深入探讨集成学习:Bagging与Boosting的核心原理与实践
在机器学习领域,集成方法通过组合多个基础模型来提升预测效果,这种方法能有效优化模型的稳定性和准确性。
其中,bagging和boosting是两种最主流的策略。今天,我们就来聊聊它们的基本概念、工作原理和实际应用,帮助大家更好地理解和运用这些技术。
理解集成学习的基础:自助法(Bootstrapping)
在深入bagging之前,我们先要了解一个核心概念:自助法。
简单来说,自助法是一种有放回的随机抽样方法。它通过从原始数据集中多次随机抽取样本(允许同一样本重复出现),创建多个子集。
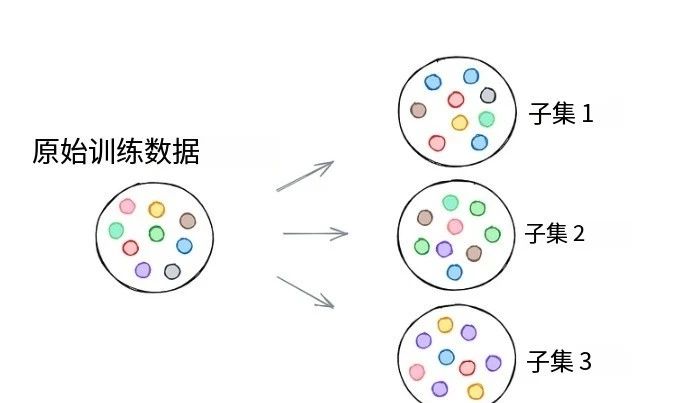
这种方法的关键在于引入数据多样性:每个子集为模型提供了不同的学习视角,从而在管理模型偏差和方差方面发挥重要作用。
最终,这能让模型更稳定可靠,避免单一数据视角导致的过拟合问题。
Bagging:降低方差的并行策略
自助法直接催生了bagging技术(全称Bootstrap Aggregating)。它的核心思想是在多个自助子集上训练独立的弱学习器(即性能略优于随机猜测的模型),然后将它们的结果聚合起来。
整个过程是并行的:模型独立训练,互不影响。
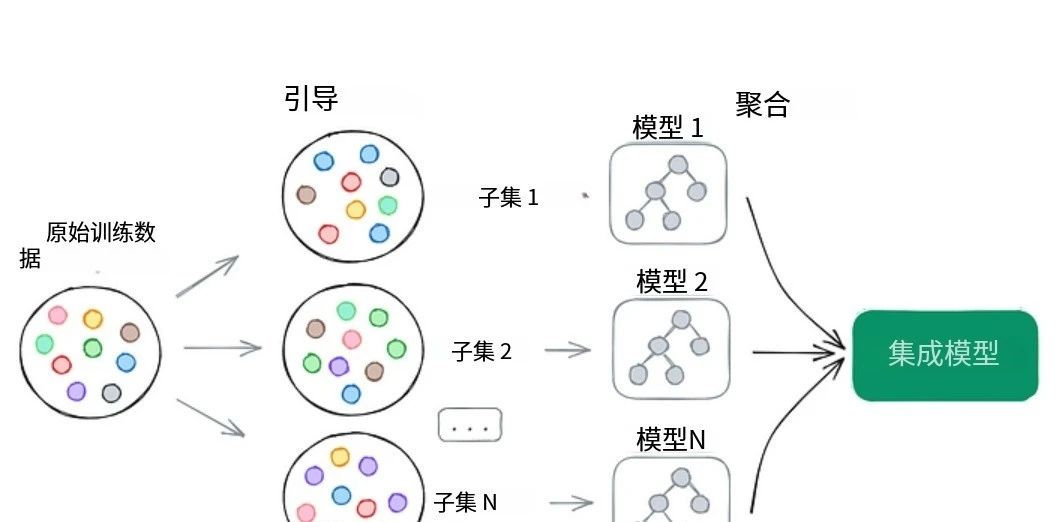
聚合方式取决于任务类型:
对于回归任务(预测连续值),最终输出通常是所有模型预测的平均值,这有助于减少方差。
对于分类任务(预测类别标签),则采用多数投票机制:每个模型投票给一个类别,得票最多的类别胜出。
Bagging的常见实现包括:
随机森林:在自助子集上训练决策树,并在每个分裂点随机选择特征子集。这减少了树之间的相关性,提升泛化能力。
极端随机树:在随机森林基础上,进一步随机化决策阈值,增加模型多样性。
通用bagging封装器(如scikit-learn中的工具):支持多种基础算法(如SVM或KNN),灵活性高。
总的来说,bagging擅长创建低方差、高稳定性的模型,特别适合处理高噪声数据集。
Boosting:迭代减少偏差的顺序策略
与bagging的并行方式不同,boosting采用顺序训练:每个后续模型都聚焦于纠正前一个模型的错误。初始模型在原始数据上训练,所有样本权重相同;之后,根据模型表现调整权重——错误预测的样本权重增加,正确预测的权重降低,这样后续模型会更关注难例。
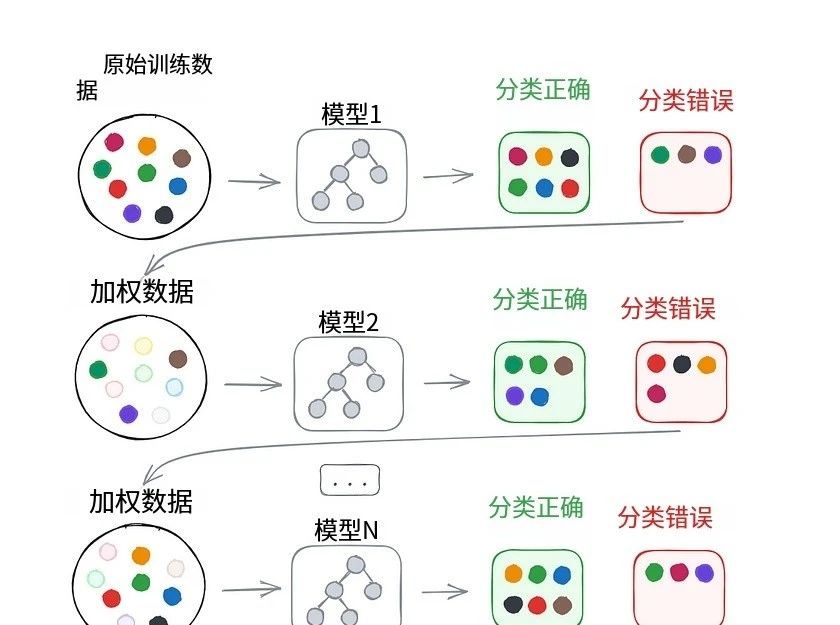
boosting的最终预测是加权组合:更准确的模型对结果贡献更大。常用算法包括:
AdaBoost:自适应调整样本权重,根据模型误差赋予性能得分,预测时加权投票。
梯度提升:让新模型拟合前一个模型的残差(预测与实际值的差),适用于任意可微损失函数。
XGBoost:梯度提升的高效实现,加入正则化防过拟合,处理缺失值能力强。
boosting在减少偏差方面表现出色,常用于提升模型精度,但要注意防止过拟合。
Bagging与Boosting的对比与选择
优点:Bagging降低方差,防止过拟合;Boosting减少偏差,提高准确性。
缺点:两者都增加计算成本,但通常值得投入,因为集成模型往往比单一模型更鲁棒。
选择建议:高噪声数据用bagging(如随机森林);低噪声但需高精度数据用boosting(如XGBoost)。
在实际应用中,我建议大家结合数据集特性选择策略。如果你想系统学习这些技术,我推荐一个实用的学习资源:一套AI科研入门学习方案,它基于数据与模型方法,分时序、图结构和影像三大实验室,针对不同数据类型提供学习路径。通过直播+录播形式,多位老师指导,能帮助你在几个月内掌握核心技能,并应用到论文写作中。
相关资料(包括入门教程和实战案例)我已整理出来了。
入门学习:https://pan.quark.cn/s/bd926fb5b773
这套方案我个人觉得很有帮助,它不是速成法,而是循序渐进的学习工具。如果你在机器学习路上遇到瓶颈,不妨从这里起步,结合实践深化理解。
集成学习是机器学习的精华所在,bagging和boosting各有千秋。
掌握它们,能让你在数据处理中游刃有余。希望这篇解析能帮到你,欢迎分享给身边的朋友或同学!如果你有疑问,随时交流。