(十一)ps识别: epoch 训练日志解析
图片信息

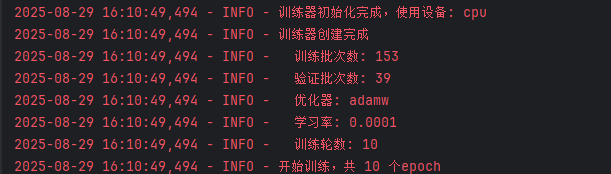
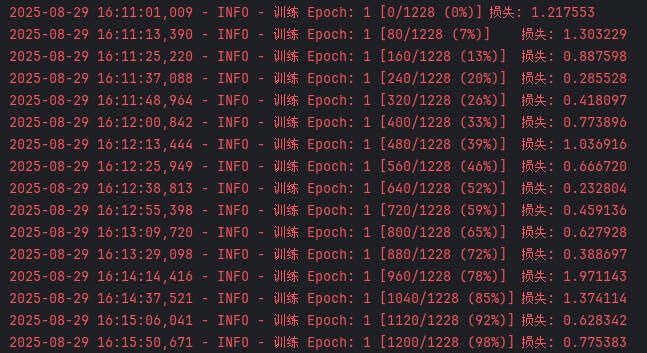
上图是模型训练的基本信息以及第一轮 训练日志,
概况
模型损失呈现出明显的不稳定性,波动较大(从 0.23 到 1.97 不等)。这种现象在模型训练初期可能出现,但过度波动通常意味着训练过程存在一些需要优化的问题。具体分析
一、现象分析
-
损失波动剧烈
同一 epoch 内,损失值在 0.23~1.97 之间大幅震荡,没有呈现稳定下降的趋势。这说明模型对不同批次的样本“学习效果”差异很大,可能是对部分样本的特征捕捉不稳定。 -
后期损失异常升高
训练到 78% 阶段(960/1228)时,损失突然飙升到 1.97,远高于前期水平。这可能是该批次样本存在“异常”(如难度极高的样本、数据增强过度导致失真,或数据标注错误),也可能是优化过程中的梯度爆炸/震荡。
二、可能的原因
-
数据层面
- 数据分布不均:训练集中可能存在部分批次的样本(如特定类型的 PS 痕迹)与整体分布差异较大,导致模型难以稳定学习。
- 数据增强过度:之前代码中使用了较多数据增强(如旋转、仿射、颜色抖动),可能导致部分样本被“扭曲”到难以识别的程度,反而干扰模型学习。
- 批次样本异质性高:batch size 为 16(参考之前代码),若同一批次内样本差异过大(如既有简单原始图,又有复杂篡改图),模型难以同时适应,导致损失波动。
-
模型与优化层面
- 学习率不合适:初始学习率 1e-4 可能对融合模型(Swin+ResNet)来说偏高,导致优化器在参数更新时“步伐过大”,难以稳定收敛。
- 梯度不稳定:两个预训练模型的特征尺度和参数量级可能存在差异,直接融合时可能导致梯度传播不稳定。
- 正则化不足:虽然代码中加入了 Dropout,但可能不足以抑制模型对“噪声样本”的过度拟合,导致损失波动。
三、解决方案建议
1. 调整数据处理策略
-
降低数据增强强度:减少过度变换(如将旋转角度从 15° 降至 10°,缩小仿射变换的平移范围),避免样本失真。
# 修改数据增强部分 train_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.RandomHorizontalFlip(p=0.5),transforms.RandomRotation(degrees=10), # 降低旋转角度transforms.RandomAffine(degrees=0, translate=(0.05, 0.05)), # 缩小平移范围transforms.ColorJitter(brightness=0.1, contrast=0.1), # 降低颜色抖动幅度transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) -
检查并清洗数据:排查训练集中是否存在标注错误、模糊或过度篡改的样本,移除“异常值”。
-
增大 batch size:若硬件允许,将 batch size 从 16 增至 32 或 64,减少单批次样本的随机性对损失的影响(需同步调整学习率)。
2. 优化模型训练参数
-
降低初始学习率:将学习率从 1e-4 降至 5e-5 或 3e-5,减缓参数更新速度,使损失更稳定。
optimizer = optim.AdamW(model.parameters(), lr=5e-5, weight_decay=1e-5) # 降低学习率 -
加入梯度裁剪:限制梯度最大值,避免梯度爆炸导致的损失突变。
# 在训练循环的反向传播后添加 loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0) # 梯度裁剪 optimizer.step() -
调整预训练模型的冻结策略:之前代码冻结了部分底层参数,可尝试先冻结全部预训练层,仅训练融合部分和分类器,待损失稳定后再解冻微调。
# 先冻结所有预训练层 for param in self.resnet.parameters():param.requires_grad = False for param in self.swin.parameters():param.requires_grad = False # 只训练融合和分类部分 for param in self.attention.parameters():param.requires_grad = True for param in self.classifier.parameters():param.requires_grad = True
3. 增加训练稳定性
-
使用学习率预热:在训练初期先用较小的学习率(如初始学习率的 1/10),经过几个 epoch 后再恢复正常学习率,帮助模型“适应”数据。
可借助torch.optim.lr_scheduler.LinearLR实现:# 定义学习率调度器,前3个epoch预热 scheduler = optim.lr_scheduler.SequentialLR(optimizer,schedulers=[optim.lr_scheduler.LinearLR(optimizer, start_factor=0.1, total_iters=3), # 预热optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.5) # 正常调度],milestones=[3] ) -
增加正则化强度:提高 Dropout 比例(如从 0.5 增至 0.6),或加入权重衰减(已在 AdamW 中设置,可保持 1e-5 不变)。
四、总结
当前损失波动主要是由于数据增强过度、学习率偏高、批次样本随机性大导致的。建议优先调整数据增强策略和学习率,观察后续 epoch 的损失是否趋于稳定。若调整后仍有大幅波动,再逐步加入梯度裁剪、学习率预热等策略。
训练初期(前 3~5 个 epoch)损失可能仍有小幅度波动,但应逐渐呈现下降趋势。若持续震荡或上升,则需进一步排查数据质量或模型架构是否存在问题。