维度建模 —— 雪花模型 和 星型模型的优缺点
维度建模 —— 雪花模型 和 星型模型的优缺点
核心概念回顾
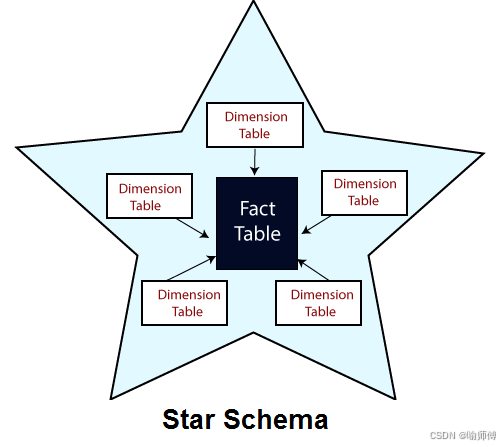
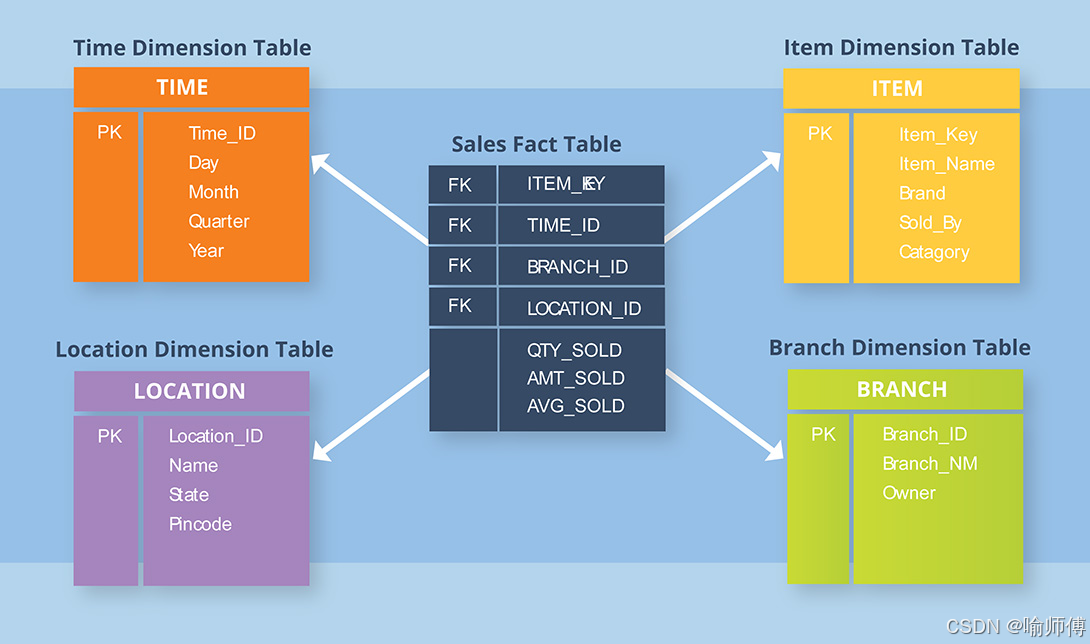
- 星型模型 (Star Schema):
- 结构: 一个中心事实表(Fact Table),直接连接多个维度表(Dimension Tables)。维度表是非规范化的,通常包含所有相关的属性,不进行拆分。
- 形状: 像一颗星星,事实表在中心,维度表像星芒一样向外辐射。
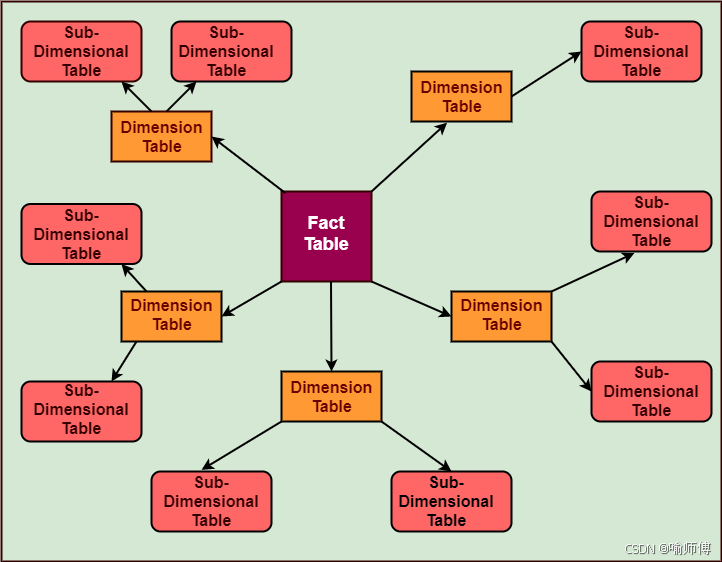
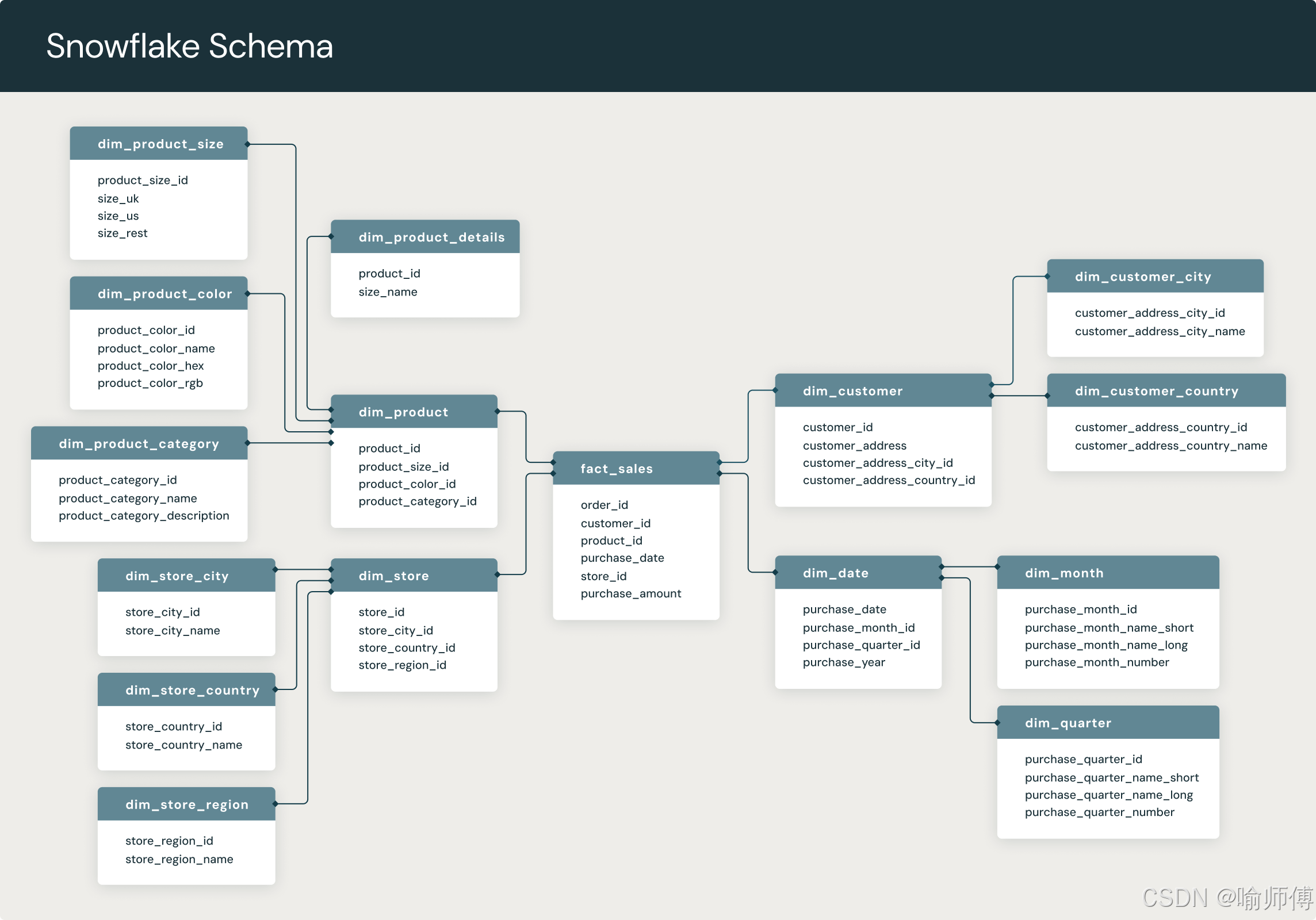
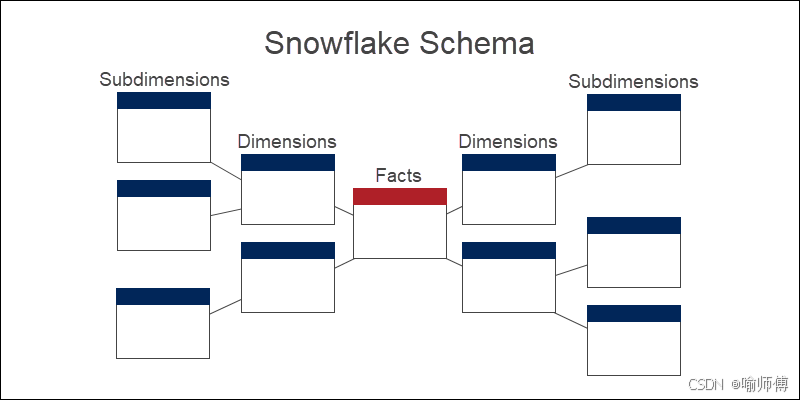
- 雪花模型 (Snowflake Schema):
- 结构: 也是以事实表为中心,但维度表是规范化的。一个维度表可能会被拆分成多个相关的表,形成层级结构。
- 形状: 像一片雪花,中心是事实表,维度表向外延伸,并且维度表本身也连接到更细粒度的“子维度”表。
优缺点对比
1. 星型模型 (Star Schema)

优点 (Pros):
- 查询性能优异:
- 这是最大的优势。由于维度表是非规范化的,查询通常只需要进行一次连接(JOIN) 就能从维度表获取所有需要的属性(如
Product表包含Product Name,Category,Subcategory等)。 - 减少了连接操作的数量和复杂度,查询执行速度快,尤其适合即席查询(Ad-hoc Queries)和OLAP分析。
- 这是最大的优势。由于维度表是非规范化的,查询通常只需要进行一次连接(JOIN) 就能从维度表获取所有需要的属性(如
- 结构简单,易于理解和设计:
- 模型直观,业务用户和开发人员容易理解数据结构和关系。
- 设计和维护相对简单。
缺点 (Cons):
- 数据冗余:
- 由于非规范化,维度表中存在重复数据。例如,在
Product维度表中,Category名称会为该类别下的每个产品重复存储。 会增加存储空间的占用。
- 由于非规范化,维度表中存在重复数据。例如,在
- 潜在的数据一致性风险:
- 如果同一个属性(如
Category Name)在多个地方存储,当需要更新时,必须确保所有相关记录都更新,否则可能导致数据不一致(虽然在维度表中这种情况较少,因为维度数据相对稳定)。
- 如果同一个属性(如
- 维护复杂性(相对):
- 当维度属性需要修改时(如产品类别重命名),可能需要更新大量记录。
2. 雪花模型 (Snowflake Schema)
优点 (Pros):
- 减少数据冗余,节省存储空间:
- 通过规范化,将重复的属性(如
Category,Subcategory)提取到单独的表中,只存储一次。 - 存储效率更高,尤其在维度属性非常多且存在明显层级关系时。
- 通过规范化,将重复的属性(如
- 数据一致性好:
- 规范化设计遵循了数据库范式,减少了数据更新异常。例如,修改一个
Category Name只需要在Category表中修改一次,所有引用它的Product记录都会自动反映更新。
- 规范化设计遵循了数据库范式,减少了数据更新异常。例如,修改一个
- 更符合第三范式 (3NF):
- 在需要遵循严格数据库设计原则的场景下,雪花模型更受欢迎。
- 维度结构更灵活:
- 更容易支持复杂的维度层级和共享维度(例如,
Geography维度可能被Customer和Store维度共享)。
- 更容易支持复杂的维度层级和共享维度(例如,
缺点 (Cons):
- 查询性能较低:
- 这是最主要的缺点。为了获取完整的维度信息,查询通常需要进行多次连接(JOIN)。例如,要获取产品的类别名称,可能需要连接
Fact Sales->Dim Product->Dim Subcategory->Dim Category。 - 多次连接会增加查询的复杂性和执行时间,影响OLAP和即席查询的响应速度。
- 这是最主要的缺点。为了获取完整的维度信息,查询通常需要进行多次连接(JOIN)。例如,要获取产品的类别名称,可能需要连接
- 结构复杂,不易理解:
- 模型层级较多,关系复杂,业务用户和开发人员理解起来更困难。
- 设计和维护的复杂度更高。
星型模型追求查询性能和简单性,牺牲了存储空间;雪花模型追求存储效率和数据一致性,牺牲了查询性能。在性能至上的数据仓库分析场景中,星型模型通常是首选。