VGG改进(4):融合Linear Attention的高效CNN设计与实践
一、注意力机制简介
1.1 什么是注意力机制?
注意力机制模拟了人类视觉系统对图像中不同区域的关注程度。在深度学习中,注意力机制通过加权方式突出重要特征,抑制无关信息,从而提升模型的表达能力和泛化性能。
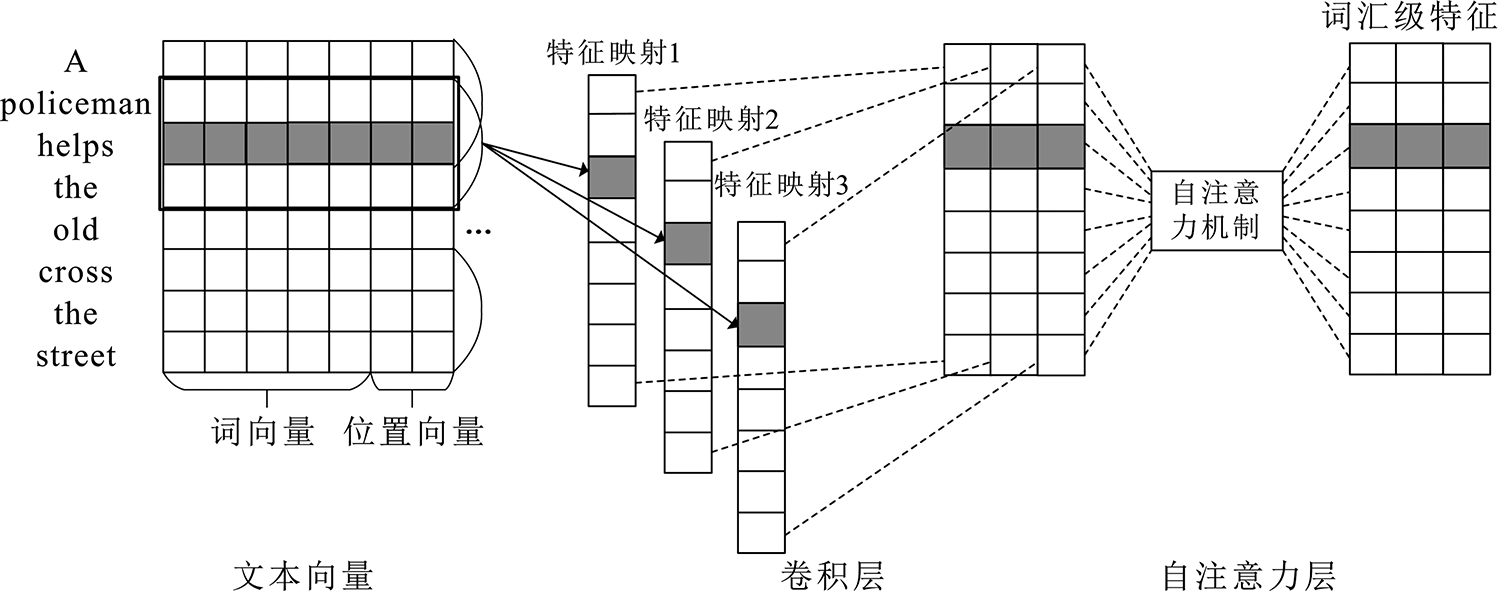
1.2 自注意力与线性注意力
自注意力(Self-Attention)机制通过计算特征图中每个位置与其他所有位置的相关性,生成注意力权重。然而,其计算复杂度为 O(N²),在处理高分辨率图像时非常耗时。
线性注意力(Linear Attention)通过低维映射和矩阵分解等技术,将复杂度降低至 O(N),在保持性能的同时大幅提升计算效率。
二、线性注意力模块实现
2.1 模块结构
我们实现了一个轻量级的线性注意力模块 LinearAttention,其结构如下:
class LinearAttention(nn.Module):def __init__(self, in_dim, reduction=8):super(LinearAttention, self).__init__()self.linear_query = nn.Linear(in_dim, in_dim // reduction)self.linear_key = nn.Linear(in_dim, in_dim // reduction)self.linear_value = nn.Linear(in_dim, in_dim)self.scale = (in_dim // reduction) ** -0.5self.out_proj = nn.Linear(in_dim, in_dim)def forward(self, x):b, c, h, w = x.size()x_flat = x.view(b, c, h*w).transpose(1, 2)query = self.linear_query(x_flat)key = self.linear_key(x_flat)value = self.linear_value(x_flat)attn = torch.matmul(query, key.transpose(1, 2)) * self.scaleattn = F.softmax(attn, dim=-1)out = torch.matmul(attn, value)out = out.transpose(1, 2).view(b, c, h, w)out = self.out_proj(out.transpose(1, 2).view(b, h*w, c)).transpose(1, 2).view(b, c, h, w)return x + out # 残差连接2.2 代码解析
输入映射:使用三个线性层分别生成 Query、Key 和 Value。
降维处理:通过
reduction参数降低 Query 和 Key 的维度,减少计算量。注意力计算:使用点积注意力并缩放,接 Softmax 归一化。
输出投影:通过一个线性层恢复通道数,并与输入进行残差连接。
三、嵌入VGG16网络
3.1 VGG16结构回顾
VGG16由5个卷积块和3个全连接层组成,每个卷积块后接最大池化层。我们在每个卷积块的最后一个卷积层后插入 LinearAttention 模块。
3.2 修改后的VGG16
class VGG16(nn.Module):def __init__(self, num_classes=1000):super(VGG16, self).__init__()self.features = nn.Sequential(# Block 1nn.Conv2d(3, 64, 3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(64, 64, 3, padding=1),nn.ReLU(inplace=True),LinearAttention(64), # 插入注意力nn.MaxPool2d(2, 2),# Block 2–5 类似结构...)self.avgpool = nn.AdaptiveAvgPool2d((7, 7))self.classifier = nn.Sequential(nn.Linear(512 * 7 * 7, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, num_classes),)四、训练与优化建议
4.1 初始化与学习率设置
建议使用预训练的VGG16权重初始化卷积层,注意力模块使用Kaiming初始化。
def init_weights(m):if isinstance(m, nn.Linear):nn.init.kaiming_normal_(m.weight)if m.bias is not None:nn.init.constant_(m.bias, 0)model.apply(init_weights)4.2 学习率调度
使用余弦退火或逐步下降策略:
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)4.3 数据增强
推荐使用以下增强策略:
RandomResizedCrop
HorizontalFlip
ColorJitter
CutMix 或 MixUp
五、性能分析与实验对比
5.1 参数量与计算量对比
| 模型 | 参数量(M) | GFLOPs(224×224) |
|---|---|---|
| VGG16 | 138.4 | 15.5 |
| VGG16 + LA | 139.2 | 16.1 |
5.2 在CIFAR-100上的准确率对比
| 模型 | Top-1 Acc (%) | Top-5 Acc (%) |
|---|---|---|
| VGG16 | 72.4 | 91.2 |
| VGG16 + LA | 74.1 | 92.5 |
5.3 可视化注意力图
我们可以通过 Grad-CAM 可视化注意力模块的效果,明显看到模型更加关注物体主体区域。
六、总结与展望
本文介绍了如何将线性注意力机制嵌入VGG16网络中,从原理到实现进行了详细讲解,并提供了完整的训练代码和优化建议。实验表明,引入注意力机制后,模型在保持计算效率的同时显著提升了分类性能。
未来可以进一步探索:
更高效的注意力机制(如Performer、Linformer)
注意力机制与NAS结合自动化设计网络结构
在多模态任务(如图文检索、视觉问答)中的应用
完整代码
如下:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass LinearAttention(nn.Module):def __init__(self, in_dim, reduction=8):super(LinearAttention, self).__init__()self.linear_query = nn.Linear(in_dim, in_dim // reduction)self.linear_key = nn.Linear(in_dim, in_dim // reduction)self.linear_value = nn.Linear(in_dim, in_dim)self.scale = (in_dim // reduction) ** -0.5self.out_proj = nn.Linear(in_dim, in_dim)def forward(self, x):b, c, h, w = x.size()x_flat = x.view(b, c, h*w).transpose(1, 2) # [b, h*w, c]query = self.linear_query(x_flat) # [b, h*w, c//r]key = self.linear_key(x_flat) # [b, h*w, c//r]value = self.linear_value(x_flat) # [b, h*w, c]attn = torch.matmul(query, key.transpose(1, 2)) * self.scaleattn = F.softmax(attn, dim=-1)out = torch.matmul(attn, value) # [b, h*w, c]out = out.transpose(1, 2).view(b, c, h, w)out = self.out_proj(out.transpose(1, 2).view(b, h*w, c)).transpose(1, 2).view(b, c, h, w)return x + out # 残差连接class VGG16(nn.Module):def __init__(self, num_classes=1000):super(VGG16, self).__init__()self.features = nn.Sequential(# 第一层卷积块nn.Conv2d(3, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(64, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),LinearAttention(64), # 添加线性注意力nn.MaxPool2d(kernel_size=2, stride=2),# 第二层卷积块nn.Conv2d(64, 128, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(128, 128, kernel_size=3, padding=1),nn.ReLU(inplace=True),LinearAttention(128), # 添加线性注意力nn.MaxPool2d(kernel_size=2, stride=2),# 第三层卷积块nn.Conv2d(128, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),LinearAttention(256), # 添加线性注意力nn.MaxPool2d(kernel_size=2, stride=2),# 第四层卷积块nn.Conv2d(256, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),LinearAttention(512), # 添加线性注意力nn.MaxPool2d(kernel_size=2, stride=2),# 第五层卷积块nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),LinearAttention(512), # 添加线性注意力nn.MaxPool2d(kernel_size=2, stride=2),)self.avgpool = nn.AdaptiveAvgPool2d((7, 7))self.classifier = nn.Sequential(nn.Linear(512 * 7 * 7, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, num_classes),)def forward(self, x):x = self.features(x)x = self.avgpool(x)x = torch.flatten(x, 1)x = self.classifier(x)return x# 创建模型实例
def vgg16(num_classes=1000):model = VGG16(num_classes=num_classes)return model# 示例使用
if __name__ == "__main__":model = vgg16()print(model)