R-Zero:通过自博弈机制让大语言模型无需外部数据实现自我进化训练
R-Zero框架实现了大语言模型在无外部训练数据条件下的自主进化与推理能力提升。
当前的LLM改进方法高度依赖大规模人工标注数据,这种范式虽然取得了显著成果但面临两个根本性限制:人类生成数据的有限性将导致训练瓶颈,以及人工数据的智能上界制约了模型超越人类能力的可能性。
针对这一挑战,研究人员提出了一个关键问题:是否存在让LLM自主识别缺陷、生成训练数据并据此改进的方法?最新发表在ArXiv上的研究给出了肯定答案。研究团队提出的R-Zero框架是一个完全自主的训练系统,能够使LLM从零开始生成自身训练数据并实现持续改进。
实验结果显示,R-Zero在多个数学推理和通用领域推理基准测试中显著提升了LLM的推理性能。
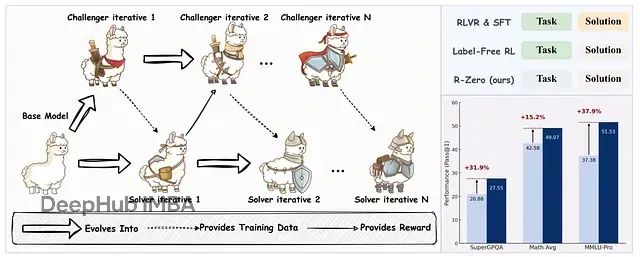
R-Zero框架示意图及其在Qwen3–4B-Base模型上实现的性能提升
自演化大语言模型的技术背景
自演化LLM指能够自主识别性能薄弱环节并通过自身经验学习实现迭代改进的模型系统。
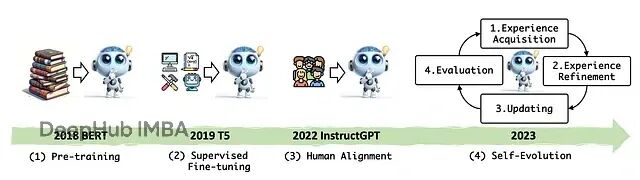
现有的自演化LLM主要依赖专家精心构建的标注数据集,这些数据集包含任务题目及其标准答案。在监督微调(Supervised Fine-Tuning, SFT)或可验证奖励强化学习(Reinforcement Learning with Verifiable Rewards, RLVR)过程中,标注数据为模型提供改进信号。RLVR技术使用基于规则的验证器,对正确输出给予奖励值
1
,错误输出给予
0
,以此指导训练过程。


人工标注数据的构建成本极高,需要领域专家参与,具有时间密集、劳动密集和扩展困难等特征。更重要的是,这种数据构成了模型能力发展的上限瓶颈,阻碍了超人级智能的实现。
为减少对标注数据的依赖,研究界发展了无标签强化学习(Label-Free Reinforcement Learning)方法,这类方法的改进信号直接来源于模型自身输出而非外部标签。主要技术路线包括基于序列级置信度的奖励机制(奖励模型高置信度答案)、基于多路径推理一致性的奖励机制(奖励跨推理路径保持一致的答案)、低输出熵奖励(奖励确定性强的答案)、随机奖励(促进探索)以及负奖励(惩罚错误答案)。
尽管这些方法摆脱了对外部标签的依赖,但仍需要未标注问题数据集进行训练。先前研究已经探索了LLM在自生成问题上的训练方法(自挑战LLM),这种方法在数学问题求解和代码生成等领域表现良好,因为可以通过代码执行器或验证器检查自生成任务的正确性。
开放式推理问题缺乏可靠的验证器,限制了这类方法的应用范围。R-Zero通过利用LLM自身的内在信号来评估任务质量和正确性,有效解决了这一限制。
R-Zero框架的技术实现
R-Zero采用了自博弈(Self-play)训练策略,单一LLM被分化为两个功能角色,通过相互对抗和迭代优化实现共同进化。系统包含挑战者(Challenger)和求解者(Solver)两个组件:挑战者负责生成处于求解者能力边界的高难度问题,求解者负责解决这些问题。两个组件在迭代循环中持续改进,挑战者学习创建更具挑战性的任务,求解者学习应对这些挑战。整个过程完全自监督,无需任何人工干预。
挑战者训练机制
挑战者模型
Q(θ)
的目标是生成具有特定难度特征的数学问题,这些问题需要满足可解性要求,同时位于求解者解决能力的临界边界。系统使用不确定性奖励机制指导挑战者的问题生成过程。
对于挑战者生成的问题
x
,求解者
S(Φ)
进行
m
次独立求解,得到答案集合
{y(1), …, y(m)}
。集合中的众数作为该问题的伪标签
ỹ(x)
,求解者答案与伪标签的匹配比例构成经验准确率
p̂
。
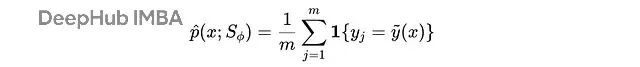
求解者的经验准确率计算公式,其中y(j)是求解者的第j个答案,
ỹ(x)
是伪标签,
1{⋅}
表示指示函数,如果条件为真则返回1,否则返回0
不确定性奖励的计算公式为:
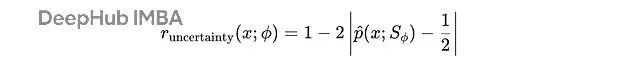
不确定性奖励公式,其中
p̂
表示求解者对问题x的经验准确率
该奖励函数在
p̂ = 0.5
时达到最大值,对应求解者在50%的尝试中正确解决问题的状态。这个设计精准捕捉了求解者的最大不确定性点,确保挑战者生成的问题难度适中。
为防止挑战者通过重复生成相似问题来获得高奖励,系统引入了重复惩罚机制。通过计算问题对
x(i)
和
x(j)
之间的BLEU相似性得分,并将其转换为距离度量
d(i)(j) = 1 - BLEU(x(i), x(j))
。当距离低于阈值
τ(BLEU)
时,问题被归入同一聚类。
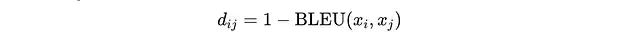
问题聚类过程,距离低于阈值的问题被分组到集合
C = {C(1),... , C(k)}
中
聚类内问题的惩罚分数与聚类规模成正比:
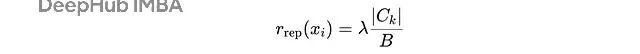
重复惩罚计算公式,其中B是批次大小,λ是缩放因子
这种设计使得相似问题聚类越大,其成员受到的惩罚越重,从而驱动挑战者生成更具多样性的问题。
系统还实施格式检查机制,要求挑战者的输出必须正确使用
<question>
和
</question>
标签包围问题内容。未通过格式检查的输出直接获得零奖励。通过格式检查的输出,其最终复合奖励计算为:
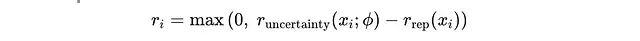
最终奖励组合公式,确保奖励值不低于零
基于批次内
G
个问题的奖励分布
{r(1), …, r(G)}
,系统计算每个问题的优势值
Â(i)
:
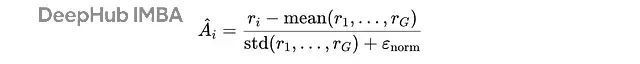
优势计算公式,其中ε(norm)是数值稳定性常数
优势值随后用于通过GRPO(Generalized Reward Policy Optimization)损失函数更新挑战者策略参数:
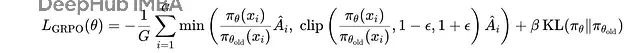
GRPO损失函数,包含裁剪和KL散度惩罚项以防止策略更新过度

求解者训练数据构建
完成挑战者训练后,系统利用更新后的挑战者生成包含
N
个问题的候选集合。对于集合中的每个问题
x(i)
,求解者进行
m
次求解,最高频答案成为该问题的伪标签
ỹ(i)
。问题-答案对
(x(i), ỹ(i))
加入求解者训练集
S
的条件为:
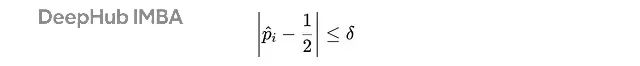
数据筛选条件,其中
p̂
是求解者对问题i的经验准确率
该筛选机制仅保留求解者准确率在50%附近(误差范围为
δ
)的问题,有效过滤过于简单或过于困难的样本。
求解者训练优化
基于构建的训练数据集
S
,求解者模型
S(Φ)
进行微调优化。训练过程采用简化的奖励机制:对于数据集中带有伪标签
ỹ(i)
的问题
x(i)
,求解者生成多个候选答案,每个答案
x(j)
根据与伪标签的匹配情况获得二进制奖励
r(j)
:

求解者的二进制奖励函数
系统将二进制奖励标准化为优势值
Â(j)
,并通过GRPO损失函数更新求解者策略,提高其在困难问题上产生正确答案的概率。
完整的R-Zero训练流程如下图所示:
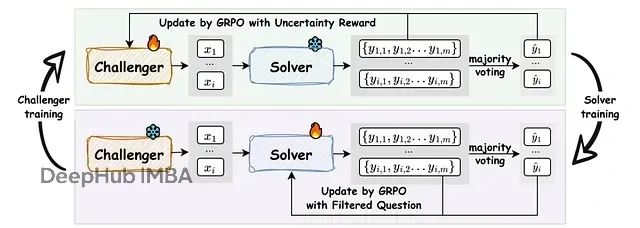
R-Zero完整训练流程:挑战者基于冻结求解者的不确定性信号训练生成困难问题,求解者随后在挑战者生成的筛选问题集上微调,两个组件通过迭代实现协同演化
实验评估与性能分析
研究团队在两个主流LLM系列上验证了R-Zero的有效性:Qwen系列(Qwen3–4B-Base和Qwen3–8B-Base)以及OctoThinker系列(基于Llama 3.1持续训练得到的OctoThinker-3B和OctoThinker-8B模型)。实验涵盖多个数学推理和通用领域推理基准测试。
R-Zero在提升两个模型系列的数学问题解决能力方面表现卓越。性能提升在迭代过程中呈现稳定增长趋势,其中首轮迭代产生的改进幅度最为显著,这突出了强化学习训练挑战者的关键作用。基线实验中"基础挑战者"(未训练的挑战者)的对比结果进一步证实了这一观察。
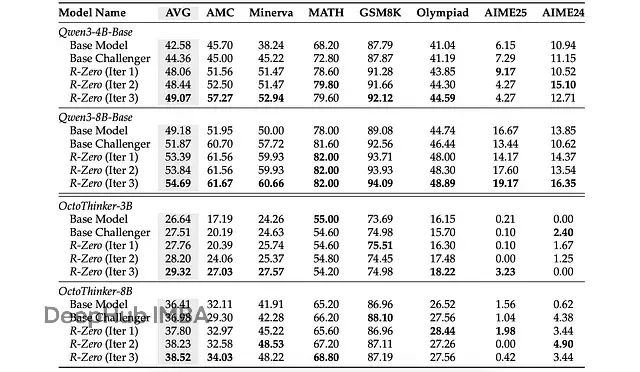
R-Zero在数学推理基准测试上的性能表现,"基础挑战者"基线代表使用未训练挑战者问题训练求解者的情况
值得注意的是,尽管R-Zero专门针对数学推理任务进行训练,其习得的推理技能显著改善了模型在通用领域的推理表现。如下表所示,通用推理性能在迭代过程中持续提升。
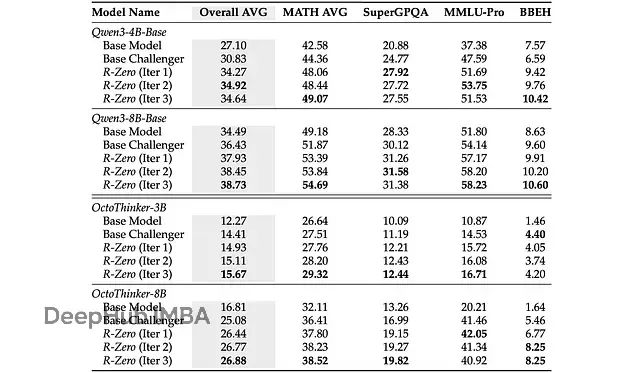
总结
R-Zero代表了一个完全自主的LLM训练框架,实现了模型在多个推理领域的显著自演化改进。当前版本专注于数学推理任务,主要因为该领域具备客观的正确性验证机制。将框架扩展至开放式推理任务将是通向真正自演化LLM的重要发展方向。
这一研究方向具有重要的理论价值和实践意义,为突破传统训练范式的数据依赖限制提供了新的技术路径。
参考资料
论文:“R-Zero: Self-Evolving Reasoning LLM from Zero Data”
https://avoid.overfit.cn/post/d18d62b217dd4ad6a87599757579e450
作者:Dr. Ashish Bamania