ICP语序文字点选验证逆向分析(含Py纯算源码)
文章目录
- 1. 写在前面
- 2. jsl分析
- 3. token生成
- 4. 语序点选识别
- 5. 语序点选逆向
【🏠作者主页】:吴秋霖
【💼作者介绍】:擅长爬虫与JS加密逆向分析!Python领域优质创作者、CSDN博客专家、阿里云博客专家、华为云享专家。一路走来长期坚守并致力于Python与爬虫领域研究与开发工作!
【🌟作者推荐】:对爬虫领域以及JS逆向分析感兴趣的朋友可以关注《爬虫JS逆向实战》《深耕爬虫领域》
未来作者会持续更新所用到、学到、看到的技术知识!包括但不限于:各类验证码突防、爬虫APP与JS逆向分析、RPA自动化、分布式爬虫、Python领域等相关文章
作者声明:文章仅供学习交流与参考!严禁用于任何商业与非法用途!否则由此产生的一切后果均与作者无关!如有侵权,请联系作者本人进行删除!
1. 写在前面
目前每一次查询要处理的流程略微繁琐,其中包括不限于jsl的处理、Token的授权、文字点选验证码识别、IP的限制
每一次查询请求的加载流程: cookie生成->auth授权token -> 语序文字点选验证码提交->获取查询数据
加速乐防护是知道创宇旗下加速乐平台用于网站安全防护的一种反爬虫及访问验证机制。它借助动态生成及校验Cookie,区分正常用户和爬虫程序,防止网站数据被恶意爬取
2. jsl分析
jsl相关的文章之前作者也有更新过,目前市面上很多防护类的产品或者SDK在不同版本中差异不大(一通则全通~)。之前看过一次这个网站在首页加载的时候,会有几次521然后再200正常加载,其实这个过程它就是在set cookie,请求如下:

这里我们可以点开前面两次521的响应,返回的两段JS代码。先看第一段代码给document.cookie赋值一个字符串,而这个字符串是由固定字符跟JavaScript表达式计算的结果拼接而成的。拆解后得: cookie名、值、属性,如下所示:
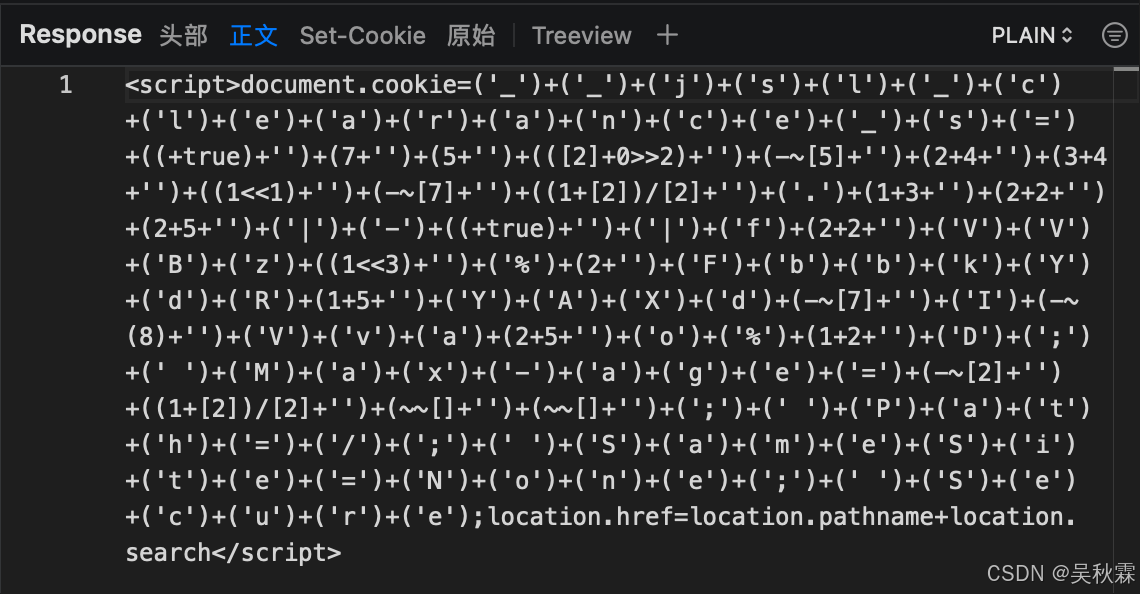
客户端必须执行这些代码才能得到有效的cookie用于后续的请求,这里在浏览器运行一下,可以看到拼接后直接得到字符串__jsl_clearance_s,如下所示:

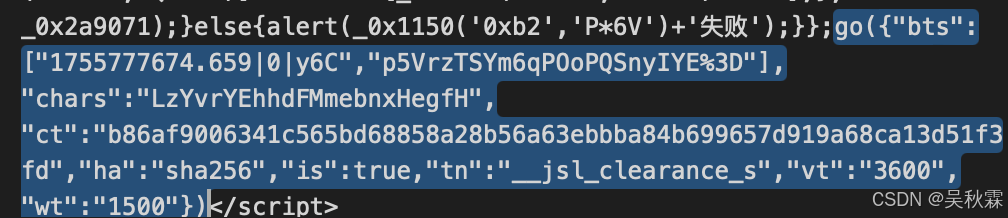
第二次521同样返回了一堆JS代码,经过了多重混淆。同样是来实现动态生成cookie的,核心逻辑通过go函数生成一个符合要求的验证字符串用于设置__jsl_clearance_s,其中_0x124cb9是核心生成函数,负责遍历字符集、拼接字符串、计算哈希,核心代码如下所示:
function go(_0x431d65) {var _0x56d876 = {};_0x56d876.mRQMB = function (_0xb0802b, _0x3ab73e) {return _0xb0802b != _0x3ab73e;};_0x56d876.Yktqk = function (_0x2b581d, _0x5db2cb) {return _0x2b581d - _0x5db2cb;};_0x56d876.RhMpI = function (_0x131a25, _0x251f4b, _0x3da4e7) {return _0x131a25(_0x251f4b, _0x3da4e7);};_0x56d876.QqiyR = function (_0xd46cbf, _0x388c97) {return _0xd46cbf === _0x388c97;};_0x56d876.Btcke = function (_0x1dece7, _0x111514) {return _0x1dece7 < _0x111514;};_0x56d876.vTMTG = function (_0x28f1d9, _0x1ee929) {return _0x28f1d9 !== _0x1ee929;};_0x56d876.IZRZA = "WMlWc";_0x56d876.gyivY = function (_0x26de5f, _0x2ee888) {return _0x26de5f + _0x2ee888;};_0x56d876.eBEGq = function (_0x29cba2, _0x31abed) {return _0x29cba2 == _0x31abed;};_0x56d876.hRMbY = function (_0x4b350f, _0x54e8ba) {return _0x4b350f(_0x54e8ba);};_0x56d876.DjTHy = function (_0x394f49, _0x112485) {return _0x394f49 !== _0x112485;};_0x56d876.gQtlV = "nxYiJ";_0x56d876.HxPMa = function (_0x530626, _0x1bad84) {return _0x530626 + _0x1bad84;};_0x56d876.cCcWW = function (_0x4256ac, _0x19e0bd) {return _0x4256ac + _0x19e0bd;};_0x56d876.qFdqL = "; path =" + " /";_0x56d876.NxtWP = function (_0xba3663, _0x3886e1) {return _0xba3663 + _0x3886e1;};_0x56d876.emWst = function (_0x20f543) {return _0x20f543();};_0x56d876.slBpB = function (_0xdbe318, _0x33438c, _0x450262) {return _0xdbe318(_0x33438c, _0x450262);};_0x56d876.IXiow = function (_0x39a21, _0x4e8394) {return _0x39a21(_0x4e8394);};_0x56d876.rsiWV = "请求验证失败";function _0x52dcb3() {var _0x370a6e = window["navigato" + "r"]["userAgen" + "t"];var _0x51ffbe = ["Phantom"];for (var _0x4df905 = 0; _0x4df905 < _0x51ffbe.length; _0x4df905++) {if (_0x56d876.mRQMB(_0x370a6e.indexOf(_0x51ffbe._0x4df905), -1)) {return true;}}if (window["callPhan" + "tom"] || window._phantom || window.Headless || window["navigato" + "r"]["webdrive" + "r"] || window["navigato" + "r"]["__driver" + "_eva" + "luat" + "e"] || window["navigato" + "r"]["__webdri" + "ver_" + "eval" + "uate"]) {return true;}};if (_0x56d876.emWst(_0x52dcb3)) {return;}var _0x47258d = new Date();function _0x124cb9(_0x4a8fda, _0x4f069f) {var _0x258a93 = {};_0x258a93.HRHuC = function (_0x4a6d6b, _0x204cd9, _0x16c83d) {return _0x4a6d6b(_0x204cd9, _0x16c83d);};_0x258a93.WGfIR = function (_0x28004d, _0x29a3b6, _0x36025e) {return _0x28004d(_0x29a3b6, _0x36025e);};_0x258a93.OXDXT = function (_0x47e550, _0x1626bc, _0x28271f, _0x50db3d) {return _0x47e550(_0x1626bc, _0x28271f, _0x50db3d);};_0x258a93.hklxW = function (_0x54f546, _0x3293e3) {return _0x56d876.Yktqk(_0x54f546, _0x3293e3);};_0x258a93.hbhuE = function (_0x413798, _0x101213) {return _0x413798 % _0x101213;};_0x258a93.hRdIR = function (_0x32129a, _0x36e601) {return _0x32129a * _0x36e601;};_0x258a93.ZrnuI = function (_0x4e5851, _0x1a930d) {return _0x4e5851 | _0x1a930d;};_0x258a93.BDoWL = function (_0x1528db, _0xbd6e94, _0x4e0f63, _0x54dd78) {return _0x1528db(_0xbd6e94, _0x4e0f63, _0x54dd78);};_0x258a93.wiOax = function (_0x518b47, _0x3711da, _0x3b17e6) {return _0x56d876.RhMpI(_0x518b47, _0x3711da, _0x3b17e6);};if (_0x56d876.QqiyR("vUatf", "vUatf")) {var _0x560343 = _0x431d65.chars.length;for (var _0x5a196a = 0; _0x5a196a < _0x560343; _0x5a196a++) {for (var _0x184814 = 0; _0x56d876.Btcke(_0x184814, _0x560343); _0x184814++) {if (_0x56d876.vTMTG("hbwDk", _0x56d876.IZRZA)) {var _0x2b5b90 = _0x56d876.gyivY(_0x56d876.gyivY(_0x4f069f.0 + _0x431d65.chars.substr(_0x5a196a, 1), _0x431d65.chars.substr(_0x184814, 1)), _0x4f069f.1);if (_0x56d876.eBEGq(_0x56d876.hRMbY(hash, _0x2b5b90), _0x4a8fda)) {if (_0x56d876.DjTHy(_0x56d876.gQtlV, _0x56d876.gQtlV)) {a = _0x258a93.HRHuC(AddUnsigned, a, AddUnsigned(_0x258a93.WGfIR(AddUnsigned, _0x258a93.OXDXT(I, b, c, d), x), ac));return AddUnsigned(RotateLeft(a, s), b);} else {return [_0x2b5b90, new Date() - _0x47258d];}}} else {lWordCount = _0x258a93.hklxW(lByteCount, _0x258a93.hbhuE(lByteCount, 4)) / 4;lBytePosition = _0x258a93.hRdIR(lByteCount % 4, 8);lWordArray.lWordCount = _0x258a93.ZrnuI(lWordArray.lWordCount, sMessage["charCode" + "At"](lByteCount) << lBytePosition);lByteCount++;}}}} else {a = AddUnsigned(a, AddUnsigned(_0x258a93.WGfIR(AddUnsigned, _0x258a93.BDoWL(H, b, c, d), x), ac));return AddUnsigned(_0x258a93.wiOax(RotateLeft, a, s), b);}};var _0x3ddaf8 = _0x124cb9(_0x431d65.ct, _0x431d65.bts);if (_0x3ddaf8) {var _0x2645d6;if (_0x431d65.wt) {_0x2645d6 = parseInt(_0x431d65.wt) > _0x3ddaf8.1 ? _0x56d876.Yktqk(parseInt(_0x431d65.wt), _0x3ddaf8.1) : 500;} else {_0x2645d6 = 1500;}_0x56d876.slBpB(setTimeout, function () {var _0x31854f = _0x56d876.HxPMa(_0x56d876.HxPMa(_0x56d876.cCcWW(_0x431d65.tn, "="), _0x3ddaf8.0), ";Max-age" + "=") + _0x431d65.vt + _0x56d876.qFdqL;if (_0x431d65.is) {_0x31854f = _0x56d876.NxtWP(_0x31854f, "; SameSi" + "te=N" + "one;" + " Sec" + "ure");}document.cookie = _0x31854f;location.href = location.pathname + location.search;}, _0x2645d6);} else {_0x56d876.IXiow(alert, _0x56d876.rsiWV);}
};
go({"bts": ["1755776815.763|0|WFi", "olnk2cex8wlwgbEMH%2Fzeow%3D"],"chars": "IykmSifEzbnjcdKImXgjrh","ct": "c327d34a93e250d59efe4ecbc58e004f","ha": "md5","is": true,"tn": "__jsl_clearance_s","vt": "3600","wt": "1500"
});
_0x431d65整个[]对象,包含chars|ha|ct,_0x4a8fda跟_0x4f069f分别是对象里面的ct|bts最后通过双重循环遍历字符集来生成字符组合,如下所示:
// 外层循环
for (var _0x5a196a = 0; _0x5a196a < _0x560343; _0x5a196a++)
// 内层循环
for (var _0x184814 = 0; _0x56d876.Btcke(_0x184814, _0x560343); _0x184814++)// 字符串生成逻辑对应(基于bts数组)
_0x2b5b90 = _0x56d876.gyivY(_0x56d876.gyivY(_0x4f069f.0 + _0x431d65.chars.substr(_0x5a196a, 1), _0x431d65.chars.substr(_0x184814, 1)), _0x4f069f.1)// 哈希验证逻辑对应
if (_0x56d876.eBEGq(_0x56d876.hRMbY(hash, _0x2b5b90), _0x4a8fda))// 返回值对应
return [_0x2b5b90, new Date() - _0x47258d]
上面的那个hash函数则是根据ha参数选择使用对应算法,有几种情况除了上面第一次贴的md5还有sha1|sha256,如下所示:
bts基础字符串片段数组,chars拼接的动态字符串,ct目标哈希值,ha使用的哈希算法,经过上面的分析流程,这里对最后一次请求cookies的加密进行实现,算法如下所示:
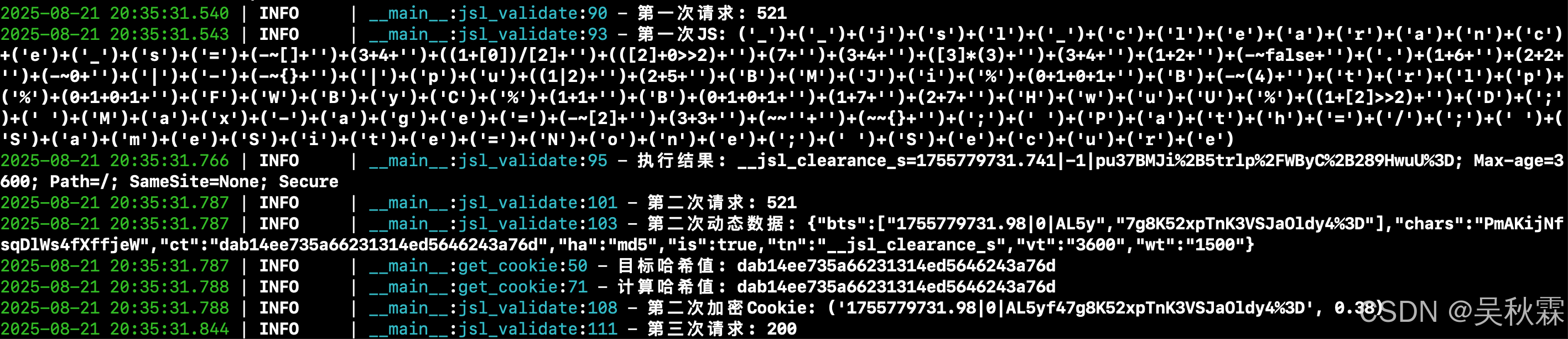
def get_cookie(data: dict) -> tuple:start_time = time.time() * 1000target_hash = data['ct']bts = data['bts']chars = data['chars']hash_type = data['ha']hash_functions = {'md5': lambda s: hashlib.md5(s.encode()).hexdigest(),'sha1': lambda s: hashlib.sha1(s.encode()).hexdigest(),'sha256': lambda s: hashlib.sha256(s.encode()).hexdigest()}if hash_type not in hash_functions:raise ValueError(f"不支持的哈希类型: {hash_type},支持的类型为md5/sha1/sha256")chars_len = len(chars)for i in range(chars_len): # 外层循环for j in range(chars_len): # 内层循环candidate = f"{bts[0]}{chars[i]}{chars[j]}{bts[1]}" current_hash = hash_functions[hash_type](candidate)if current_hash == target_hash:cost_time = time.time() * 1000 - start_timereturn (candidate, round(cost_time, 2))return (None, 0)
通过嵌套循环遍历字符集chars的所有索引组合(i和j)生成待验证的字符串candidate,与JS中的_0x2b5b90拼接保持逻辑完全一致,最后调用hash_functions中对应的哈希函数,对拼接的candidate字符串计算哈希值(16进制字符串),在内循环中计算哈希是否相同寻找哈希值匹配的字符串,运行如下:
如上所示,至此,完成了第一部分jsl的cookie流程生成与处理
3. token生成
接下来,我们需要处理auth接口,这个接口每一次刷新请求接口会返回一个token用于后续的请求(连贯且有时效性),这里需要还原一下,动态请求生成用以后续每一次接口请求头中的Token参数,如下所示:


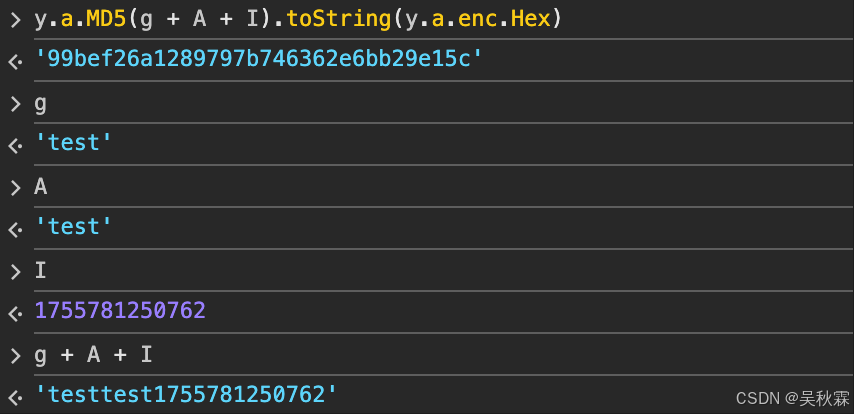
authKey这个参数是一个MD5,固定两个test字符串加一个时间戳即可,如下所示:

import time
import hashlib
import requestsdef auth_key(g: str, A: str, t: int) -> str:combined = g + A + str(t)md5_hash = hashlib.md5()md5_hash.update(combined.encode('utf-8'))return md5_hash.hexdigest()def get_auth_token():headers = {} # 自行放置url = "https://***/icpproject_query/api/auth"times = int(time.time() * 1000)data = {"authKey": auth_key('test', 'test', times),"timeStamp": str(times)}response = requests.post(url, headers=headers, data=data)token = response.json().get('params', {}).get('bussiness')return token
4. 语序点选识别
完成了上面两步初始化工作后,就到了重点部分了。每一次搜索都会触发一个语序文字点选的行为验证码,过了这个验证码后才会返回数据,如下所示:

这里第一步需要先获取到图片(行为验证码突防的第一步拿到图片信息用以后续的识别),获取图片接口getCheckImagePoint,有一个请求参数clientUid需要处理,如下所示:

先定位到clientUid参数的生成位置,再进行还原,位置与算法实现如下所示:

def getUUID():A = "0123456789abcdef"g = [A[int(16 * random.random())] for _ in range(36)]g[14] = "4"g[19] = A[int(3 & int(g[19], 16) | 8)]g[8] = g[13] = g[18] = g[23] = "-"C = "point-" + "".join(g)return C
接着解析图片信息,将smallImage跟bigImage字段信息拿出来进行坐标识别,用以后续的验证提交,如下所示:
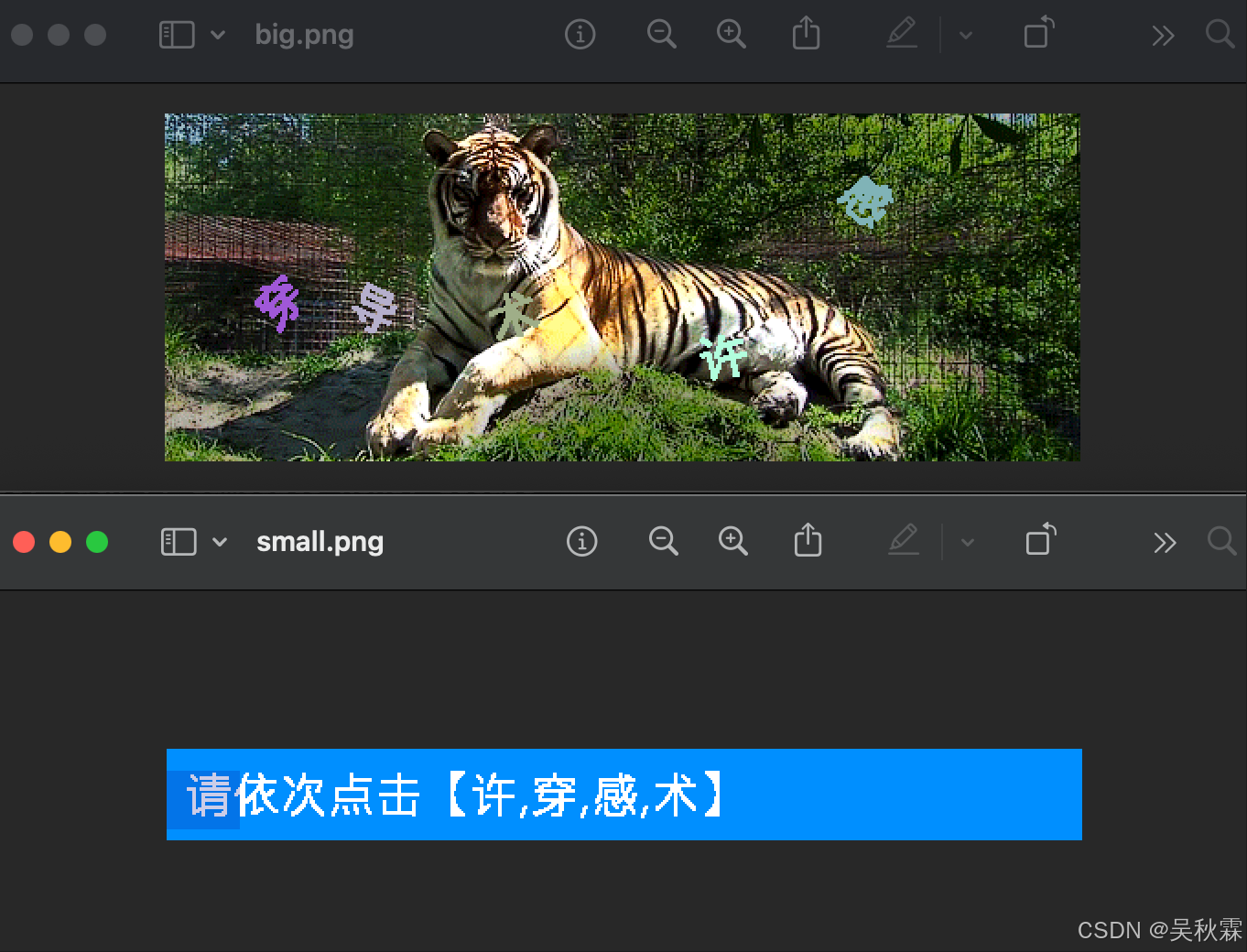
这里识别提取坐标的方案有多种,第一种借助第三方打码平台调用接口返回坐标信息即可,调用第三方的话将上述两个图合并后编码提交即可,代码实现如下:
import base64
from PIL import Imagedef process_merged_image():"""处理并合并图片,调用第三方接口识别验证码"""# 获取图片相关标识与token凭证client_id = getUUID()auth_token = get_auth_token()image_data = get_image_data(auth_token, client_id)# 解码Base64图片数据为二进制big_image_bytes = base64.b64decode(image_info['bigImage'])small_image_bytes = base64.b64decode(image_info['smallImage'])with BytesIO(big_image_bytes) as big_buffer, \BytesIO(small_image_bytes) as small_buffer:with Image.open(big_buffer) as big_img, \Image.open(small_buffer) as small_img:# 计算合并后图片的尺寸merged_width = big_img.widthmerged_height = big_img.height + small_img.height# 创建新图片并合并merged_img = Image.new(big_img.mode, (merged_width, merged_height))merged_img.paste(big_img, (0, 0))merged_img.paste(small_img, (0, big_img.height))# 将合并后的图片保存到内存缓冲区merged_img.save(merged_buffer, format='PNG')merged_buffer.seek(0)merged_base64 = base64.b64encode(merged_buffer.read()).decode('utf-8')# 调用第三方识别接口recognition_result = third_party_captcha_recognize(merged_base64)# 返回坐标数据return recognition_result
第二种则是自己使用Yolo或ddddocr配合siamese来进行目标检测提取坐标并识别最终符合坐标,选Yolo的话可以自己准备一些样本数据并进行标注来训练一个自定义的文字目标检测模型。也可以使用目前开源的ddddocr,这里两种方案都可以(想要成功率更高当然是自己训练更好),如下所示:
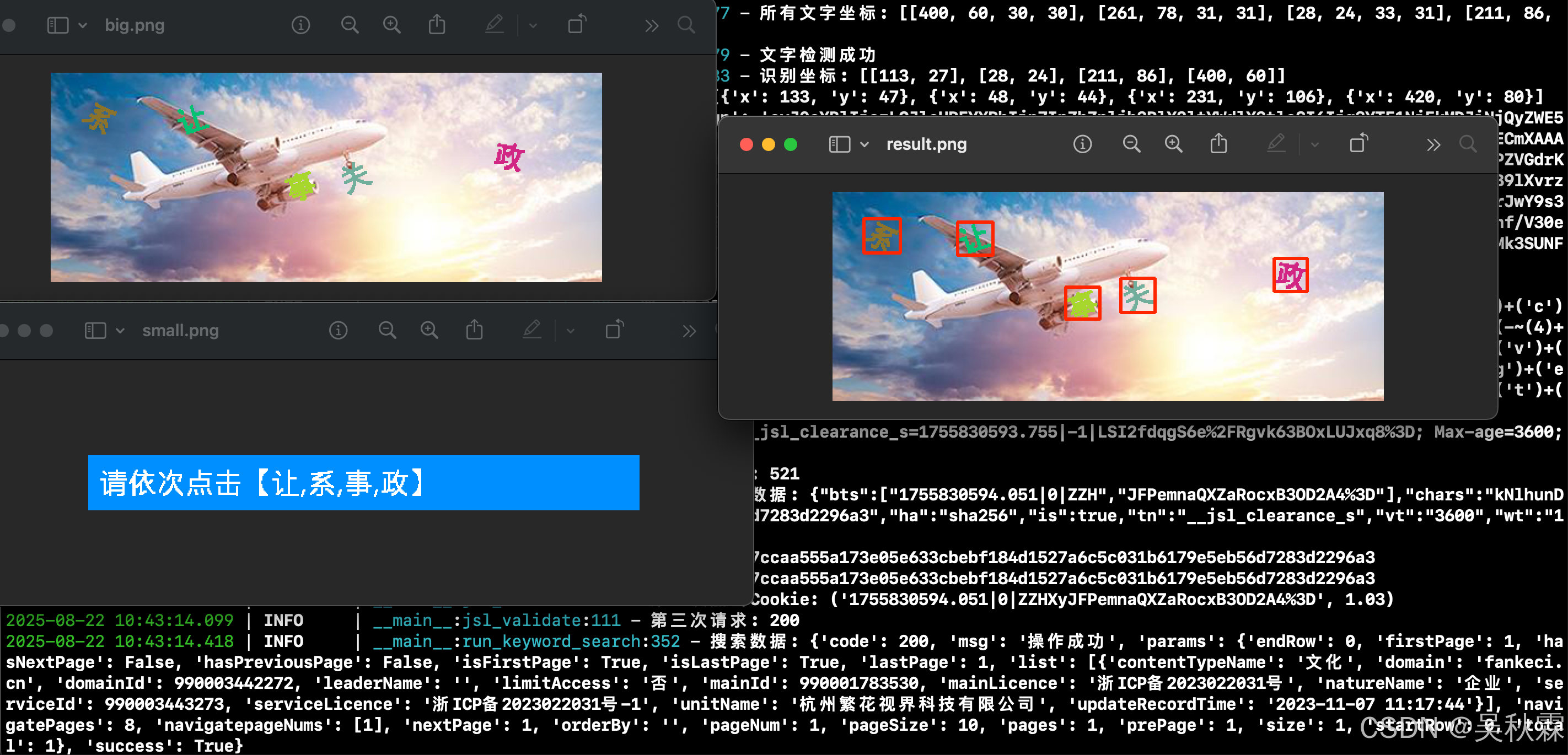
目标识别解决后用Siamese(孪生网络)来按照语序进行文字匹配。最终得到按顺序排列的文字坐标。这里先实现对背景图片的文字目标检测并提取其坐标,代码实现如下:
def detect_text_boxes(self, base64_image: str) -> List[List[int]]:"""检测图像中的文字区域Args:base64_image: base64编码的图像字符串Returns:包含文字边界框的列表,每个边界框格式为[left, top, width, height]"""self.big_image = self.read_base64_image(base64_image)_, img_encoded = cv2.imencode('.png', self.big_image)image_bytes = img_encoded.tobytes()# 使用ddddocr进行文字检测detected_positions = self.detector.detection(image_bytes)# 转换检测结果为标准边界框格式bounding_boxes = self._convert_to_bounding_boxes(detected_positions)# 调试用:可选的可视化功能# self._visualize_detection(detected_positions, "detection_result.png")return bounding_boxesdef _convert_to_bounding_boxes(self, positions: List[Tuple[int, int, int, int]]) -> List[List[int]]:"""将检测到的位置转换为标准边界框格式Args:positions: 检测到的位置列表,每个元素为(x1, y1, x2, y2)Returns:转换后的边界框列表,每个元素为[left, top, width, height]"""boxes = []for (x1, y1, x2, y2) in positions:left = x1top = y1width = x2 - x1height = y2 - y1boxes.append([left, top, width, height])return boxesdef _visualize_detection(self, positions: List[Tuple[int, int, int, int]], output_path: str) -> None:"""可视化检测结果(用于调试)Args:positions: 检测到的位置列表output_path: 输出图像路径"""if self.big_image is None:return# 创建图像副本用于绘制visualization_img = self.big_image.copy()# 绘制所有检测框for box in positions:x1, y1, x2, y2 = boxcv2.rectangle(visualization_img, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=2)# 保存结果图像cv2.imwrite(output_path, visualization_img)
先对图片进行预处理然后使用ddddocr或者自己训练的yolo onnx文件识别文字区域,提取每一个文字的矩形框坐标(x、y),拿到所有文字的坐标后进入到匹配阶段,这里我们需要加载siamese.onnx孪生网络模型,用于计算图片相似度,对小图中的每个目标文字区域进行预处理(RGB、归一化、唯维度调整)遍历背景图中的文字与小图目标文字输入孪生网络计算相似度,根据相似度的分数(值越接近1表示越相似)决定是否匹配成功,算法实现如下:
import cv2
import onnxruntime
import numpy as np
from typing import List, Tuple# 预定义的模板位置 (x坐标)
TEMPLATE_X_POSITIONS = [165, 200, 231, 265]
# 相似度阈值
SIMILARITY_THRESHOLD = 0.7
# 模板提取参数
TEMPLATE_Y_START = 11
TEMPLATE_HEIGHT = 28
TEMPLATE_WIDTH = 26
# 图像处理尺寸
PROCESSED_SIZE = (105, 105)def match_with_siamese_network(template_image_base64: str, candidate_boxes: List[List[int]], big_image: np.ndarray) -> List[Tuple[int, int]]:"""使用孪生网络匹配模板图像与候选区域Args:template_image_base64: 模板图像的base64编码字符串candidate_boxes: 候选边界框列表,格式为[left, top, width, height]big_image: 大图像数据Returns:匹配成功的候选框左上角坐标列表"""# 初始化ONNX推理会话session = onnxruntime.InferenceSession("siamese.onnx")matched_positions = []# 处理每个模板位置for template_x in TEMPLATE_X_POSITIONS:if len(matched_positions) >= 4: # 最多匹配4个位置break# 提取模板图像区域template_region = extract_template_region(template_image_base64, template_x)# 预处理模板图像processed_template = preprocess_image(template_region)# 与每个候选框进行匹配for box in candidate_boxes:# 提取候选区域candidate_region = extract_candidate_region(box, big_image)# 预处理候选图像processed_candidate = preprocess_image(candidate_region)# 使用孪生网络进行相似度计算similarity_score = calculate_similarity(session, processed_candidate, processed_template)# 如果相似度超过阈值,记录匹配结果if similarity_score >= SIMILARITY_THRESHOLD:matched_positions.append((box[0], box[1]))break # 匹配成功后跳出当前候选框循环return matched_positionsdef extract_template_region(template_image_base64: str, x_position: int) -> np.ndarray:"""从模板图像中提取指定位置的区域Args:template_image_base64: 模板图像的base64编码字符串x_position: 要提取的区域的x坐标Returns:提取的图像区域"""template_image = read_base64_image(template_image_base64) # 假设此函数已实现# 提取固定位置和大小的区域return template_image[TEMPLATE_Y_START:TEMPLATE_Y_START + TEMPLATE_HEIGHT, x_position:x_position + TEMPLATE_WIDTH]def extract_candidate_region(box: List[int], big_image: np.ndarray) -> np.ndarray:"""从大图像中提取候选区域Args:box: 边界框信息 [left, top, width, height]big_image: 大图像数据Returns:提取的图像区域"""left, top, width, height = box# 在原边界框基础上增加2像素的边界return big_image[top:top + height + 2, left:left + width + 2]def preprocess_image(image: np.ndarray) -> np.ndarray:"""预处理图像以供孪生网络使用Args:image: 输入图像Returns:预处理后的图像数据"""# 转换为RGB格式rgb_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)# 调整大小resized_image = cv2.resize(rgb_image, PROCESSED_SIZE)# 归一化并调整维度顺序normalized_image = np.array(resized_image) / 255.0transposed_image = np.transpose(normalized_image, (2, 0, 1))# 添加批次维度并转换为float32return np.expand_dims(transposed_image, axis=0).astype(np.float32)def calculate_similarity(session: onnxruntime.InferenceSession, image1: np.ndarray, image2: np.ndarray) -> float:"""使用孪生网络计算两幅图像的相似度Args:session: ONNX推理会话image1: 第一幅图像数据image2: 第二幅图像数据Returns:相似度得分 (0-1之间)"""# 准备输入数据inputs = {'input': image1, "input.53": image2}# 运行模型推理output = session.run(None, inputs)# 应用sigmoid函数获取相似度得分similarity_score = 1 / (1 + np.exp(-output[0]))return similarity_score[0][0]def read_base64_image(base64_str: str) -> np.ndarray:"""从base64字符串读取图像注意:这里需要实现具体的base64解码逻辑"""# 实现base64解码和图像读取# 这里只是一个占位符,实际实现需要根据具体需求编写pass
5. 语序点选逆向
在通过接口发包调试信息中可以发现按顺序点击对应的文字后,会提交坐标信息并进行加密处理再提交,如下所示:


提交验证接口checkImage请求参数pointJson需要处理一下,这个参数是点选坐标信息的加密值(上面的AES处理位置处生成),提交验证请求通过后会返回一个sign用于最后一步提交查询接口使用才能获取到数据,如下所示:

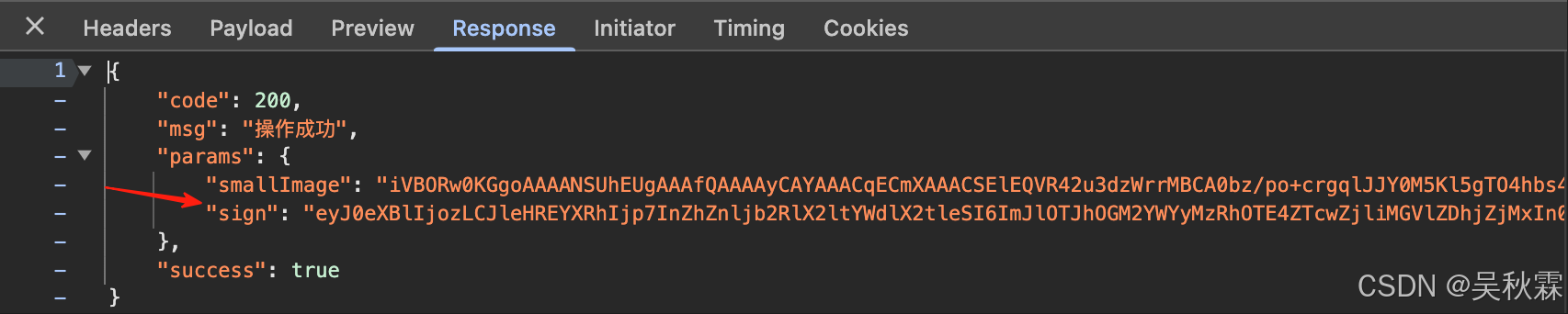
坐标数据AES加密实现算法如下所示(可以使用它那个固定的密钥也可以使用调试出来的):
from Crypto.Cipher import AES
from Crypto.Util.Padding import paddef _aes_ecb_encrypt(g: str, a: str = "") -> str:key = a.encode('utf-8')key = key[:16]plaintext = g.encode('utf-8')padded_plaintext = pad(plaintext, AES.block_size, style='pkcs7')cipher = AES.new(key, AES.MODE_ECB)ciphertext = cipher.encrypt(padded_plaintext)return b64encode(ciphertext).decode('utf-8')# 坐标值加密
def encrypt_coords(coordinate: list, s_key: str) -> str:coord_str = json.dumps(coordinate, ensure_ascii=False, separators=(',', ':'))return _aes_ecb_encrypt(coord_str, s_key)
最后一步查询接口queryByCondition请求头会用到上面验证接口通过后返回的sign,携带请求即可(Token用第一次的连贯携带即可)。如下所示:

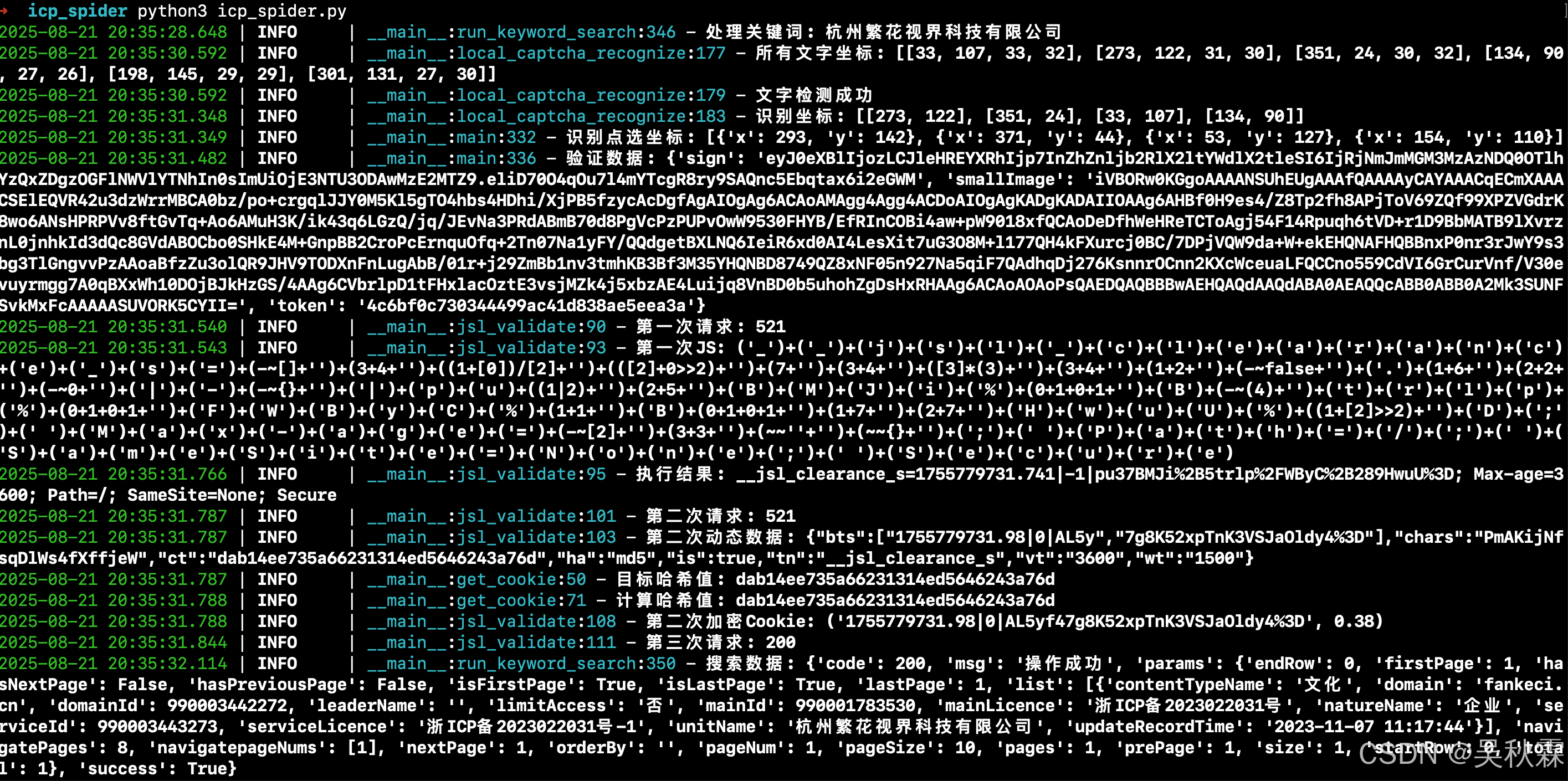
本文语序验证码识别部分目前的ddddocr搭配siamese方案成功率在70~90%,感兴趣的小伙伴可以自己抓一些样本进行训练,成功率将会更高