理解AI智能体:智能体记忆
想象一下,和一个会忘记你说过的每一句话的朋友交谈。每次对话都从零开始。没有记忆,没有上下文,没有进展。这会让人感到尴尬、疲惫且缺乏人情味。不幸的是,这正是当今大多数 AI 系统的行为方式。它们很聪明,没错,但它们缺乏一些关键的东西:记忆。
让我们首先谈谈记忆在 AI 中的真正含义以及它为何重要。
1. 引言
1.1 当今 AI 中记忆的假象
像 ChatGPT 或编程助手这样的工具感觉很有用,直到你发现自己一次又一次地重复指令或偏好。要构建能够学习、演进和协作的智能体,真正的记忆不仅有益——而且至关重要。
由上下文窗口和巧妙的提示工程所创造出的这种记忆假象,让许多人相信智能体已经能够“记住”。实际上,当今大多数智能体都是无状态的,无法从过去的交互中学习或随着时间适应。
要从无状态工具转变为真正智能、自主(有状态)的智能体,我们需要赋予它们记忆,而不仅仅是更大的提示或更好的检索。
1.2 AI 智能体中的记忆指的是什么?
在 AI 智能体的上下文中,记忆是指跨时间、跨任务、跨多次用户交互保留和回忆相关信息的能力。它允许智能体记住过去发生的事情,并利用这些信息来改进未来的行为。
记忆不仅仅是存储聊天记录或在提示中填入更多令牌(tokens)。它是关于构建一个持久的内部状态,这个状态会演进并为智能体的每一次交互提供信息,即使是相隔数周或数月。
定义智能体记忆的三个支柱:
- 状态 (State):知道当前正在发生什么
- 持久性 (Persistence):跨会话保留知识
- 选择性 (Selection):决定什么值得记住
这三者共同实现了我们从未有过的东西:连续性。
1.3 记忆如何融入智能体技术栈
让我们将记忆置于现代智能体的架构中。典型组件包括:
- 用于推理和答案生成的 LLM(大语言模型)
- 策略或规划器(例如 ReAct、AutoGPT 风格)
- 对工具/API 的访问
- 用于获取文档或过去数据的检索器
问题在于:这些组件都不记得昨天发生了什么。没有内部状态。没有演进的理解。没有记忆。
1.4 上下文窗口 ≠ 记忆
一个常见的误解是,大的上下文窗口将消除对记忆的需求。
但由于某些限制,这种方法存在不足。调用带有更多上下文的 LLM 的一个主要缺点是它们可能:
- 昂贵:更多令牌 = 更高成本和延迟
- 分散注意力:无关上下文会降低性能(“中间迷失”问题)
- 短暂:上下文在会话结束后消失
上下文窗口帮助智能体在单个会话内保持一致。记忆则允许智能体跨会话保持智能。即使上下文长度达到 10 万个令牌,缺乏持久性、优先级和显著性也使其不足以实现真正的智能。
1.5 为什么 RAG 与记忆不同
虽然 RAG(检索增强生成)和记忆系统都检索信息来支持 LLM,但它们解决的是非常不同的问题。
- RAG 在推理时将外部知识引入提示中。它对于用文档中的事实来支撑回答很有用。
- 但 RAG 本质上是无状态的——它不知道之前的交互、用户身份,或者当前查询与过去对话的关系。
另一方面,记忆带来了连续性。它捕获用户偏好、过去的查询、决策和失败,并使它们在未来的交互中可用。
可以这样想:
- RAG 帮助智能体更好地回答问题。
- 记忆 帮助智能体更智能地行事。
两者都需要——RAG 为 LLM 提供信息,记忆塑造其行为。
2. 智能体中的记忆类型
在基础层面,AI 智能体中的记忆有两种形式:
- 短期记忆:在单次交互中保存即时上下文。
- 长期记忆:跨会话、任务和时间持久保存知识。
就像人类一样,这些记忆类型服务于不同的认知功能。短期记忆帮助智能体在当下保持连贯。长期记忆帮助它学习、个性化适应。
👉 简单的经验法则:
- 短期记忆 = AI 在与你交谈时“现在记得”的内容。
- 长期记忆 = AI 在多次对话后“学习并后来回忆”的内容。
2.1 短期记忆(或工作记忆)
AI 系统中最基本的记忆形式保存即时上下文——就像一个人记得刚才对话中说了什么。这包括:
- 对话历史:近期的消息及其顺序
- 工作记忆:临时变量和状态
- 注意力上下文:对话当前的焦点
2.2 长期记忆
更复杂的 AI 应用实现了长期记忆,以在多次对话中保留信息。
这包括:
2.2.1 程序性记忆
定义你的智能体知道要做什么,直接编码在你的代码中。从简单的模板到复杂的推理流程——这是你的逻辑层。
这是你智能体的“肌肉记忆”——变成自动行为的习得行为。就像你打字时不会有意思考每个击键一样,你的智能体会内化一些过程,比如“总是优先处理关于 API 文档的电子邮件”或“在回答技术问题时使用更有帮助的语气”。
2.2.2 情景记忆(示例)
用户特定的过去交互和经历。它实现了连续性、个性化和随时间学习的能力。
这就是你智能体的“记忆相册”——它存储着过去事件与互动的具体记忆。就像你可能清楚记得听到重要新闻时自己身在何处,你的智能体也会记住:“上次这位客户发邮件请求延期时,我的回复过于生硬,导致了沟通摩擦”,或者“当邮件中出现‘简单问一下’这种短语时,往往需要提供详细的技术解释,结果根本不‘简单’。”
2.2.3 语义记忆(事实)
通过向量搜索或 RAG 检索到的事实性世界知识。
这是你智能体的“百科全书”——它学到的关于你的世界的事实。就像你知道巴黎是法国的首都,而不记得具体是在何时何地学到的一样,你的智能体会记住“Alice 是 API 文档的联络人”或“John 更喜欢早上的会议”。这是独立于特定经历而存在的知识。

3. 管理记忆
许多 AI 应用需要记忆来在多次交互间共享上下文。LangGraph 支持两种对构建对话智能体至关重要的记忆类型:
- 短期记忆
- 长期记忆
启用短期记忆后,长对话可能会超过 LLM 的上下文窗口。常见的解决方案是:
- 修剪 (Trimming)
- 摘要 (Summarization)
- 从 LangGraph 状态中永久删除消息
- 自定义策略(例如,消息过滤等)
这使得智能体能够跟踪对话而不会超出 LLM 的上下文窗口。
4. 写入记忆
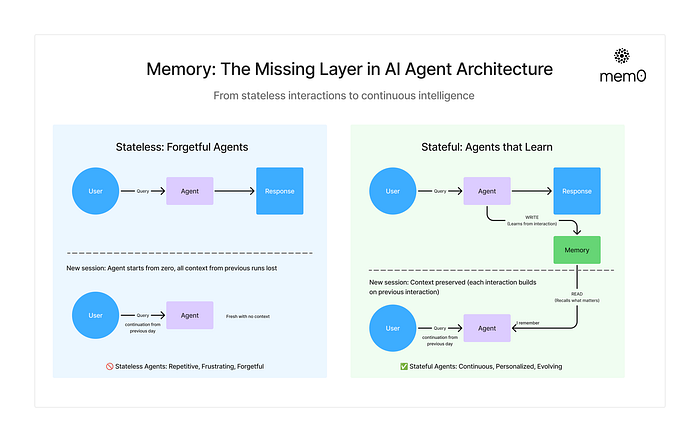
虽然人类经常在睡眠中形成长期记忆,但 AI 智能体需要不同的方法。智能体应该在何时以及如何创建新的记忆?智能体写入记忆至少有两种主要方法:“在热路径(hot path)上”和“在后台”。
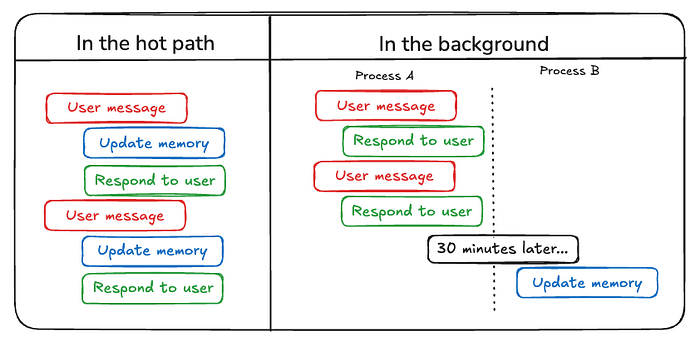
4.1 在热路径(hot path)上写入记忆
在运行时创建记忆既有优点也有挑战。积极的一面是,这种方法允许实时更新,使新记忆立即可用于后续交互。它还实现了透明度,因为可以在创建和存储记忆时通知用户。
例如,ChatGPT 使用一个 save_memories 工具来更新插入(upsert)作为内容字符串的记忆,并根据每个用户消息决定是否以及如何使用此工具。
4.2 在后台写入记忆
作为单独的后台任务创建记忆有几个优点。它消除了主应用程序中的延迟,将应用程序逻辑与内存管理分开,并允许智能体更专注地完成任务。这种方法还提供了在时间上灵活安排记忆创建以避免冗余工作的能力。
5. 添加短期记忆
短期记忆(线程级持久性)使智能体能够跟踪多轮对话。
添加短期记忆:
from langchain.chat_models import init_chat_model
from langgraph.graph import StateGraph, MessagesState, STARTfrom langgraph.checkpoint.memory import InMemorySavermodel = init_chat_model(model="anthropic:claude-3-5-haiku-latest")def call_model(state: MessagesState):response = model.invoke(state["messages"])return {"messages": response}builder = StateGraph(MessagesState)
builder.add_node(call_model)
builder.add_edge(START, "call_model")checkpointer = InMemorySaver()
graph = builder.compile(checkpointer=checkpointer)config = {"configurable": {"thread_id": "1"}
}for chunk in graph.stream({"messages": [{"role": "user", "content": "hi! I'm bob"}]},config,stream_mode="values",
):chunk["messages"][-1].pretty_print()for chunk in graph.stream({"messages": [{"role": "user", "content": "what's my name?"}]},config,stream_mode="values",
):chunk["messages"][-1].pretty_print()
================================ Human Message =================================hi! I'm bob
================================== Ai Message ==================================Hi Bob! How are you doing today? Is there anything I can help you with?
================================ Human Message =================================what's my name?
================================== Ai Message ==================================Your name is Bob.
5.1 在生产环境中
在生产环境中,你会希望使用由数据库支持的检查点器:
示例:使用 MongoDBSaver 实现持久化检查点
要使用 MongoDB 检查点器,你需要一个 MongoDB 集群。如果还没有,请遵循此指南创建一个集群。
pip install -U pymongo langgraph langgraph-checkpoint-mongodbfrom langchain.chat_models import init_chat_model
from langgraph.graph import StateGraph, MessagesState, START
from langgraph.checkpoint.mongodb import MongoDBSavermodel = init_chat_model(model="anthropic:claude-3-5-haiku-latest")DB_URI = "localhost:27017"
with MongoDBSaver.from_conn_string(DB_URI) as checkpointer:def call_model(state: MessagesState):response = model.invoke(state["messages"])return {"messages": response}builder = StateGraph(MessagesState)builder.add_node(call_model)builder.add_edge(START, "call_model")graph = builder.compile(checkpointer=checkpointer)config = {"configurable": {"thread_id": "1"}}for chunk in graph.stream({"messages": [{"role": "user", "content": "hi! I'm bob"}]},config,stream_mode="values"):chunk["messages"][-1].pretty_print()for chunk in graph.stream({"messages": [{"role": "user", "content": "what's my name?"}]},config,stream_mode="values"):chunk["messages"][-1].pretty_print()
5.2 使用子图
如果你的图包含子图,只需在编译父图时提供检查点器。LangGraph 会自动将检查点器传播到子子图。
from langgraph.graph import START, StateGraph
from langgraph.checkpoint.memory import InMemorySaver
from typing import TypedDictclass State(TypedDict):foo: str# Subgraphdef subgraph_node_1(state: State):return {"foo": state["foo"] + "bar"}subgraph_builder = StateGraph(State)
subgraph_builder.add_node(subgraph_node_1)
subgraph_builder.add_edge(START, "subgraph_node_1")
subgraph = subgraph_builder.compile()# Parent graphdef node_1(state: State):return {"foo": "hi! " + state["foo"]}builder = StateGraph(State)
builder.add_node("node_1", subgraph)
builder.add_edge(START, "node_1")checkpointer = InMemorySaver()
graph = builder.compile(checkpointer=checkpointer)
5.3 管理检查点
你可以查看和删除检查点器存储的信息:
查看线程状态(检查点)
config = {"configurable": {"thread_id": "1",# optionally provide an ID for a specific checkpoint,# otherwise the latest checkpoint is shown# "checkpoint_id": "1f029ca3-1f5b-6704-8004-820c16b69a5a"}
}
graph.get_state(config)
StateSnapshot(values={'messages': [HumanMessage(content="hi! I'm bob"), AIMessage(content='Hi Bob! How are you doing today?), HumanMessage(content="what's my name?"), AIMessage(content='Your name is Bob.')]}, next=(), config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f029ca3-1f5b-6704-8004-820c16b69a5a'}},metadata={'source': 'loop','writes': {'call_model': {'messages': AIMessage(content='Your name is Bob.')}},'step': 4,'parents': {},'thread_id': '1'},created_at='2025-05-05T16:01:24.680462+00:00',parent_config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f029ca3-1790-6b0a-8003-baf965b6a38f'}}, tasks=(),interrupts=()
)
查看线程的历史记录(检查点)
config = {"configurable": {"thread_id": "1"}
}
list(graph.get_state_history(config))
[StateSnapshot(values={'messages': [HumanMessage(content="hi! I'm bob"), AIMessage(content='Hi Bob! How are you doing today? Is there anything I can help you with?'), HumanMessage(content="what's my name?"), AIMessage(content='Your name is Bob.')]}, next=(), config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f029ca3-1f5b-6704-8004-820c16b69a5a'}}, metadata={'source': 'loop', 'writes': {'call_model': {'messages': AIMessage(content='Your name is Bob.')}}, 'step': 4, 'parents': {}, 'thread_id': '1'},created_at='2025-05-05T16:01:24.680462+00:00',parent_config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f029ca3-1790-6b0a-8003-baf965b6a38f'}},tasks=(),interrupts=()),StateSnapshot(values={'messages': [HumanMessage(content="hi! I'm bob"), AIMessage(content='Hi Bob! How are you doing today? Is there anything I can help you with?'), HumanMessage(content="what's my name?")]}, next=('call_model',), config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f029ca3-1790-6b0a-8003-baf965b6a38f'}},metadata={'source': 'loop', 'writes': None, 'step': 3, 'parents': {}, 'thread_id': '1'},created_at='2025-05-05T16:01:23.863421+00:00',parent_config={...}tasks=(PregelTask(id='8ab4155e-6b15-b885-9ce5-bed69a2c305c', name='call_model', path=('__pregel_pull', 'call_model'), error=None, interrupts=(), state=None, result={'messages': AIMessage(content='Your name is Bob.')}),),interrupts=()),StateSnapshot(values={'messages': [HumanMessage(content="hi! I'm bob"), AIMessage(content='Hi Bob! How are you doing today? Is there anything I can help you with?')]}, next=('__start__',), config={...}, metadata={'source': 'input', 'writes': {'__start__': {'messages': [{'role': 'user', 'content': "what's my name?"}]}}, 'step': 2, 'parents': {}, 'thread_id': '1'},created_at='2025-05-05T16:01:23.863173+00:00',parent_config={...}tasks=(PregelTask(id='24ba39d6-6db1-4c9b-f4c5-682aeaf38dcd', name='__start__', path=('__pregel_pull', '__start__'), error=None, interrupts=(), state=None, result={'messages': [{'role': 'user', 'content': "what's my name?"}]}),),interrupts=()),StateSnapshot(values={'messages': [HumanMessage(content="hi! I'm bob"), AIMessage(content='Hi Bob! How are you doing today? Is there anything I can help you with?')]}, next=(), config={...}, metadata={'source': 'loop', 'writes': {'call_model': {'messages': AIMessage(content='Hi Bob! How are you doing today? Is there anything I can help you with?')}}, 'step': 1, 'parents': {}, 'thread_id': '1'},created_at='2025-05-05T16:01:23.862295+00:00',parent_config={...}tasks=(),interrupts=()),StateSnapshot(values={'messages': [HumanMessage(content="hi! I'm bob")]}, next=('call_model',), config={...}, metadata={'source': 'loop', 'writes': None, 'step': 0, 'parents': {}, 'thread_id': '1'}, created_at='2025-05-05T16:01:22.278960+00:00', parent_config={...}tasks=(PregelTask(id='8cbd75e0-3720-b056-04f7-71ac805140a0', name='call_model', path=('__pregel_pull', 'call_model'), error=None, interrupts=(), state=None, result={'messages': AIMessage(content='Hi Bob! How are you doing today? Is there anything I can help you with?')}),), interrupts=()),StateSnapshot(values={'messages': []}, next=('__start__',), config={'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1f029ca3-0870-6ce2-bfff-1f3f14c3e565'}},metadata={'source': 'input', 'writes': {'__start__': {'messages': [{'role': 'user', 'content': "hi! I'm bob"}]}}, 'step': -1, 'parents': {}, 'thread_id': '1'}, created_at='2025-05-05T16:01:22.277497+00:00', parent_config=None,tasks=(PregelTask(id='d458367b-8265-812c-18e2-33001d199ce6', name='__start__', path=('__pregel_pull', '__start__'), error=None, interrupts=(), state=None, result={'messages': [{'role': 'user', 'content': "hi! I'm bob"}]}),), interrupts=())
]
删除线程的所有检查点
thread_id = "1"
checkpointer.delete_thread(thread_id)
6. 添加长期记忆
使用长期记忆(跨线程持久性)来跨对话存储用户特定或应用程序特定的数据。这对于像聊天机器人这样的应用程序很有用,你可能希望记住用户偏好或其他信息。
要使用长期记忆,我们需要在创建图时提供一个存储:
import uuid
from typing_extensions import Annotated, TypedDictfrom langchain_core.runnables import RunnableConfig
from langgraph.graph import StateGraph, MessagesState, START
from langgraph.checkpoint.memory import InMemorySaverfrom langgraph.store.memory import InMemoryStore
from langgraph.store.base import BaseStoremodel = init_chat_model(model="anthropic:claude-3-5-haiku-latest")def call_model(state: MessagesState,config: RunnableConfig,*,store: BaseStore,
):user_id = config["configurable"]["user_id"]namespace = ("memories", user_id)memories = store.search(namespace, query=str(state["messages"][-1].content))info = "\\n".join([d.value["data"] for d in memories])system_msg = f"You are a helpful assistant talking to the user. User info: {info}"# Store new memories if the user asks the model to rememberlast_message = state["messages"][-1]if "remember" in last_message.content.lower():memory = "User name is Bob"store.put(namespace, str(uuid.uuid4()), {"data": memory})response = model.invoke([{"role": "system", "content": system_msg}] + state["messages"])return {"messages": response}builder = StateGraph(MessagesState)
builder.add_node(call_model)
builder.add_edge(START, "call_model")checkpointer = InMemorySaver()
store = InMemoryStore()graph = builder.compile(checkpointer=checkpointer,store=store,
)
config = {"configurable": {"thread_id": "1","user_id": "1",}
}
for chunk in graph.stream({"messages": [{"role": "user", "content": "Hi! Remember: my name is Bob"}]},config,stream_mode="values",
):chunk["messages"][-1].pretty_print()config = {"configurable": {"thread_id": "2","user_id": "1",}
}for chunk in graph.stream({"messages": [{"role": "user", "content": "what is my name?"}]},config,stream_mode="values",
):chunk["messages"][-1].pretty_print()
================================ Human Message =================================Hi! Remember: my name is Bob
================================== Ai Message ==================================Hi Bob! I'll remember that your name is Bob. How are you doing today?
================================ Human Message =================================what is my name?
================================== Ai Message ==================================Your name is Bob.
6.1 在生产环境中
在生产环境中,你会希望使用由数据库支持的存储:
示例:使用 Postgres 存储
第一次使用 Postgres 存储时,您需要调用 store.setup()。
pip install -U "psycopg[binary,pool]" langgraph langgraph-checkpoint-postgres
from langchain_core.runnables import RunnableConfig
from langchain.chat_models import init_chat_model
from langgraph.graph import StateGraph, MessagesState, START
from langgraph.checkpoint.postgres import PostgresSaver
from langgraph.store.postgres import PostgresStore
from langgraph.store.base import BaseStoremodel = init_chat_model(model="anthropic:claude-3-5-haiku-latest")DB_URI = "postgresql://postgres:postgres@localhost:5442/postgres?sslmode=disable"with (PostgresStore.from_conn_string(DB_URI) as store,PostgresSaver.from_conn_string(DB_URI) as checkpointer,
):# store.setup()# checkpointer.setup()def call_model(state: MessagesState,config: RunnableConfig,*,store: BaseStore,):user_id = config["configurable"]["user_id"]namespace = ("memories", user_id)memories = store.search(namespace, query=str(state["messages"][-1].content))info = "\\n".join([d.value["data"] for d in memories])system_msg = f"You are a helpful assistant talking to the user. User info: {info}"# Store new memories if the user asks the model to rememberlast_message = state["messages"][-1]if "remember" in last_message.content.lower():memory = "User name is Bob"store.put(namespace, str(uuid.uuid4()), {"data": memory})response = model.invoke([{"role": "system", "content": system_msg}] + state["messages"])return {"messages": response}builder = StateGraph(MessagesState)builder.add_node(call_model)builder.add_edge(START, "call_model")graph = builder.compile(checkpointer=checkpointer,store=store,)config = {"configurable": {"thread_id": "1","user_id": "1",}}for chunk in graph.stream({"messages": [{"role": "user", "content": "Hi! Remember: my name is Bob"}]},config,stream_mode="values",):chunk["messages"][-1].pretty_print()config = {"configurable": {"thread_id": "2","user_id": "1",}}for chunk in graph.stream({"messages": [{"role": "user", "content": "what is my name?"}]},config,stream_mode="values",):chunk["messages"][-1].pretty_print()
6.2 语义搜索
你可以在图的记忆存储中启用语义搜索:这让图智能体能够通过语义相似性来搜索存储中的项目。
from typing import Optionalfrom langchain.embeddings import init_embeddings
from langchain.chat_models import init_chat_model
from langgraph.store.base import BaseStore
from langgraph.store.memory import InMemoryStore
from langgraph.graph import START, MessagesState, StateGraphllm = init_chat_model("openai:gpt-4o-mini")# Create store with semantic search enabled
embeddings = init_embeddings("openai:text-embedding-3-small")
store = InMemoryStore(index={"embed": embeddings,"dims": 1536,}
)store.put(("user_123", "memories"), "1", {"text": "I love pizza"})
store.put(("user_123", "memories"), "2", {"text": "I am a plumber"})def chat(state, *, store: BaseStore):# Search based on user's last messageitems = store.search(("user_123", "memories"), query=state["messages"][-1].content, limit=2)memories = "\\n".join(item.value["text"] for item in items)memories = f"## Memories of user\\n{memories}" if memories else ""response = llm.invoke([{"role": "system", "content": f"You are a helpful assistant.\\n{memories}"},*state["messages"],])return {"messages": [response]}builder = StateGraph(MessagesState)
builder.add_node(chat)
builder.add_edge(START, "chat")
graph = builder.compile(store=store)for message, metadata in graph.stream(input={"messages": [{"role": "user", "content": "I'm hungry"}]},stream_mode="messages",
):print(message.content, end="")
在设计你的智能体时,以下问题可以作为有用的指南:
- 你的智能体应该学习什么类型的内容:事实/知识?过去事件的摘要?规则和风格?
- 记忆应该在何时形成(以及应该由谁形成记忆)?
- 记忆应该存储在哪里?
7. 构建电子邮件智能体:分步指南
通过将三种长期记忆类型编织在一起,我们的智能体变得真正智能和个性化。想象一个助手:
- 注意到来自特定客户的电子邮件如果在 24 小时内未回复通常需要跟进
- 学习你的写作风格和语气,对外部通信采用正式回复,对团队成员采用随意回复
- 记住复杂的项目上下文,而无需你反复解释
- 更擅长预测你想看哪些电子邮件 versus 自动处理哪些
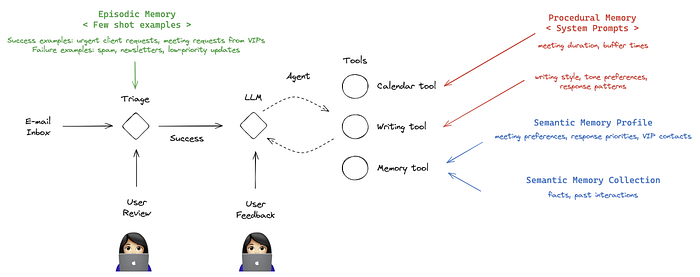
-
工作流:
START → Triage (Episodic + Procedural Memory) → Decision → Response Agent (Semantic + Procedural Memory) → END
让我们携手将此愿景付诸实践,使之成为现实!:)
导入和设置
!pip install langmem langchain_community python-dotenv --quiet
# ===============================================================================
# IMPORTS
# ===============================================================================
import os
import warnings
import numpy as np
from dotenv import load_dotenv
from typing import TypedDict, Literal, Annotated, List# LangGraph and LangChain imports
from langgraph.graph import StateGraph, START, END, add_messages
from langgraph.prebuilt import create_react_agent
from langgraph.store.memory import InMemoryStore
from langchain.chat_models import init_chat_model
from langchain_core.tools import tool
from langchain.prompts import PromptTemplate
from langchain.schema import HumanMessage
from pydantic import BaseModel, Field# LangMem imports for memory tools
from langmem import create_manage_memory_tool, create_search_memory_tool, create_multi_prompt_optimizer# IPython for visualization
from IPython.display import Image, display# Suppress numpy warnings from embedding calculations
warnings.filterwarnings("ignore", category=RuntimeWarning, module="numpy")
warnings.filterwarnings("ignore", category=RuntimeWarning, module="langgraph")
现在,让我们初始化我们的环境和工具:
%env OPENAI_API_KEY=<your_openai_api_key>
# ===============================================================================
# CONFIGURATION
# ===============================================================================# Load environment variables
load_dotenv()# User Configuration
USER_ID = "test_user"
CONFIG = {"configurable": {"langgraph_user_id": USER_ID}}# Initialize core components
llm = init_chat_model("openai:gpt-4o-mini")
store = InMemoryStore(index={"embed": "openai:text-embedding-3-small"})
这里的记忆存储尤其重要——它就像是给我们智能体一个可以存储和检索信息的大脑。为简单起见,我们使用内存存储,但在生产环境中,你可能希望使用持久性数据库。
7.1 定义我们智能体的“大脑”:状态 (State)
现在我们需要设计智能体的工作记忆——它跟踪当前正在处理的事情的精神便笺。这不同于我们稍后将实现的长期记忆——它更像你在处理任务时主动记在心里的东西。
class State(TypedDict):"""State management for the email agent workflow.This state is passed between nodes in the LangGraph workflow and contains:- email_input: The incoming email to be processed- messages: Conversation history for the response agent- triage_result: Classification result from triage ('ignore', 'notify', 'respond')The state evolves as it moves through the workflow, accumulating informationthat helps the agent make better decisions and provide contextual responses."""email_input: dict # The incoming emailmessages: Annotated[list, add_messages] # The conversation historytriage_result: str # The result of the triage (ignore, notify, respond)
这个 State 对象包含三个关键信息:
-
正在处理的当前电子邮件
-
正在进行的对话(如果有)
-
关于如何处理邮件的决定
可以把它想象成医生在查房时的剪贴板——它包含做决定所需的即时信息,而病人的完整病历则留在病历室(我们的记忆存储)中。
7.2 分诊中心:决定做什么(使用情景记忆)
首先,我们将为智能体创建一个结构来解释其推理和分类:
class Router(BaseModel):"""Structured output model for email triage classification.This model ensures that the LLM provides both reasoning and classificationin a consistent format, making the triage process transparent and debuggable.The reasoning field helps us understand how the agent made its decision,which is crucial for improving prompts and training examples."""reasoning: str = Field(description="Step-by-step reasoning behind the classification.")classification: Literal["ignore", "respond", "notify"] = Field(description="The classification of an email: 'ignore', 'notify', or 'respond'.")# Initialize LLM router with structured output
llm_router = llm.with_structured_output(Router)
为了利用情景记忆,我们需要一种方法来格式化过去交互的示例:
def format_few_shot_examples(examples):"""Format episodic memory examples for few-shot learning.This function converts stored email examples from the episodic memoryinto a formatted string that can be included in the triage prompt.Args:examples: List of stored email examples from memory.search()Returns:str: Formatted examples string for few-shot learning"""formatted_examples = []for eg in examples:email = eg.value['email']label = eg.value['label']formatted_examples.append(f"From: {email['author']}\\nSubject: {email['subject']}\\nBody: {email['email_thread'][:300]}...\\n\\nClassification: {label}")return "\\n\\n".join(formatted_examples)
这个函数将我们存储的示例转换为有助于模型从中学习的格式,就像向新员工展示带有如何处理不同情况的注释示例的训练手册一样。
现在,让我们创建使用情景记忆的电子邮件分诊功能:
def triage_email(state: State, config: dict, store: InMemoryStore) -> dict:"""Basic email triage function using episodic memory.This function classifies incoming emails using:1. Static prompt template2. Few-shot examples from episodic memoryArgs:state: Current workflow state containing email_inputconfig: Configuration containing user_id for memory namespacingstore: InMemoryStore for accessing episodic memoryReturns:dict: Updated state with triage_result"""email = state["email_input"]user_id = config["configurable"]["langgraph_user_id"]namespace = ("email_assistant", user_id, "examples") # Namespace for episodic memory# Retrieve relevant examples from memoryexamples = store.search(namespace, query=str(email))formatted_examples = format_few_shot_examples(examples)prompt_template = PromptTemplate.from_template("""You are an email triage assistant. Classify the following email:From: {author}To: {to}Subject: {subject}Body: {email_thread}Classify as 'ignore', 'notify', or 'respond'.Here are some examples of previous classifications:{examples}""")prompt = prompt_template.format(examples=formatted_examples, **email)messages = [HumanMessage(content=prompt)]result = llm_router.invoke(messages)return {"triage_result": result.classification}
这个功能是情景记忆工作的核心。当新邮件到达时,它不会孤立地分析它——它会搜索过去类似的邮件,看看它们是如何被处理的。就像一个记得“最后三个有这些症状的病人对这种治疗反应良好”的医生。
7.3 使用语义记忆定义工具
现在让我们给我们的智能体一些工具来工作。首先,是写邮件和查日历的基本能力:
@tool
def write_email(to: str, subject: str, content: str) -> str:"""Tool for composing and sending email responses.This tool is available to the Response Agent and allows it to:- Draft professional email responses- Send replies to email inquiries- Handle email communication tasksArgs:to: Recipient email addresssubject: Email subject linecontent: Email body contentReturns:str: Confirmation message of email sent"""print(f"Sending email to {to} with subject '{subject}'\\nContent:\\n{content}\\n")return f"Email sent to {to} with subject '{subject}'"@tool
def check_calendar_availability(day: str) -> str:"""Tool for checking calendar availability.This tool allows the Response Agent to:- Check available meeting times- Schedule appointments- Provide calendar informationArgs:day: Day to check availability forReturns:str: Available time slots for the specified day"""return f"Available times on {day}: 9:00 AM, 2:00 PM, 4:00 PM"
请注意,这些是用于演示目的的简化实现。在生产环境中,你需要将这些功能连接到实际的电子邮件和日历 API(如 Gmail API 或 Microsoft Graph API)。例如,write_email 函数将与真实的电子邮件服务交互以发送消息,而 check_calendar_availability 将查询你实际的日历数据。
现在,让我们添加语义记忆工具——我们智能体存储和检索关于世界的事实的能力:
# ===============================================================================
# TOOLS CONFIGURATION
# ===============================================================================# Create LangMem memory tools
manage_memory_tool = create_manage_memory_tool(namespace=("email_assistant", "{langgraph_user_id}", "collection"))
search_memory_tool = create_search_memory_tool(namespace=("email_assistant", "{langgraph_user_id}", "collection"))# All available tools for the response agent
tools = [write_email, check_calendar_availability, manage_memory_tool, search_memory_tool]
7.4 响应智能体:创建我们的核心助手(使用语义记忆)
我们现在将创建使用其所有记忆系统处理响应的核心智能体:
def create_agent_prompt(state, config, store):"""Create dynamic prompts for the Response Agent using procedural memory.This function demonstrates how PROCEDURAL MEMORY enables adaptive behavior:1. Retrieves the current response prompt from memory storage2. Combines it with conversation history3. Returns properly formatted prompt for the LLMArgs:state: Current workflow state with message historyconfig: Configuration containing user_id for memory accessstore: InMemoryStore for accessing procedural memoryReturns:list: Formatted messages for the LLM including system prompt + history"""messages = state['messages']user_id = config["configurable"]["langgraph_user_id"]print("RESPONSE AGENT: Initializing with adaptive system prompt")# Get the current response prompt from procedural memorysystem_prompt = store.get(("email_assistant", user_id, "prompts"), "response_prompt")print("PROCEDURAL MEMORY: Retrieved current response prompt")# Ensure the system prompt is a stringif not isinstance(system_prompt, str):system_prompt = str(system_prompt.value) if hasattr(system_prompt, 'value') else str(system_prompt)return [{"role": "system", "content": system_prompt}] + messages
这个函数创建了一个从程序性记忆中提取指令并传递当前对话的提示。就像一个经理在回应复杂情况之前检查公司手册,确保他们遵循最新的协议。
请注意,我们现在已经建立了两个关键的记忆系统:
- 情景记忆(在分诊功能中)
- 语义记忆(在这些智能体工具中)
但是我们仍然需要添加程序性记忆来完成我们智能体的认知能力。这将在以下部分中出现,我们将使我们的智能体能够根据反馈随时间改进自己的行为。
7.5 构建图:连接各个部分
现在,让我们把所有东西整合到一个连贯的工作流程中:
def create_basic_email_agent(store):"""Factory function to create a basic email processing agent using only episodic memory.This function creates a simpler workflow for comparison purposes that only uses:1. EPISODIC MEMORY: Past email examples for few-shot learningArgs:store: InMemoryStore containing episodic memoryReturns:CompiledGraph: Executable workflow with basic memory capabilities"""# Define the workflowworkflow = StateGraph(State)# Use the basic triage function (episodic memory only)workflow.add_node("triage", lambda state, config: triage_email(state, config, store))# Create a basic response agent with static promptsresponse_agent = create_react_agent(tools=tools,prompt=create_agent_prompt,store=store,model=llm)workflow.add_node("response_agent", response_agent)def route_based_on_triage(state):if state["triage_result"] == "respond":return "response_agent"else:return END# The routing logic remains the sameworkflow.add_edge(START, "triage")workflow.add_conditional_edges("triage", route_based_on_triage,{"response_agent": "response_agent",END: END})# Compile and return the graphreturn workflow.compile(store=store)
我们的智能体看起来是这样的:
from langchain_core.runnables.graph import MermaidDrawMethod
from IPython.display import display, Imagedisplay(Image(create_basic_email_agent(store).get_graph().draw_mermaid_png(draw_method=MermaidDrawMethod.API,))
)
这个工作流程定义了智能体的逻辑路径:
- 首先,使用情景记忆对收到的邮件进行分诊
- 如果需要回复,则激活带有语义记忆的响应智能体
- 否则,结束流程(对于“忽略”或“通知”的邮件)
就像在工厂里设置装配线工位一样——每个部分都有自己的工作,但它们共同协作以创造出最终产品。
7.6 运行它!(并存储一些记忆)
是时候测试我们的智能体了:
# SAMPLE DATA AND INITIALIZATION
# ===============================================================================# Sample email for testing
email_input = {"author": "Alice Smith <alice.smith@company.com>","to": "John Doe <john.doe@company.com>","subject": "Quick question about API documentation","email_thread": """Hi John,I was reviewing the API documentation and noticed a few endpoints are missing. Could you help?Thanks,
Alice""",
}# Initial prompts
initial_triage_prompt = """You are an email triage assistant. Classify the following email:
From: {author}
To: {to}
Subject: {subject}
Body: {email_thread}Classify as 'ignore', 'notify', or 'respond'.Here are some examples of previous classifications:
{examples}
"""initial_response_prompt = """You are a helpful assistant. Use the tools available, including memory tools, to assist the user."""
让我们也向情景记忆添加一个训练示例,以帮助智能体将来识别垃圾邮件:
def initialize_memory():"""Initialize memory with default examples and prompts"""# Add few shot examples to episodic memoryexample1 = {"email": {"author": "Spammy Marketer <spam@example.com>","to": "John Doe <john.doe@company.com>","subject": "BIG SALE!!!","email_thread": "Buy our product now and get 50% off!",},"label": "ignore",}store.put(("email_assistant", USER_ID, "examples"), "spam_example", example1)# Initialize procedural memory with default promptsstore.put(("email_assistant", USER_ID, "prompts"), "triage_prompt", initial_triage_prompt)store.put(("email_assistant", USER_ID, "prompts"), "response_prompt", initial_response_prompt)
这就像训练一个新助手:“看到这种邮件了吗?你可以安全地忽略它们。” 我们提供的例子越多,智能体的理解就越细致。
7.7 添加程序性记忆(更新指令)—— 最后的点睛之笔!
现在,对于最复杂的记忆系统,程序性记忆允许我们的智能体根据反馈改进自己的指令。
让我们创建一个从记忆中提取指令的分诊函数版本:
def triage_email_with_procedural_memory(state: State, config: dict, store: InMemoryStore) -> dict:"""Advanced email triage using BOTH episodic and procedural memory.This is the heart of the adaptive learning system, combining:1. PROCEDURAL MEMORY: Dynamic prompts that improve over time2. EPISODIC MEMORY: Few-shot examples from past classificationsArgs:state: Current workflow state containing email_inputconfig: Configuration with user_id for memory namespacingstore: InMemoryStore with both memory typesReturns:dict: Updated state with triage_result classification"""email = state["email_input"]user_id = config["configurable"]["langgraph_user_id"]print(f"TRIAGE: Analyzing email from {email['author']} with subject: '{email['subject']}'")# Retrieve the current triage prompt (procedural memory)current_prompt_template = store.get(("email_assistant", user_id, "prompts"), "triage_prompt")print("PROCEDURAL MEMORY: Retrieved current triage prompt")# Ensure the prompt template is a stringif not isinstance(current_prompt_template, str):current_prompt_template = str(current_prompt_template) # Convert to string if it's an Item object# Retrieve relevant examples from memory (episodic memory)namespace = ("email_assistant", user_id, "examples")examples = store.search(namespace, query=str(email))formatted_examples = format_few_shot_examples(examples)print(f"EPISODIC MEMORY: Found {len(examples)} relevant examples from past classifications")# Format the promptprompt = PromptTemplate.from_template(current_prompt_template).format(examples=formatted_examples, **email)messages = [HumanMessage(content=prompt)]result = llm_router.invoke(messages)print(f"TRIAGE RESULT: {result.classification}")print(f"REASONING: {result.reasoning}")return {"triage_result": result.classification}
这个函数集成了程序性记忆(当前的提示模板)和情景记忆(相关示例)来做分诊决策。
现在,让我们创建一个可以根据反馈优化提示的函数:
def optimize_prompts(feedback: str, config: dict, store: InMemoryStore):"""PROCEDURAL MEMORY LEARNING: Optimize prompts based on performance feedback.This function implements the core learning mechanism that enables gradual improvement:1. Analyzes current prompt performance via feedback2. Uses AI-powered optimization to improve prompts3. Updates procedural memory with better prompts4. Future agent instances automatically use improved promptsArgs:feedback: Human feedback describing performance issuesconfig: Configuration with user_id for memory accessstore: InMemoryStore for updating procedural memoryReturns:str: Confirmation message about improvements madeExample Evolution:Initial: "How can I assist you today?"After feedback: "How can I assist you with API documentation?""""print("\\nOPTIMIZATION: Starting prompt improvement process...")user_id = config["configurable"]["langgraph_user_id"]# Get current promptsprint("RETRIEVING: Current prompts from procedural memory")triage_prompt = store.get(("email_assistant", user_id, "prompts"), "triage_prompt").valueresponse_prompt = store.get(("email_assistant", user_id, "prompts"), "response_prompt").value# Create a more relevant test example based on our actual emailsample_email = {"author": "Alice Smith <alice.smith@company.com>","to": "John Doe <john.doe@company.com>","subject": "Quick question about API documentation","email_thread": "Hi John, I was reviewing the API documentation and noticed a few endpoints are missing. Could you help? Thanks, Alice",}print("ANALYZING: Creating conversation trajectory with feedback")# Create the optimizeroptimizer = create_multi_prompt_optimizer(llm)# Create a more relevant conversation trajectory with feedbackconversation = [{"role": "system", "content": response_prompt},{"role": "user", "content": f"I received this email: {sample_email}"},{"role": "assistant", "content": "How can I assist you today?"}]# Format promptsprompts = [{"name": "triage", "prompt": triage_prompt},{"name": "response", "prompt": response_prompt}]# More relevant trajectoriestrajectories = [(conversation, {"feedback": feedback})]print("OPTIMIZING: Using AI to improve prompts based on feedback...")result = optimizer.invoke({"trajectories": trajectories, "prompts": prompts})# Extract the improved promptsimproved_triage_prompt = next(p["prompt"] for p in result if p["name"] == "triage")improved_response_prompt = next(p["prompt"] for p in result if p["name"] == "response")# Append specific instruction for API documentation issuesimproved_triage_prompt = improved_triage_prompt + "\\n\\nPay special attention to emails about API documentation or missing endpoints - these are high priority and should ALWAYS be classified as 'respond'."improved_response_prompt = improved_response_prompt + "\\n\\nWhen responding to emails about documentation or API issues, acknowledge the specific issue mentioned and offer specific assistance rather than generic responses."print("STORING: Updated prompts in procedural memory")# Store the improved promptsstore.put(("email_assistant", user_id, "prompts"), "triage_prompt", improved_triage_prompt)store.put(("email_assistant", user_id, "prompts"), "response_prompt", improved_response_prompt)print("IMPROVEMENT COMPLETE: Prompts have been enhanced!")print(f"Triage prompt preview: {improved_triage_prompt[:100]}...")print(f"Response prompt preview: {improved_response_prompt[:100]}...")return "Prompts improved based on feedback!"
这个功能是程序性记忆的本质。它接受诸如“你没有正确优先处理关于 API 文档的电子邮件”这样的反馈,并用它来重写智能体的核心指令。优化器就像一个观看比赛录像的教练,研究哪里出了问题并相应地更新战术手册。它分析对话示例和反馈,然后改进指导智能体行为的提示。它不是仅仅记住具体的更正,而是将潜在的教训吸收到其整体方法中,类似于厨师根据客户反馈改进食谱,而不是每次简单地遵循不同的指令。
7.8 运行我们完整的记忆增强智能体!
现在让我们把所有东西整合成一个可以随时间演进的完整系统:
def create_email_agent(store):"""Factory function to create a memory-enabled email processing agent.This function builds a LangGraph workflow that combines all three memory types:1. EPISODIC MEMORY: Past email examples for few-shot learning2. SEMANTIC MEMORY: Contextual information via memory tools3. PROCEDURAL MEMORY: Adaptive prompts that improve over timeArgs:store: InMemoryStore containing all memory systemsReturns:CompiledGraph: Executable workflow with memory capabilities"""# Define the workflowworkflow = StateGraph(State)workflow.add_node("triage", lambda state, config: triage_email_with_procedural_memory(state, config, store))# Create a fresh response agent that will use the latest promptsresponse_agent = create_react_agent(tools=tools,prompt=create_agent_prompt,store=store,model=llm)workflow.add_node("response_agent", response_agent)def route_based_on_triage(state):if state["triage_result"] == "respond":return "response_agent"else:return END# The routing logic remains the sameworkflow.add_edge(START, "triage")workflow.add_conditional_edges("triage", route_based_on_triage,{"response_agent": "response_agent",END: END})# Compile and return the graphreturn workflow.compile(store=store)
这个函数创建了一个使用我们提示最新版本的新智能体——确保它始终反映我们最新的学习和反馈。
这是智能体的最终版本(包含所有内容):
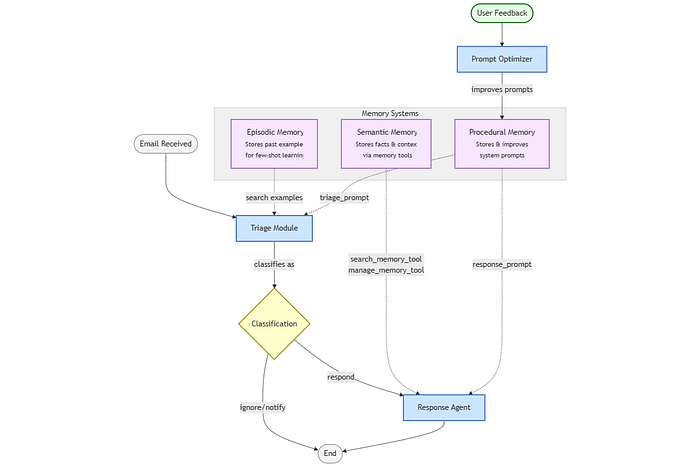
让我们运行两次——一次使用原始设置,一次在我们提供反馈改进之后:
# ===============================================================================
# MAIN EXECUTION: DEMONSTRATION OF GRADUAL IMPROVEMENT
# ===============================================================================
"""
This demonstration shows how the agent learns and improves over time:1. BEFORE OPTIMIZATION: Agent uses initial prompts and minimal examples
2. MEMORY ACCUMULATION: Add new examples to episodic memory
3. FEEDBACK PROCESSING: Human feedback triggers prompt optimization
4. AFTER OPTIMIZATION: Agent uses improved prompts with more examplesThe key insight: Each run benefits from ALL previous learning!
"""def run_demonstration():"""Main demonstration of the memory-enabled learning system"""print("🚀 STARTING MEMORY-ENABLED EMAIL AGENT DEMONSTRATION")print("=" * 60)# Initialize memory with default examples and promptsprint("📚 INITIALIZATION: Setting up memory systems...")initialize_memory()print("✅ MEMORY INITIALIZED: Episodic and procedural memory ready")# Setup for demonstrationinputs = {"email_input": email_input, "messages": []}# COMPARISON: Basic vs Advanced Agentprint("\\n" + "=" * 60)print("📧 PHASE 1: BASIC AGENT (Episodic Memory Only)")print("=" * 60)basic_agent = create_basic_email_agent(store)print("🏗️ BASIC AGENT CREATED: Using only episodic memory")print("\\n🔄 BASIC WORKFLOW EXECUTION:")for output in basic_agent.stream(inputs, config=CONFIG):for key, value in output.items():if key not in ['triage', 'response_agent']: # Skip internal node outputsprint(f"-----\\n{key}:")print(value)print("-----")# Advanced Agent - Before Optimizationprint("\\n" + "=" * 60)print("📧 PHASE 2: ADVANCED AGENT (Before Optimization)")print("=" * 60)agent = create_email_agent(store)print("🏗️ ADVANCED AGENT CREATED: Using episodic + procedural memory")print("\\n🔄 ADVANCED WORKFLOW EXECUTION (Before Learning):")for output in agent.stream(inputs, config=CONFIG):for key, value in output.items():if key not in ['triage', 'response_agent']: # Skip internal node outputsprint(f"-----\\n{key}:")print(value)print("-----")print("\\n" + "=" * 60)print("🧠 PHASE 3: MEMORY ENHANCEMENT & FEEDBACK")print("=" * 60)# Add a specific example to episodic memoryapi_doc_example = {"email": {"author": "Developer <dev@company.com>","to": "John Doe <john.doe@company.com>","subject": "API Documentation Issue", "email_thread": "Found missing endpoints in the API docs. Need urgent update.",},"label": "respond",}store.put(("email_assistant", USER_ID, "examples"), "api_doc_example", api_doc_example)print("📚 EPISODIC MEMORY: Added API documentation example")# Provide feedback for optimizationfeedback = """The agent didn't properly recognize that emails about API documentation issues are high priority and require immediate attention. When an email mentions 'API documentation', it should always be classified as 'respond' with a helpful tone.Also, instead of just responding with 'How can I assist you today?', the agent should acknowledge the specific documentation issue mentioned and offer assistance."""print("💬 FEEDBACK RECEIVED: Performance improvement suggestions")# Optimize prompts based on feedbackoptimize_prompts(feedback, CONFIG, store)# Process the SAME email after optimization with a FRESH agentprint("\\n" + "=" * 60)print("📧 PHASE 4: ADVANCED AGENT (After Optimization)")print("=" * 60)new_agent = create_email_agent(store)print("🏗️ OPTIMIZED AGENT CREATED: Fresh agent with optimized memory state")print("\\n🔄 ADVANCED WORKFLOW EXECUTION (After Learning):")for output in new_agent.stream(inputs, config=CONFIG):for key, value in output.items():if key not in ['triage', 'response_agent']: # Skip internal node outputsprint(f"-----\\n{key}:")print(value)print("-----")print("\\n" + "=" * 60)print("🎉 DEMONSTRATION COMPLETE: Comparison shows memory-enabled learning!")print("📊 RESULTS SUMMARY:")print(" 1️⃣ Basic Agent: Static prompts, episodic memory only")print(" 2️⃣ Advanced Agent (Before): Initial procedural memory + episodic memory")print(" 3️⃣ Advanced Agent (After): Optimized procedural memory + enhanced episodic memory")print("=" * 60)# Run the demonstration
if __name__ == "__main__":run_demonstration()
输出:
🚀 STARTING MEMORY-ENABLED EMAIL AGENT DEMONSTRATION
============================================================
📚 INITIALIZATION: Setting up memory systems...
✅ MEMORY INITIALIZED: Episodic and procedural memory ready============================================================
📧 PHASE 1: BASIC AGENT (Episodic Memory Only)
============================================================
🏗️ BASIC AGENT CREATED: Using only episodic memory🔄 BASIC WORKFLOW EXECUTION:
-----
RESPONSE AGENT: Initializing with adaptive system prompt
PROCEDURAL MEMORY: Retrieved current response prompt
-----============================================================
📧 PHASE 2: ADVANCED AGENT (Before Optimization)
============================================================
🏗️ ADVANCED AGENT CREATED: Using episodic + procedural memory🔄 ADVANCED WORKFLOW EXECUTION (Before Learning):
TRIAGE: Analyzing email from Alice Smith <alice.smith@company.com> with subject: 'Quick question about API documentation'
PROCEDURAL MEMORY: Retrieved current triage prompt
EPISODIC MEMORY: Found 2 relevant examples from past classifications
TRIAGE RESULT: respond
REASONING: The email from Alice Smith is a request for help regarding missing endpoints in the API documentation. This indicates a requirement for a response to assist her with the issue, as it relates to important documentation that is likely affecting her work or the work of her team. Unlike spam or non-urgent inquiries, this is a valid work-related request that warrants a response.
-----
RESPONSE AGENT: Initializing with adaptive system prompt
PROCEDURAL MEMORY: Retrieved current response prompt
-----============================================================
🧠 PHASE 3: MEMORY ENHANCEMENT & FEEDBACK
============================================================
📚 EPISODIC MEMORY: Added API documentation example
💬 FEEDBACK RECEIVED: Performance improvement suggestionsOPTIMIZATION: Starting prompt improvement process...
RETRIEVING: Current prompts from procedural memory
ANALYZING: Creating conversation trajectory with feedback
OPTIMIZING: Using AI to improve prompts based on feedback...
STORING: Updated prompts in procedural memory
IMPROVEMENT COMPLETE: Prompts have been enhanced!
Triage prompt preview: You are an email triage assistant. Classify the following email based on its content and determine i...
Response prompt preview: You are a helpful assistant. Use the tools available, including memory tools, to assist the user. Wh...============================================================
📧 PHASE 4: ADVANCED AGENT (After Optimization)
============================================================
🏗️ OPTIMIZED AGENT CREATED: Fresh agent with optimized memory state🔄 ADVANCED WORKFLOW EXECUTION (After Learning):
TRIAGE: Analyzing email from Alice Smith <alice.smith@company.com> with subject: 'Quick question about API documentation'
PROCEDURAL MEMORY: Retrieved current triage prompt
EPISODIC MEMORY: Found 2 relevant examples from past classifications
TRIAGE RESULT: respond
REASONING: The email from Alice Smith discusses missing endpoints in the API documentation, which aligns perfectly with the high-priority key phrases outlined in the triage prompt. The prompt explicitly states that such emails should ALWAYS be classified as 'respond'. Given the importance of API documentation for the workflow, it is necessary to provide assistance.
-----
RESPONSE AGENT: Initializing with adaptive system prompt
PROCEDURAL MEMORY: Retrieved current response prompt
-----============================================================
🎉 DEMONSTRATION COMPLETE: Comparison shows memory-enabled learning!
📊 RESULTS SUMMARY:1️⃣ Basic Agent: Static prompts, episodic memory only2️⃣ Advanced Agent (Before): Initial procedural memory + episodic memory3️⃣ Advanced Agent (After): Optimized procedural memory + enhanced episodic memory
============================================================
看看回复的差异!在我们的反馈之后,智能体应该:
- 更一致地将 API 文档问题识别为高优先级
- 提供更具体、更有帮助的回复,承认实际的问题
- 提供具体的帮助而不是泛泛而谈
8. 结语
记忆是智能 AI 智能体的基石,使它们能够保留、回忆和适应信息。我们已经探讨了短期和长期记忆——程序性、情景性和语义性——如何融入智能体技术栈,超越了单纯的上下文窗口或 RAG。通过构建一个记忆增强的电子邮件智能体,我们展示了这些概念的实际应用,从状态管理到语义搜索和自适应指令。掌握记忆使 AI 能够提供个性化、上下文感知的解决方案,为在生产环境中构建更智能、更强大的系统铺平了道路。