【Linux进程控制详解】
一、创建进程
使用pid_t fork() 创建一个子进程
进程调用fork,当控制转移到内核fork代码后,内核会做:
- 分配新的内存块和内核数据给子进程
- 将父进程的部分数据结构拷贝给子进程
- 添加子进程到系统列表当中
- fork返回,开始调度器调度
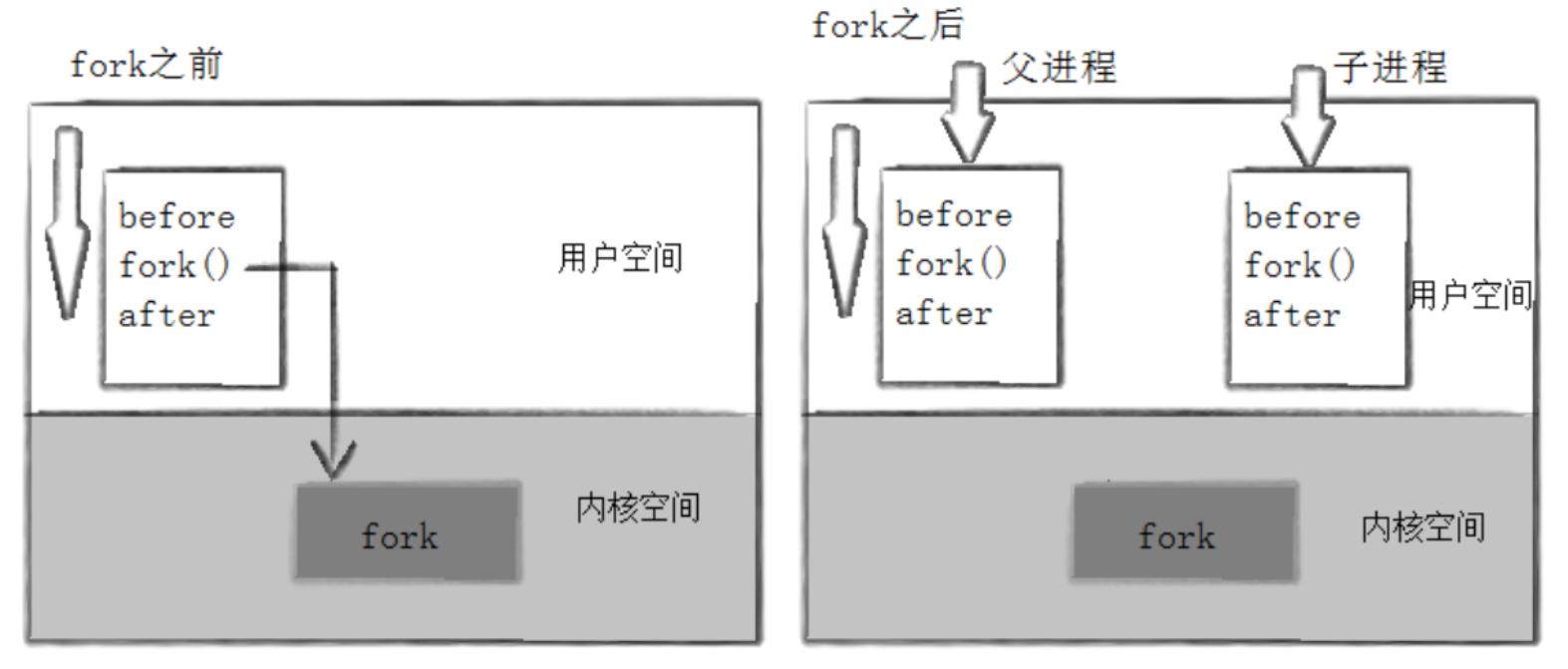
当一个进程调用fork后,就会有两个二进代码相同的进程,它们都运行在同一个地方,但是它们开启不一样的旅程。
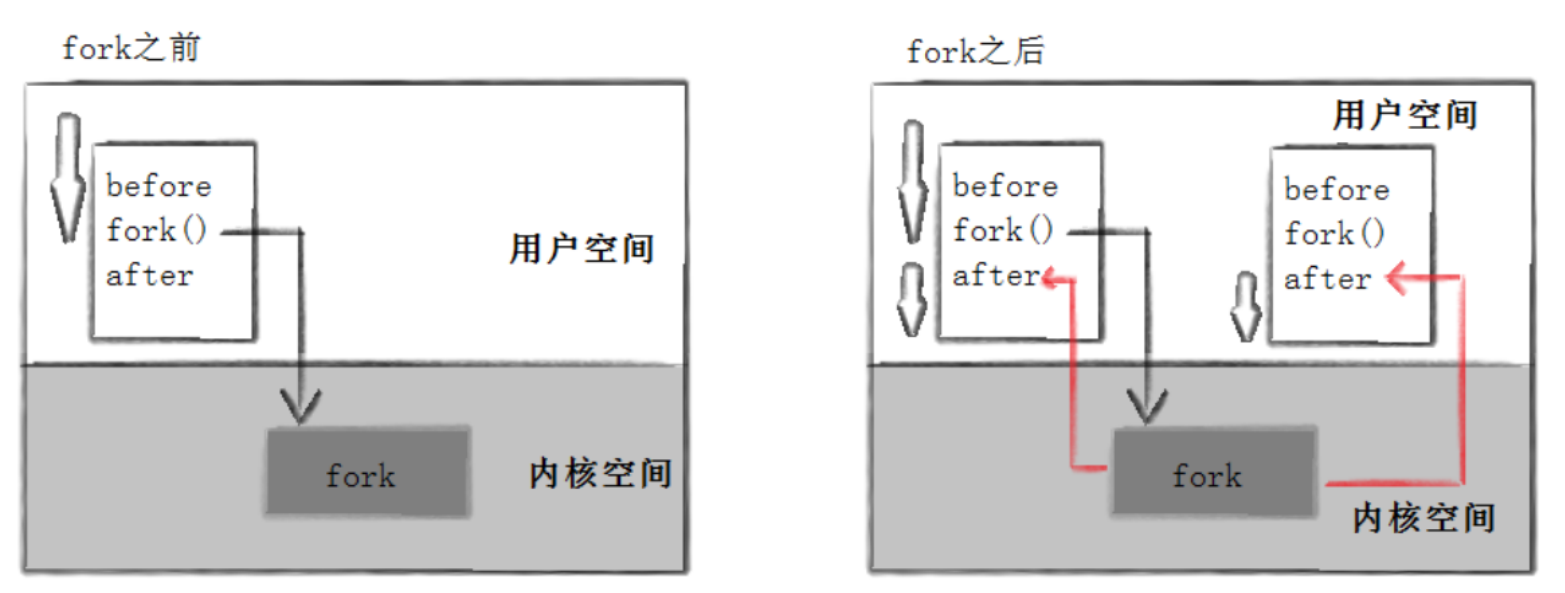
所以我们知道fork之前父进程独立执行,fork之后父子进程分流执行。
我们都知道数据段在页表当中的权限是可读的,但是一旦创建了子进程,操作系统会把权限改为只读的。当子进程尝试写入的时候,操作系统就会报错。
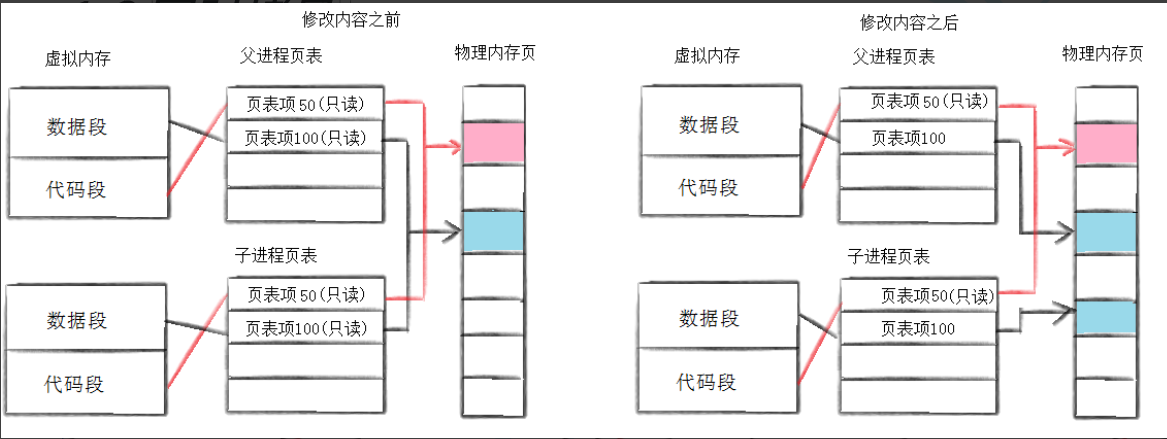
操作系统会对当前情况进行判断分类:
判断是不是野指针,如果是就终止进程,不是就会发生写时拷贝,更改回权限
为什么创建子进程后,不直接把数据分开呢?还要写时拷贝?
直接拷贝将父子进程的数据分开是可以的,但是假设子进程对数据是只读的呢?这种情况就没必要进行拷贝了,父进程的代码和数据很小,每次创建子进程都要进行拷贝,这样以来就会产生时间浪费,以及内存的浪费。子进程读取父进程的数据,直接用父进程的就可以了,子进程要进行写入的时候,再给子进程申请。写时拷贝的本质就是一种惰性申请,这样可以提高内存使用率。
为什么要拷贝,能不能直接开辟对应的空间就好了?
不需要,开辟虚拟地址空间就可以了,真正需要用到的时候,操作系统才会做内存级的申请,构建完整的映射关系,本质上是一种惰性的申请。
二、进程终止
进程终止本质上就是释放系统资源,释放进程申请的相关内核数据结构和对应的数据代码
进程退出的场景:
- 代码运行完毕结果正确
- 代码运行完毕结果错误
- 代码异常终止
问题:进程终止的时候操作系统要做什么?
进程终止时,操作系统要释放进程资源,停止CPU对进程的调度,更新进程状态
问题:我们在写代码的时候总是要写return 0(或是return别的数)那这个return返回这个是什么意思呢?给了谁?
return 0我们叫进程退出的退出码,它会被系统获得,让系统辨别该进程的执行情况
为什么要有退出码呢?
我们创建进程来完成任务的时候,进程完成得怎么样我们是要知道结果的吧,那我们要怎么样才能得到结果呢?
进程返回0表示程序运行成功
!0表示失败,例如1、2、3等等
char* strerror(int errnum) //将错误码转化为可读错误信息字符串
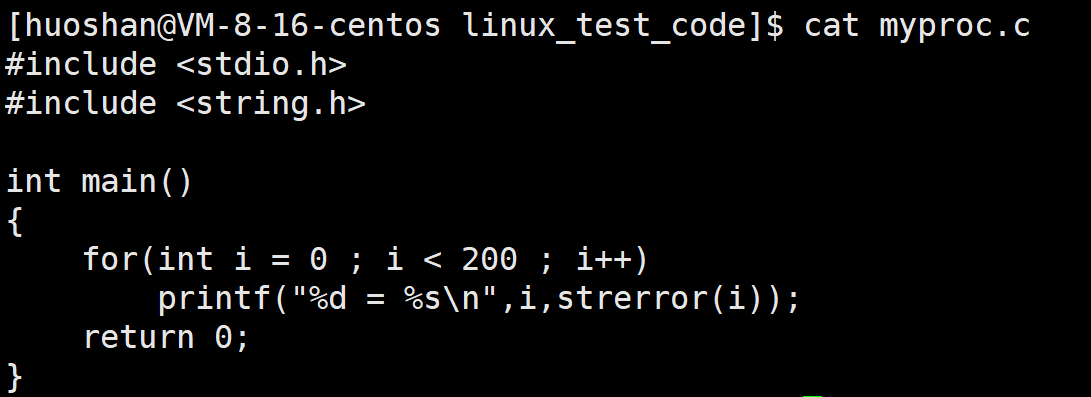
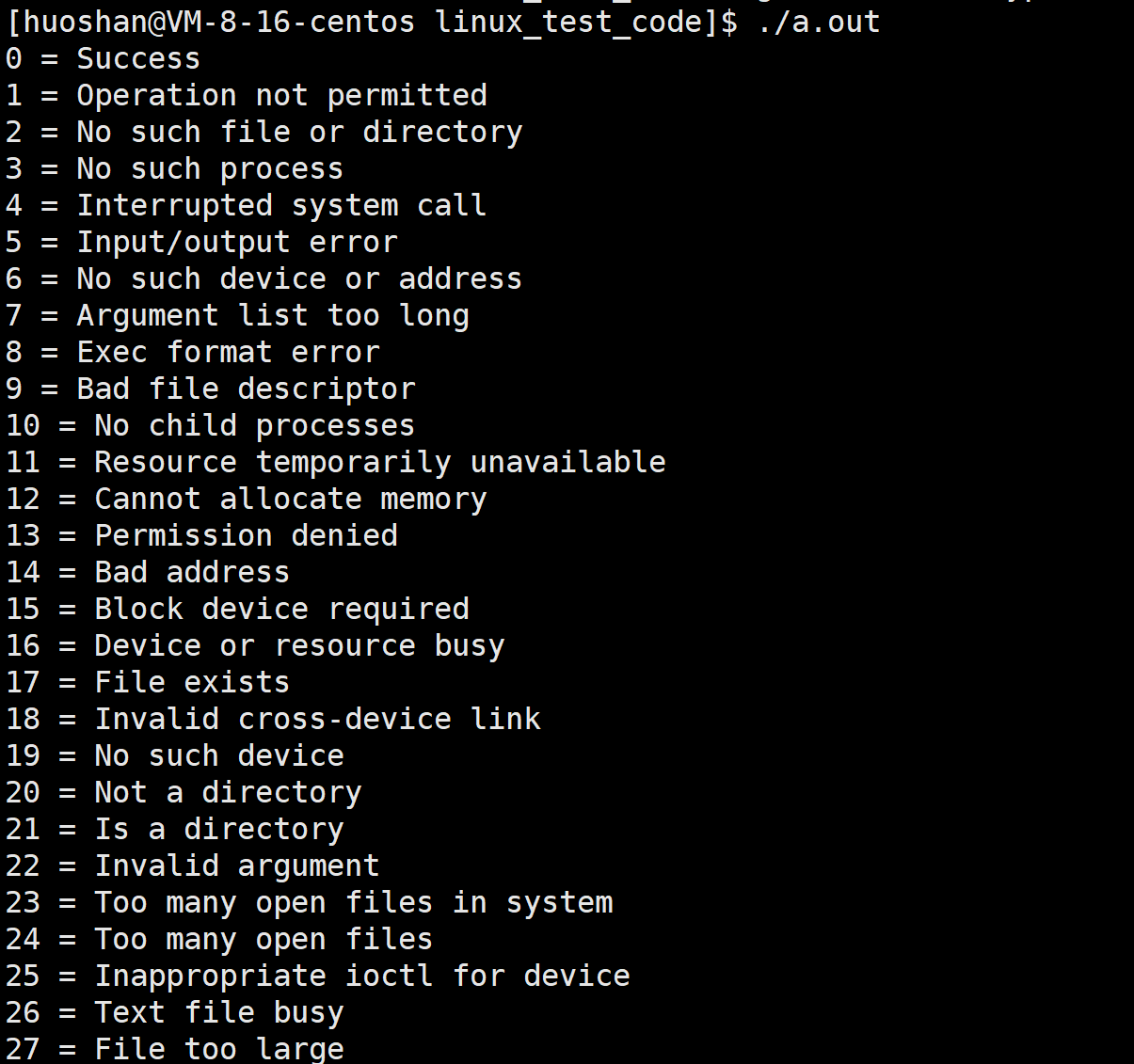
由上面程序运行的结果我们可以看到,一共有134个错误,其他都是未知的。
将来这个退出码会被写到PCB中,父进程通过子进程的pid就可以找到子进程,获取子进程的信息,这也就是为什么子进程在退出时,状态会被设置为僵尸状态,不能立即释放所有资源,要保留PCB的原因了。
进程退出的方法
方法一:main()函数进行return n,n 表示该进程的退出码
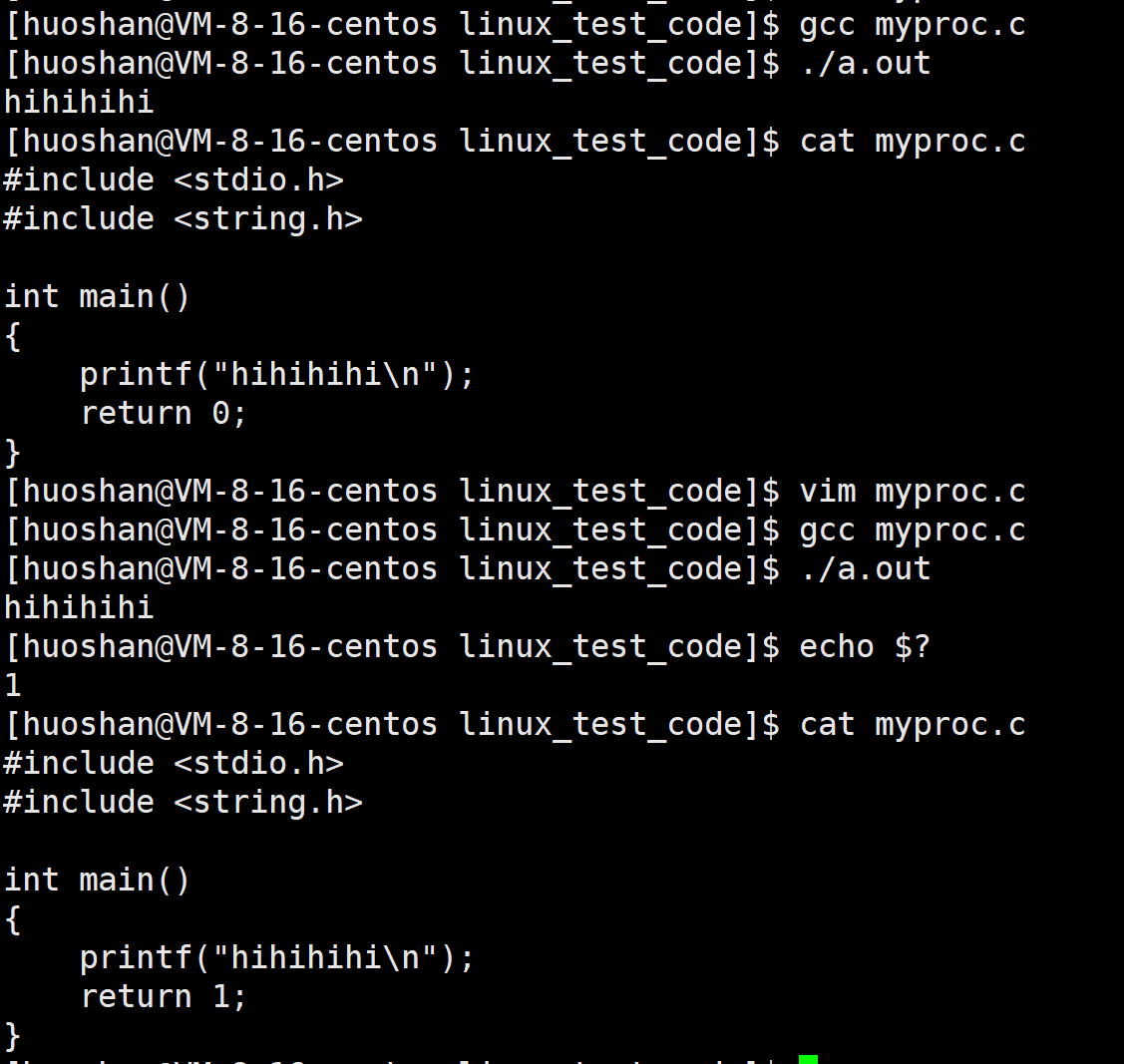
方法二:调用exit(n),n表示进程的退出码
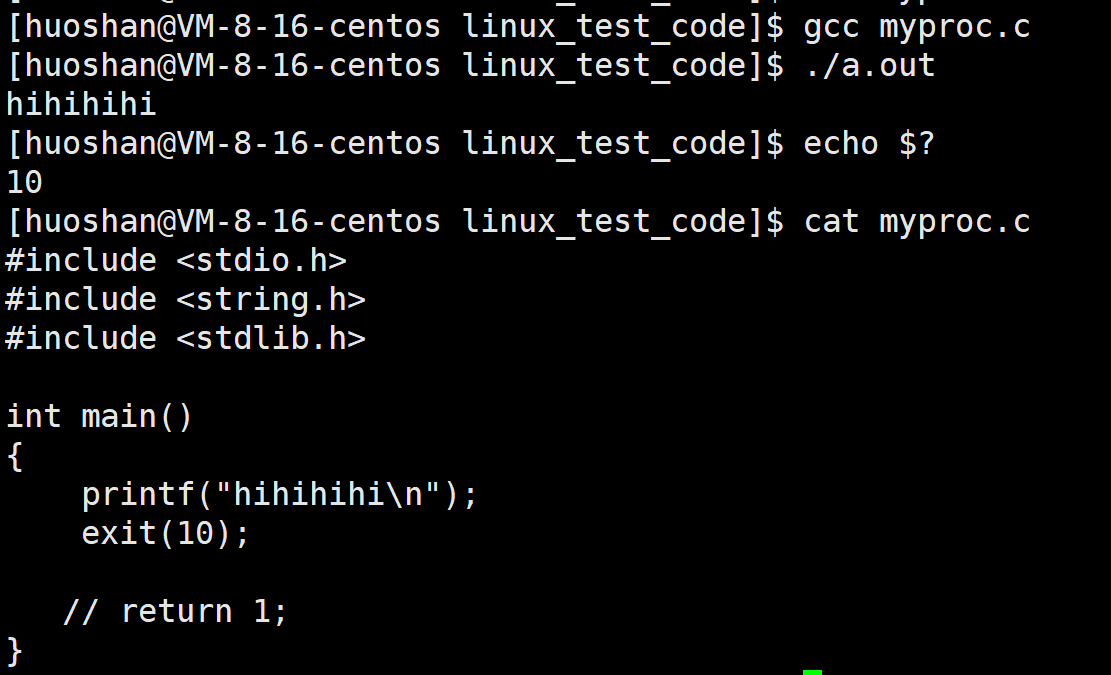
方法三:直接调用系统调用_exit(n)
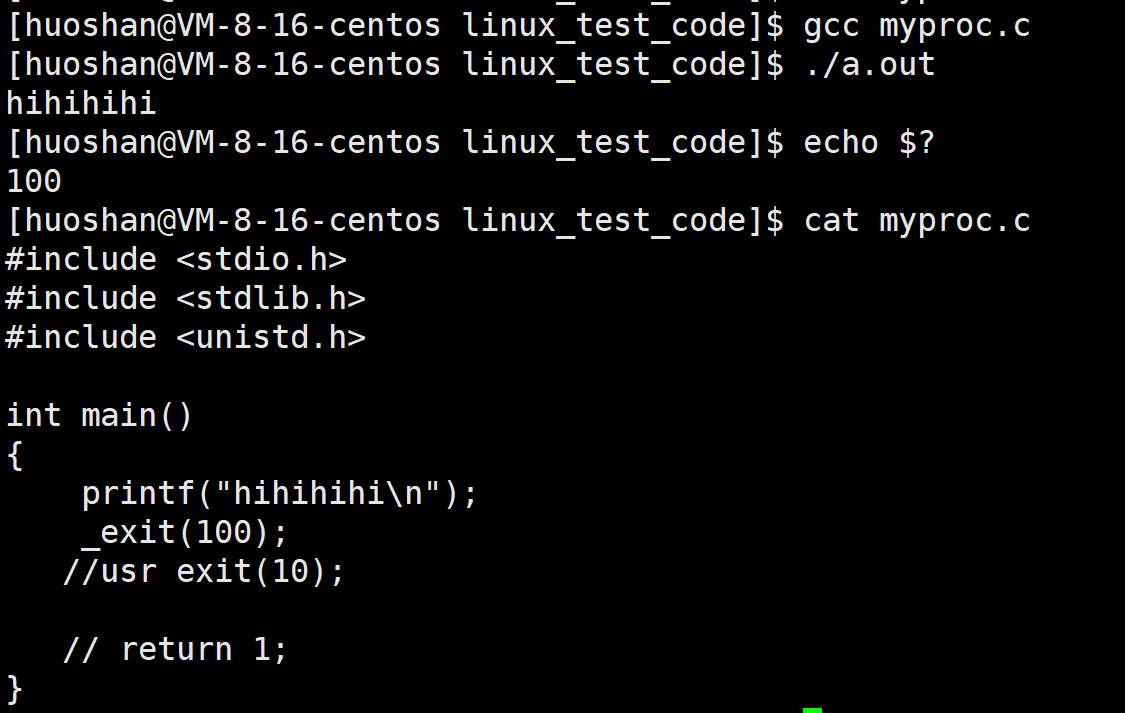
return和exit的对比
我们都知道return一般是函数调用结束的时候,表示进程退出
exit()则表示进程结束,在代码中任何地方调用都会导致进程退出
具体看以下代码:
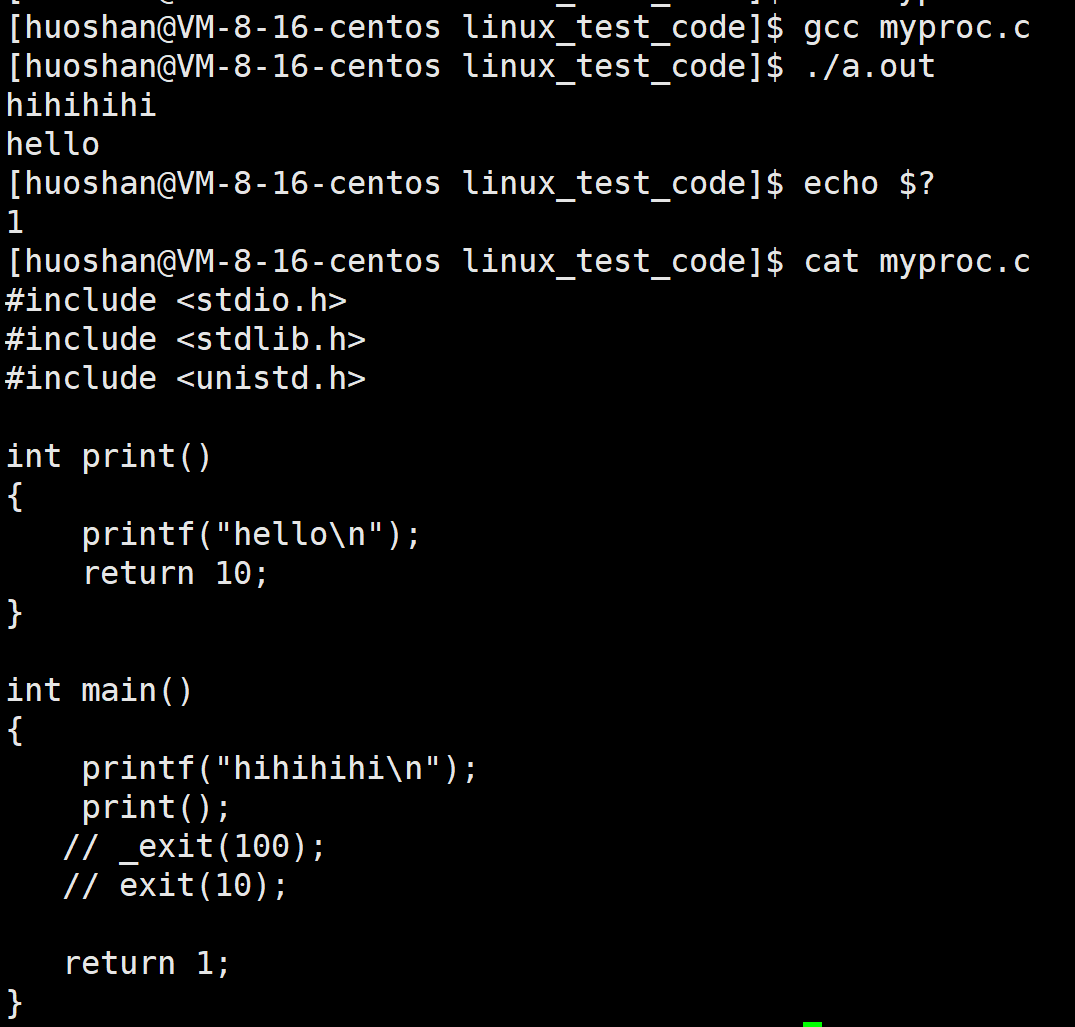
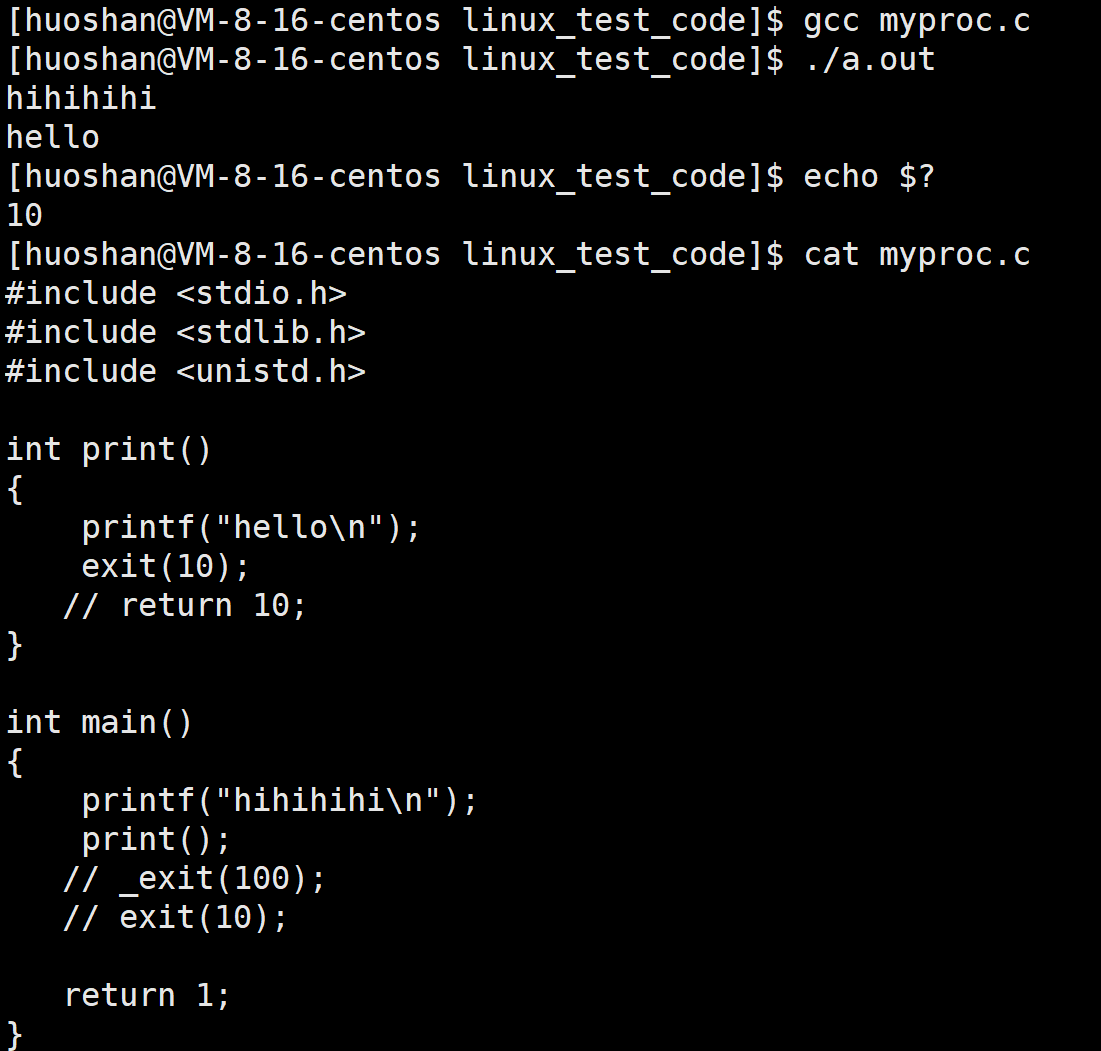
exit和_exit对比
看下面的代码
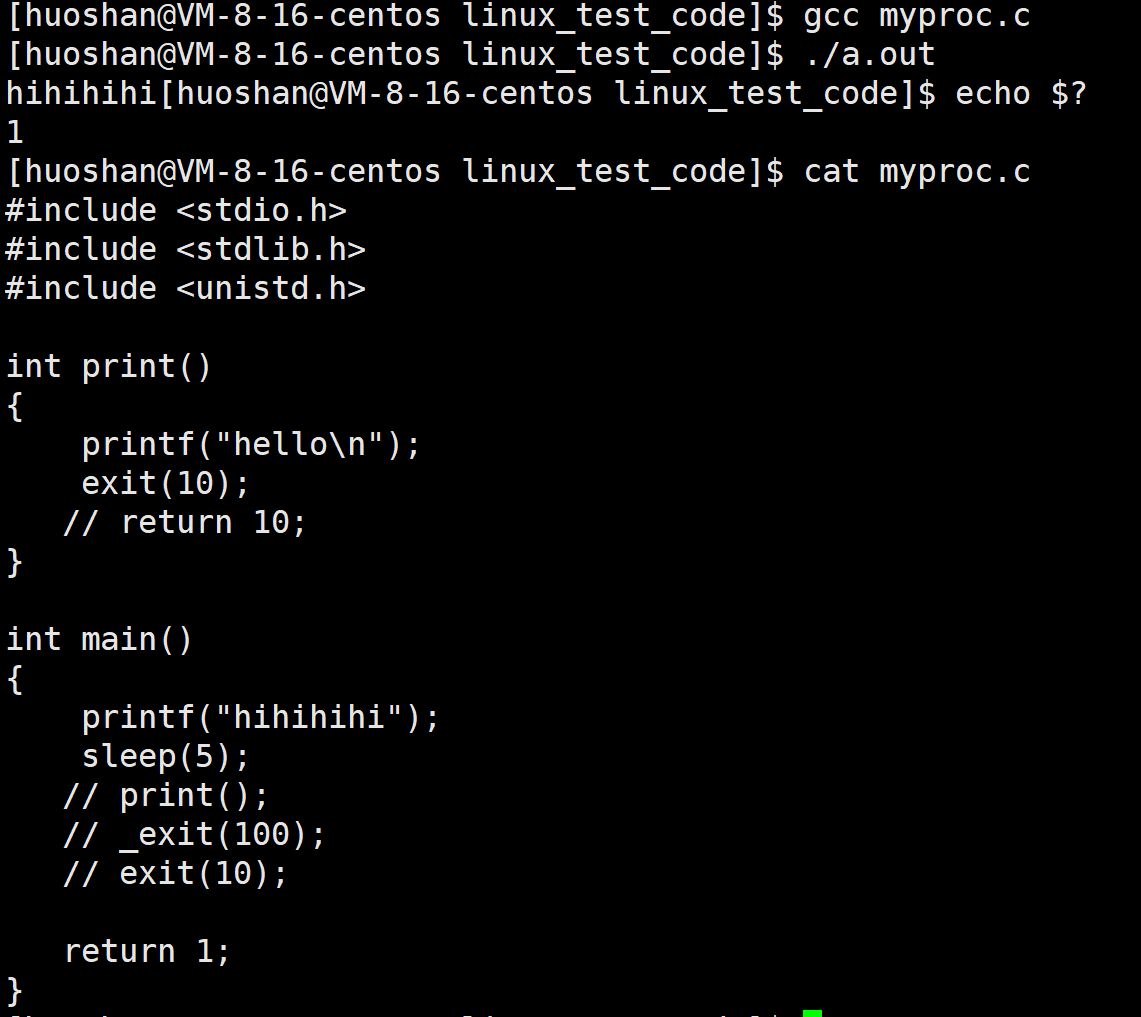
运行我们会发现,它前五秒光标一直没有打印出内容,其实它是被写入到缓冲区内,main函数中return表明进程结束,输出缓冲区,在进程结束的时候会自动刷新。同理exit终止进程也会主动刷新缓冲区。而_exit却跟以上两种不同,看以下代码:
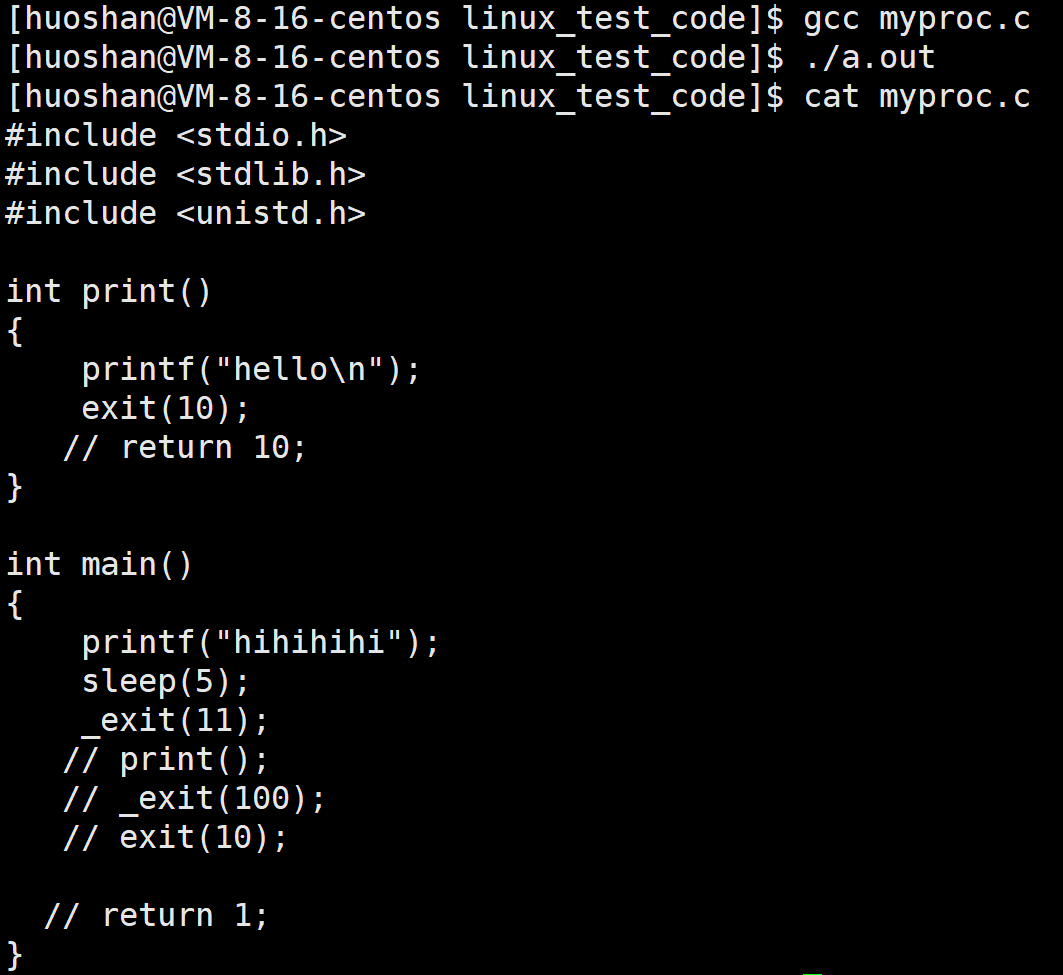
_exit会直接终止进程,不会刷新缓冲区
我们都知道库和系统是上下层的关系,系统调用的存在就是为了保证用户安全的访问操作系统,也就是说只有系统调用才可以和操作系统交互。
进程退出的时候需要释放资源,这些工作都是由操作系统完成的,我们调用C语言的库函数exit为什么可以让进程退出呢?答案是进程终止绝对要调用系统调用,必须让操作系统完成真正的进程删除退出,所以库函数的底层一定封装了系统调用。