大模型入门学习微调实战:基于PyTorch和Hugging Face电影评价情感分析模型微调全流程(附完整代码)手把手教你做
深入浅出:如何训练一个属于你的大模型?
“一个强大的大模型,究竟是如何训练出来的?”
本文将基于行业共识,为您详细拆解大模型的完整训练流程,并提供一个基于开源模型和数据集的实战代码示例,帮助您从理论到实践,全面掌握大模型训练的核心。
大模型训练的核心:
从本质上讲,训练一个大模型主要依赖两大核心要素:海量的训练数据和先进的机器学习模型。整个训练过程可以概括为三个主要阶段:
第一阶段:数据准备
第二阶段:模型训练
第三阶段:成果验证
实战示例:使用Hugging Face微调一个情感分析模型
理论讲完了,让我们通过一个具体的代码示例来感受一下模型微机。我们将使用强大的Hugging Face生态,微调一个预训练模型来完成电影评论的情感分类任务。
-
目标:训练一个能判断电影评论是正面还是负面的模型。
-
模型选择:我们将使用
distilbert-base-uncased,这是一个轻量级的BERT模型,非常适合用于教学演示。 -
数据集:使用经典的
imdb数据集,它包含了5万条带有正面/负面标签的电影评论。 -
第一阶段:数据准备
-
新建三个文件夹,如图名字自己改一下,把对应的文件放进去
-
数据集链接:https://huggingface.co/datasets/imdb
-
模型链接https://huggingface.co/distilbert/distilbert-base-uncased/tree/main
-
代码链接https://huggingface.co/spaces/evaluate-metric/accuracy/blob/main/accuracy.py
-
-
-
由于部分朋友无法下载,网盘整理好的整个项目链接
-
链接: https://pan.baidu.com/s/1cNXgc5VerhqJSlsyiR736w?pwd=DDDD 提取码: DDDD
-
第二阶段:模型训练
把代码复制下来,在pycharm里新建一个111.py文件,安装上依赖项开始运行,如果不行在某宝上找这家店 强者自强 环境问题帮助挺大。
训练代码
# final_local_script.pyimport os
import torch
import numpy as np
import evaluate
from datasets import load_dataset
from transformers import (AutoTokenizer,AutoModelForSequenceClassification,TrainingArguments,Trainer,DataCollatorWithPadding
)# -------------------- [核心修改区] --------------------# 设置环境变量,优先使用国内镜像(这是一个好习惯,即使本地加载也建议保留)
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'# 定义所有本地资源的路径
LOCAL_DATASET_PATH = "./imdb"
LOCAL_MODEL_PATH = "./distilbert-base-uncased-local"
LOCAL_METRIC_PATH = "./metrics/accuracy.py" # 直接指向 .py 文件# ----------------------------------------------------# 确保使用GPU(如果可用)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# --- 2. 从本地加载数据集 ---
print(f"正在从本地路径 '{LOCAL_DATASET_PATH}' 加载IMDB数据集...")
# <-- 修改点:直接传入文件夹路径,datasets库会自动识别
# 我们加载完整的 'train' 和 'test' 部分
full_dataset = load_dataset(LOCAL_DATASET_PATH, name="plain_text")# 为了快速演示,我们仍然只使用一小部分数据
# 如果您想用全部数据,可以注释掉下面两行
train_sample = full_dataset['train'].shuffle(seed=42).select(range(1600))
test_sample = full_dataset['test'].shuffle(seed=42).select(range(400))# 创建一个新的DatasetDict来组织我们的抽样数据
dataset = {'train': train_sample, 'test': test_sample}print("\n数据集结构预览:")
print(dataset)
print("\n一条训练数据示例:")
print(dataset['train'][0])# --- 3. 从本地加载预训练模型和分词器 (Tokenizer) ---
print(f"\n正在从本地路径 '{LOCAL_MODEL_PATH}' 加载预训练模型...")
# <-- 修改点:将模型名称换成本地文件夹路径
tokenizer = AutoTokenizer.from_pretrained(LOCAL_MODEL_PATH)
model = AutoModelForSequenceClassification.from_pretrained(LOCAL_MODEL_PATH,num_labels=2,id2label={0: "NEGATIVE", 1: "POSITIVE"}
).to(device)# --- 4. 数据预处理 (与您之前的代码一致) ---
def preprocess_function(examples):return tokenizer(examples["text"],truncation=True,padding=False,max_length=256)print("\n正在对数据集进行分词处理...")
# 注意:datasets库的map操作是惰性的,这里需要将字典重新包装
from datasets import DatasetDict
tokenized_datasets = DatasetDict({'train': dataset['train'].map(preprocess_function, batched=True),'test': dataset['test'].map(preprocess_function, batched=True)
})tokenized_datasets = tokenized_datasets.remove_columns(["text"])
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
tokenized_datasets.set_format("torch", columns=["input_ids", "attention_mask", "labels"])train_dataset = tokenized_datasets["train"]
eval_dataset = tokenized_datasets["test"]data_collator = DataCollatorWithPadding(tokenizer=tokenizer,padding="longest",return_tensors="pt"
)# --- 5. 从本地定义评估指标 ---
print(f"正在从本地路径 '{LOCAL_METRIC_PATH}' 加载评估脚本...")
# <-- 修改点:直接加载本地的 .py 文件
metric = evaluate.load(LOCAL_METRIC_PATH)def compute_metrics(eval_pred):logits, labels = eval_predpredictions = np.argmax(logits, axis=-1)return metric.compute(predictions=predictions, references=labels)# --- 6. 设置训练参数 (与您之前的代码一致) ---
training_args = TrainingArguments(output_dir="./results",num_train_epochs=3,per_device_train_batch_size=16,per_device_eval_batch_size=32,learning_rate=2e-5,warmup_ratio=0.1,weight_decay=0.01,logging_dir="./logs",logging_steps=10,evaluation_strategy="epoch",save_strategy="epoch",load_best_model_at_end=True,metric_for_best_model="accuracy",greater_is_better=True,report_to="none",seed=42
)# --- 7. 创建并启动训练器 (与您之前的代码一致) ---
trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=eval_dataset,compute_metrics=compute_metrics,tokenizer=tokenizer,data_collator=data_collator
)print("\n--- 开始模型微调训练 ---")
trainer.train()
print("\n--- 训练完成 ---")# --- 8. 保存最终模型和分词器 ---
final_model_path = "./sentiment_analyzer_model"
trainer.save_model(final_model_path)
print(f"\n模型已成功保存至: {final_model_path}")# (为节省空间,省略了最后的推理部分,您可以从之前的代码中复制过来)
print("\n训练流程结束。")运行训练的过程,CPU大概运行了20分钟,这还只是使用已有的模型微调,如果没有模型不得几十天啊。
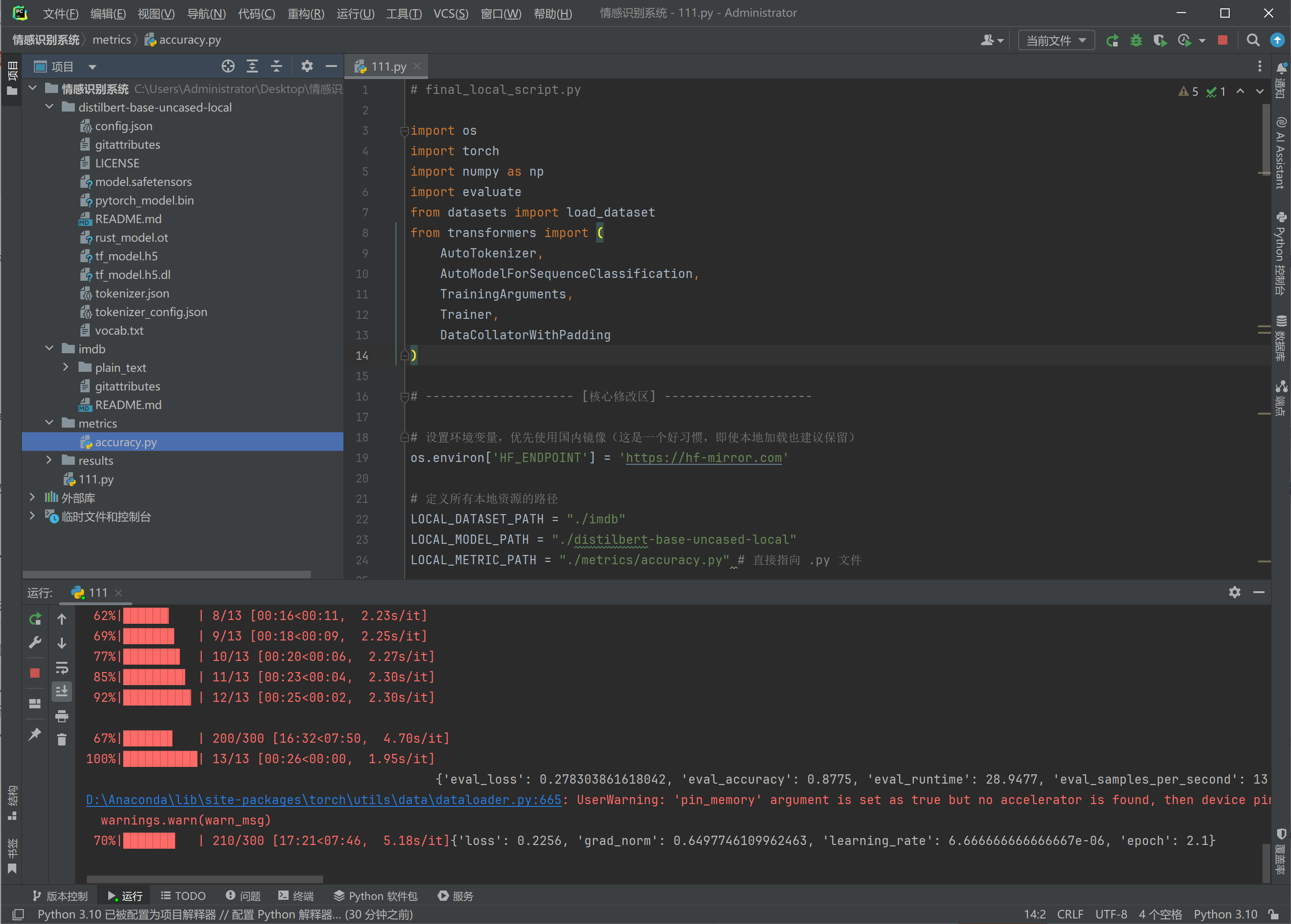
训练完了多出来两个文件夹就是我们的模型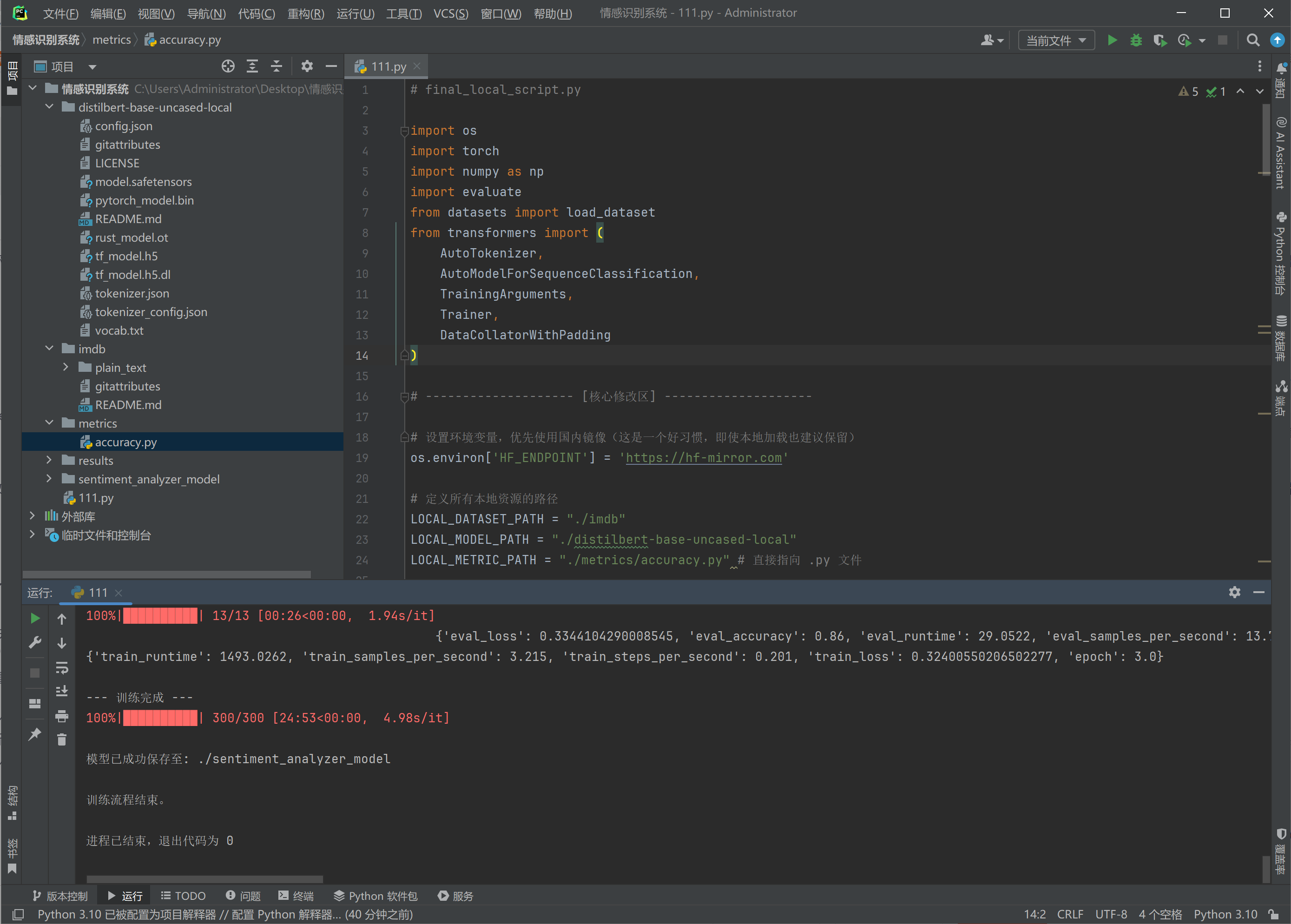
第三阶段:成果验证
模型有了,现在来测试使用,用TK界面,方便直观快速。
新建222.py代码
import tkinter as tk
from tkinter import ttk
from tkinter.scrolledtext import ScrolledText
import threading
from transformers import pipeline# --- 1. 定义本地模型路径 ---
MODEL_PATH = "./sentiment_analyzer_model"# --- 全局变量,用于存储加载好的模型 ---
sentiment_pipeline = Nonedef load_model():"""在后台线程中加载模型,避免UI卡顿"""global sentiment_pipelineprint("正在后台加载已微调的情感分析模型...")try:# 使用pipeline加载本地模型sentiment_pipeline = pipeline("sentiment-analysis", # 任务类型model=MODEL_PATH, # 本地模型路径tokenizer=MODEL_PATH # 本地分词器路径)print("模型加载完毕!")# 模型加载成功后,启用分析按钮analyze_button.config(state=tk.NORMAL, text="分析情感")except Exception as e:print(f"模型加载失败: {e}")# 如果加载失败,在结果框显示错误信息result_text.config(state=tk.NORMAL)result_text.delete("1.0", tk.END)result_text.insert(tk.END, f"模型加载失败!\n\n请确保 './sentiment_analyzer_model' 文件夹存在于脚本旁边。\n\n错误详情: {e}")result_text.config(state=tk.DISABLED)def analyze_sentiment():"""点击按钮时触发的情感分析函数"""# 1. 从输入框获取用户输入的文本user_input = input_text.get("1.0", "end-1c").strip()# 2. 检查输入是否为空if not user_input:response = "请输入一些文本后再点击分析。"elif sentiment_pipeline is None:response = "模型仍在加载中,请稍候..."else:try:# 3. 使用加载好的pipeline进行预测print(f"正在分析文本: '{user_input}'")result = sentiment_pipeline(user_input)[0]label = result['label']score = result['score']# 4. 根据预测结果,格式化输出if label == 'POSITIVE':emoji = "😊"text_label = "正面"else:emoji = "😠"text_label = "负面"response = (f"情感倾向分析结果:\n\n"f" 类别: 【{text_label}】 {emoji}\n\n"f" 置信度: {score:.2%}")except Exception as e:response = f"分析时出现错误: {e}"# 5. 将结果显示在下方的结果框中result_text.config(state=tk.NORMAL) # 先设置为可编辑状态result_text.delete("1.0", tk.END) # 清空旧内容result_text.insert(tk.END, response) # 插入新内容result_text.config(state=tk.DISABLED) # 再设置为只读状态# --- 2. 创建Tkinter主窗口 ---
root = tk.Tk()
root.title("电影评价情感分析工具")
root.geometry("550x450") # 设置窗口大小
root.resizable(False, False) # 禁止调整窗口大小# 设置整体样式
style = ttk.Style()
style.configure("TLabel", font=("Microsoft YaHei", 11))
style.configure("TButton", font=("Microsoft YaHei", 11, "bold"))# 创建主框架
main_frame = ttk.Frame(root, padding="15")
main_frame.pack(fill=tk.BOTH, expand=True)# --- 3. 创建界面组件 ---# 输入部分
input_label = ttk.Label(main_frame, text="请输入要分析的英文电影评论:")
input_label.pack(pady=(0, 5), anchor="w")input_text = ScrolledText(main_frame, height=8, font=("Arial", 11), wrap=tk.WORD)
input_text.pack(fill=tk.X, expand=True)
input_text.focus() # 启动时自动聚焦到输入框# 分析按钮
analyze_button = ttk.Button(main_frame, text="正在加载模型...", command=analyze_sentiment, state=tk.DISABLED)
analyze_button.pack(pady=15)# 结果显示部分
result_label = ttk.Label(main_frame, text="分析结果:")
result_label.pack(pady=(10, 5), anchor="w")result_text = ScrolledText(main_frame, height=7, font=("Microsoft YaHei", 12), wrap=tk.WORD, state=tk.DISABLED)
result_text.pack(fill=tk.X, expand=True)# --- 4. 启动后台线程加载模型 ---
# 使用线程可以防止加载大模型时UI界面卡死
model_load_thread = threading.Thread(target=load_model, daemon=True)
model_load_thread.start()# --- 5. 启动Tkinter事件循环 ---
root.mainloop()
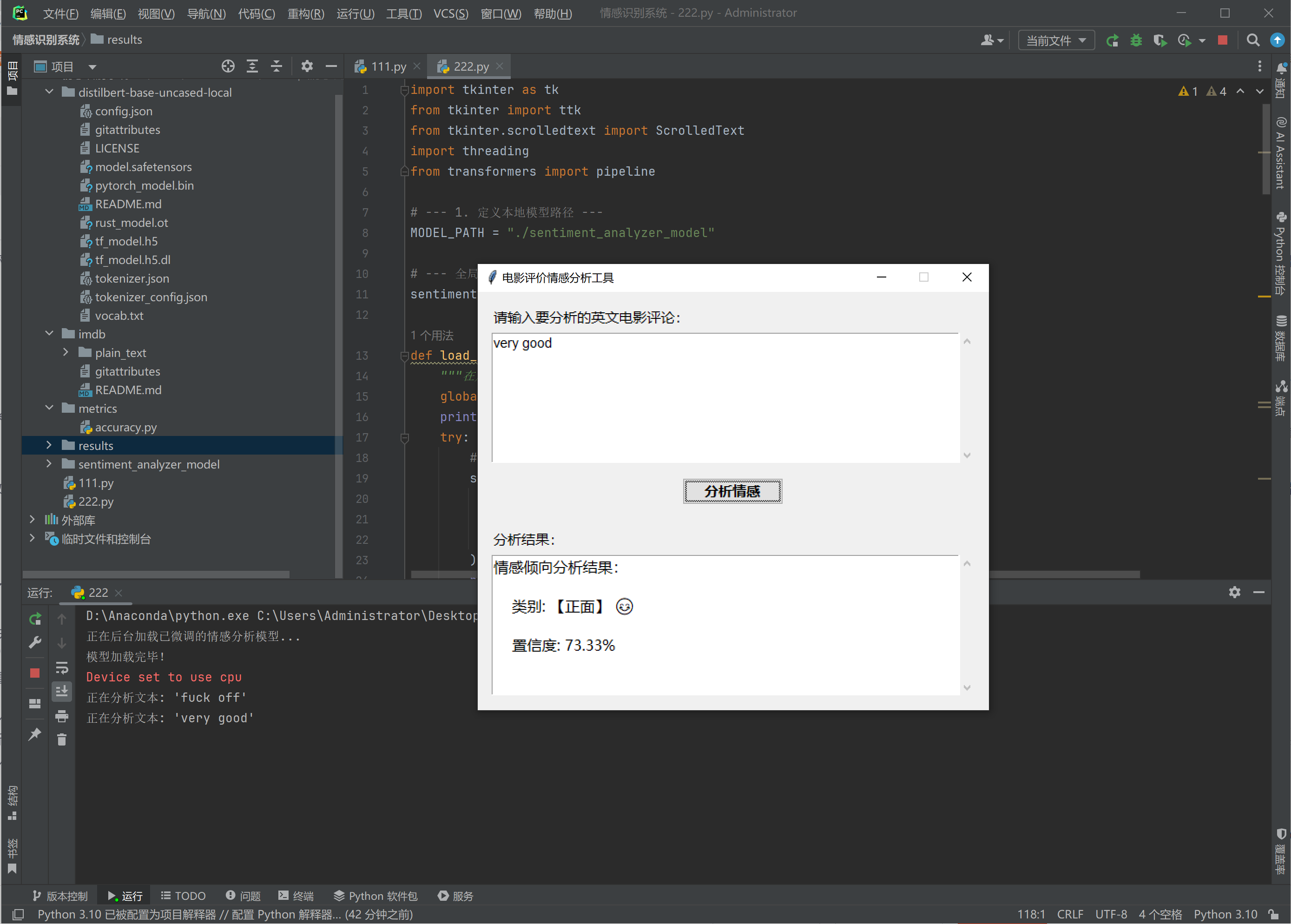
不要觉得训练大模型是那些大公司的事情,不积小流无以成江海。
美好时代的到来需要所有人一起努力。
下面是AI讲解和问答
项目全流程解析:打造你的电影评价情感分析大模型
本项目旨在通过现代自然语言处理(NLP)技术,带领开发者走完从数据准备、模型微调到最终创建可交互桌面应用的完整流程。我们将利用强大的Hugging Face生态和PyTorch框架,将一个通用的预训练大模型,调教成一个专注于电影评论情感分析的“专家模型”。第一步:数据收集与准备
目标:获取用于训练和评估模型的高质量数据集。1. 数据集选择
我们选用了NLP领域最经典的情感分析数据集之一:IMDb Large Movie Review Dataset。来源:由斯坦福大学的研究人员整理发布。内容:包含50,000条来自IMDb网站的电影评论。结构:每条评论都被清晰地标记为正面(Positive)或负面(Negative)。特点:数据量适中,情感两极分明,非常适合作为情感分类任务的入门和基准测试。2. 数据获取
我们通过Hugging Face的datasets库来获取数据。最初,我们尝试从网络直接下载,但考虑到国内网络环境的限制,我们最终采用了本地加载的方式。手动下载:我们从Hugging Face官网或其国内镜像,手动下载了数据集的parquet文件,并将其存放在项目根目录下的 imdb/plain_text/ 文件夹中。数据格式:下载的文件为.parquet格式,这是一种高效的列式存储格式,非常适合大规模数据处理。datasets库可以原生支持这种格式的读取。3. 数据结构概览
加载到程序中后,数据集主要包含两个核心字段:text:字符串类型,即电影评论的原文。label:整数类型,1 代表正面情感,0 代表负面情感。至此,我们已经拥有了高质量的“教材”,可以用来“教导”我们的模型了。第二步:模型训练 (代码核心:final_local_script.py)
目标:在一个强大的通用大模型基础上,微调出一个能精准判断电影评论情感的专用模型。1. 基础模型选择
我们没有从零开始,而是站在巨人的肩膀上,选择了一个优秀的预训练模型:distilbert-base-uncased。特点:这是一个轻量级的BERT模型,由Hugging Face蒸馏而来。它保留了BERT模型97%的性能,但体积更小,训练速度更快,非常适合学习和快速迭代。能力:它已经通过海量文本的预训练,掌握了丰富的英语语法、语义和基本常识,是一个聪明的“通才”。本地加载:同样为了避免网络问题,我们手动下载了模型的配置文件、权重文件和分词器文件,并将它们存放在 distilbert-base-uncased-local 文件夹中。2. 训练代码 (final_local_script.py) 核心逻辑拆解
训练脚本是整个项目的核心,其步骤如下:加载本地资源:脚本首先会从本地路径加载所有必需的资源:使用load_dataset("./imdb")加载数据集。使用AutoTokenizer.from_pretrained("./distilbert-base-uncased-local")加载分词器。使用AutoModelForSequenceClassification.from_pretrained(...)加载基础模型,并自动在其顶部添加一个用于二分类的“决策头”。使用evaluate.load("./metrics/accuracy.py")加载本地的评估脚本。数据预处理:分词 (Tokenization):使用加载好的tokenizer,将原始的文本评论(字符串)转换为模型能够理解的数字序列(Token IDs)。动态填充 (Padding):我们使用DataCollatorWithPadding,它可以在训练时自动将每个批次(batch)的数据填充到该批次内最长的句子长度,从而大大提高训练效率和减少内存占用。定义训练过程:TrainingArguments:这是一个配置中心,我们在这里定义了所有的训练超参数,例如:num_train_epochs=3:训练3个轮次。per_device_train_batch_size=16:每个批次处理16个样本。learning_rate=2e-5:学习率,控制模型参数更新的幅度。output_dir="./results":训练结果的保存目录。Trainer:这是Hugging Face提供的高度封装的训练器。我们将模型、训练参数、数据集、评估函数等所有组件交给它,它就能自动完成复杂的训练循环(前向传播、计算损失、反向传播、参数优化)。执行训练:调用trainer.train(),微调过程正式开始。在这个过程中,模型顶部的分类头被重点训练,而基础模型的参数则进行微小的调整,以更好地适应情感分析任务。保存成果:训练完成后,trainer.save_model("./sentiment_analyzer_model")会将我们微调好的、包含新权重的模型完整地保存在指定文件夹中。至此,我们就拥有了一个属于自己的、定制化的情感分析模型。第三步:模型测试与应用 (代码核心:test_app_tk.py)
目标:为我们训练好的模型创建一个图形用户界面(GUI),方便普通用户进行交互和测试。1. 技术选择
我们使用了Python内置的GUI库 Tkinter 来创建一个简单、稳定、跨平台的桌面应用程序。2. 测试代码 (test_app_tk.py) 核心逻辑拆解
这个脚本就是您在Canvas中看到的代码,它的工作流程如下:加载微调模型:程序启动时,它会使用Hugging Face的pipeline工具加载我们保存在 ./sentiment_analyzer_model 文件夹中的最终模型。后台加载:为了防止加载模型(可能需要几秒钟)时导致界面卡死,我们巧妙地使用了Python的threading库,将模型加载过程放在一个后台线程中执行,极大地提升了用户体验。创建GUI界面:代码使用tkinter和tkinter.ttk创建了一个主窗口。窗口内包含三个主要部分:一个用于用户输入文本的多行输入框 (ScrolledText),一个用于触发分析的按钮 (Button),以及一个用于显示结果的只读文本框。实现交互逻辑:analyze_sentiment函数是核心。当用户点击“分析情感”按钮时,这个函数会被调用。它会获取输入框中的文本,将其传递给我们加载好的sentiment_pipeline。pipeline会执行模型推理,并返回预测结果(如{'label': 'POSITIVE', 'score': 0.99})。函数最后会将这个结果格式化成一段通俗易懂的文字(例如:“情感倾向分析结果:【正面】😊”),并更新到结果显示框中。启动应用:最后,root.mainloop()启动了Tkinter的事件循环,使我们的桌面应用能够响应用户的操作。通过这三个步骤,我们完成了一个从理论到实践,从原始数据到最终可用产品的完整AI项目闭环。我们刚才训练的模型是一个情感分类器。它的核心作用是自动判断一段文本所表达的情感是积极的(Positive)还是消极的(Negative)。这是一个在真实世界中应用极其广泛的技术,例如:
-
舆情分析:自动分析社交媒体上(如微博、Twitter)用户对某个产品、事件或品牌的整体看法是正面还是负面。
-
产品评论分析:电商网站(如淘宝、亚马逊)可以利用它快速分析成千上万条用户评论,了解用户对商品的满意度,找到差评集中的问题点。
-
客户服务:智能客服系统可以实时分析用户输入的文字,如果检测到强烈的负面情绪,可以自动升级给人工客服优先处理,提升用户满意度。
-
内容审核:自动识别和过滤网络上的恶意评论或网络暴力言论。
当这个训练过程(进度条走完3个epoch)结束后,您就会在项目文件夹里得到一个专属于您的、经过微调的情感分析模型。它被保存在了 ./results 和 ./sentiment_analyzer_model 这两个文件夹里。
问题二:这个模型主要微调了什么东西?
这是一个非常棒的技术问题!为了方便理解,我们可以把一个大模型想象成两部分:一个巨大的**“语言理解核心”和一个小小的“任务决策头”**。
1. 添加了一个全新的“任务决策头” (Classification Head)
-
您在日志里看到这样一句话:
Some weights of DistilBertForSequenceClassification were not initialized... and are newly initialized: ['classifier.bias', 'classifier.weight', 'pre_classifier.bias', 'pre_classifier.weight'] -
这句日志是关键! 它告诉我们:当加载
distilbert-base-uncased这个“通才”模型时,为了让它能做“情感分类”这个具体任务,程序在它的顶部自动添加了一个全新的、小型的“决策头”。 -
这个“头”的结构很简单,它的唯一工作就是接收“语言核心”传递过来的深层理解,然后做出一个二选一的判断(0代表负面,1代表正面)。
-
因为是全新的,所以它的内部参数(权重)是随机的,完全不懂得如何分类。在微调过程中,这个“头”是学习和改变最剧烈的部分。
2. 对整个模型的参数(权重)进行了微小的调整
-
什么是权重? 您可以把模型的几千万个权重想象成大脑里的神经元连接强度,或者是收音机上亿万个微调旋钮。这些“旋钮”的组合决定了模型如何思考和决策。
-
微调过程是这样工作的:
-
我们从
imdb数据集中取一句话(比如一个好评)输入模型。 -
模型经过它当前的“旋钮”设置,做出一个预测(可能猜错了,猜成差评)。
-
我们拿模型的错误预测和正确答案(好评)进行对比,计算出“误差”。
-
根据这个“误差”,我们使用一种叫做“反向传播”的算法,把模型里所有的“旋钮”(包括“语言核心”和新建的“决策头”)都向着正确的方向微调一点点。
-
我们用成千上万个例子重复这个过程,每一次都微调一点点。
-
-
最终,新建的“决策头”的旋钮会从完全随机变得高度精确,而庞大的“语言核心”的旋钮只会在原有基础上发生非常细微的、适应性的变化,让它对“电影评论”这种文体的理解变得更敏锐。
这个训练出来后相当于这个通用的模型就能用于情感分析了,其实最主要的工作还是这个通用的模型才是最牛的,情感分析只是起了一个分析 好 坏 的情绪而已
1. “这个训练出来后相当于这个通用的模型就能用于情感分析了是吧”
是的。 微调(fine-tuning)就像是给一个全能的瑞士军刀(通用模型),安装上一个专门用来开红酒的开瓶器(情感分析功能)。军刀本身的多功能性和强大是基础,但经过这个小小的“加装”后,它就在一个特定任务上变得专业且高效。
2. “其实最主要的工作还是这个通用的模型才是最牛的”
您说的完全没错,这正是关键! 基础大模型(通用模型)的诞生,是整个AI领域革命性的突破。
-
投入巨大:它的预训练过程需要耗费天价的计算资源和海量的数据,是真正的“大力出奇迹”。
-
能力核心:它学习到了语言的语法、语义、逻辑、甚至一定程度的世界知识。没有这个强大的“大脑”,我们后续任何微调都无从谈起。