 分割为窗口:(B, H, W, C) → (nW×B, window_size, window_size, C) → (nW×B, N, C)(N=window_size²) x_windows = window_partition(shifted_x, self.window_size) x_windows = x_windows.view(-1, self.window_size * self.window_size, C)# 窗口内注意力计算(带掩码,若为SW-MSA) attn_windows, attn = self.attn(x_windows, mask=self.attn_mask) # (nW×B, N, C) -
窗口合并与反移位:
# 合并窗口:(nW×B, N, C) → (nW×B, window_size, window_size, C) → (B, H, W, C) attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C) shifted_x = window_reverse(attn_windows, self.window_size, H, W)# 反循环移位:恢复原始特征图位置 if self.shift_size > 0:x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2)) else:x = shifted_x x = x.view(B, H * W, C) # 重塑为序列:(B, L, C) -
残差连接与随机深度:
x = shortcut + self.drop_path(x) # 残差连接:注意力输出 + 原始输入(经随机深度)
(3)MLP分支:特征非线性转换
x = x + self.drop_path(self.mlp(self.norm2(x))) # 残差连接:MLP输出 + 注意力分支输出
- 流程:输入先经
norm2归一化,再通过MLP进行非线性转换,最后经随机深度后与上一步输出残差相加。
(4)输出
return x, attn # 输出处理后的特征和注意力权重(用于分析)
5. 关键特性与优势
- 交替窗口机制:通过
shift_size交替使用W-MSA(shift_size=0)和SW-MSA(shift_size=window_size//2),既保持局部注意力的高效性(复杂度O(N·w²)),又实现跨窗口信息交互,兼顾效率与全局视野; - 随机深度正则化:
drop_path在训练时随机丢弃部分块的输出,减少过拟合,增强模型泛化能力; - pre-norm设计:归一化在注意力和MLP之前应用,解决深层网络训练不稳定问题;
- 灵活性:支持不同窗口大小、注意力头数和MLP比例,可根据任务需求调整(如HTS-AT中适配音频频谱图的分辨率)。
6. 在HTS-AT中的作用
在音频处理中,SwinTransformerBlock用于捕捉梅尔频谱图(时间×频率)的局部与全局特征:
- 窗口大小适配音频的时间-频率尺度(如
8×8窗口对应特定时长和频率范围的音频片段); - 交替窗口机制使模型既能学习局部频谱模式(如特定频率成分的短时变化),又能捕捉全局时序关联(如跨长时段的音频事件);
- 残差连接确保深层网络中音频特征的有效传递,避免梯度消失。
总结
SwinTransformerBlock通过“窗口注意力+MLP+残差连接”的核心结构,结合移位窗口策略,实现了高效的局部与全局特征建模。它是Swin Transformer和HTS-AT模型的基础,既解决了传统Transformer的计算复杂度问题,又保持了强大的特征学习能力,使其能适配高分辨率的图像或音频特征处理任务。
4. 补丁合并(PatchMerging)
PatchMerging(补丁合并)是Swin Transformer(及HTS-AT模型)中用于特征图下采样的核心模块,其作用是在每个Transformer阶段末尾降低特征图的空间分辨率、同时增加通道维度,类似于卷积神经网络中的下采样层(如 stride=2 的卷积)。与传统卷积下采样不同,它通过直接聚合相邻补丁的特征实现下采样,更贴合Transformer的“补丁(token)级”操作逻辑。以下是详细解析:
1. 核心功能与设计动机
- 下采样与特征聚合:将输入特征图的空间分辨率(高和宽)减半,同时将通道维度翻倍,实现“压缩空间、扩展语义”的特征转换。
- 局部信息融合:通过合并2×2相邻的补丁(token),聚合局部空间信息,增强特征的上下文关联性。
- 适配多阶段架构:作为Swin Transformer各阶段之间的过渡层,配合Transformer块逐步提升特征的抽象层次(从细粒度到粗粒度)。
2. 类定义与关键参数
class PatchMerging(nn.Module):def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
- 核心参数解析:
input_resolution:输入特征图的空间分辨率,格式为(H, W)(如(32, 32),表示高32、宽32)。dim:输入特征的通道维度(如96)。norm_layer:归一化层类型(默认nn.LayerNorm,用于合并后的特征归一化)。
3. 核心组件初始化
self.input_resolution = input_resolution # 输入分辨率 (H, W)
self.dim = dim # 输入通道维度
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False) # 降维线性层:4*dim → 2*dim(通道翻倍)
self.norm = norm_layer(4 * dim) # 归一化层:对合并后的4*dim特征进行归一化
- 关键组件:
reduction:线性层,将合并后的4×dim通道特征降维为2×dim,实现通道数翻倍(从dim到2×dim)。norm:归一化层,对合并后的高维特征(4×dim)进行归一化,稳定训练。
4. 前向传播过程(forward方法)
PatchMerging的核心逻辑是“分割相邻补丁→拼接特征→归一化→降维”,具体步骤如下:
(1)输入验证与形状转换
输入x是经过补丁嵌入和Transformer块处理后的特征,形状为(B, L, C),其中:
B:批量大小;L:特征图展平后的token总数(L = H × W,H和W为输入分辨率);C:通道维度(C = dim)。
首先验证输入的有效性,并将序列形状转换为空间形状:
H, W = self.input_resolution # 解析输入分辨率
B, L, C = x.shape # 输入特征形状
assert L == H * W, "输入特征的token总数必须等于H×W"
assert H % 2 == 0 and W % 2 == 0, "输入分辨率H和W必须为偶数(确保能被2整除)"x = x.view(B, H, W, C) # 将序列重塑为空间特征图:(B, H, W, C)
(2)分割2×2相邻补丁
将特征图按2×2网格分割为4个不重叠的子区域(相邻补丁),每个子区域的分辨率为(H/2, W/2):
x0 = x[:, 0::2, 0::2, :] # 左上子区域:步长为2取偶数行和列 → (B, H/2, W/2, C)
x1 = x[:, 1::2, 0::2, :] # 左下子区域:取奇数行、偶数列 → (B, H/2, W/2, C)
x2 = x[:, 0::2, 1::2, :] # 右上子区域:取偶数行、奇数列 → (B, H/2, W/2, C)
x3 = x[:, 1::2, 1::2, :] # 右下子区域:取奇数行和列 → (B, H/2, W/2, C)
- 示例:若输入
H=8, W=8,则每个子区域的分辨率为4×4,共4个子区域。
(3)拼接与降维
将4个子区域在通道维度拼接,再通过归一化和线性层降维,实现下采样:
# 拼接4个子区域的特征:通道维度变为4×C → (B, H/2, W/2, 4*C)
x = torch.cat([x0, x1, x2, x3], -1)
# 重塑为序列:(B, (H/2)*(W/2), 4*C)(新的token总数为原有的1/4)
x = x.view(B, -1, 4 * C) x = self.norm(x) # 归一化:(B, (H/2)*(W/2), 4*C) → 稳定训练
x = self.reduction(x) # 线性降维:4*C → 2*C → (B, (H/2)*(W/2), 2*C)
(4)输出
最终输出形状为(B, (H/2)×(W/2), 2×C),实现:
- 空间分辨率:
H → H/2,W → W/2(总token数变为原来的1/4); - 通道维度:
C → 2×C(通道数翻倍,承载更丰富的语义信息)。
5. 关键特性与优势
- 高效下采样:通过简单的切片和拼接操作实现下采样,无需卷积核参数,计算成本低。
- 局部信息聚合:合并2×2相邻补丁的特征,强制模型学习局部空间关联性(如音频频谱图中相邻时间-频率点的关联)。
- 通道扩展:通道维度翻倍(
dim → 2×dim),为下一阶段的Transformer块提供更丰富的特征维度,支持更复杂的注意力计算。 - 与Transformer兼容:操作对象是“补丁序列”,保持了Transformer对token级特征的处理逻辑,避免了卷积下采样与Transformer架构的适配问题。
6. 在HTS-AT中的作用
在音频处理中,HTS-AT将梅尔频谱图(时间×频率)视为2D特征图,PatchMerging的作用体现在:
- 分辨率压缩:逐步降低时间和频率维度的分辨率(如从
128×128→64×64→32×32),减少后续Transformer块的计算量。 - 频谱-时间信息聚合:合并相邻的时间-频率点(补丁),捕捉局部频谱模式(如短时频率变化)和时序关联(如相邻帧的依赖关系)。
- 特征抽象:通过通道维度扩展,使高层特征能编码更抽象的音频语义(如乐器类型、语音情感等),而非原始频谱细节。
示例说明
假设输入特征为音频梅尔频谱图经补丁嵌入后的特征:
- 输入形状:
(B=2, L=32×32=1024, C=96)(H=32, W=32,dim=96); - 经
PatchMerging处理后:- 分割为4个
16×16的子区域,拼接后通道变为4×96=384; - 归一化后通过线性层降维为
2×96=192; - 输出形状:
(2, 16×16=256, 192),实现分辨率减半、通道翻倍。
- 分割为4个
总结
PatchMerging是Swin Transformer实现多阶段特征学习的关键组件,通过“分割-拼接-降维”的简单逻辑,高效完成下采样并聚合局部信息。在HTS-AT中,它适配音频频谱图的结构,逐步压缩时间-频率分辨率并扩展特征维度,为高层Transformer块提供更抽象、更高效的输入特征,平衡了计算复杂度与特征表达能力。
5. 基础层(BasicLayer)
BasicLayer是Swin Transformer(及HTS-AT模型)中构成“阶段”的核心组件,每个BasicLayer由多个SwinTransformerBlock堆叠而成,并可选配PatchMerging下采样层,负责在特定空间分辨率下完成多轮特征细化与抽象。它是连接模型输入与输出的中间层次,通过逐步提升特征的语义层次,实现从低级别细节到高级别抽象的特征转换。以下是详细解析:
1. 核心功能与设计动机
- 多轮特征细化:通过堆叠多个
SwinTransformerBlock(窗口注意力+MLP结构),对输入特征进行多轮局部与全局信息交互,逐步捕捉更复杂的模式(如音频中的频谱-时间关联、图像中的局部结构)。 - 分辨率过渡:每个
BasicLayer处理特定分辨率的特征图,阶段末尾通过PatchMerging下采样(最后一个阶段除外),将特征图分辨率减半、通道维度翻倍,为下一个阶段提供更高抽象层次的输入。 - 效率与灵活性:支持检查点(checkpoint)机制减少内存占用,适配深层网络训练;通过参数配置(如块数量、注意力头数)可灵活调整模型能力与计算成本。
2. 类定义与关键参数
class BasicLayer(nn.Module):def __init__(self, dim, input_resolution, depth, num_heads, window_size,mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False,norm_before_mlp='ln'):
- 核心参数解析:
dim:当前阶段输入特征的通道维度(如96、192)。input_resolution:输入特征图的空间分辨率((H, W),如(64, 64))。depth:当前阶段堆叠的SwinTransformerBlock数量(如2、6)。num_heads:每个SwinTransformerBlock中注意力头的数量(如4、8)。window_size:窗口注意力的窗口尺寸(如8)。drop_path:随机深度(Stochastic Depth)概率(可为列表,为每个块分配不同概率)。downsample:下采样层类型(默认PatchMerging,最后一个阶段为None)。use_checkpoint:是否使用检查点机制(节省内存,适用于深层模型)。- 其他参数(如
mlp_ratio、qkv_bias)与SwinTransformerBlock一致,用于配置块内细节。
3. 核心组件初始化
(1)堆叠SwinTransformerBlock
self.blocks = nn.ModuleList([SwinTransformerBlock(dim=dim, input_resolution=input_resolution,num_heads=num_heads, window_size=window_size,# 交替使用W-MSA(i为偶数,shift_size=0)和SW-MSA(i为奇数,shift_size=window_size//2)shift_size=0 if (i % 2 == 0) else window_size // 2,mlp_ratio=mlp_ratio,qkv_bias=qkv_bias, qk_scale=qk_scale,drop=drop, attn_drop=attn_drop,# 若drop_path为列表,则为每个块分配不同概率;否则所有块共享同一概率drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,norm_layer=norm_layer, norm_before_mlp=norm_before_mlp)for i in range(depth)
])
- 交替窗口机制:通过
shift_size控制,偶数索引的块使用普通窗口注意力(W-MSA),奇数索引的块使用移位窗口注意力(SW-MSA),实现局部与跨窗口信息的交替交互。 - 随机深度配置:若
drop_path为列表(长度等于depth),则每个块使用不同的随机深度概率(通常前浅后深,逐步增加丢弃概率);否则所有块共享同一概率。
(2)下采样层(PatchMerging)
if downsample is not None:self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer)
else:self.downsample = None # 最后一个阶段无下采样
downsample通常为PatchMerging类,用于当前阶段末尾将特征图分辨率减半、通道维度翻倍(如从dim到2×dim),为下一阶段提供输入。- 最后一个
BasicLayer的downsample为None,直接输出特征用于后续分类/检测头。
(3)其他配置
self.dim = dim # 当前阶段特征维度
self.input_resolution = input_resolution # 输入分辨率
self.depth = depth # 块数量
self.use_checkpoint = use_checkpoint # 是否使用检查点机制
4. 前向传播过程(forward方法)
BasicLayer的前向传播是“多块特征处理→可选下采样”的流程,具体步骤如下:
(1)输入特征处理
输入x是上一阶段(或补丁嵌入层)输出的特征,形状为(B, L, C),其中:
B:批量大小;L:展平后的token总数(L = H × W,H和W为input_resolution);C:通道维度(C = dim)。
(2)堆叠SwinTransformerBlock处理
attns = [] # 存储注意力权重(仅推理时)
for blk in self.blocks:if self.use_checkpoint:# 检查点机制:节省内存,仅在反向传播时计算块的输出x = checkpoint.checkpoint(blk, x)else:# 正常处理:通过块获取输出特征和注意力权重x, attn = blk(x)if not self.training: # 推理时保存注意力权重attns.append(attn.unsqueeze(0)) # 增加维度便于后续拼接
- 检查点机制:当
use_checkpoint=True时,checkpoint.checkpoint会暂时不存储中间激活值,而是在反向传播时重新计算,显著减少内存占用(尤其适合深层模型)。 - 注意力权重存储:仅在推理模式(
not self.training)下保存每个块的注意力权重,用于后续分析(如可视化注意力热力图)。
(3)注意力权重聚合(仅推理时)
if not self.training:# 拼接所有块的注意力权重并取平均attn = torch.cat(attns, dim=0) # (depth, B_, num_heads, N, N)attn = torch.mean(attn, dim=0) # (B_, num_heads, N, N),平均所有块的注意力
- 推理时将多个块的注意力权重聚合(平均),用于分析模型对输入特征的关注区域(如音频中哪些时间-频率点对分类更重要)。
(4)下采样(可选)
if self.downsample is not None:x = self.downsample(x) # 通过PatchMerging下采样:(B, L, C) → (B, L/4, 2C)
- 若存在下采样层,当前阶段输出的特征会被下采样(分辨率减半、通道翻倍),作为下一
BasicLayer的输入。
(5)输出
return x, attn # 输出处理后的特征和聚合的注意力权重(推理时)
- 输出特征形状:若经过下采样,则为
(B, (H/2)×(W/2), 2×dim);否则为(B, H×W, dim)。
5. 关键特性与优势
- 多阶段特征抽象:每个
BasicLayer处理特定分辨率的特征,通过多个SwinTransformerBlock的堆叠,逐步将低级别特征(如音频的原始频谱细节)转换为高级别语义(如“鸟鸣”“汽车鸣笛”)。 - 交替窗口的累积效应:通过W-MSA与SW-MSA的交替使用,多个块的累积作用可实现比单个块更大的感受野,逐步扩大模型对输入特征的感知范围。
- 内存高效训练:检查点机制允许在有限内存下训练更深的模型,尤其适合高分辨率输入(如HTS-AT中处理长音频的梅尔频谱图)。
- 模块化设计:每个
BasicLayer是独立模块,通过调整depth、num_heads等参数可灵活控制模型容量(如浅层少块少头,深层多块多头)。
6. 在HTS-AT中的作用
在音频处理中,HTS-AT通常包含4个BasicLayer(对应Swin-T的配置),其作用体现为:
- 多尺度频谱-时间建模:每个阶段处理不同分辨率的梅尔频谱图(如从
128×128→64×64→32×32→16×16),逐步捕捉从细粒度(短时高频变化)到粗粒度(长时全局模式)的音频特征。 - 语义层次提升:前两个
BasicLayer侧重学习局部频谱-时间模式(如音符、短时噪声),后两个侧重学习全局语义(如音乐类型、语音情感)。 - 特征维度扩展:通过
PatchMerging,通道维度从96→192→384→768逐步扩展,为高层分类头提供更丰富的特征表达。
示例说明
以HTS-AT的一个BasicLayer为例(假设为第二阶段):
- 输入:
(B=2, L=32×32=1024, C=192)(分辨率32×32,通道192); - 包含
depth=2个SwinTransformerBlock:- 第1块(i=0):
shift_size=0(W-MSA),处理局部窗口特征; - 第2块(i=1):
shift_size=4(SW-MSA,window_size=8),处理跨窗口特征;
- 第1块(i=0):
- 下采样:通过
PatchMerging输出(2, 16×16=256, 384)(分辨率16×16,通道384),传递到第三阶段。
总结
BasicLayer是Swin Transformer和HTS-AT的“阶段级”组件,通过堆叠多个SwinTransformerBlock实现特征的多轮细化,并通过PatchMerging实现分辨率与通道的过渡。它是模型从低级别特征到高级别语义的核心转换器,通过模块化设计和灵活配置,平衡了特征表达能力与计算效率,使其能适配图像和音频等多种高分辨率输入任务。
6. HTS-AT主模型(HTSAT_Swin_Transformer)
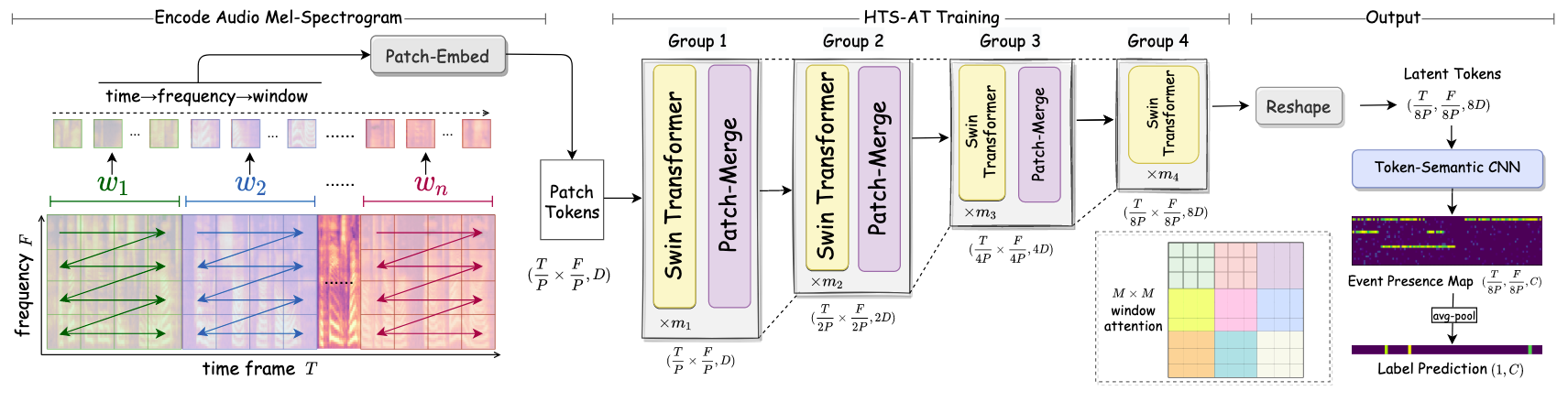
HTSAT_Swin_Transformer是基于Swin Transformer架构适配音频任务的层次化令牌-语义音频Transformer,专为声音分类(片段级)和声音检测(帧级)设计。它将音频波形转换为梅尔频谱图(视为2D特征图),通过Swin Transformer的层次化注意力机制捕捉频谱-时间特征,并结合时间-频谱类激活映射(TSCAM)实现细粒度和粗粒度的音频理解。以下是详细解析:
1. 核心功能与设计动机
- 音频到视觉的适配:将音频波形转换为梅尔频谱图(时间×频率的2D特征),复用Swin Transformer的局部窗口注意力机制捕捉频谱-时间模式(如短时音频事件的频率变化、长时时序依赖)。
- 层次化特征提取:通过多阶段
BasicLayer逐步降低特征图分辨率、提升通道维度,从细粒度(高频谱-时间细节)到粗粒度(抽象语义)捕捉音频特征。 - 双输出任务支持:同时输出片段级分类结果(整个音频的类别)和帧级检测结果(每个时间点的类别),满足声音分类与事件检测的双重需求。
- 长度鲁棒性:通过裁剪、重复、滑动窗口等策略处理不同长度的音频输入,确保对长音频和短音频均有稳定表现。
2. 类定义与关键参数
class HTSAT_Swin_Transformer(nn.Module):def __init__(self, spec_size=256, patch_size=4, patch_stride=(4,4), in_chans=1, num_classes=527,embed_dim=96, depths=[2, 2, 6, 2], num_heads=[4, 8, 16, 32],window_size=8, mlp_ratio=4., qkv_bias=True, qk_scale=None,drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,norm_layer=nn.LayerNorm, ape=False, patch_norm=True,use_checkpoint=False, norm_before_mlp='ln', config=None, **kwargs):
-** 核心参数解析 :
- 音频特征相关 :spec_size(梅尔频谱图目标尺寸)、patch_stride(补丁分割的步长,控制时间和频率维度的分辨率)、config(包含音频参数如采样率、梅尔 bins 等)。
- Transformer 结构 :depths(每个阶段的SwinTransformerBlock数量)、num_heads(每个阶段的注意力头数)、window_size(窗口注意力的窗口尺寸)。
- 正则化 :drop_rate(dropout 概率)、drop_path_rate(随机深度概率)。
- 任务相关 :num_classes(分类类别数)、in_chans(输入通道,音频为1通道梅尔频谱)。
- 其他 **:ape(是否使用绝对位置嵌入)、use_checkpoint(是否使用检查点机制节省内存)。
3. 核心组件初始化
(1)音频特征预处理模块
将波形转换为梅尔频谱图,并进行数据增强:
# 梅尔频谱提取器
self.spectrogram_extractor = Spectrogram(n_fft=config.window_size, hop_length=config.hop_size, ...)
self.logmel_extractor = LogmelFilterBank(sr=config.sample_rate, n_mels=config.mel_bins, ...)
# 频谱增强(时间/频率掩蔽)
self.spec_augmenter = SpecAugmentation(time_drop_width=64, time_stripes_num=2, ...)
# 批归一化
self.bn0 = nn.BatchNorm2d(config.mel_bins)
-** 流程 **:波形 → STFT 频谱 → 对数梅尔频谱 → 批归一化 → 数据增强(训练时)。
(2)补丁嵌入(PatchEmbed)
将梅尔频谱图(2D)分割为补丁并映射到高维嵌入:
self.patch_embed = PatchEmbed(img_size=spec_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim, norm_layer=norm_layer, patch_stride=patch_stride
)
-** 功能 **:将spec_size×spec_size的梅尔频谱图按patch_size×patch_size(步长patch_stride)分割为补丁,通过卷积映射到embed_dim维度,输出形状为(B, N, embed_dim)(N为补丁数)。
(3)位置嵌入与随机深度
# 绝对位置嵌入(可选)
if self.ape:self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))trunc_normal_(self.absolute_pos_embed, std=.02)
self.pos_drop = nn.Dropout(p=drop_rate) # 位置嵌入后的dropout# 随机深度概率(线性衰减)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
- 随机深度概率随网络加深递增,增强模型泛化能力。
(4)主干网络(多阶段BasicLayer)
由多个BasicLayer堆叠而成,逐步下采样并提升特征维度:
self.layers = nn.ModuleList()
for i_layer in range(num_layers):layer = BasicLayer(dim=int(embed_dim * 2**i_layer), # 通道维度:embed_dim → 2×embed_dim → ... → 8×embed_diminput_resolution=(patches_resolution[0] // (2**i_layer), patches_resolution[1] // (2**i_layer)), # 分辨率逐步减半depth=depths[i_layer],num_heads=num_heads[i_layer],window_size=window_size,drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer+1])], # 每个阶段的随机深度概率downsample=PatchMerging if (i_layer < num_layers - 1) else None, # 最后一阶段无下采样...)self.layers.append(layer)
- 示例:4个阶段的配置(如Swin-T):
- 阶段1:
dim=96,resolution=(64,64),depth=2,num_heads=4; - 阶段2:
dim=192,resolution=(32,32),depth=2,num_heads=8; - 阶段3:
dim=384,resolution=(16,16),depth=6,num_heads=16; - 阶段4:
dim=768,resolution=(8,8),depth=2,num_heads=32。
- 阶段1:
(5)输出头(分类与检测)
支持两种输出模式,核心是TSCAM(时间-频谱类激活映射):
if config.enable_tscam:# TSCAM用于帧级检测:通过卷积生成类相关激活图SF = spec_size // (2**(num_layers-1)) // patch_stride[0] // freq_ratioself.tscam_conv = nn.Conv2d(in_channels=num_features, # 最后阶段的通道维度out_channels=num_classes, # 类别数kernel_size=(SF, 3), # 卷积核:频率维度覆盖整个特征,时间维度局部感知padding=(0,1))self.head = nn.Linear(num_classes, num_classes) # 片段级输出头
else:self.head = nn.Linear(num_features, num_classes) # 直接映射(无帧级输出)
- TSCAM作用:将高层特征映射为与类别相关的激活图,通过插值恢复到原始时间长度,得到帧级检测结果;通过池化聚合为片段级分类结果。
4. 前向传播过程(forward方法)
整体流程:** 音频预处理 → 补丁嵌入 → Transformer特征提取 → 输出头计算 → 适配不同长度输入 **。
(1)音频预处理
# 波形 → 梅尔频谱
x = self.spectrogram_extractor(x) # (B, 1, T, freq_bins)
x = self.logmel_extractor(x) # (B, 1, T, mel_bins)# 批归一化与数据增强
x = x.transpose(1, 3) # 适配BN维度:(B, mel_bins, T, 1)
x = self.bn0(x)
x = x.transpose(1, 3) # 恢复:(B, 1, T, mel_bins)
if self.training:x = self.spec_augmenter(x) # 训练时增强# Mixup(可选)
if self.training and mixup_lambda is not None:x = do_mixup(x, mixup_lambda)
(2)输入长度适配
针对不同长度的音频,通过裁剪、重复或滑动窗口处理:
if infer_mode:# 推理时:短音频重复填充至目标长度frame_num = x.shape[2]target_T = int(spec_size * freq_ratio)repeat_ratio = math.floor(target_T / frame_num)x = x.repeat(repeats=(1,1,repeat_ratio,1))x = self.reshape_wav2img(x) # 重塑为适配Transformer的尺寸
elif config.enable_repeat_mode:# 重复模式:训练时随机裁剪,推理时多位置平均...
else:# 常规模式:长音频裁剪,短音频插值if x.shape[2] > freq_ratio * spec_size:x = self.crop_wav(x, crop_size=freq_ratio * spec_size) # 裁剪x = self.reshape_wav2img(x) # 重塑为(spec_size×spec_size)
reshape_wav2img:将梅尔频谱图重塑为spec_size×spec_size的2D特征图,适配Swin Transformer的输入要求。
(3)Transformer特征提取
# 补丁嵌入与位置嵌入
x = self.patch_embed(x) # (B, N, embed_dim)
if self.ape:x = x + self.absolute_pos_embed # 加绝对位置嵌入
x = self.pos_drop(x)# 多阶段特征处理
for layer in self.layers:x, attn = layer(x) # 每个阶段输出特征和注意力权重
(4)输出头计算
if config.enable_tscam:# 帧级与片段级输出x = self.norm(x) # 归一化B, N, C = x.shape# 重塑为2D特征图:(B, C, F, T)(F为频率维度,T为时间维度)x = x.permute(0,2,1).contiguous().reshape(B, C, SF, ST)# 频率维度分组聚合(适配梅尔频谱的频率分辨率)x = x.reshape(B, C, F//c_freq_bin, c_freq_bin, T)x = x.permute(0,1,3,2,4).contiguous().reshape(B, C, c_freq_bin, -1)# TSCAM卷积生成类激活图x = self.tscam_conv(x) # (B, num_classes, c_freq_bin, T)x = torch.flatten(x, 2) # (B, num_classes, T)# 帧级输出:插值到原始时间长度framewise_output = interpolate(torch.sigmoid(x).permute(0,2,1), ...)# 片段级输出:平均池化clipwise_output = self.avgpool(x) # (B, num_classes, 1)clipwise_output = torch.flatten(clipwise_output, 1) # (B, num_classes)clipwise_output = torch.sigmoid(clipwise_output) if config.loss_type != "clip_ce" else clipwise_output
else:# 仅片段级输出(无TSCAM)...
(5)输出
return {'framewise_output': framewise_output, # 帧级检测结果 (B, T, num_classes)'clipwise_output': clipwise_output # 片段级分类结果 (B, num_classes)
}
5. 核心特性与优势
- 层次化音频建模:通过多阶段
BasicLayer逐步捕捉从细粒度(如50ms内的频率变化)到粗粒度(如2s内的全局事件)的音频特征,适配不同时间尺度的音频事件。 - TSCAM细粒度定位:时间-频谱类激活映射将类别与频谱-时间位置关联,支持帧级事件检测(如定位“狗叫”发生的具体时间)。
- 长度自适应机制:通过裁剪、重复、滑动窗口平均等策略,处理从短音频(如1s)到长音频(如10s)的输入,解决音频长度不一的问题。
- 高效注意力计算:基于Swin Transformer的窗口注意力机制,将计算复杂度从
O(N²)降至O(N·w²)(w为窗口大小),支持高分辨率梅尔频谱图的处理。
6. 在音频任务中的适配
HTS-AT针对音频特性的关键优化:
- 梅尔频谱作为输入:相比原始波形,梅尔频谱更符合人耳感知,且可视为2D特征图,直接复用视觉Transformer的架构。
- 频率-时间双维度建模:窗口注意力同时捕捉频率维度(如不同频段的关联)和时间维度(如前后帧的依赖),适配音频的时空二重性。
- 多尺度输出:帧级输出支持事件检测(如“在第3秒出现汽车鸣笛”),片段级输出支持分类(如“这段音频是狗叫声”),兼顾两种核心音频任务。
总结
HTSAT_Swin_Transformer通过将音频梅尔频谱图适配为视觉Transformer的输入格式,结合Swin Transformer的层次化窗口注意力和TSCAM的细粒度映射,实现了高效的音频分类与检测。其核心优势在于层次化特征提取、双输出任务支持和长度鲁棒性,使其在多种音频场景(如环境声音识别、语音事件检测)中表现优异。
总结
HTS-AT模型通过以下核心设计适配音频任务:
1.** 音频到视觉的适配 :将梅尔频谱图视为2D“图像”,复用Swin Transformer的局部窗口注意力机制捕捉频谱-时间特征。
2. 层次化特征提取 :通过多阶段下采样,逐步捕捉从细粒度(高频谱-时间分辨率)到粗粒度(低分辨率)的音频语义。
3. 帧级与片段级联合建模 :结合TSCAM生成帧级激活图,同时输出片段级分类结果,满足检测与分类需求。
4. 长度鲁棒性 **:通过裁剪、滑动窗口、平均等策略处理可变长度音频,确保在长音频上的稳定性。
该模型融合了Transformer的全局建模能力与Swin的局部效率,在音频分类和检测任务中表现优异。