CVPR小模型创新点深度分析:小VLM化身精准向导,大模型多模态推理效率全面加速,性能突破不再依赖算力堆叠
关注gongzhonghao【CVPR顶会精选】
1.导读
1.1 论文基本信息
论文标题:《A Stitch in Time Saves Nine: Small VLM is a Precise Guidance for Accelerating Large VLMs》
作者:Wangbo Zhao, Yizeng Han, Jiasheng Tang, Kai Wang, Zhikai Li, Yibing Song, Zhangyang Wang, Yang You
作者单位:新加坡国立大学、阿里巴巴达摩院、湖畔实验室、德克萨斯大学奥斯汀分校
发表会议:CVPR (IEEE/CVF Conference on Computer Vision and Pattern Recognition)
论文链接:https://arxiv.org/html/2412.03324v1
图灵学术科研辅导
2.论文概述
2.1 核心问题
随着大型语言模型的成功,视觉语言模型已成为研究热点,并在各类多模态任务中展现出卓越的能力。然而,这些模型在处理图像时,会产生大量的视觉令牌,给推理过程带来了巨大的计算开销和效率挑战
本文针对大型VLM的推理效率问题,提出了一种名为SGL的创新性、免训练的加速框架。该框架的核心思想是利用一个小型VLM来指导和加速一个大型VLM的推理过程。
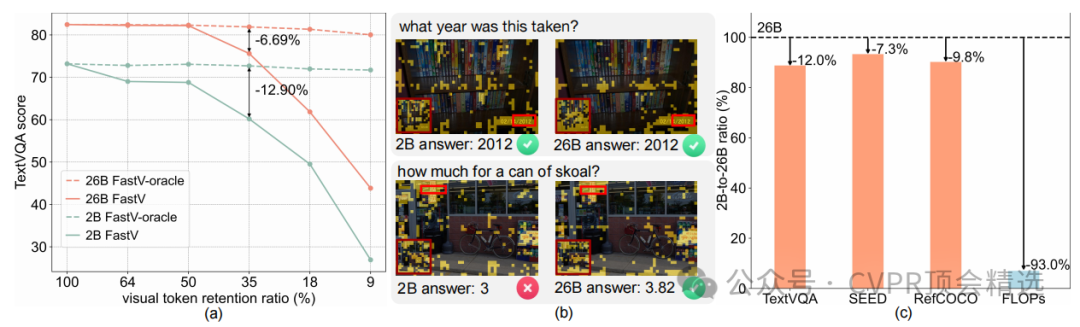
2.2 实证研究发现了三个关键洞见
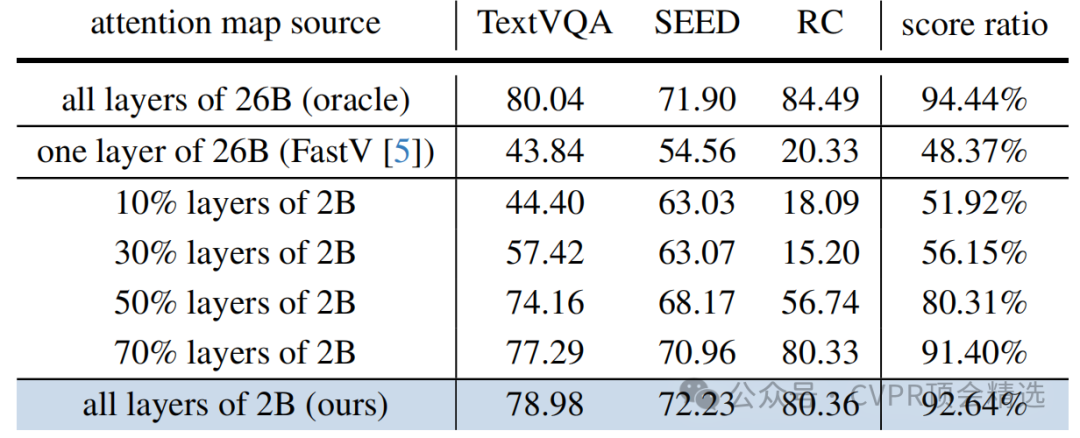
局部信息不足:仅使用大型VLM特定单层的注意力图等局部信息来剪枝视觉令牌,在剪枝率较高时性能会急剧下降,无法准确识别关键视觉信息。
全局信息有效但昂贵:聚合大型VLM所有层的注意力图可以非常精确地识别重要令牌,即使在极高的剪枝率下也能保持优异性能。但获取这种全局信息需要完整的推理前向传播,计算成本高昂,不具备实用性。
小模型的近似性:研究发现,小型VLM的全局注意力图与大型VLM的全局注意力图高度相似,这为寻找一种低成本且高效的指导信号提供了可能。
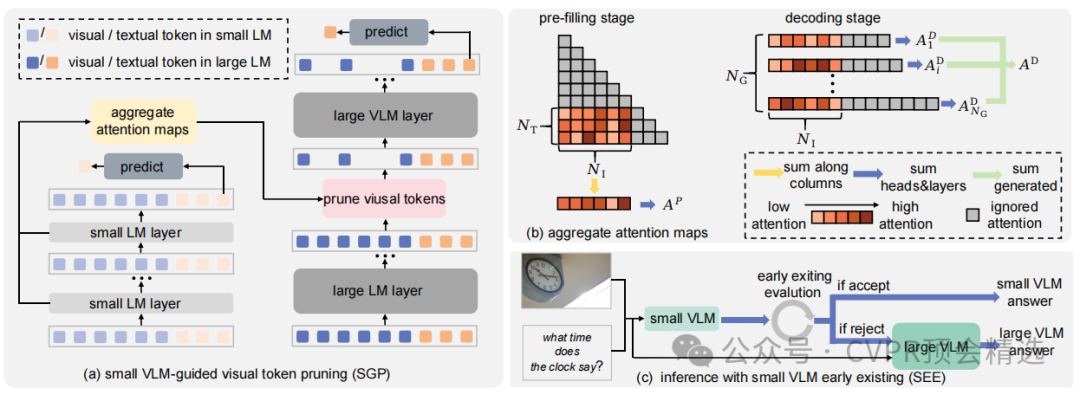
2.3
SGL框架包含两个核心技术
SGP:首先通过小型VLM进行一次完整的推理,并聚合其所有层的注意力图,以此计算出各个视觉令牌的重要性得分。然后,利用这个得分排序来指导大型VLM,在其中剪除大量不重要的视觉令牌,从而在保留关键信息的同时,显著降低计算负荷 。
SEE:对于那些“简单”的输入,如果小型VLM的回答置信度足够高,则直接采纳其结果,终止整个推理流程,完全跳过大型VLM的调用,进一步提升效率。
3.研究背景及相关工作
3.1 VLM的计算开销问题
现代主流的VLM,如LLaVa, InternVL, Qwen-VL等,通常采用“视觉编码器+大型语言模型”的架构。图像通过视觉编码器被转换为一系列视觉令牌,然后与文本令牌一同送入语言模型进行处理 。
3.2 视觉令牌压缩的相关工作
需要训练的方法:这类方法通常通过引入新的模块或设计新的训练目标来压缩信息。例如,Q-Former使用一组可学习的查询向量来浓缩视觉信息;令牌蒸馏和参数对齐等方法也属于此类。它们的共同缺点是需要额外的训练开销 。
免训练的方法:(1)ToMe等方法在视觉编码器内部合并相似的令牌,但这可能忽略了后续语言模型处理中重要的图文交互信息 。(2)令牌剪枝:利用语言模型中特定层的注意力图来评估视觉令牌的重要性,并剪除得分较低的令牌。然而,本文通过实验证明,仅依赖单层注意力图的局部信息是次优的,尤其在高剪枝率下性能损失严重。该研究指出,虽然聚合所有层的注意力图效果最好,但其高昂的计算成本使其不切实际。
3.3 模型置信度估计的相关工作
评估模型的预测置信度对于构建可靠的人工智能系统至关重要。对于大型语言模型,已有多种方法用于估计生成文本的置信度,例如基于信息论的方法、集成方法或自反思方法。
在实际应用中,高置信度的预测可以直接采纳,而低置信度的内容则可以交由更强大的模型或人工进行复核。本文提出的SEE机制便借鉴了这一思想,通过评估小型VLM的输出置信度来决定是否需要调用计算成本更高的大型VLM,从而实现计算资源的动态分配。
4.实验设计和方法
4.1 小型VLM指导的视觉令牌剪枝
1.在小型VLM中聚合全局注意力图:首先,将输入的图像和文本提示送入小型VLM,收集并聚合所有 Transformer 层的注意力权重,以计算每个视觉令牌的重要性得分。随后,这个聚合过程分为两个阶段:预填充阶段、解码阶段。最终,将预填充阶段和解码阶段的注意力得分相加,得到每个视觉令牌的最终重要性得分A 。这个得分全面地衡量了视觉令牌与输入问题和生成答案的关联程度。
2.在大型VLM中进行剪枝:使用上一步从小型VLM中获得的重要性得分,A,对视觉令牌进行排序。将相同的图像和文本输入大型VLM,在其网络的一个较早的中间层,根据之前的排序,只保留重要性排名前 R% 的视觉令牌,其余的则被丢弃。最后,由于剪枝发生在较早的层,后续所有层的计算量都将大幅减少,从而实现显著的推理加速
4.2 SEE:小型VLM的早期退出机制
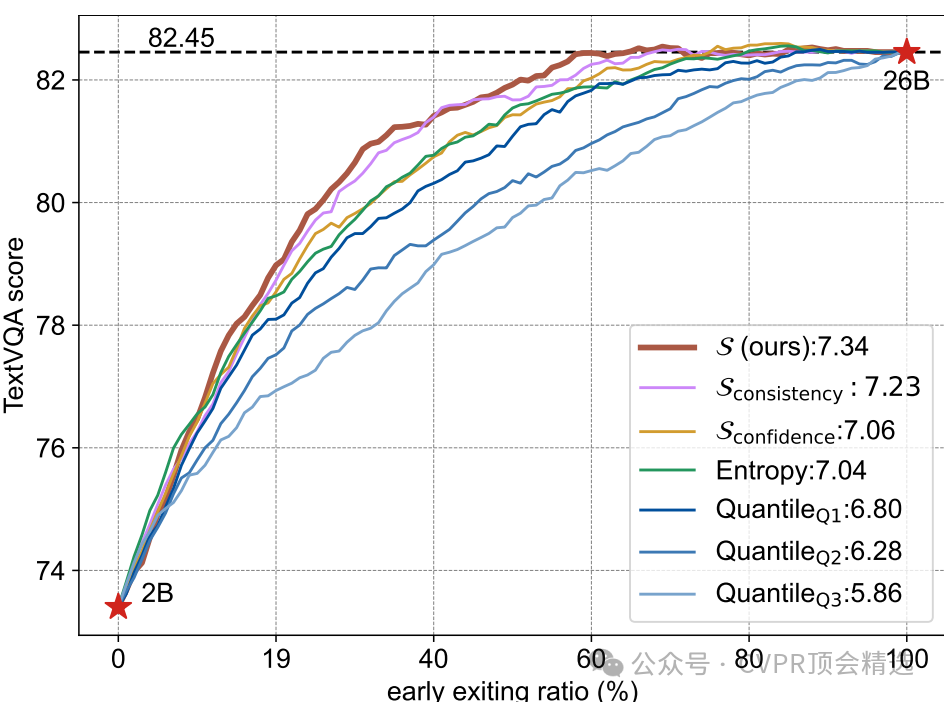
决策标准:1.置信度分数,基于生成答案的序列概率计算得出,并进行长度归一化。这是一种衡量模型对其输出“自信”程度的直接方法。2.一致性分数,其基本假设是:如果小型VLM能够给出正确答案,那么它应该已经准确识别了关键的视觉令牌。因此,使用由SGP识别出的重要令牌子集再次在小型VLM中计算原始答案的生成概率。如果这个概率很高,说明模型在信息大量删减后依然能稳定生成相同的答案,即具有很高的一致性,也间接证明了其回答的可靠性。该分数的计算非常高效,因为使用了极高剪枝率的令牌,并且可以并行计算。
执行流程:计算出最终决策分数S后,将其与一个预设的阈值进行比较。如果分数高于阈值,则认为小型VLM的回答可靠,直接输出其结果并终止流程;否则,才继续调用大型VLM。

4.3 实验设置
基准测试:视觉问答、视觉定位、综合多模态理解
对比方法:主要与两种代表性的免训练加速方法进行比较:ToMe和FastV(基于单层注意力的令牌剪枝)。
图灵学术科研辅导
5. 实验结果分析
5.1 SGP方法的有效性验证
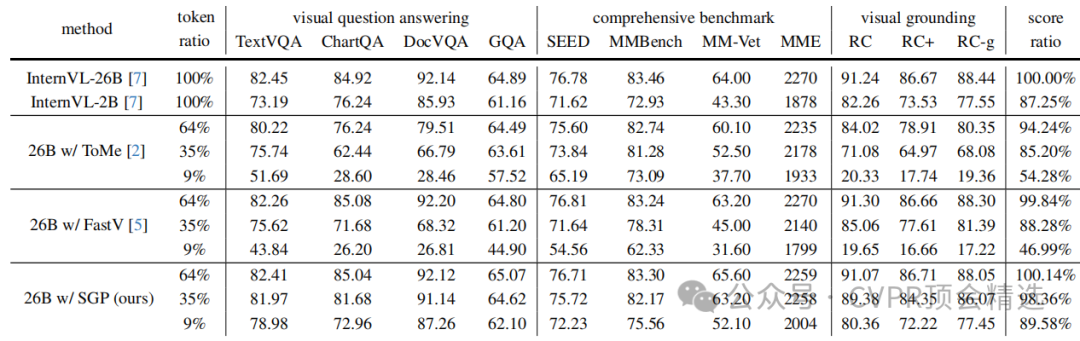
在不使用SEE机制的情况下,研究者首先将SGP与FastV和ToMe在不同视觉令牌保留率(64%、35%、9%)下进行了对比。
高保留率(64%):所有方法性能都与原始的InternVL-26B模型相当。这表明VLM中确实存在大量的视觉信息冗余,剪枝是可行且必要的。
中等保留率(35%):FastV和ToMe的性能开始出现明显下降,尤其是在需要精细视觉理解的OCR相关任务和视觉定位任务上。相比之下,SGP在所有任务上几乎没有性能损失,维持了极具竞争力的表现。
极低保留率(9%):FastV和ToMe的性能全面崩溃,因为它们无法准确保留关键的视觉令牌。而SGP在如此极限的剪枝率下,依然能保持原始模型约89.58%的综合性能,表现出惊人的鲁棒性。这充分证明了利用小型VLM的全局注意力图作为指导信号的优越性。
5.2 SGP方法的有效性验证
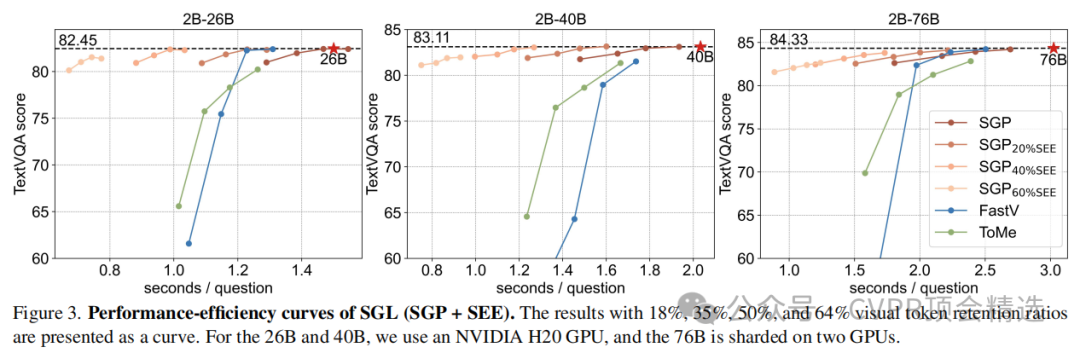
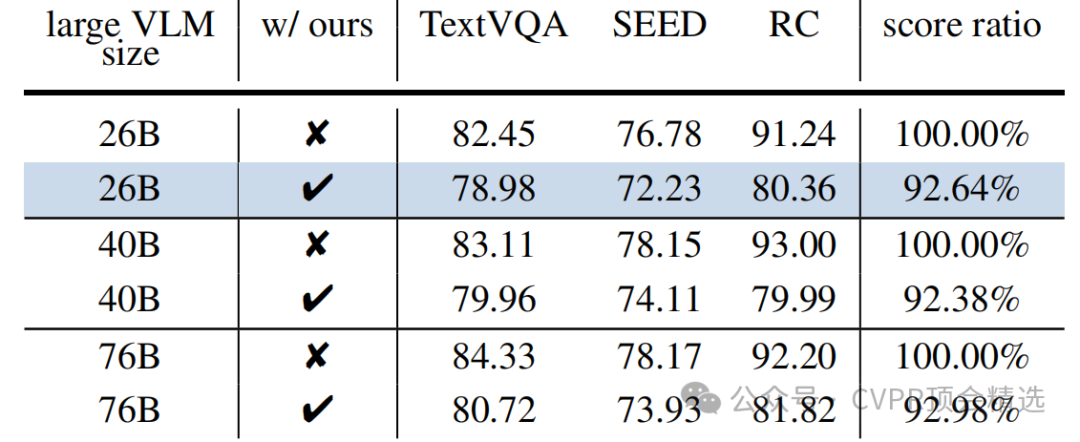
开销分析:在不使用SEE时,由于引入了小型VLM的额外计算,SGP在处理26B模型时比FastV和ToMe稍慢。但当目标大型VLM的尺寸增加到40B和76B时,小型VLM的开销占比减小,SGP的速度变得具有竞争力,同时性能优势更加凸显。
SEE的作用:引入SEE后,通过设置不同的早期退出率,SGL能够在几乎不损失性能的前提下,大幅缩短平均推理时间。
5.3 泛化能力分析
对不同尺寸模型的泛化:实验证明,SGL框架对于不同尺寸的小型和大型VLM均具有良好的适应性。
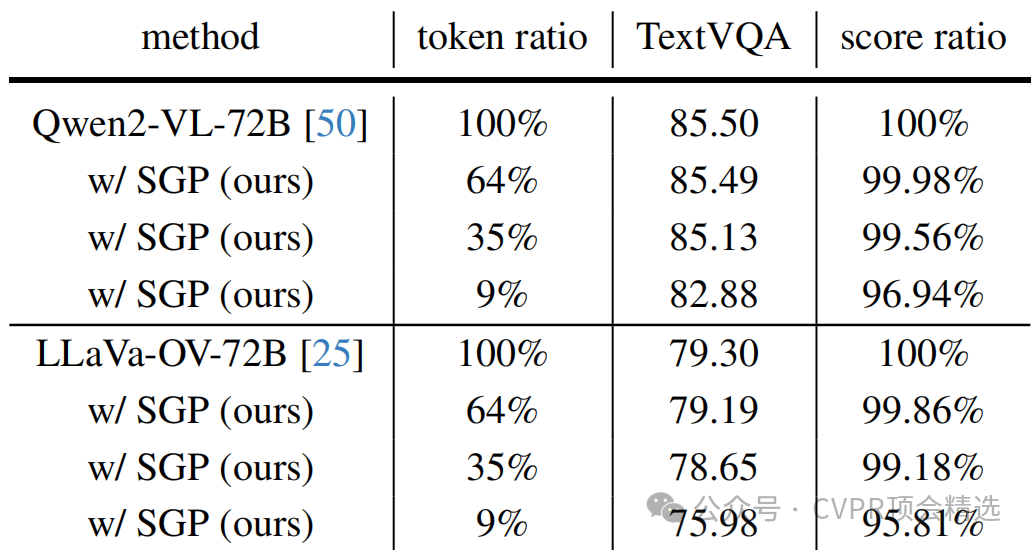
对不同架构模型的泛化:SGL被成功应用于Qwen2-VL和LLaVa-OV模型族。使用各自系列中的小型模型指导大型模型,在9%的极低令牌保留率下,依然能保持约96%的原始性能。这充分说明SGL是一个与模型架构无关的通用加速框架。
6.论文总结
本文针对大型VLM推理效率问题,提出了免训练的SGL框架。研究发现,小型VLM的全局注意力图可作为大型VLM的精确替代品,优于依赖局部信息的方法。其核心SGP方法利用该洞见指导剪枝,在高剪枝率下仍能保持强大性能。结合SEE提前退出机制,框架可在“简单”任务上采纳小模型预测,实现性能与效率的平衡。该方法的有效性与泛化性已在11个基准及多种模型上得到全面验证。