基于TCN-BiLSTM-SelfAttention神经网络的多输入单输出回归预测【MATLAB】
在当今数据驱动的时代,精准的预测能力对于科学研究、工业生产乃至日常决策都具有重要意义。特别是在处理时间序列数据时,如何从复杂的历史信息中提取关键特征,并对未来趋势做出可靠预测,一直是研究的热点。本文将介绍一种融合了多种先进神经网络技术的预测模型——基于TCN-BiLSTM-Attention的多输入单输出回归预测方法,并展示如何在MATLAB环境中实现。
为什么选择TCN-BiLSTM-Attention?
传统的预测模型在处理具有长期依赖性、非线性特征的时间序列数据时,往往显得力不从心。而TCN(Temporal Convolutional Network,时间卷积网络)、BiLSTM(双向长短期记忆网络)与Attention(注意力机制)的结合,为解决这一难题提供了强有力的工具。
-
TCN:高效捕捉局部与长期依赖
TCN利用空洞卷积技术,能够在不增加网络深度的情况下,显著扩大感受野。这意味着模型可以高效地捕捉到输入序列中的局部模式以及跨越较长时间的依赖关系,为后续处理提供高质量的特征表示。 -
BiLSTM:双向理解时间动态
BiLSTM能够同时从前向和后向两个方向处理序列数据。这种双向结构使得模型不仅能基于过去的信息预测未来,还能利用未来的上下文信息来更好地理解当前时刻的状态,从而更全面地把握时间序列的动态变化。 -
Attention:聚焦关键信息
Attention机制赋予模型“选择性关注”的能力。在预测过程中,它能够自动识别并放大对当前预测结果影响最大的历史时刻或特征,抑制无关信息的干扰,从而显著提升预测的准确性和鲁棒性。
将这三者有机结合,TCN负责初步的特征提取,BiLSTM进一步挖掘深层次的时间依赖,Attention则优化信息的加权融合,最终形成一个强大且灵活的预测框架。
模型架构与工作流程
整个模型采用多输入单输出的设计,适用于需要综合多个相关变量来预测单一目标值的场景。例如,预测某地的气温可能需要考虑历史气温、湿度、风速等多个输入变量。
-
数据预处理:
首先,对原始多变量时间序列数据进行清洗、归一化处理,并构造合适的输入-输出样本对。多输入数据被组织成三维张量,以便送入网络。 -
TCN特征提取层:
预处理后的数据首先进入TCN模块。通过一系列的卷积操作,模型提取出序列中的关键时空特征,并输出一个浓缩了重要信息的特征序列。 -
BiLSTM时序建模层:
TCN输出的特征序列被送入BiLSTM层。该层通过其独特的门控机制,学习序列中复杂的长期依赖关系,生成包含双向上下文信息的隐藏状态。 -
Attention权重分配层:
Attention机制作用于BiLSTM的隐藏状态序列,计算每个时间步的重要性权重。这些权重被用于对隐藏状态进行加权求和,生成一个富含关键信息的上下文向量。 -
输出预测层:
最终,上下文向量被送入全连接层,映射到单一的输出值,完成回归预测任务。
MATLAB实现要点
在MATLAB中构建该模型,可以利用其强大的深度学习工具箱。主要步骤包括:
- 使用
sequenceInputLayer定义多变量输入。 - 通过
convolution1dLayer(配合适当参数模拟空洞卷积)和batchNormalizationLayer、reluLayer等构建TCN块。 - 利用
bilstmLayer创建双向LSTM层。 - SelfAttention层(可通过
selfAttentionLayer实现),计算注意力权重并进行加权。 - 最后连接
fullyConnectedLayer和regressionLayer输出预测结果。 - 使用
trainNetwork函数进行模型训练,并通过plot系列函数可视化训练过程和预测效果。
应用场景与优势
该模型特别适用于能源负荷预测、金融市场分析、环境监测、设备故障预警等需要高精度时间序列预测的领域。其优势在于:
- 高精度:融合多种先进结构,有效提升预测准确性。
- 强鲁棒性:Attention机制增强了模型对噪声和异常值的抵抗能力。
- 可解释性增强:Attention权重可以直观展示模型关注的重点时段,为决策提供依据。
结语
基于TCN-BiLSTM-Attention的神经网络模型,为多输入单输出回归预测任务提供了一种前沿且高效的解决方案。通过MATLAB平台,研究人员和工程师可以便捷地实现、训练和部署该模型,充分挖掘数据价值,为智能决策赋能。随着深度学习技术的不断发展,此类融合模型必将在更多领域展现其巨大潜力。
部分代码
%% 清空环境变量
warning off% 关闭报警信息
close all% 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
rng('default');
%% 导入数据
res = xlsread('data.xlsx');
num_samples = size(res, 1); % 样本个数
num_size = 0.7; % 训练集占数据集比例
outdim = 1; % 最后一列为输出
num_train_s = round(num_size * num_samples); % 训练集样本个数
L = size(res, 2) - outdim; % 输入特征维度
X = res(1:end,1: L)';
Y = res(1:end,L+1: end)';
%% 数据分析
[trainInd,valInd,testInd] = dividerand(size(res,1),0.7,0,0.3); %划分训练集与测试集
P_train = X(:,trainInd); %列索引
T_train = Y(:,trainInd);
P_test = X(:,testInd);
T_test = Y(:,testInd);
M = size(P_train, 2);
N = size(P_test, 2);
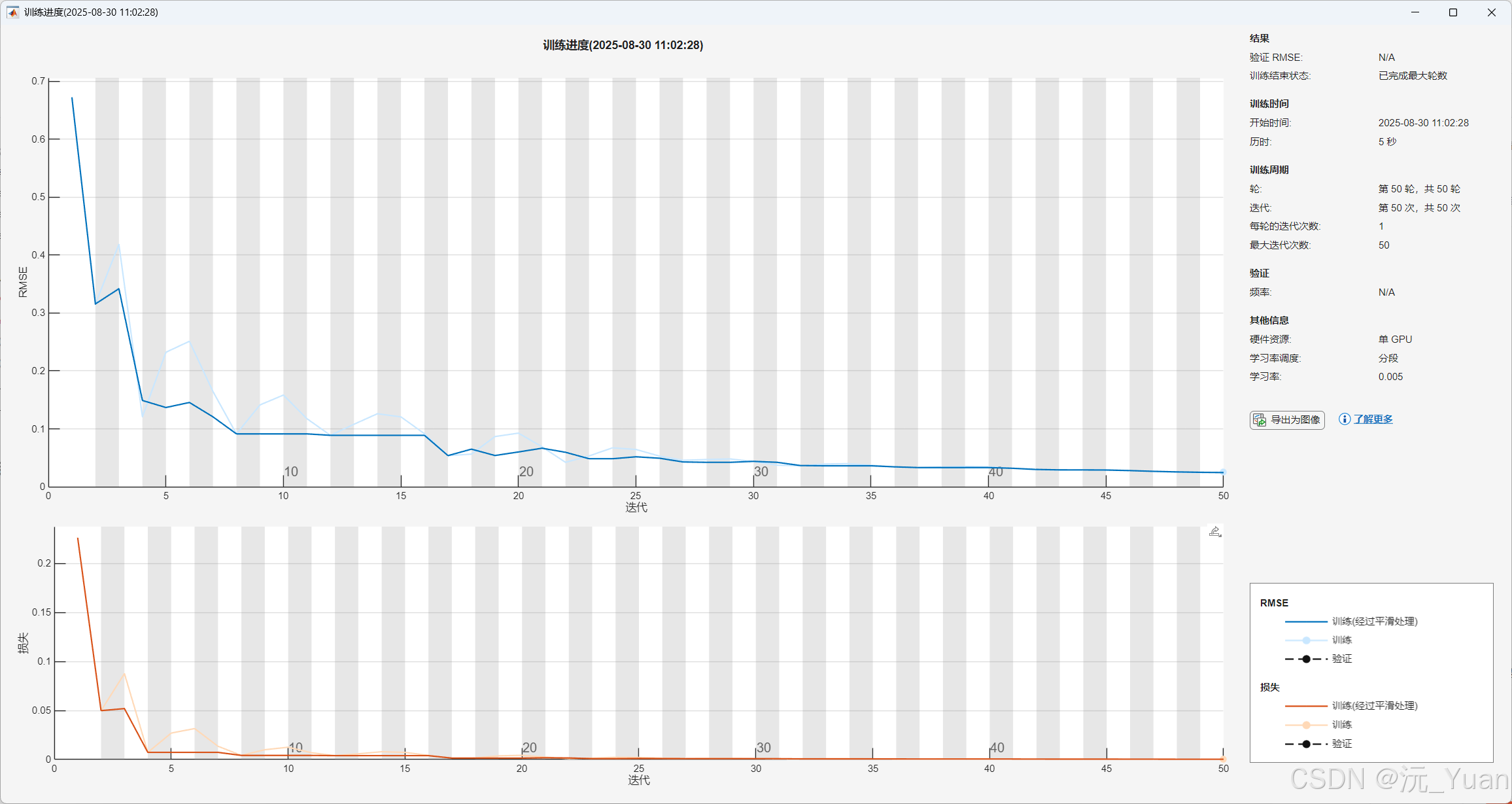
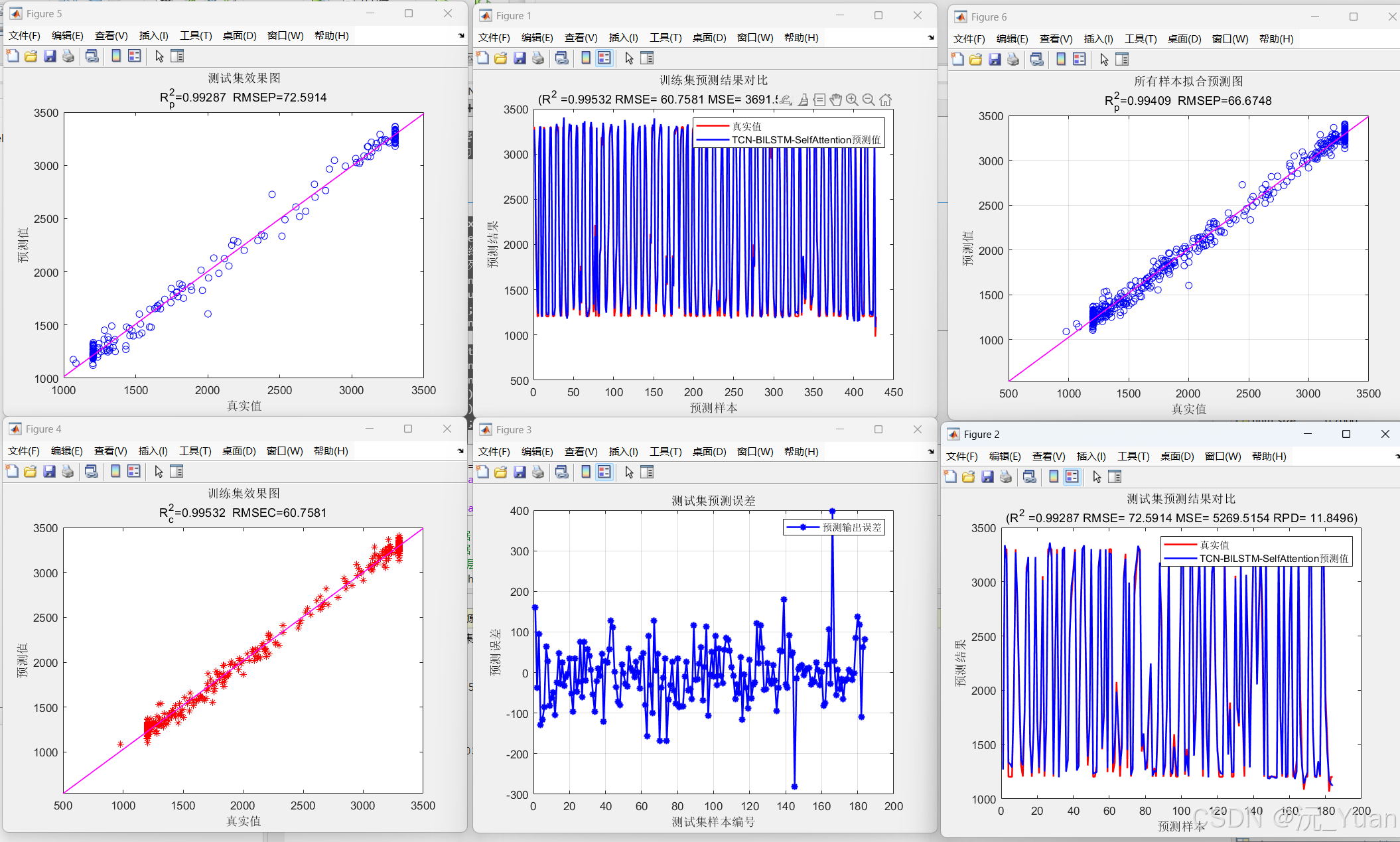
运行结果
代码下载
https://mbd.pub/o/bread/YZWXk5ZxbQ==