Python万里长征6(非教程)pandas筛选数据三基础、三核心、三高级
文章目录
- 一、背景
- 二、布尔索引
- 2.1 总结
- 三、进阶核心用法(实用高效)
- 3.1 多条件组合
- 3.2 字符串表达式(类似SQL)
- 3.3 针对字符串的正则匹配
- 四、高级方法(依赖基础)
- 4.1 函数应用(如apply()或lambda)
- 4.2 缺失值筛选
- 4.3 loc与iloc
- 五、总结
一、背景
2025年8月22日了,回头查了下第一个python万里长征的文章还是2018年11月。但是没有写几篇,坚持写这个还是挺难的,回头一想,八年多还在这个岗位上,还是有半杯欣慰的,来干了!cheers!
最近一年,数据分析做的内容比较多,但是回头看,对pandas这个东西的使用,还是有一层迷雾感的。所以写点东西,记录下心路旅程,也许未来某一天看看自己的笔记,会微笑多那么一点点,足够了。等待未来callback的一天。
二、布尔索引
今天让ai出了个几个选择题,做了几个题消耗些时间,看了个解释,发现一句话,布尔索引是标准的筛选方式。
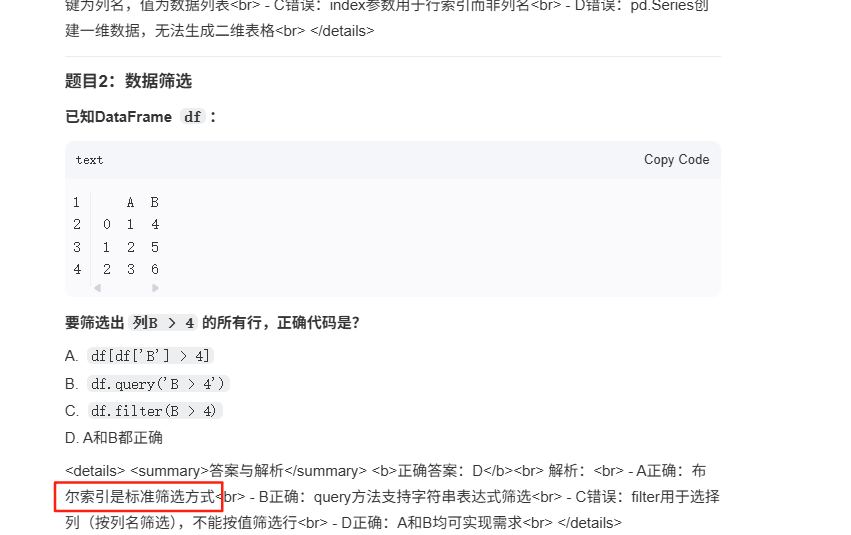
深入研究了下,布尔索引过滤是pandas中通过逻辑条件筛选数据的一种方法,他属于三大基础方法之一,另两个基础是isin和between。
一个是二值化筛选,一个是多值筛选,一个是范围筛选。
2.1 总结
新手记住三基础就可以了。后面看进阶
三、进阶核心用法(实用高效)
想打个高效,总是打出来搞笑!!!(i fu le you 输入法)
也是分三类记下吧,都是为了更好的回忆。
3.1 多条件组合
通过&、|、~组合条件,需注意括号使用,例如:df[(df[‘A’] > 10) & (df[‘B’] == ‘X’)]
3.2 字符串表达式(类似SQL)
query()方法,支持字符串表达式
例如:df.query(“A > 10 and B == ‘X’”)。适合复杂条件场景,这个严格来说也是多条件组合,只不过是sql化的用法。
3.3 针对字符串的正则匹配
str.contains()
针对字符串列的正则匹配,例如:df[df[‘CVE ID’].str.contains(‘CVE-’)]
四、高级方法(依赖基础)
4.1 函数应用(如apply()或lambda)
自定义复杂逻辑,例如:df[df.apply(lambda x: x[‘A’] + x[‘B’] > 100, axis=1)]
遇事不决可问春风 春风不语即随本心!!!
4.2 缺失值筛选
使用isna()或notna(),例如:df[df[‘列名’].notna()]
4.3 loc与iloc
loc:基于标签和布尔索引筛选行或列,例如:df.loc[df[‘A’] > 10, [‘B’, ‘C’]]
输入格式:loc[] 的通用语法是 df.loc[行选择, 列选择]。若省略列部分(如本例),则返回所有列。
iloc:基于整数位置筛选(较少用于逻辑条件),输入格式类似loc
这里loc和iloc容易混淆,所以还是看下区别:
| 特性 | loc | iloc |
|---|---|---|
| 索引类型 | 标签(显式) | 整数位置(隐式) |
| 切片包含性 | 包含结束标签!!! | 不包含结束位置!!!(Python 风格) |
| 示例 | df.loc[‘a’:‘c’] | df.iloc[0:2] |
如需按位置选择数据,应使用 iloc。
五、总结
pandas的筛选数据肯定是不止这些方法,但是要更好的记忆,必须是有量化层次做基础的,三基础、三核心、三高级并不是绝对的,看适合个人的记忆,别让大脑处于混乱朦胧的状态即可,真正的进阶需要用。