Redis缓存雪崩缓存击穿缓存穿透的处理方式
当我们在项目中使用到redis的时候,那么势必会考虑如果出现缓存雪崩,缓存击穿,缓存穿透之后会怎么办。下面我们来讲讲解决方案
缓存击穿
什么是缓存击穿呢?当一个key是热点的时候,在不停的被高流量的请求进行访问的时候。如果key在瞬间出现了失效,那么这些大量的请求直接打到数据库中则会可能会导致整个服务的瘫痪或者性能的严重下降。这种情况则是缓存击穿。
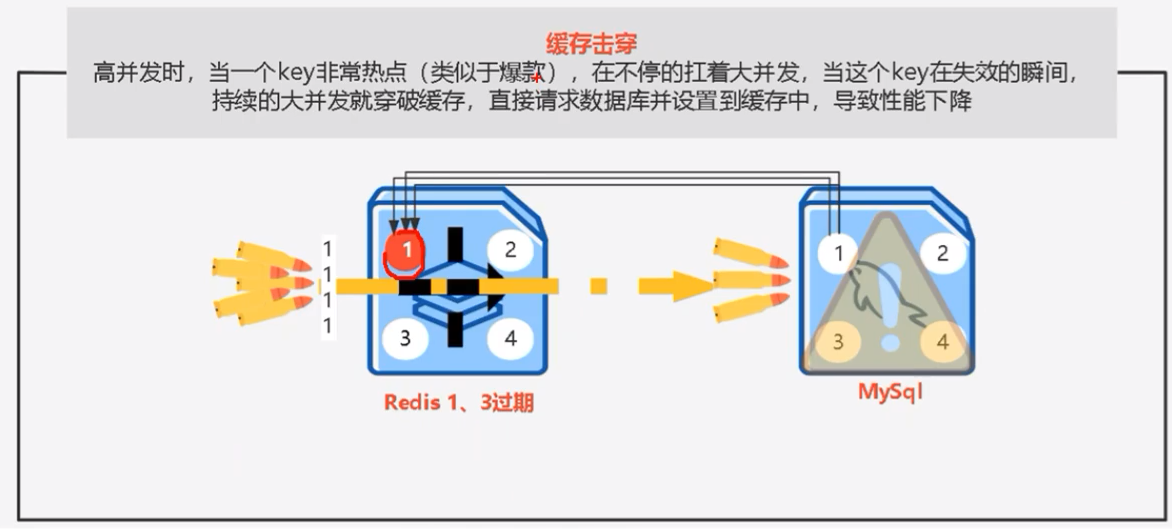
那么如何防止出现缓存击穿这种情况呢?
public Object getData(String key) {// 1. 尝试从缓存获取数据Object data = redis.get(key);if (data != null) {return data; // 缓存命中直接返回}// 2. 缓存未命中,获取键对应的锁Lock keyLock = keyLocks.computeIfAbsent(key, k -> new ReentrantLock());try {// 3. 尝试获取锁if (keyLock.tryLock(0, TimeUnit.SECONDS)) {try {// 4. 再次检查缓存(双重检查锁定)data = redis.get(key);if (data != null) {return data;}// 5. 从数据库加载数据data = db.query(key);if (data != null) {// 6. 设置缓存(可设置随机过期时间避免集体失效)int expireTime = 3600 + new Random().nextInt(300); // 基础时间+随机时间redis.setex(key, expireTime, data);} else {// 处理数据库也不存在的情况(防止缓存穿透)// 可设置空值或特殊标记短暂缓存redis.setex(key, 60, "NULL"); // 短暂缓存空值}return data;} finally {// 7. 释放锁keyLock.unlock();keyLocks.remove(key); // 从映射中移除锁}} else {// 8. 未获取到锁,等待并重试Thread.sleep(50);return getData(key); // 递归重试}} catch (InterruptedException e) {Thread.currentThread().interrupt();throw new RuntimeException("获取缓存中断", e);}}
}上述代码则是主要针对缓存击穿的解决方案:采用单机线程锁的方式来实现。当未在redis查询到当前数据的时候则通过获取当前key的单机锁来实现。并且进行双重校验(防止重复从mysql中取数据)。
为什么使用单机锁而不是分布式锁呢?如果一个集群中有多台机器,那么当前数据的最大并发量最多则是集群的机器数,这些并发量对于数据库来说是扛得住的。同时不采用分布式锁也降低了使用成本。
总的来说一般防止缓存击穿则是在查询不到缓存数据的时候采用单机锁或者分布式锁的方式保证只能一个线程来访问当前数据库这样就不会出现大量请求直接访问数据库的情况了。还有一种方式则是不设置过期时间,也就是key永久存在(不过一般不会这样因为会增大内存的压力)
缓存雪崩
什么是缓存雪崩呢?缓存雪崩则是同一时间出现大量的key过期导致整个系统直接访问数据库的请求过多出现性能下降。
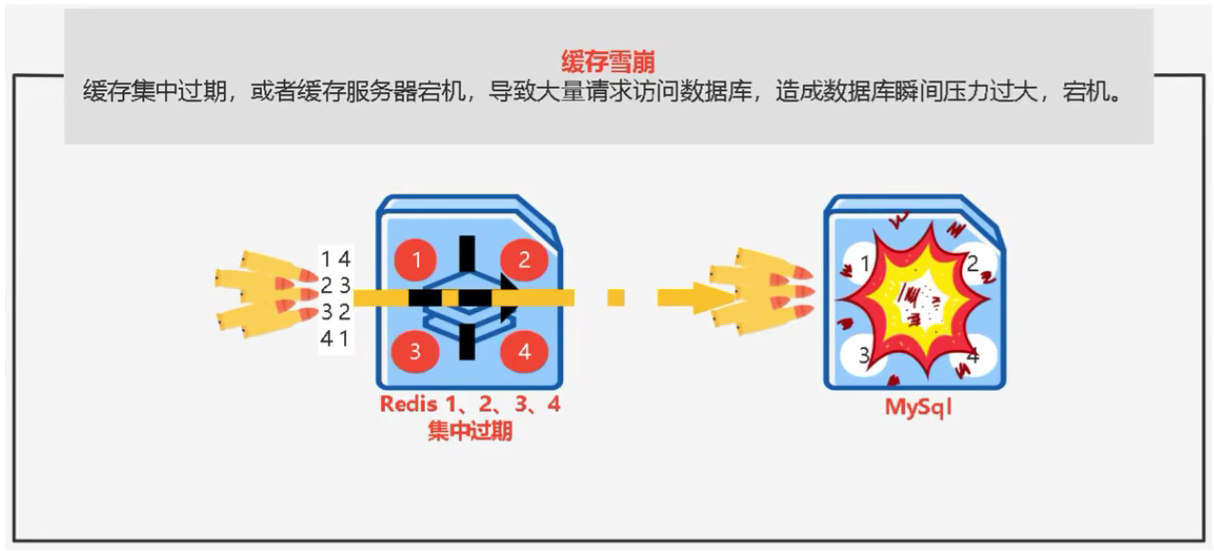
那么这种方式的预防方案则是每个key都加随机时间,这样将每个key散落在不同时刻过期从而减缓了整个系统的压力
if (keyLock.tryLock()) {try {// 4. 再次检查缓存(双重检查锁定)data = redis.get(key);if (data != null) {if ("NULL".equals(data)) {return null;}return data;}// 5. 从数据库加载数据data = db.query(key);// 6. 设置缓存,为每个key设置随机过期时间if (data != null) {// 为每个key生成不同的随机过期时间int expireTime = BASE_CACHE_TIME + random.nextInt(RANDOM_RANGE);redis.setex(key, expireTime, data);}return data;} finally {// 7. 释放锁并从映射中移除keyLock.unlock();keyLocks.remove(key);}} else {// 8. 未获取到锁,等待并重试(但有最大重试次数限制)if (retryCount < MAX_RETRY) {Thread.sleep(LOCK_WAIT_TIME);return getDataWithRetry(key, retryCount + 1);} else {// 超过最大重试次数,直接查询数据库(降级方案)return db.query(key);}}} catch (InterruptedException e) {Thread.currentThread().interrupt();// 中断时直接查询数据库return db.query(key);}}上述代码则是在将mysql数据库中的数据放回至redis中采用了随机时间的方式来实现的。
还有一种方式则是不添加过期时间
缓存穿透
缓存穿透则是在redis和数据库中都没有这个数据而大量请求请求这个数据则会一直绕过redis来访问数据库从而导致了整个系统的性能下降
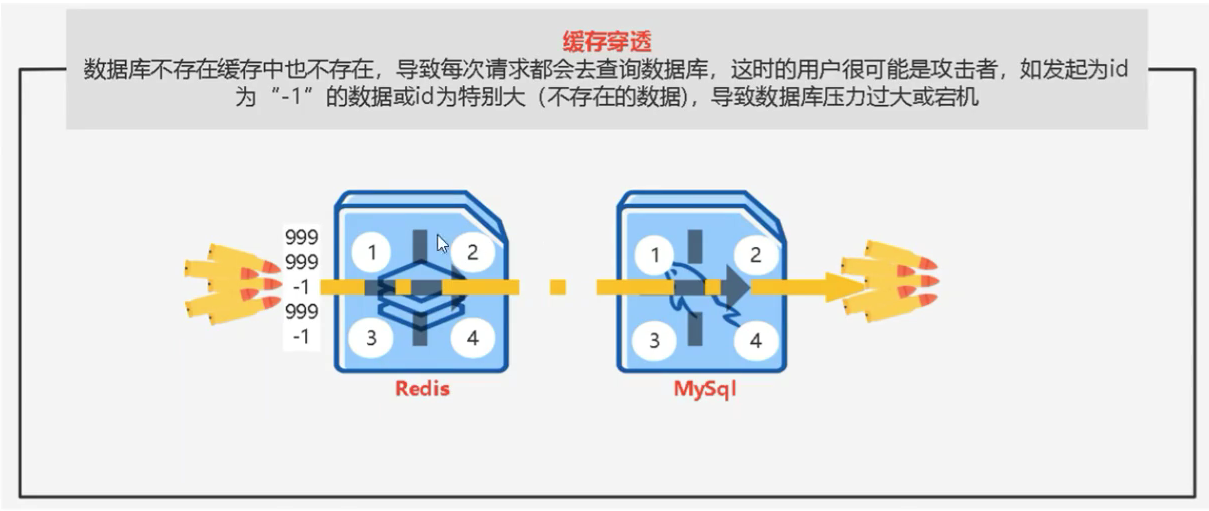
预防缓存穿透则是可以每次不管从数据库有没有取到数据都放在redis当中
3. 尝试获取锁(非阻塞方式)if (keyLock.tryLock()) {try {// 4. 再次检查缓存(双重检查锁定)data = redis.get(key);if (data != null) {if ("NULL".equals(data)) {return null;}return data;}// 5. 从数据库加载数据data = db.query(key);// 6. 设置缓存,为每个key设置随机过期时间if (data != null) {// 为每个key生成不同的随机过期时间int expireTime = BASE_CACHE_TIME + random.nextInt(RANDOM_RANGE);redis.setex(key, expireTime, data);} else {// 处理数据库也不存在的情况(防止缓存穿透)redis.setex(key, NULL_CACHE_TIME, "NULL"); // 短暂缓存空值}return data;} finally {// 7. 释放锁并从映射中移除keyLock.unlock();keyLocks.remove(key);}} else {// 8. 未获取到锁,等待并重试(但有最大重试次数限制)if (retryCount < MAX_RETRY) {Thread.sleep(LOCK_WAIT_TIME);return getDataWithRetry(key, retryCount + 1);} else {// 超过最大重试次数,直接查询数据库(降级方案)return db.query(key);}}} catch (InterruptedException e) {Thread.currentThread().interrupt();// 中断时直接查询数据库return db.query(key);}}或者采用布隆过滤器的方式来进行实现,布隆过滤器则有两种方式分别是白名单和黑名单。白名单则是将数据库有的数据放入到布隆过滤器中,而黑名单则是将redis和库都没有的数据放入到布隆过滤器中。这几种方式则是解决缓存穿透的预防方案
布隆过滤器有着可以判断当前数据是否可能存在而不会准确的判断一定存在。但是如果当前数据存在则不会误判,而当前数据如果不存在则可能误判为存在。