解析DB-GPT项目中三个 get_all_model_instances 方法的区别
1、manager.py中:
async def get_all_model_instances(self, worker_type: str, healthy_only: bool = True) -> List[WorkerRunData]:instances = list(itertools.chain(*self.workers.values()))result = []for instance in instances:name, wt = WorkerType.parse_worker_key(instance.worker_key)if wt != worker_type or (healthy_only and instance.stopped):continueresult.append(instance)return result
2、remote_manager.py中:
async def get_all_model_instances(self, worker_type: str, healthy_only: bool = True) -> List[WorkerRunData]:instances: List[ModelInstance] = await self.model_registry.get_all_model_instances(healthy_only=healthy_only)result = []for instance in instances:name, wt = WorkerType.parse_worker_key(instance.model_name)if wt != worker_type:continueresult.append(self._build_single_worker_instance(name, instance))return result
3、registry.py中:
async def get_all_model_instances(self, healthy_only: bool = False) -> List[ModelInstance]:instances = list(itertools.chain(*self.registry.values()))if healthy_only:instances = [ins for ins in instances if ins.healthy == True]return instances核心区别总结表
| 特性 | manager.py 中的方法 | remote_manager.py 中的方法 | registry.py 中的方法 |
|---|---|---|---|
| 所属类 | WorkerManager | RemoteWorkerManager | ModelRegistry |
| 职责层级 | 本地 Worker 管理 | 远程/全局 Worker 管理 | 模型实例 存储与状态管理 |
| 数据来源 | 本地内存字典 self.workers | 远程注册中心 self.model_registry | 本地内存字典 self.registry |
| 核心操作 | 遍历并过滤本地 Worker 列表 | 1. 从注册中心获取实例 2. 转换为 Worker 格式 | 遍历并过滤注册中心里的实例列表 |
| 过滤条件 | 1. worker_type 匹配2. healthy_only 时检查 instance.stopped | 1. worker_type 匹配2. healthy_only 参数传递给注册中心 | 仅根据 healthy_only 过滤健康状态 |
| 返回数据类型 | List[WorkerRunData] | List[WorkerRunData] | List[ModelInstance] |
| 应用场景 | 在单个进程内管理和调度其创建的 Worker | 在控制器或管理器节点上,发现和调度集群内所有节点的 Worker | 作为底层存储,被 RemoteWorkerManager 调用,提供最基础的实例数据 |
详细解析
1. manager.py 中的 get_all_model_instances (属于 WorkerManager 类)
职责:本地管理。这个方法管理的是当前进程(或节点)内部启动和维护的所有 Worker 实例。
数据来源:
self.workers。这是一个本地字典,键是模型名称,值是该模型对应的所有WorkerRunData对象的列表。这些数据是在本地启动 Worker 时被添加进来的。逻辑:
将
self.workers中所有值的列表扁平化,得到所有本地 Worker 实例。遍历每个实例,解析其
worker_key以获得其工作类型 (wt)。进行过滤:工作类型必须匹配传入的
worker_type;如果healthy_only为True,则跳过已停止 (instance.stopped) 的实例。
特点:它的视野仅限于本进程,不知道其他机器或进程上的 Worker。它操作的对象是
WorkerRunData,其中包含了进程控制、通信地址等运行时信息。
2. remote_manager.py 中的 get_all_model_instances (属于 RemoteWorkerManager 类)
职责:远程/全局管理。这个方法用于在分布式环境中,从一个中心式的注册中心(如数据库、Redis等)发现和管理所有节点上注册的模型实例。
数据来源:
self.model_registry.get_all_model_instances(...)。它调用的是第三个方法(在registry.py中),从注册中心获取数据。逻辑:
委托调用:首先调用底层的
ModelRegistry的方法,获取全局的ModelInstance列表。healthy_only参数在这里被传递给注册中心。数据转换与过滤:遍历从注册中心返回的每个
ModelInstance对象。解析
model_name字段以获得工作类型 (wt)。过滤掉工作类型不匹配的实例。
将符合条件的
ModelInstance转换为WorkerRunData(通过_build_single_worker_instance方法)。这一步是关键,它把存储层的静态信息转换成了管理层的运行时信息(例如,生成用于远程调用的地址)。
特点:它具有全局视野,能够获取集群中所有健康且注册了的模型实例。它是分布式调度和负载均衡的基础。
3. registry.py 中的 get_all_model_instances (属于 ModelRegistry 类)
职责:持久化存储管理。这是最底层的方法,负责模型实例信息的增删改查,与具体的存储后端(如内存、数据库)交互。
数据来源:
self.registry。在这个具体的实现中,它是一个内存字典。但在生产环境中,这很可能被替换为连接数据库或其他分布式存储的代码。逻辑:
将注册表
self.registry中所有值的列表扁平化,得到所有已注册的ModelInstance。如果
healthy_only为True,则过滤出healthy == True的实例。
特点:它非常基础和通用。它不关心 Worker 的类型(LLM, text2vec, embedding等),只关心实例的存在性和健康状态。它返回的是
ModelInstance对象,这些对象主要包含模型的基本元数据和状态(如模型名称、主机地址、端口、是否健康等),而不包含进程控制等运行时信息。
调用关系与工作流程
一个典型的分布式场景工作流程可以清晰地展示三者的关系和区别:
Worker 启动:在某台机器上,一个进程启动了一个 LLM Worker。
本地注册:该进程的
WorkerManager会将这个 Worker 的信息(WorkerRunData)添加到自己的self.workers字典中。(方法1的数据来源)全局注册:同时,该进程会将自己的信息注册到中心的
ModelRegistry(例如,注册到数据库里一条记录:“LLM-model-x, 192.168.1.10:8000, healthy”)。(方法3管理的数据)全局发现:在调度器节点上,
RemoteWorkerManager需要找一个可用的 LLM Worker。它会调用自己的get_all_model_instances(方法2)。查询注册中心:方法2内部会调用
model_registry.get_all_model_instances(healthy_only=True)(方法3),从数据库查询所有健康的实例。过滤与转换:方法2拿到这些
ModelInstance后,过滤出类型为 “LLM” 的,并将每个实例转换为WorkerRunData(例如,根据ModelInstance的host和port生成一个 gRPC 或 HTTP 的访问地址)。调度:
RemoteWorkerManager现在得到了一个全局可用的、健康的 LLM Worker 列表(List[WorkerRunData]),然后就可以根据负载均衡策略选择一个进行任务调度。
总结
简单来说,这三个方法是自上而下、从具体到抽象的关系:
manager.py:管自己家的活的进程(运行时信息)。registry.py:是一个电话簿,记录着所有人的联系方式和当前是否可联系(静态信息)。remote_manager.py:是总调度员,它查阅电话簿,找出所有能联系上且符合要求的人,然后开始打电话分配任务(连接静态信息与运行时需求)。
它们共同协作,使得 DB-GPT 项目既能在单机模式下高效运行,也能轻松扩展到分布式集群模式。
_________________________________________________________________________
为了更直观地理解 remote_manager.py 中方法所服务的分布式环境,构建一个具体的示例场景。
分布式环境示例:AI模型服务集群
假设我们有一个名为 "智算中心" 的平台,它使用 DB-GPT 项目来部署和管理多个大语言模型(LLM),为内部多个产品(如智能客服、代码助手、文档分析)提供AI能力。
1. 物理架构(硬件与节点)
我们的集群由多台物理服务器(或虚拟机/容器)组成,它们位于同一个机房或网络中:
管理节点 (Master Node) - 1台服务器
主机名:
master.ai-internal.com运行服务: 控制器(Controller)、注册中心(Registry)、Web API网关。
职责:不运行具体的模型,只负责全局管理、调度、接收外部请求并将其路由到合适的Worker节点。
Worker节点 (Worker Nodes) - 多台高性能服务器(例如4台)
主机名:
gpu-server-01.ai-internal.com到gpu-server-04.ai-internal.com每台服务器都配备了多张高性能GPU(如A100)。
职责:在这些节点上真正地加载和运行AI模型,执行推理任务。
2. 软件部署与角色(软件与逻辑)
现在,我们在这些硬件上部署 DB-GPT 的组件:
在
master节点上:运行着
RemoteWorkerManager和ModelRegistry的实例。ModelRegistry使用一个 Redis 或 MySQL 数据库作为后端,而不是简单的内存字典,这样所有节点都能访问到统一的注册信息。
在每个
gpu-server-0x节点上:都运行着一个
WorkerManager实例。根据每台服务器的GPU内存大小,
WorkerManager启动了不同数量和类型的模型Worker。gpu-server-01: 运行了 1个
LLMWorker (模型:vicuna-13b)gpu-server-02: 运行了 2个
LLMWorker (模型:llama2-7b,codellama-34b)gpu-server-03: 运行了 1个
EmbeddingWorker (模型:bge-large) 和 1个LLMWorker (模型:chatglm3-6b)gpu-server-04: 运行了 1个
RerankWorker (模型:bge-reranker)
注册过程(心跳机制):
每个节点上的
WorkerManager在启动一个Worker后,会立即向master节点上的ModelRegistry进行注册:“嗨,我在gpu-server-01:8000,提供了一个vicuna-13b模型,类型是LLM,我现在是健康的”。之后,它会定期(比如每10秒)发送一次心跳,告诉注册中心:“我还活着,依然健康”。如果注册中心长时间收不到某个Worker的心跳,就会将其标记为不健康。
3. 动态流程图:一次用户请求的旅程
现在,一个用户通过“智能客服”产品提问了:“你们公司的退货政策是什么?”
图表
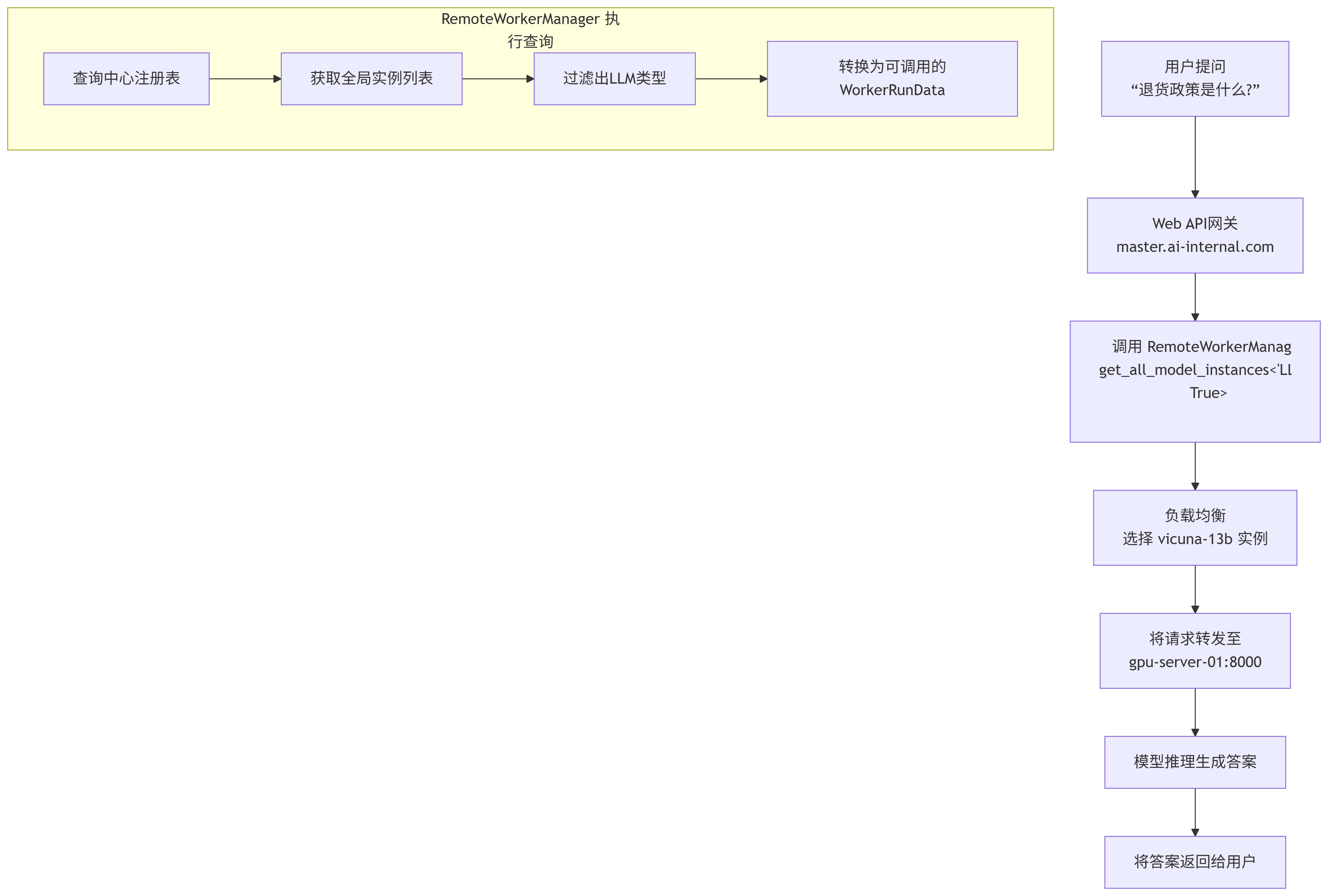
4. 关键点与 remote_manager.py 方法的价值
在这个分布式示例中,RemoteWorkerManager.get_all_model_instances() 方法的核心价值得以体现:
全局视角 (Global View):
管理节点上的
RemoteWorkerManager对集群了如指掌。它知道gpu-server-01上有 Vicuna,gpu-server-02上有 Llama2 和 CodeLlama,等等。任何一个节点上的
WorkerManager(方法1)都不具备这个全局视角,它只知道自家节点上的事。
解耦 (Decoupling):
调度者(
RemoteWorkerManager)和执行者(各个WorkerManager)是分离的。调度者不需要关心Worker在哪台机器上,只需要知道它的地址和状态。这使得集群可以轻松地扩缩容(增加或减少Worker节点)。
弹性与高可用 (Resilience & High Availability):
如果
gpu-server-01突然宕机了,它的心跳会超时。ModelRegistry会将其上所有Worker标记为不健康。当下一个请求来时,
RemoteWorkerManager.get_all_model_instances(healthy_only=True)就自动过滤掉这个宕机的节点,转而将请求路由到其他健康的LLM Worker(比如gpu-server-02上的llama2-7b)。从用户角度看,服务没有中断,只是可能响应速度稍有变化。
负载均衡 (Load Balancing):
拥有了所有健康实例的列表,
RemoteWorkerManager就可以在此基础上实现复杂的负载均衡策略(如轮询、选择负载最低的节点等),避免所有请求都打到同一个模型实例上。
总结
这个分布式环境示例展示了一个由中心调度器(运行 remote_manager.py 逻辑)和多个分布式执行器(运行 manager.py 逻辑)组成的集群。RemoteWorkerManager.get_all_model_instances() 方法是这个架构的核心枢纽,它通过查询中心注册表(registry.py 逻辑)来获取全局状态,从而使得智能、弹性的调度成为可能。