大数据毕业设计选题推荐-基于大数据的城镇居民食品消费量数据分析与可视化系统-Hadoop-Spark-数据可视化-BigData
✨作者主页:IT毕设梦工厂✨
个人简介:曾从事计算机专业培训教学,擅长Java、Python、PHP、.NET、Node.js、GO、微信小程序、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。
☑文末获取源码☑
精彩专栏推荐⬇⬇⬇
Java项目
Python项目
安卓项目
微信小程序项目
文章目录
- 一、前言
- 二、开发环境
- 三、系统界面展示
- 四、部分代码设计
- 五、系统视频
- 结语
一、前言
系统介绍:
本系统是基于大数据技术的城镇居民食品消费量数据分析与可视化系统,旨在通过对大规模食品消费数据的处理与分析,帮助相关部门更好地理解不同地区居民的食品消费趋势、结构和变化规律。系统通过Hadoop和Spark等大数据框架,实现对海量数据的高效处理,采用Python/Java语言开发,前端使用Vue框架结合Echarts进行可视化展示。系统不仅支持全面的数据分析,还提供直观的图表展示,帮助决策者了解食品消费的空间、时间及类别分布,进而优化相关政策与市场策略。通过该系统,用户可以便捷地对多维度的数据进行深入分析,并实时获取动态变化,提供支持科学决策的依据。
选题背景:
随着中国城镇化进程的加快,居民生活水平的不断提高,食品消费结构和模式正在发生显著变化。传统的食品消费数据分析方法,往往依赖小规模样本和静态分析,难以满足日益复杂的消费行为需求。大数据技术的快速发展,为食品消费数据的收集、存储、处理和分析提供了新的可能。近年来,随着食品安全问题的日益关注和人们健康饮食需求的增加,对食品消费行为的研究日益重要。然而,目前大多数分析仍局限于局部地区或较短时间跨度,缺乏跨区域、跨时间的系统性分析和精准的预测模型。因此,基于大数据技术的城镇居民食品消费数据分析与可视化系统的建设显得尤为必要,它不仅能够实时反映消费模式的变化,还能够为食品产业政策的制定提供依据。
选题意义:
本课题通过大数据分析与可视化技术,为食品消费行为的研究提供了更加准确和全面的视角。系统通过对不同地区、不同年份、不同类别的食品消费数据进行深入挖掘,可以帮助政府和相关部门识别区域性消费差异,预测消费趋势,并为区域经济发展和消费政策的调整提供数据支持。此外,系统还能够为食品产业链中的各个环节提供决策依据,推动食品行业的优化升级。通过对消费结构和习惯的全面分析,能够为公共健康政策提供数据支撑,提升居民的饮食健康水平。该系统不仅具有较强的实际应用价值,还为未来在食品消费领域的深度研究打下了坚实的基础。
二、开发环境
- 大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
- 开发语言:Python+Java(两个版本都支持)
- 后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
- 前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
- 详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
- 数据库:MySQL
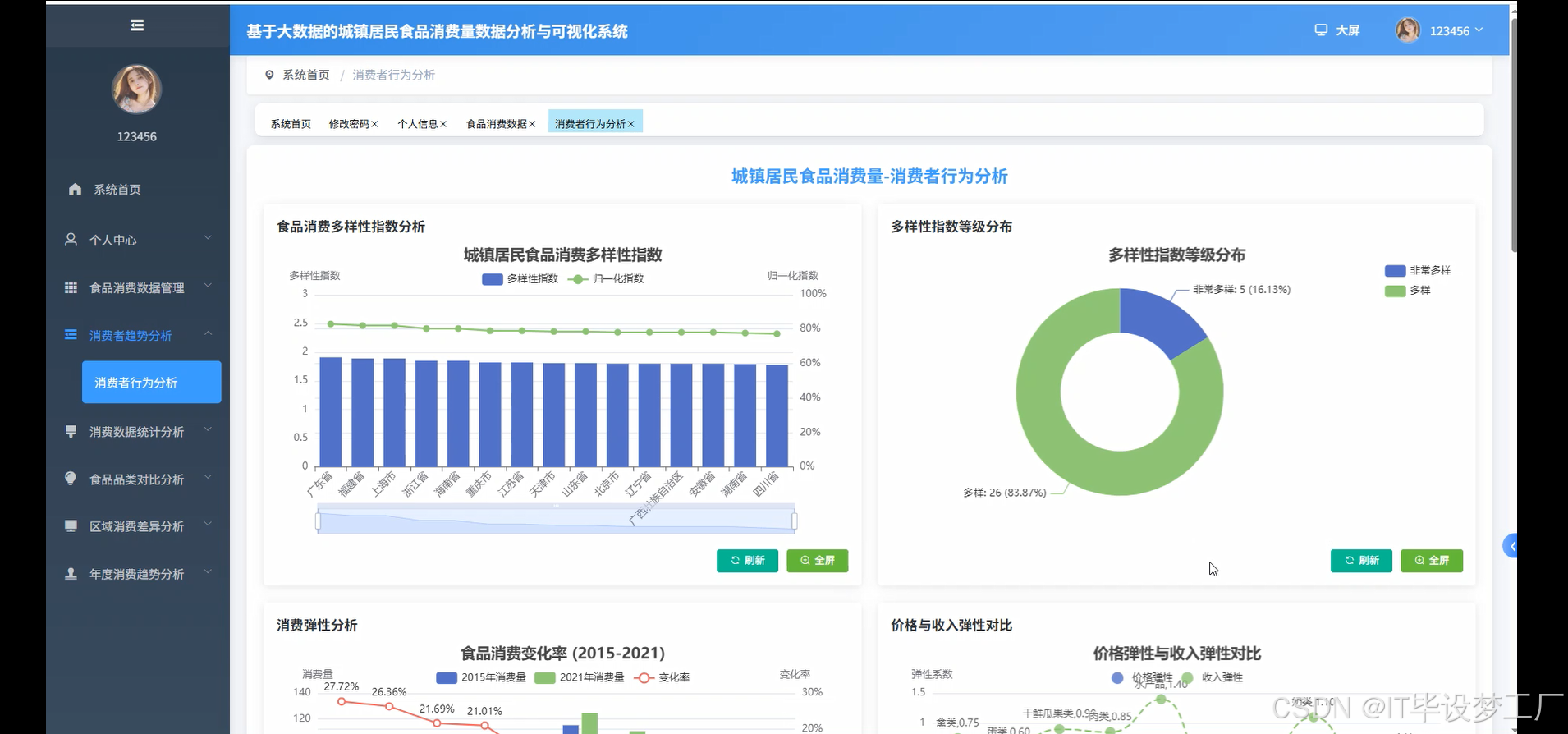
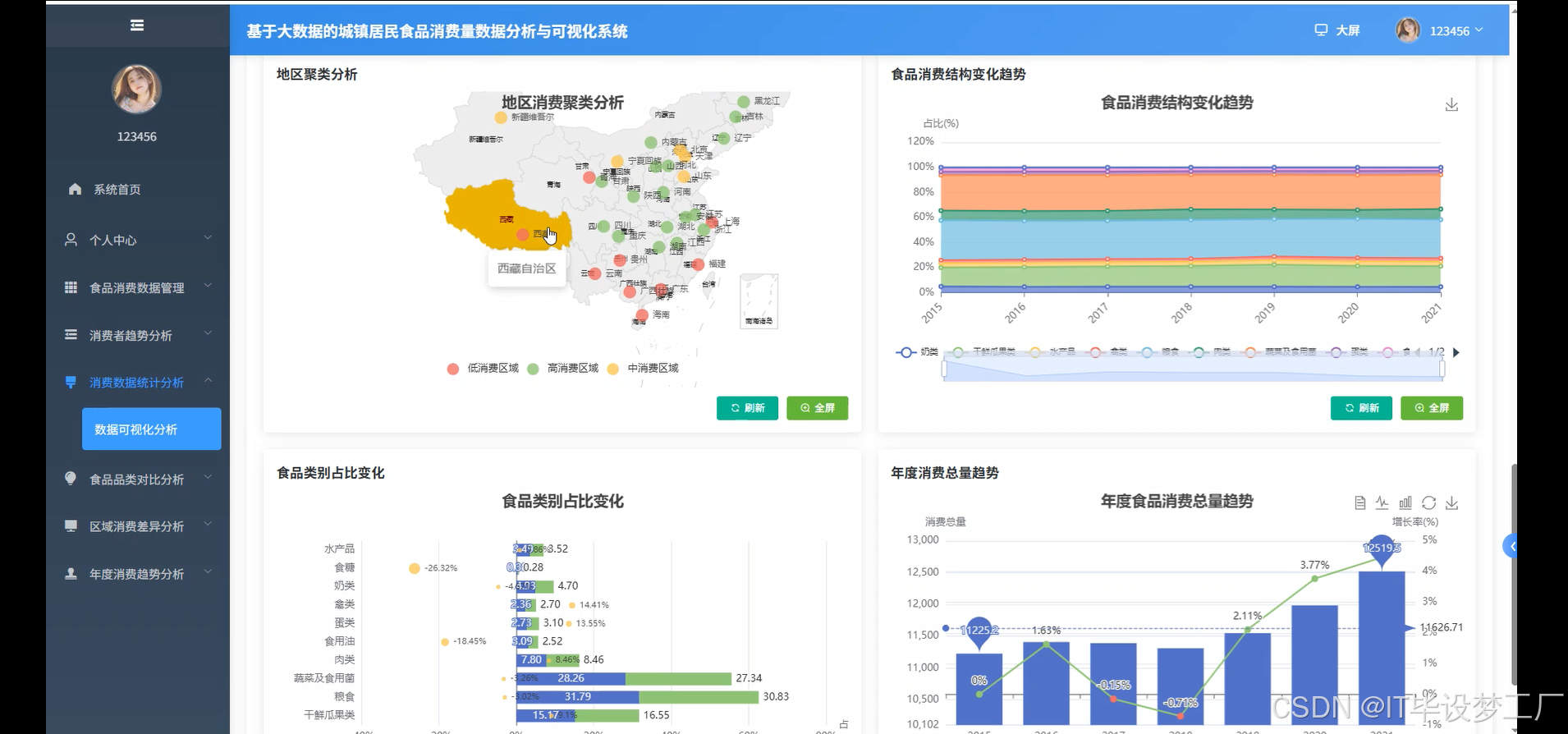
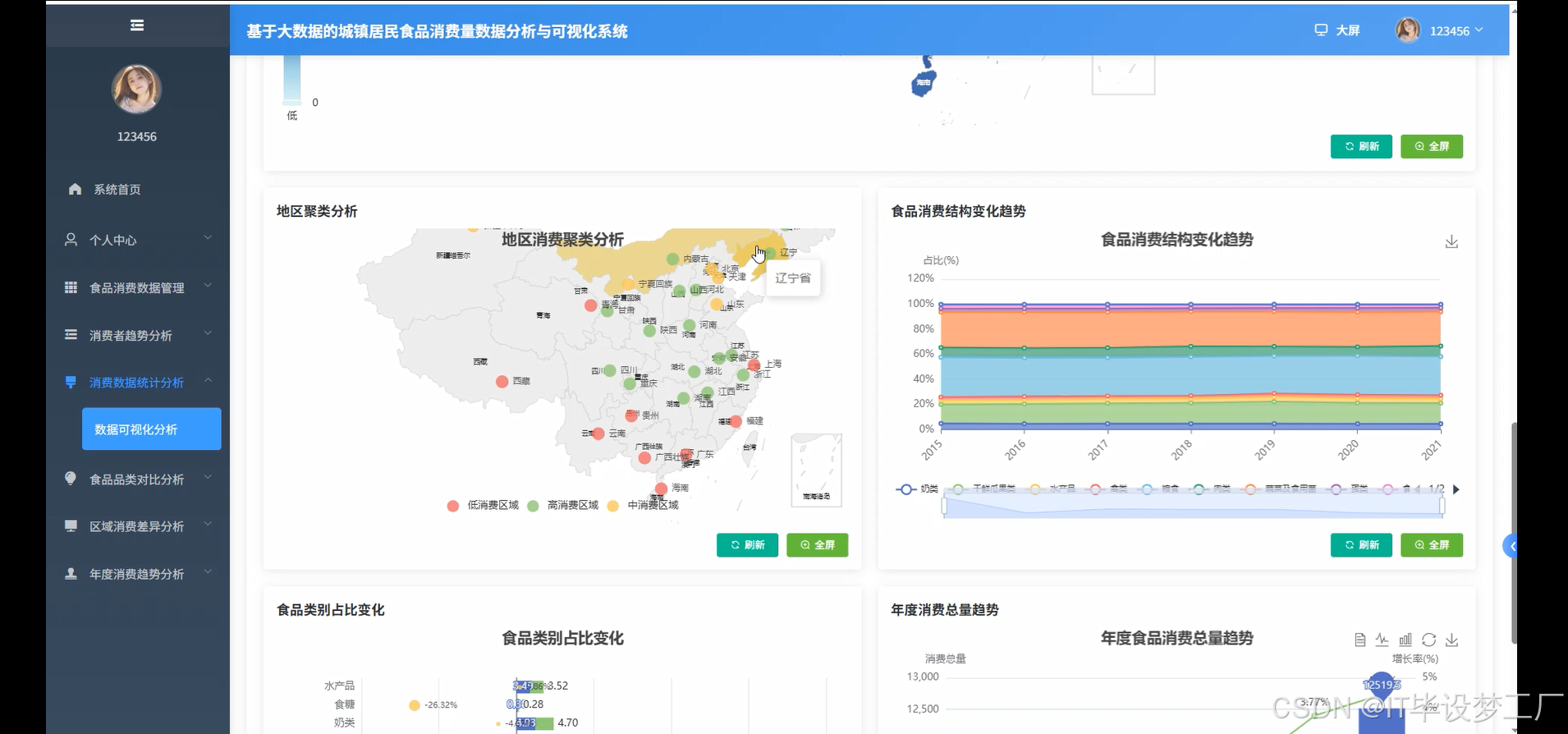
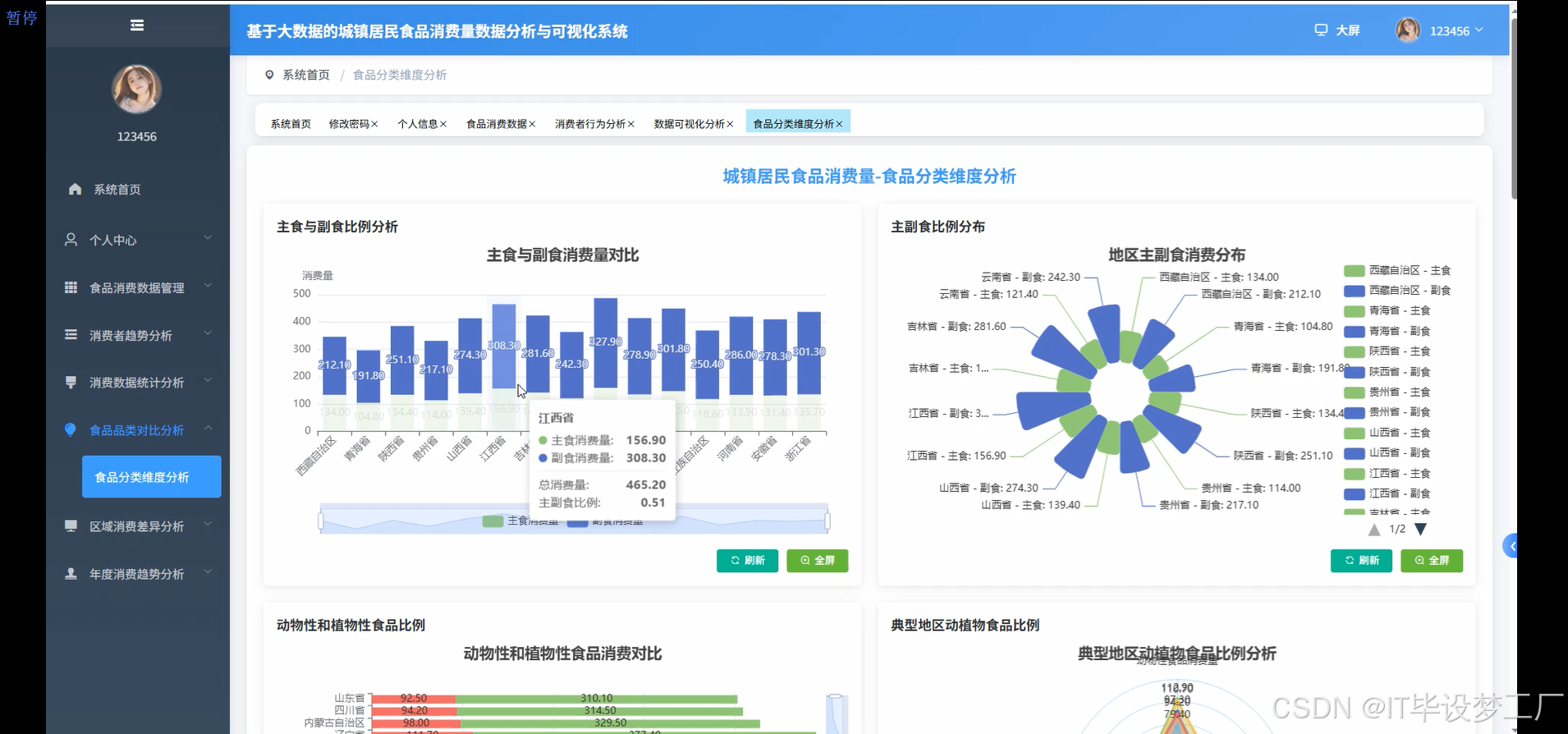
三、系统界面展示
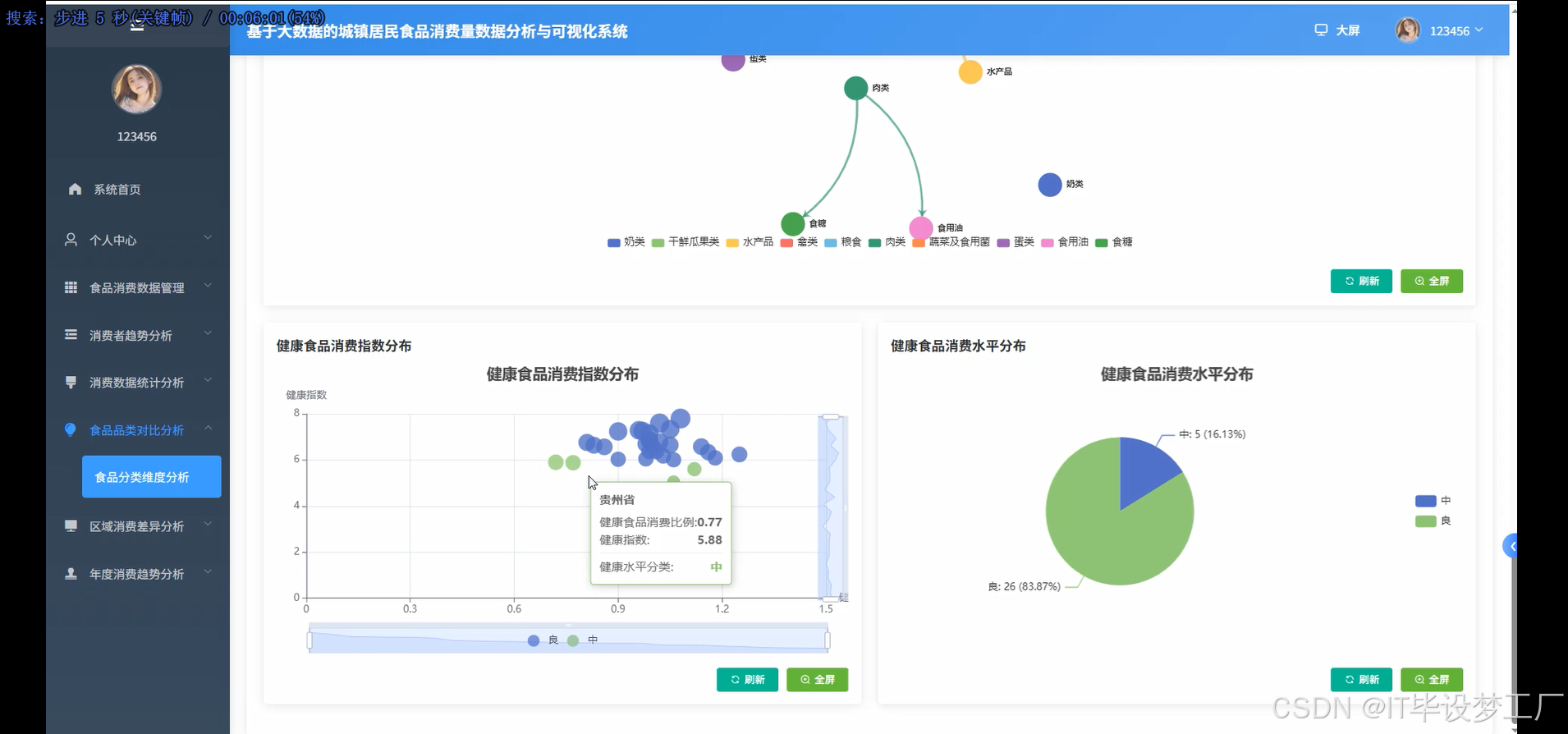
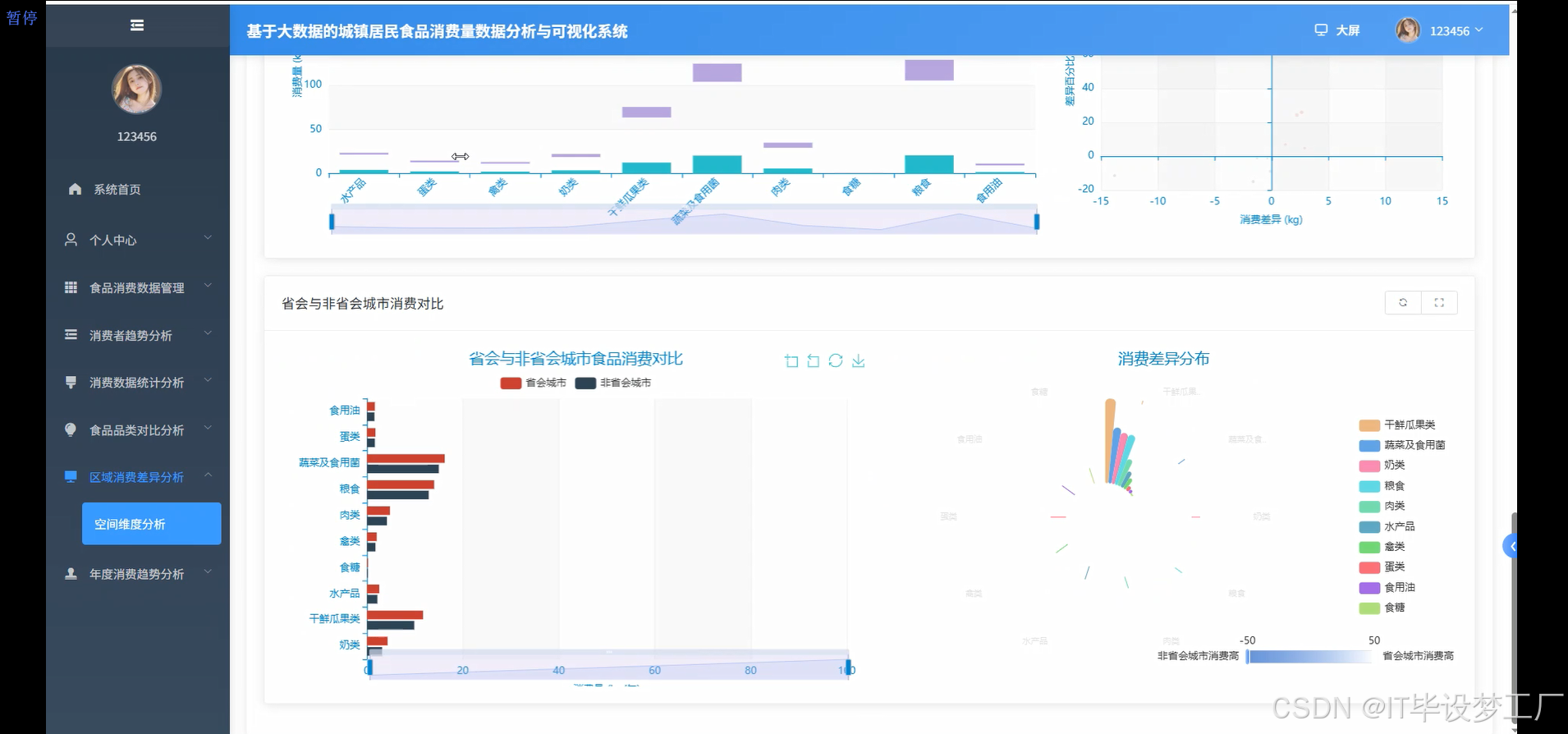
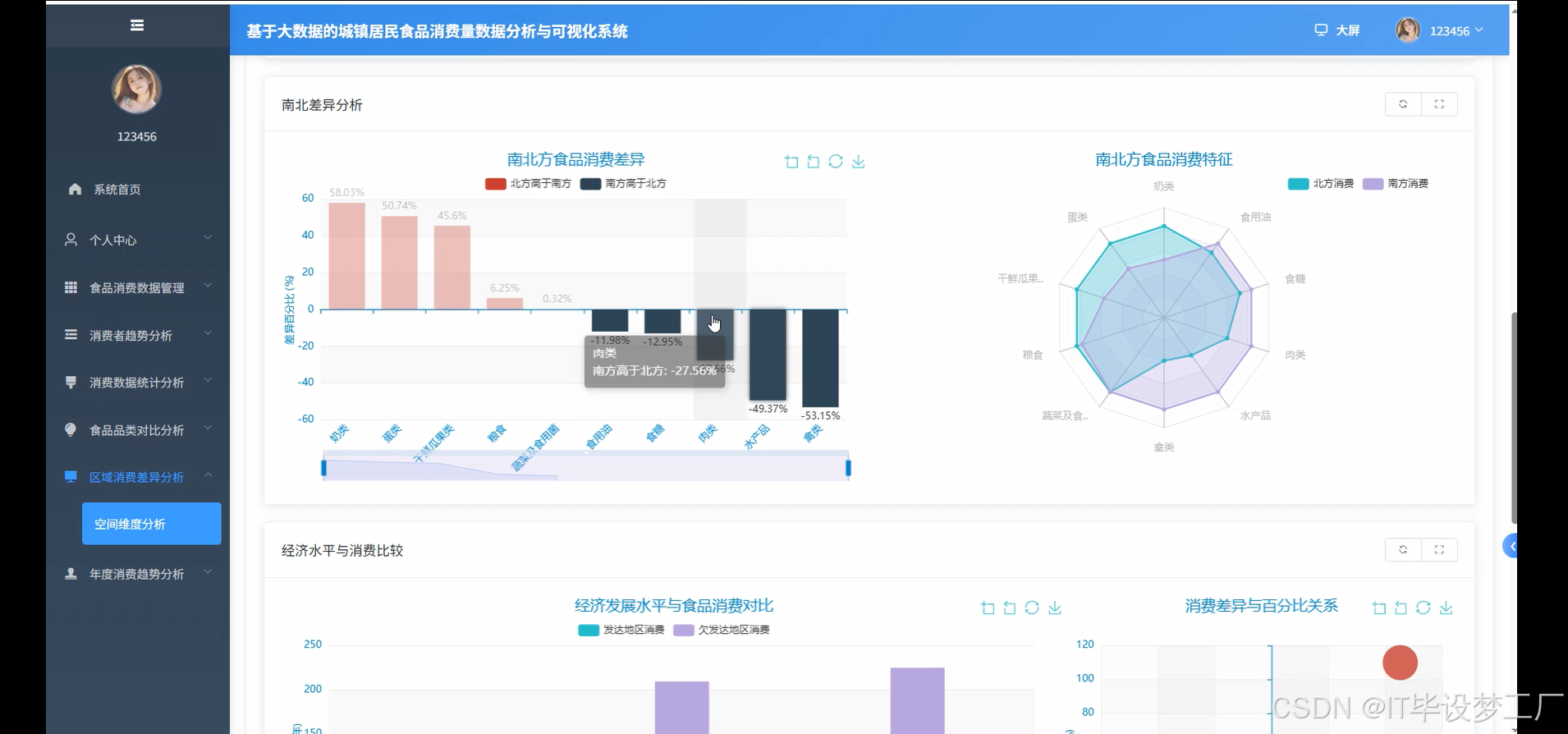
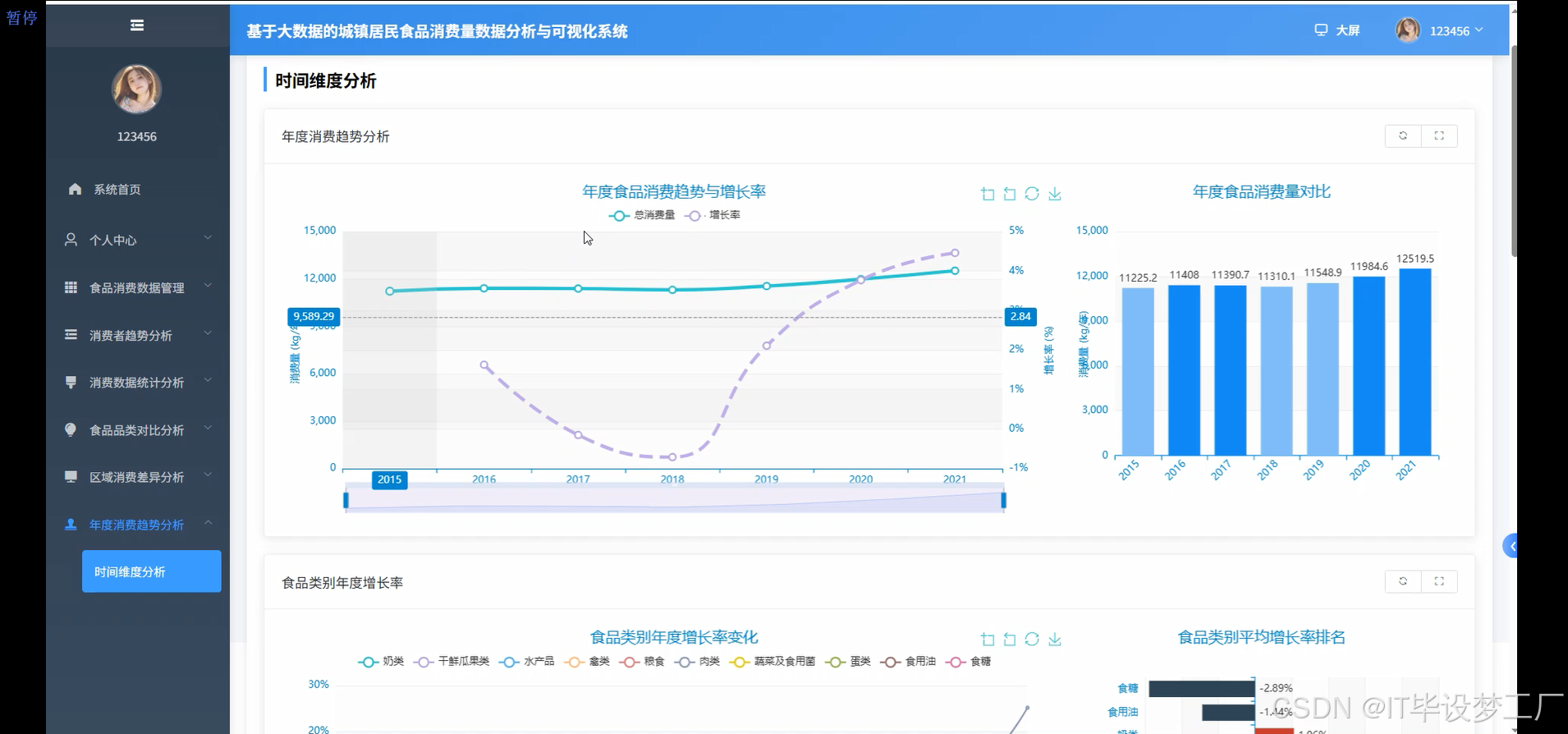
- 基于大数据的城镇居民食品消费量数据分析与可视化系统界面展示:

四、部分代码设计
- 项目实战-代码参考:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("Food Consumption Analysis").getOrCreate()
def annual_consumption_trend(data):food_data = spark.read.csv(data, header=True, inferSchema=True)food_data.createOrReplaceTempView("food_consumption")annual_trend_query = """SELECT year, SUM(consumption) as total_consumptionFROM food_consumptionGROUP BY yearORDER BY year"""annual_trend = spark.sql(annual_trend_query)return annual_trenddef process_annual_trend(data_path):annual_trend = annual_consumption_trend(data_path)annual_trend.show()process_annual_trend("food_data.csv")def consumption_growth_rate(data):food_data = spark.read.csv(data, header=True, inferSchema=True)food_data.createOrReplaceTempView("food_consumption")growth_rate_query = """SELECT year, food_category, (SUM(consumption) - LAG(SUM(consumption)) OVER (PARTITION BY food_category ORDER BY year)) / LAG(SUM(consumption)) OVER (PARTITION BY food_category ORDER BY year) * 100 as growth_rateFROM food_consumptionGROUP BY year, food_categoryORDER BY year, food_category"""growth_rate_data = spark.sql(growth_rate_query)return growth_rate_datadef process_growth_rate(data_path):growth_rate = consumption_growth_rate(data_path)growth_rate.show()process_growth_rate("food_data.csv")from pyspark.ml.clustering import KMeans
from pyspark.ml.feature import VectorAssembler
def region_clustering(data):food_data = spark.read.csv(data, header=True, inferSchema=True)assembler = VectorAssembler(inputCols=["meat", "dairy", "grain", "vegetables"], outputCol="features")clustered_data = assembler.transform(food_data)kmeans = KMeans(k=3, seed=1, featuresCol="features", predictionCol="cluster")model = kmeans.fit(clustered_data)clustered_result = model.transform(clustered_data)return clustered_resultdef process_clustering(data_path):clustered_result = region_clustering(data_path)clustered_result.show()process_clustering("food_data.csv")五、系统视频
- 基于大数据的城镇居民食品消费量数据分析与可视化系统-项目视频:
大数据毕业设计选题推荐-基于大数据的城镇居民食品消费量数据分析与可视化系统-Hadoop-Spark-数据可视化-BigData
结语
大数据毕业设计选题推荐-基于大数据的城镇居民食品消费量数据分析与可视化系统-Hadoop-Spark-数据可视化-BigData
想看其他类型的计算机毕业设计作品也可以和我说都有 谢谢大家!
有技术这一块问题大家可以评论区交流或者私我~
大家可以帮忙点赞、收藏、关注、评论啦~
源码获取:⬇⬇⬇
精彩专栏推荐⬇⬇⬇
Java项目
Python项目
安卓项目
微信小程序项目