(论文速读)OverLoCK -上下文混合动态核卷积
论文题目:OverLoCK: An Overview-first-Look-Closely-next ConvNet with Context-Mixing Dynamic Kernels(OverLoCK:具有上下文混合动态核的先看后看的卷积神经网络概述)
会议:CVPR2025
摘要:自上而下的注意在人类的视觉系统中起着至关重要的作用,大脑最初会对场景进行粗略的概述,以发现显著的线索(即先概述),然后进行更仔细的细粒度检查(即仔细观察下一步)。然而,现代ConvNet仍然局限于金字塔结构,连续对特征图进行下采样以扩展接受场,忽略了这一关键的仿生原理。我们提出了Overlock,这是第一个明确包含自顶向下注意力机制的纯ConvNet主干架构。与金字塔主干网络不同,我们的设计具有三个协同子网络的分支结构:1)编码低/中层特征的基本网络;2)通过粗略的全局上下文建模产生动态自上而下注意力的轻量级概述网络(即,概述优先);以及3)健壮的焦点网络,其执行由自上而下的注意力引导的更细粒度的感知(即,仔细观察)。为了充分释放自上而下注意的力量,我们进一步提出了一种新的上下文混合动态卷积(ContMix),它有效地模拟了长期依赖关系,同时即使在输入分辨率增加的情况下也保持了固有的局部归纳偏差,解决了现有卷积的关键限制。与现有方法相比,我们的锁显示出了显著的性能改进。例如,OVERLOCK-T达到了84.2%的Top-1准确率,大大超过了ConvNeXt-B,而只使用了大约三分之一的Flop/参数。在目标检测方面,我们的超锁-S在APB上明显超过MogaNet-B 1%。在语义切分方面,我们的Overlock-T显著提高了UniRepLKNet-T在MIU1.7%的性能。
源码链接:https://rb.gy/wit4jh.
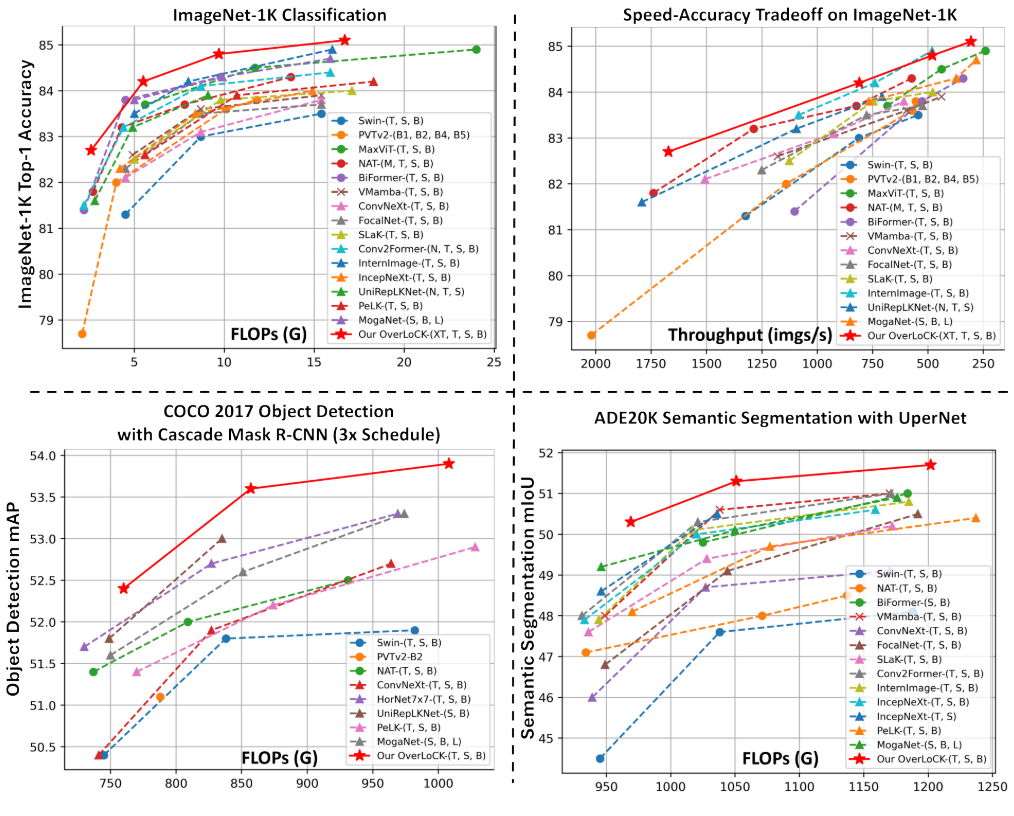
在深度学习领域,Vision Transformers 的崛起曾一度挑战了卷积神经网络(ConvNets)的统治地位。然而,最近来自香港大学的研究团队提出了一个突破性的解决方案——OverLoCK,这是第一个真正融合人类视觉系统"概览优先-仔细观察"机制的纯卷积网络。
🔍 问题的发现
传统的 ConvNets 虽然在计算机视觉任务中表现出色,但存在一个根本性的设计缺陷:它们采用的金字塔结构只能自下而上地处理信息,缺乏人类视觉系统中至关重要的自上而下的注意力机制。
想象一下你在观察一个复杂场景时的过程:
- 概览阶段:大脑首先快速获得场景的整体印象
- 细节关注:然后根据整体理解,有针对性地关注重要区域
而现有的 ConvNets 只能逐层处理,无法实现这种双向的信息流动。
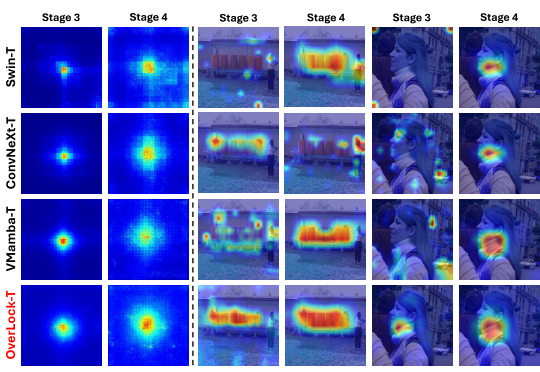
论文中的图2:(a)骨干网深层阶段最后一层(即阶段3和阶段4)的有效接受场(ERF)[47]比较。通过对ImageNet-1K验证集中的300多幅图像进行平均,得到了结果。如图所示,尽管是一个纯卷积神经网络,但在阶段3和阶段4中,OverLoCK-T的ERF都比强调全局建模的vammbat大。(b)使用GradCAM[56]对深度阶段(即阶段3和4)的输出计算的类激活图的可视化。这两个图像的类别标签是“Barrel”和“Neck Brace”。结果表明,尽管经典的层次模型可以在不同程度上捕获远程依赖关系,但它们很难用正确的类别标签定位对象,特别是在距离分类器较远的阶段3。相比之下,我们提出的新网络架构可以在阶段3和阶段4中产生更准确的类激活图。
💡 创新的解决方案
深度阶段分解策略(DDS)
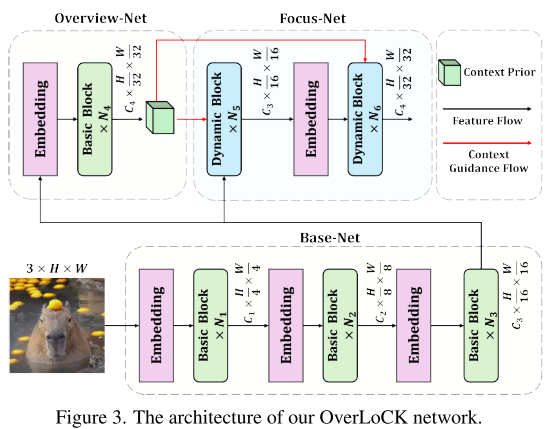
OverLoCK 的核心创新在于将传统的单一网络分解为三个协同工作的子网络:1. Base-Net:负责编码低级和中级特征,类似于传统 ConvNet 的前几层 2. Overview-Net:轻量级网络,快速生成全局概览,相当于"粗略一瞥" 3. Focus-Net:在概览指导下进行精细处理,实现"仔细观察"
上下文混合动态卷积(ContMix)
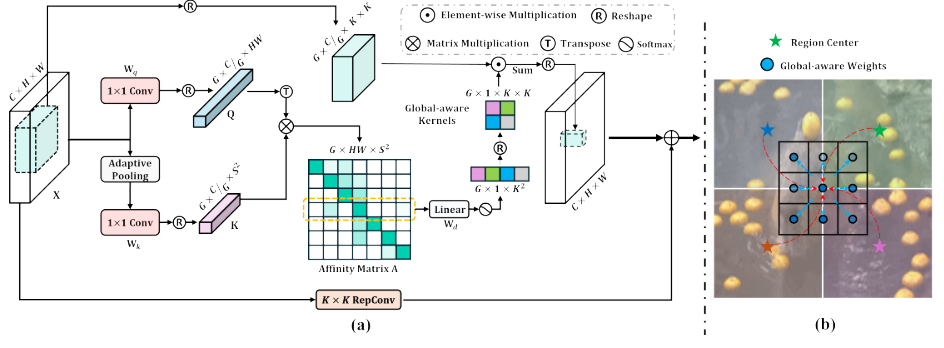
为了充分利用自上而下的上下文信息,研究团队设计了 ContMix,这是一种革命性的动态卷积机制:
- 全局感知:每个卷积核都包含全局上下文信息
- 局部精确:保持卷积的固有局部处理优势
- 动态适应:根据输入内容动态调整卷积权重
📊 性能突破
OverLoCK 在多个基准测试中创造了新的记录:
图像分类
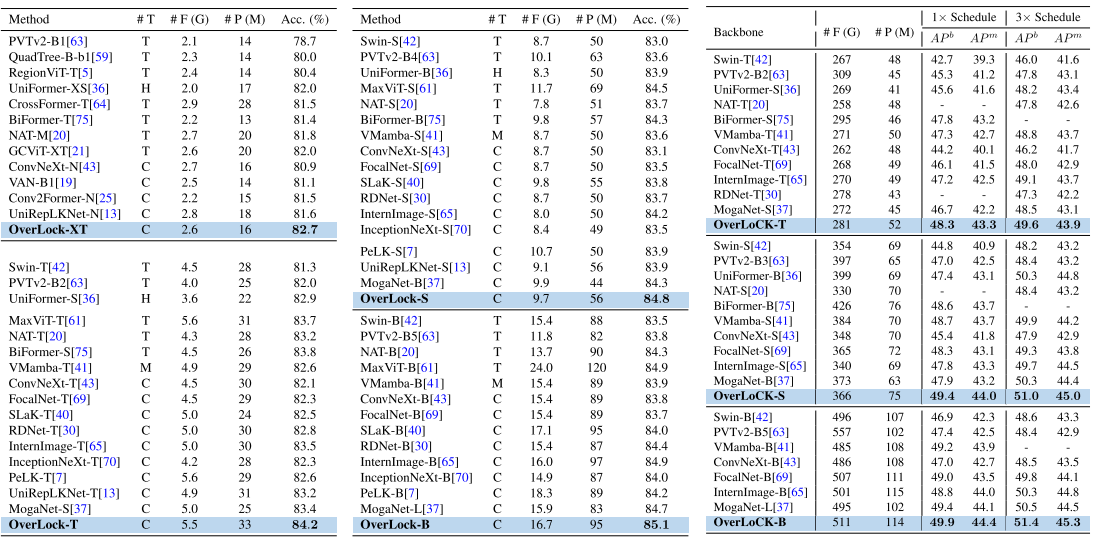
- OverLoCK-T:在 ImageNet-1K 上达到 84.2% Top-1 精度
- 相比 ConvNeXt-B,仅使用约 1/3 的计算量和参数量
目标检测
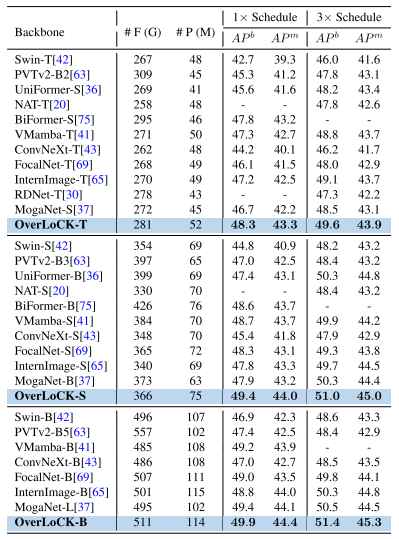
- OverLoCK-S:在 COCO 数据集上比 MogaNet-B 高出 1% APb
语义分割
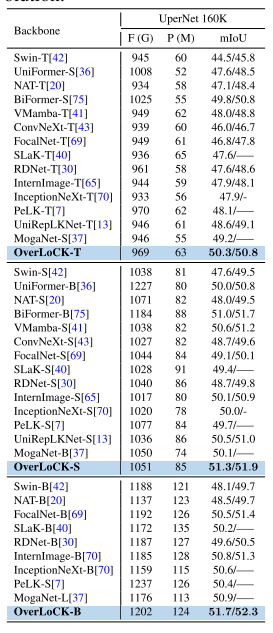
- OverLoCK-T:在 ADE20K 数据集上比 UniRepLKNet-T 提升 1.7% mIoU
🧠 技术深度解析
有效感受野分析
论文通过可视化有效感受野(ERF)证明,OverLoCK 虽然是纯卷积网络,但在 Stage 3 和 Stage 4 的感受野甚至超过了强调全局建模的 VMamba-T。
类激活图对比
通过 GradCAM 可视化显示,OverLoCK 能够更准确地定位目标物体,特别是在距离分类器较远的 Stage 3 中表现尤为突出。
🔬 消融实验洞察
研究团队进行了详尽的消融实验,证明了各个组件的重要性:
- DDS 策略:将网络分解为三个子网络带来了显著的性能提升
- 动态卷积:从静态到动态卷积的转换是性能飞跃的关键
- 上下文流动:适当的上下文信息流动设计至关重要
🌟 创新意义
OverLoCK 的成功不仅在于性能的提升,更在于它证明了:
- 生物启发的重要性:将人类视觉机制融入深度学习架构的巨大潜力
- ConvNets 的复兴:纯卷积网络仍有巨大的发展空间
- 架构设计的新思路:分解和重组网络结构的创新方法
💭 未来展望
OverLoCK 开启了一个新的研究方向:
- 更多生物启发机制:将更多人类视觉系统的特性引入深度学习
- 混合架构探索:结合不同类型网络的优势
- 效率与性能平衡:在保持高性能的同时进一步优化计算效率
🎯 结论
OverLoCK 代表了计算机视觉领域的一个重要里程碑。通过巧妙地融合生物启发的"概览优先-仔细观察"机制和创新的动态卷积技术,它不仅刷新了多项基准测试记录,更重要的是为未来的网络架构设计提供了新的思路。
这项工作提醒我们,有时候最好的创新来自于对自然界的深入观察和理解。正如人类视觉系统经过亿万年进化形成的高效机制,OverLoCK 证明了将这些机制转化为深度学习架构的巨大价值。
在人工智能快速发展的今天,OverLoCK 为我们指出了一条有希望的道路:不是简单地追求更大、更复杂的模型,而是通过深入理解和模仿自然智能,设计出既高效又强大的架构。