【完整源码+数据集+部署教程】停车位状态检测系统源码和数据集:改进yolo11-DCNV2-Dynamic
背景意义
随着城市化进程的加快,城市交通拥堵问题日益严重,停车难成为了许多城市居民面临的普遍问题。有效的停车管理不仅可以提高城市交通的流动性,还能减少因寻找停车位而造成的时间浪费和环境污染。因此,开发一个高效的停车位状态检测系统显得尤为重要。基于深度学习的计算机视觉技术,尤其是目标检测算法,已被广泛应用于智能交通系统中,为停车位的自动检测提供了新的解决方案。
YOLO(You Only Look Once)系列算法因其实时性和高准确率而受到广泛关注。YOLOv11作为该系列的最新版本,结合了多种先进的技术,能够在复杂环境中快速准确地识别目标。通过对YOLOv11的改进,我们可以进一步提升其在停车位状态检测中的性能。具体而言,改进后的模型将能够更好地处理不同光照条件、天气变化以及复杂背景下的停车位检测任务。
本研究将利用一个包含1100张图像的数据集,数据集中分为“空闲”和“占用”两类,旨在训练一个高效的停车位状态检测模型。通过对数据集的深度分析和处理,我们将为模型提供丰富的训练样本,以提升其泛化能力和准确性。此外,数据集的图像经过预处理,确保了输入数据的一致性和质量,为模型的训练打下了坚实的基础。
综上所述,基于改进YOLOv11的停车位状态检测系统不仅能够有效解决城市停车难题,还将为智能交通管理提供有力支持。通过本研究的实施,我们希望能够为未来的智能城市建设贡献一份力量,推动交通管理的智能化和自动化进程。
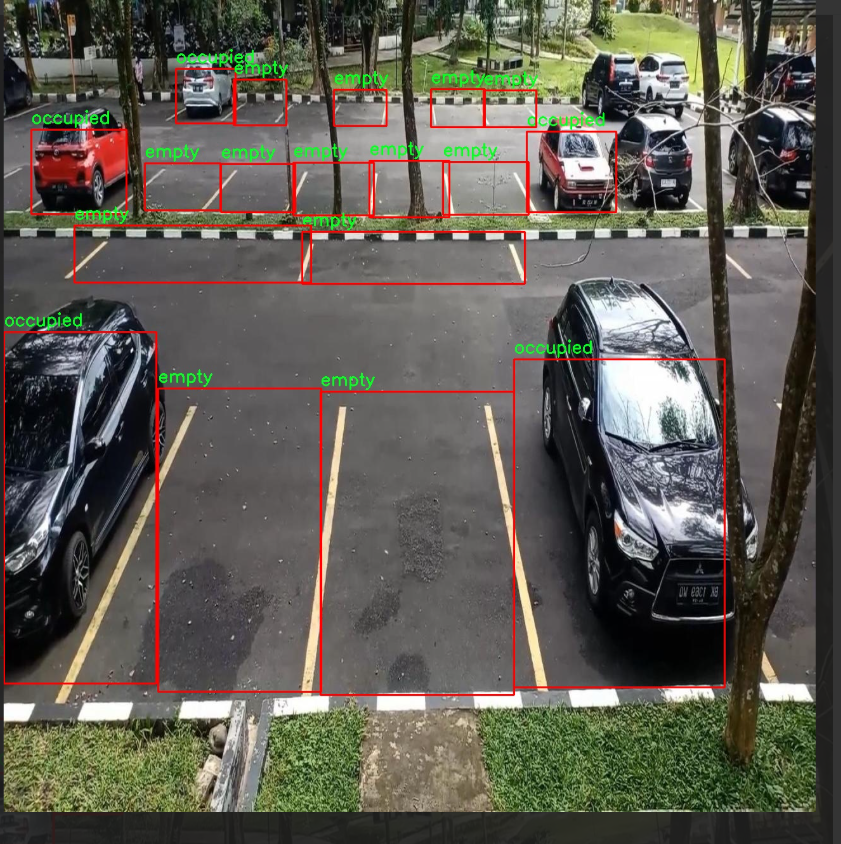
图片效果
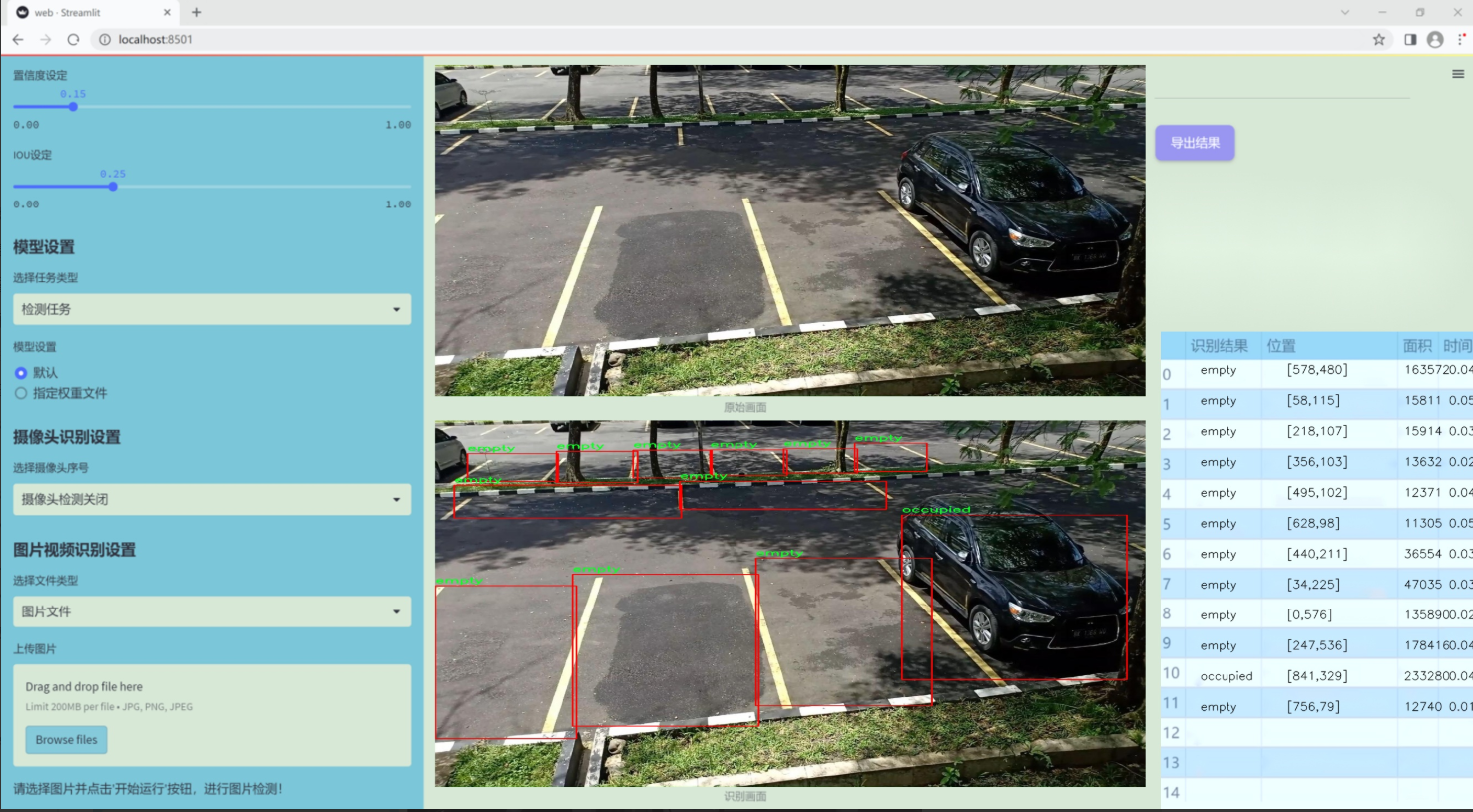
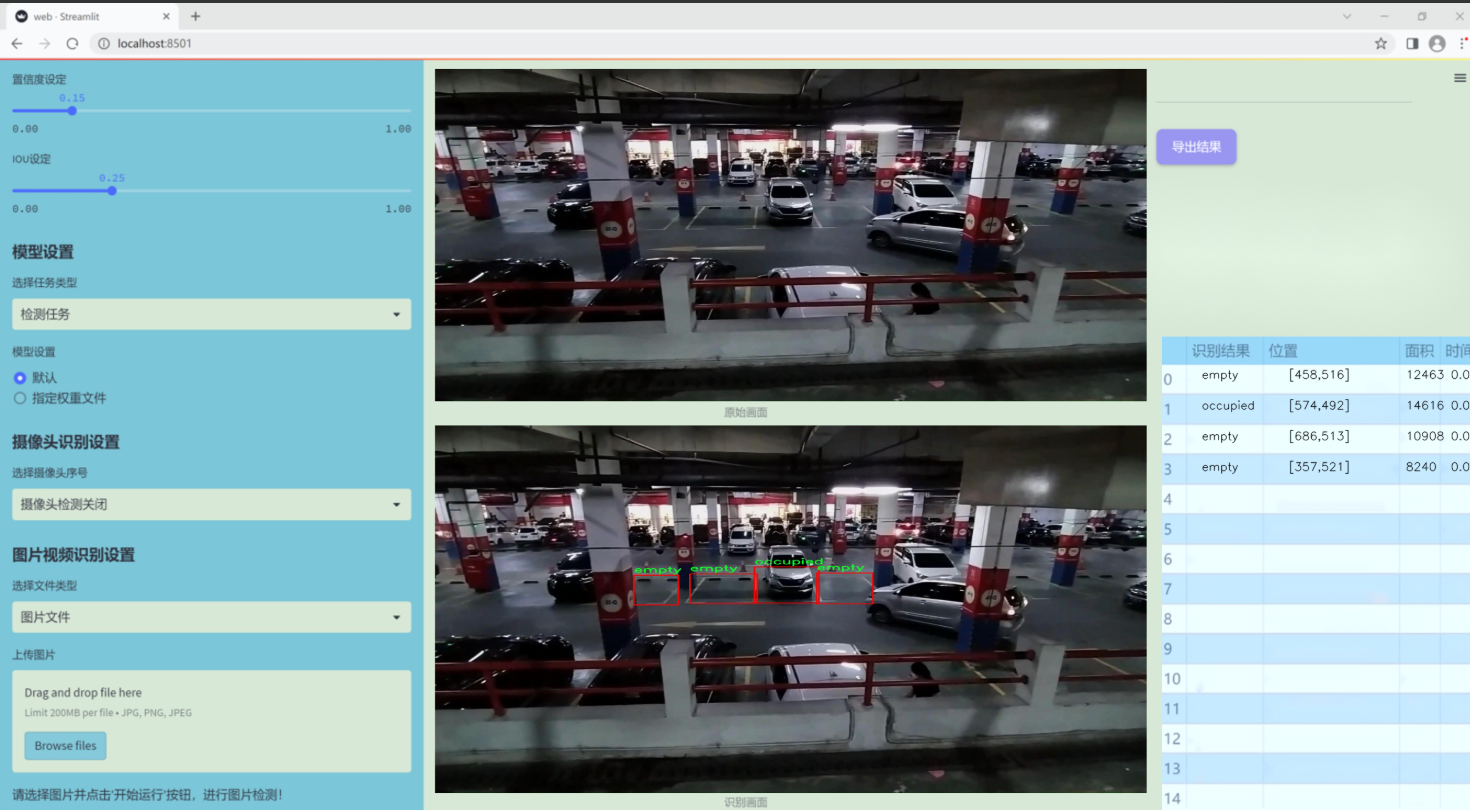
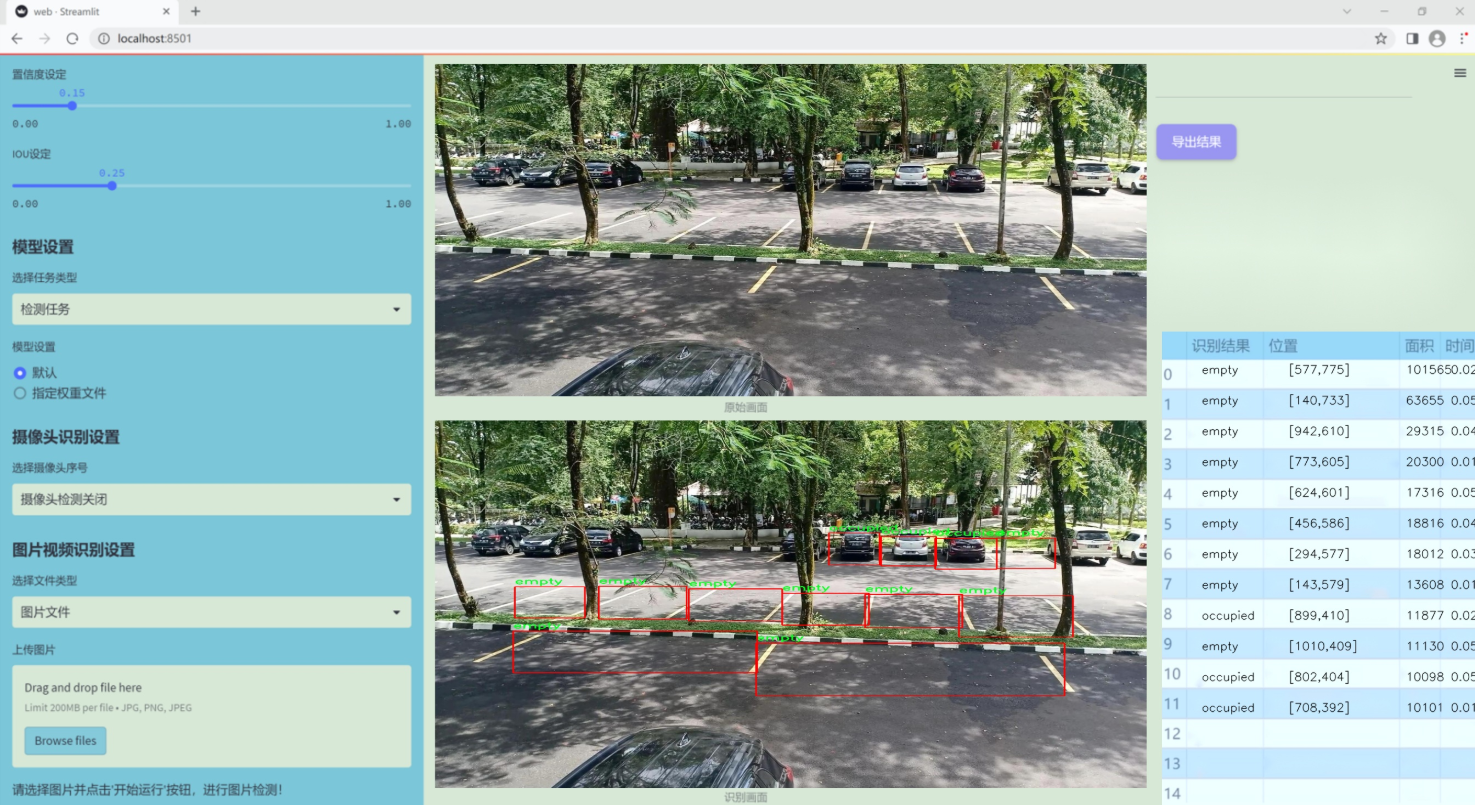
数据集信息
本项目旨在改进YOLOv11的停车位状态检测系统,所使用的数据集名为“collectPKlotData2”。该数据集专注于停车位的状态检测,包含两种主要类别:空闲(empty)和占用(occupied)。通过对这两种状态的准确识别,系统能够有效地帮助用户了解停车场的实时情况,从而提高停车效率,减少寻找停车位的时间。
数据集的构建过程经过精心设计,确保了样本的多样性和代表性。我们在不同的环境条件下收集了大量的图像数据,包括不同的天气状况、时间段以及各种停车场布局。这种多样性使得模型在训练过程中能够学习到更为丰富的特征,从而提高其在实际应用中的鲁棒性和准确性。数据集中每个类别的样本数量经过合理配置,以确保模型在学习过程中不会出现类别不平衡的问题。
在数据标注方面,我们采用了严格的标注流程,确保每张图像的状态标注准确无误。标注团队由经验丰富的人员组成,他们对停车位的状态有着深刻的理解,能够有效区分空闲和占用状态。这一过程不仅提高了数据集的质量,也为后续的模型训练打下了坚实的基础。
此外,为了提升模型的泛化能力,我们还对数据集进行了数据增强处理,包括图像旋转、缩放、亮度调整等操作。这些增强手段能够有效扩展训练样本的多样性,使得模型在面对未知数据时表现更加出色。
综上所述,数据集“collectPKlotData2”不仅涵盖了停车位状态检测所需的基本信息,还通过多样化的样本和严格的标注流程,为改进YOLOv11的停车位状态检测系统提供了坚实的数据支持。通过充分利用这一数据集,我们期待能够实现更高效、更准确的停车位状态检测,进而提升用户的停车体验。


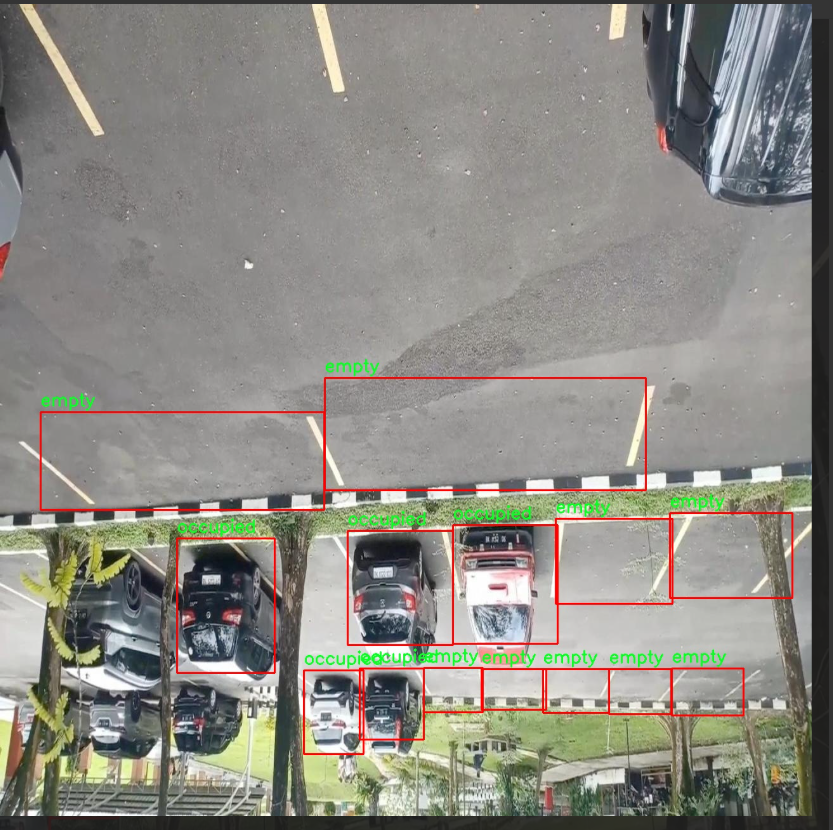

核心代码
以下是经过简化和注释的核心代码部分:
import os
import torch
from ultralytics.engine.validator import BaseValidator
from ultralytics.utils.metrics import DetMetrics, box_iou
from ultralytics.utils import LOGGER, ops
class DetectionValidator(BaseValidator):
“”"
扩展自BaseValidator类,用于基于检测模型的验证。
“”"
def __init__(self, dataloader=None, save_dir=None, args=None):"""初始化检测模型所需的变量和设置。"""super().__init__(dataloader, save_dir, args=args)self.metrics = DetMetrics(save_dir=self.save_dir) # 初始化检测指标self.iouv = torch.linspace(0.5, 0.95, 10) # IoU向量,用于计算mAPdef preprocess(self, batch):"""对图像批次进行预处理,以便于YOLO训练。"""# 将图像转移到设备上并归一化batch["img"] = batch["img"].to(self.device, non_blocking=True) / 255# 将其他数据转移到设备上for k in ["batch_idx", "cls", "bboxes"]:batch[k] = batch[k].to(self.device)return batchdef postprocess(self, preds):"""对预测输出应用非极大值抑制(NMS)。"""return ops.non_max_suppression(preds,self.args.conf,self.args.iou,multi_label=True,max_det=self.args.max_det,)def update_metrics(self, preds, batch):"""更新检测指标。"""for si, pred in enumerate(preds):# 处理每个预测结果npr = len(pred)pbatch = self._prepare_batch(si, batch) # 准备批次数据cls, bbox = pbatch.pop("cls"), pbatch.pop("bbox") # 获取真实标签if npr == 0:continue # 如果没有预测结果,跳过# 处理预测结果predn = self._prepare_pred(pred, pbatch) # 准备预测数据stat = {"conf": predn[:, 4], # 置信度"pred_cls": predn[:, 5], # 预测类别"tp": self._process_batch(predn, bbox, cls) # 计算真阳性}# 更新指标for k in self.stats.keys():self.stats[k].append(stat[k])def _process_batch(self, detections, gt_bboxes, gt_cls):"""返回正确的预测矩阵。"""iou = box_iou(gt_bboxes, detections[:, :4]) # 计算IoUreturn self.match_predictions(detections[:, 5], gt_cls, iou) # 匹配预测与真实标签def get_stats(self):"""返回指标统计信息和结果字典。"""stats = {k: torch.cat(v, 0).cpu().numpy() for k, v in self.stats.items()} # 转换为numpyif len(stats) and stats["tp"].any():self.metrics.process(**stats) # 处理指标return self.metrics.results_dict # 返回结果字典
代码注释说明:
类定义:DetectionValidator类用于验证检测模型的性能,继承自BaseValidator。
初始化方法:在初始化时设置一些必要的变量和指标,DetMetrics用于存储检测性能指标。
预处理方法:preprocess方法对输入的图像批次进行归一化处理,并将数据转移到指定的设备(如GPU)。
后处理方法:postprocess方法使用非极大值抑制(NMS)来过滤预测结果,减少冗余框。
更新指标方法:update_metrics方法根据预测结果和真实标签更新性能指标。
处理批次方法:_process_batch方法计算预测框与真实框之间的IoU,并返回匹配结果。
获取统计信息方法:get_stats方法返回当前的指标统计信息,便于后续分析和展示。
以上代码展示了YOLO模型验证的核心逻辑,注释详细解释了每个方法的功能和作用。
这个程序文件 val.py 是一个用于目标检测模型验证的类,名为 DetectionValidator,它继承自 BaseValidator 类。该类主要用于评估 YOLO(You Only Look Once)目标检测模型的性能,支持处理图像数据、计算指标、生成结果报告等功能。
在初始化方法 init 中,类设置了一些基本参数,包括数据加载器、保存目录、进度条、参数和回调函数。它还初始化了一些用于计算检测指标的变量,如 DetMetrics 对象和 IoU(Intersection over Union)向量。
preprocess 方法用于对输入的图像批次进行预处理,包括将图像数据转移到指定设备(如 GPU),进行数据类型转换,以及对边界框进行归一化处理。此方法还支持自动标注功能。
init_metrics 方法用于初始化评估指标,包括判断数据集是否为 COCO 格式,设置类别映射,以及初始化混淆矩阵和统计信息。
get_desc 方法返回一个格式化的字符串,用于描述 YOLO 模型的类别指标。
postprocess 方法应用非极大值抑制(NMS)来处理模型的预测输出,以减少冗余的检测框。
_prepare_batch 和 _prepare_pred 方法分别用于准备输入的图像和目标框的批次数据,以及处理模型的预测结果。
update_metrics 方法负责更新检测指标,通过比较预测结果和真实标签,计算出真正例、置信度和预测类别等信息,并更新统计数据。
finalize_metrics 方法设置最终的指标值,包括计算速度和混淆矩阵。
get_stats 方法返回计算后的指标统计信息,并更新每个类别的目标数量。
print_results 方法用于打印训练或验证集的每个类别的指标结果,并在需要时绘制混淆矩阵。
_process_batch 方法用于计算正确的预测矩阵,通过计算 IoU 值来匹配预测框和真实框。
build_dataset 和 get_dataloader 方法用于构建 YOLO 数据集和返回数据加载器,以便于后续的验证过程。
plot_val_samples 和 plot_predictions 方法用于可视化验证样本和模型的预测结果,并将结果保存为图像文件。
save_one_txt 方法将 YOLO 检测结果保存为文本文件,采用特定的格式以便后续使用。
pred_to_json 方法将 YOLO 的预测结果序列化为 COCO JSON 格式,以便于后续的评估。
eval_json 方法用于评估 YOLO 输出的 JSON 格式结果,并返回性能统计信息,支持与 COCO 数据集的评估工具进行交互。
总体而言,这个文件提供了一个完整的框架,用于对 YOLO 模型进行验证和评估,支持多种输出格式和性能指标的计算,适用于计算机视觉领域的目标检测任务。
10.4 mamba_yolo.py
以下是经过简化和注释的核心代码部分,保留了主要功能并添加了详细的中文注释:
import torch
import torch.nn as nn
from einops import rearrange
定义二维层归一化
class LayerNorm2d(nn.Module):
def init(self, normalized_shape, eps=1e-6, elementwise_affine=True):
super().init()
# 使用 PyTorch 的 LayerNorm 进行归一化
self.norm = nn.LayerNorm(normalized_shape, eps, elementwise_affine)
def forward(self, x):# 将输入张量的维度从 (B, C, H, W) 转换为 (B, H, W, C)x = rearrange(x, 'b c h w -> b h w c').contiguous()# 进行归一化x = self.norm(x)# 将张量的维度转换回 (B, C, H, W)x = rearrange(x, 'b h w c -> b c h w').contiguous()return x
自适应填充函数
def autopad(k, p=None, d=1): # kernel, padding, dilation
“”“根据输入的卷积核大小自动计算填充,以保持输出形状不变。”“”
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # 实际卷积核大小
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # 自动填充
return p
交叉扫描功能
class CrossScan(torch.autograd.Function):
@staticmethod
def forward(ctx, x: torch.Tensor):
B, C, H, W = x.shape # 获取输入张量的形状
ctx.shape = (B, C, H, W)
xs = x.new_empty((B, 4, C, H * W)) # 创建新的张量用于存储扫描结果
xs[:, 0] = x.flatten(2, 3) # 进行平铺
xs[:, 1] = x.transpose(dim0=2, dim1=3).flatten(2, 3) # 转置并平铺
xs[:, 2:4] = torch.flip(xs[:, 0:2], dims=[-1]) # 反转前两个结果
return xs
@staticmethod
def backward(ctx, ys: torch.Tensor):B, C, H, W = ctx.shapeL = H * W# 反向传播ys = ys[:, 0:2] + ys[:, 2:4].flip(dims=[-1]).view(B, 2, -1, L)y = ys[:, 0] + ys[:, 1].view(B, -1, W, H).transpose(dim0=2, dim1=3).contiguous().view(B, -1, L)return y.view(B, -1, H, W)
选择性扫描核心功能
class SelectiveScanCore(torch.autograd.Function):
@staticmethod
@torch.cuda.amp.custom_fwd
def forward(ctx, u, delta, A, B, C, D=None, delta_bias=None, delta_softplus=False, nrows=1, backnrows=1):
# 确保输入张量是连续的
if u.stride(-1) != 1:
u = u.contiguous()
if delta.stride(-1) != 1:
delta = delta.contiguous()
if D is not None and D.stride(-1) != 1:
D = D.contiguous()
if B.stride(-1) != 1:
B = B.contiguous()
if C.stride(-1) != 1:
C = C.contiguous()
if B.dim() == 3:
B = B.unsqueeze(dim=1) # 扩展维度
ctx.squeeze_B = True
if C.dim() == 3:
C = C.unsqueeze(dim=1) # 扩展维度
ctx.squeeze_C = True
ctx.delta_softplus = delta_softplus
ctx.backnrows = backnrows
# 调用 CUDA 核心函数进行前向计算
out, x, *rest = selective_scan_cuda_core.fwd(u, delta, A, B, C, D, delta_bias, delta_softplus, 1)
ctx.save_for_backward(u, delta, A, B, C, D, delta_bias, x) # 保存反向传播所需的张量
return out
@staticmethod
@torch.cuda.amp.custom_bwd
def backward(ctx, dout, *args):u, delta, A, B, C, D, delta_bias, x = ctx.saved_tensorsif dout.stride(-1) != 1:dout = dout.contiguous()# 调用 CUDA 核心函数进行反向计算du, ddelta, dA, dB, dC, dD, ddelta_bias, *rest = selective_scan_cuda_core.bwd(u, delta, A, B, C, D, delta_bias, dout, x, ctx.delta_softplus, 1)return (du, ddelta, dA, dB, dC, dD, ddelta_bias, None, None, None, None)
选择性扫描的主函数
def cross_selective_scan(
x: torch.Tensor,
x_proj_weight: torch.Tensor,
dt_projs_weight: torch.Tensor,
A_logs: torch.Tensor,
Ds: torch.Tensor,
out_norm: torch.nn.Module,
nrows=-1,
backnrows=-1,
delta_softplus=True,
to_dtype=True,
):
B, D, H, W = x.shape # 获取输入张量的形状
D, N = A_logs.shape
K, D, R = dt_projs_weight.shape
L = H * W
# 进行交叉扫描
xs = CrossScan.apply(x)# 进行权重投影
x_dbl = torch.einsum("b k d l, k c d -> b k c l", xs, x_proj_weight)
dts, Bs, Cs = torch.split(x_dbl, [R, N, N], dim=2) # 拆分张量
dts = torch.einsum("b k r l, k d r -> b k d l", dts, dt_projs_weight)
xs = xs.view(B, -1, L)
dts = dts.contiguous().view(B, -1, L)# HiPPO 矩阵
As = -torch.exp(A_logs.to(torch.float)) # (k * c, d_state)
Bs = Bs.contiguous()
Cs = Cs.contiguous()
Ds = Ds.to(torch.float) # (K * c)
delta_bias = dt_projs_bias.view(-1).to(torch.float)# 进行选择性扫描
ys: torch.Tensor = SelectiveScan.apply(xs, dts, As, Bs, Cs, Ds, delta_bias, delta_softplus, nrows, backnrows
).view(B, K, -1, H, W)# 合并结果
y: torch.Tensor = CrossMerge.apply(ys)# 进行输出归一化
y = out_norm(y.view(B, -1, H, W)).view(B, H, W, -1)return (y.to(x.dtype) if to_dtype else y)
简单的卷积网络结构
class SimpleStem(nn.Module):
def init(self, inp, embed_dim, ks=3):
super().init()
self.hidden_dims = embed_dim // 2
self.conv = nn.Sequential(
nn.Conv2d(inp, self.hidden_dims, kernel_size=ks, stride=2, padding=autopad(ks, d=1), bias=False),
nn.BatchNorm2d(self.hidden_dims),
nn.GELU(),
nn.Conv2d(self.hidden_dims, embed_dim, kernel_size=ks, stride=2, padding=autopad(ks, d=1), bias=False),
nn.BatchNorm2d(embed_dim),
nn.SiLU(),
)
def forward(self, x):return self.conv(x) # 前向传播
视觉线索合并模块
class VisionClueMerge(nn.Module):
def init(self, dim, out_dim):
super().init()
self.hidden = int(dim * 4)
self.pw_linear = nn.Sequential(nn.Conv2d(self.hidden, out_dim, kernel_size=1, stride=1, padding=0),nn.BatchNorm2d(out_dim),nn.SiLU())def forward(self, x):# 进行张量的拼接y = torch.cat([x[..., ::2, ::2],x[..., 1::2, ::2],x[..., ::2, 1::2],x[..., 1::2, 1::2]], dim=1)return self.pw_linear(y) # 前向传播
以上代码中,保留了重要的类和函数,提供了详细的中文注释,便于理解每个部分的功能和实现方式。
这个程序文件 mamba_yolo.py 实现了一个基于深度学习的视觉模型,主要用于目标检测任务。文件中包含了多个类和函数,构成了一个复杂的神经网络架构,结合了卷积神经网络(CNN)和一些新颖的结构,如选择性扫描(Selective Scan)和状态空间模型(State Space Model, SSM)。以下是对代码的详细讲解。
首先,文件导入了一些必要的库,包括 PyTorch 和一些用于深度学习的模块。接着,定义了一个 LayerNorm2d 类,它是对 2D 张量进行层归一化的实现。这个类的 forward 方法会对输入的张量进行维度重排,以适应层归一化的要求。
接下来,定义了一个 autopad 函数,用于计算卷积操作的自动填充,以确保输出形状与输入形状相同。
文件中还实现了多个自定义的 PyTorch 函数,如 CrossScan 和 CrossMerge,它们用于处理张量的交叉扫描和合并操作。这些操作是为了提高模型在处理特征时的灵活性和效率。
SelectiveScanCore 类实现了选择性扫描的前向和反向传播逻辑。选择性扫描是一种高效的特征处理方法,可以在计算中减少冗余,提高模型的性能。
cross_selective_scan 函数则是对选择性扫描的封装,提供了多种参数选项以适应不同的输入和输出需求。
SS2D 类实现了一个包含状态空间模型的模块,具有多个可调参数,包括模型的维度、状态维度、卷积层的设置等。这个模块的前向传播逻辑通过调用 cross_selective_scan 函数来处理输入数据。
接下来,定义了多个块(Block)类,如 RGBlock、LSBlock 和 XSSBlock,这些类都是神经网络的基本构建单元,负责处理输入特征并生成输出特征。每个块都包含卷积层、激活函数和其他操作,以增强模型的表达能力。
VSSBlock_YOLO 类是一个更高级的模块,结合了选择性扫描和其他块的功能,旨在处理更复杂的特征提取任务。它的前向传播方法将输入通过多个层进行处理,最终生成输出。
SimpleStem 类是模型的输入层,负责将输入图像通过卷积层和激活函数进行初步处理,以提取基础特征。
最后,VisionClueMerge 类用于合并不同来源的特征,增强模型的多样性和鲁棒性。
总体来说,这个文件实现了一个复杂的视觉模型,结合了多种深度学习技术,旨在提高目标检测任务的性能。通过模块化的设计,代码具有良好的可读性和可扩展性,便于后续的修改和优化。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式