selenium爬虫
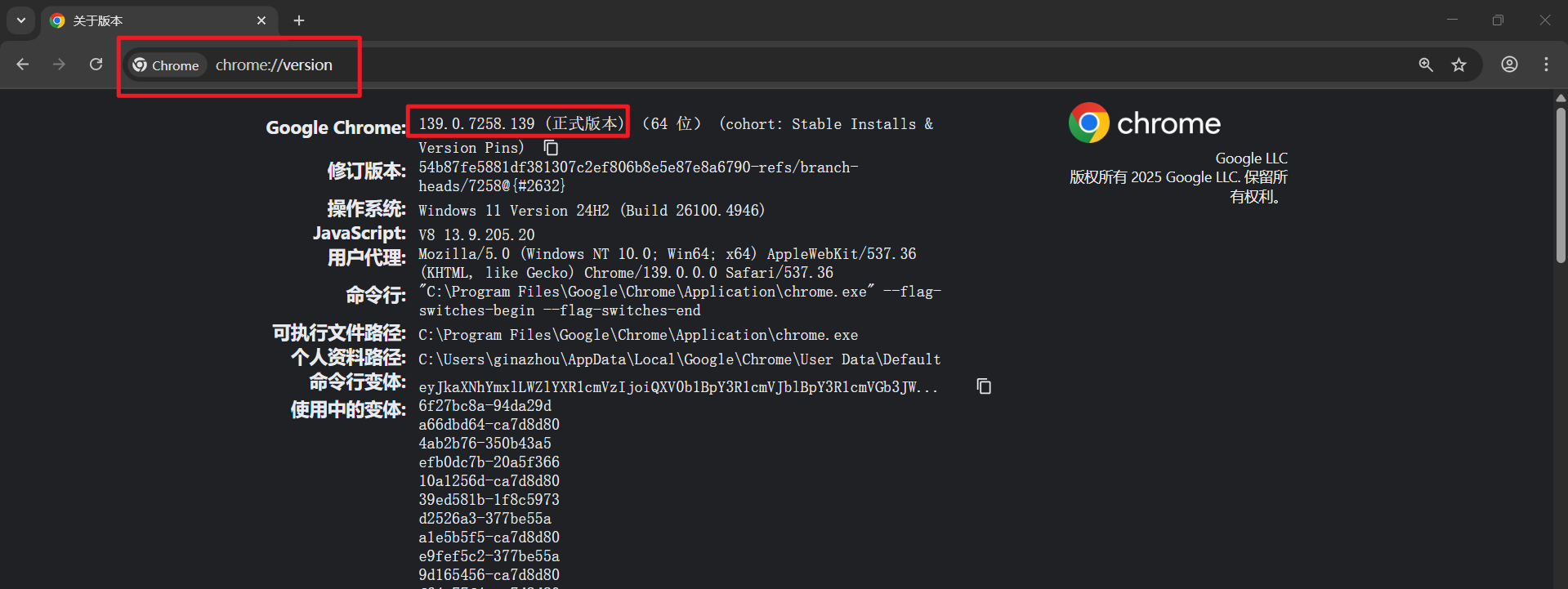
查看自己的Google Chrome版本:
| 139.0.7258.139 (正式版本) (64 位) |
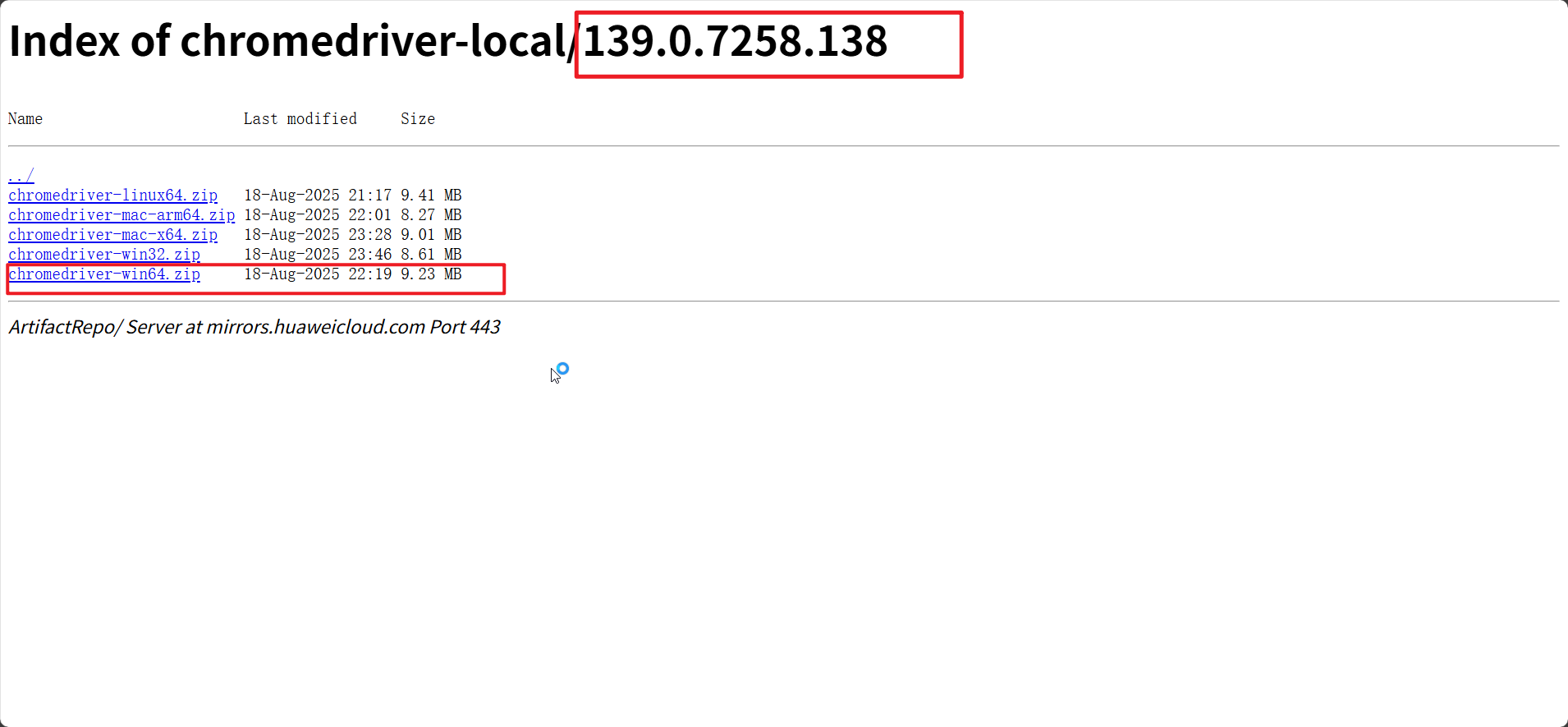
驱动下载地址:
Index of chromedriver-local/139.0.7258.138
解压
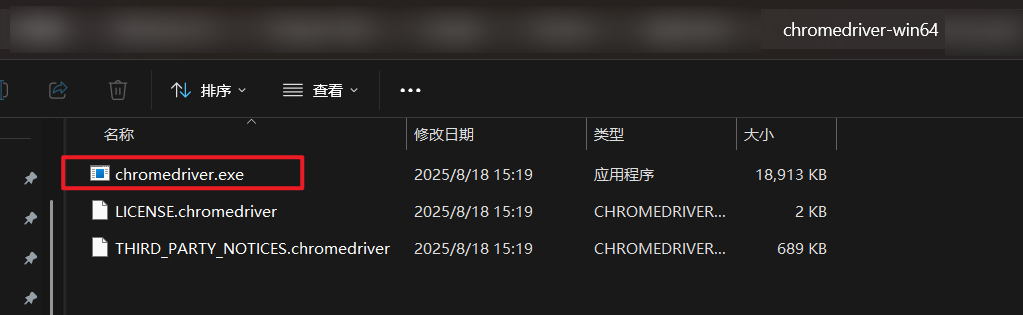
首先复制到:C:\Program Files\Google\Chrome\Application
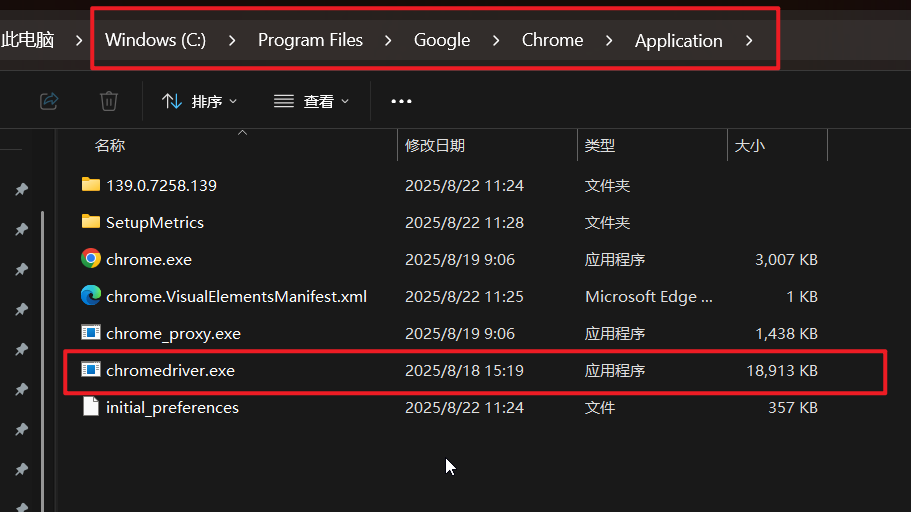
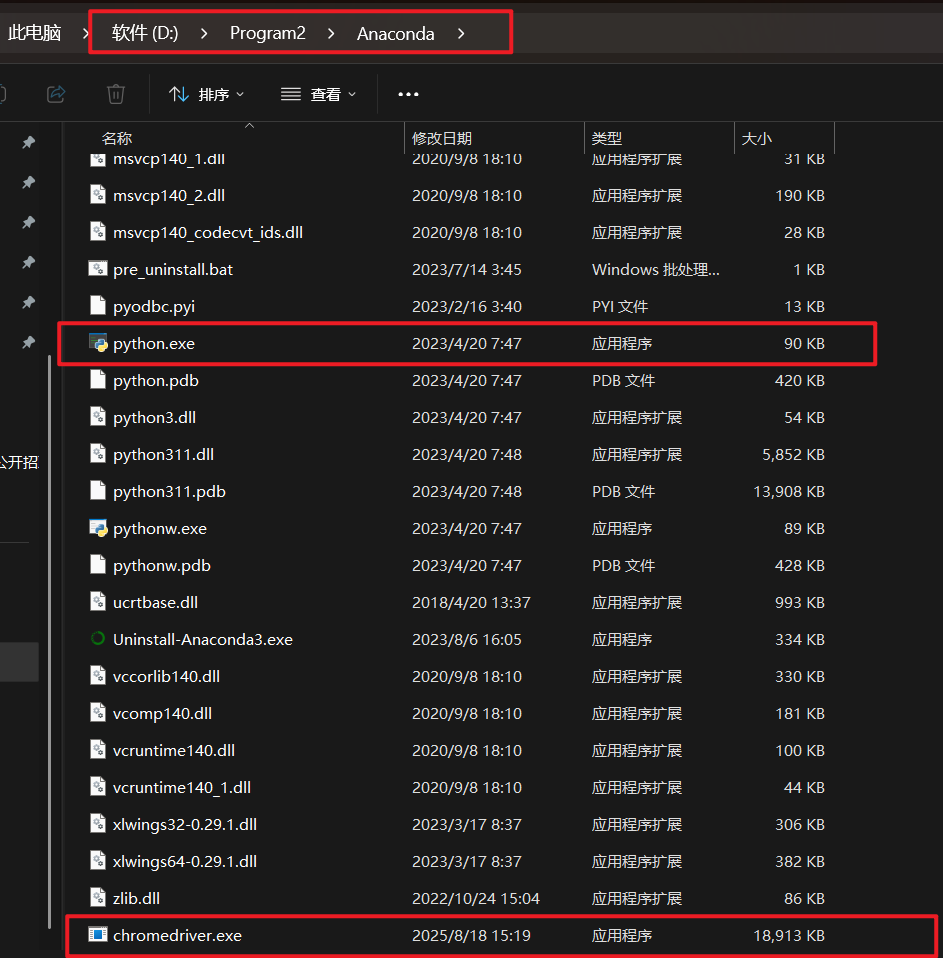
再复制到:D:\Program2\Anaconda
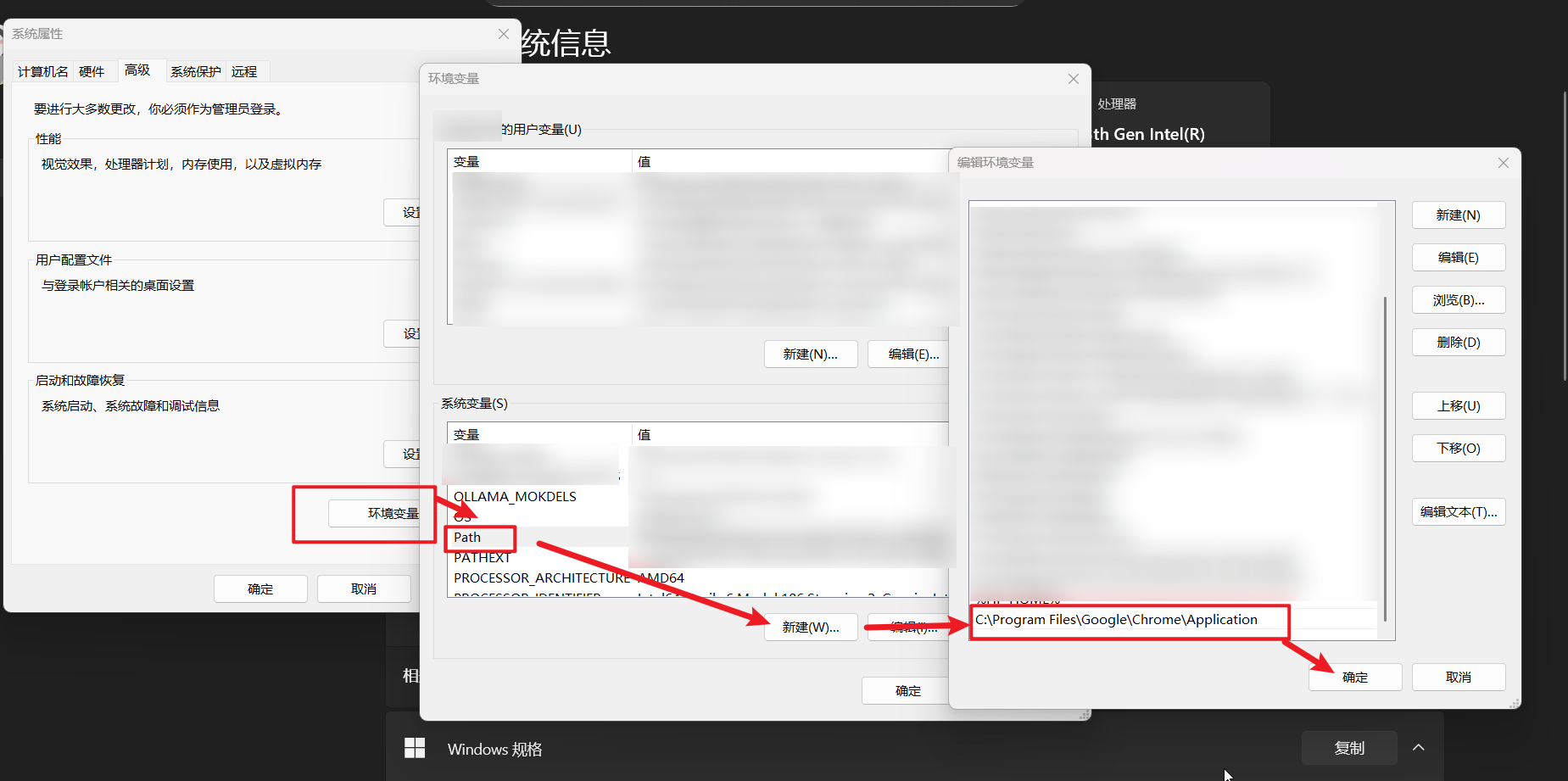
配置环境变量
测试
from selenium import webdriver #自动化控制浏览器模块
from selenium.webdriver.chrome.service import Service# 1. 先创建 Service 对象,指定 chromedriver 路径
service = Service(r"C:\Program Files\Google\Chrome\Application\chromedriver.exe") # 2. 再用 Service 对象去初始化 Chrome
driver = webdriver.Chrome(service=service) # 后续操作...
driver.get("https://baidu.com/")from selenium import webdriver
这行代码导入了 Selenium 库中的 webdriver 模块。webdriver 是 Selenium 的核心模块,用于控制不同类型的浏览器(如 Chrome、Firefox、Edge 等)。
用途:通过 webdriver,你可以创建一个浏览器实例,并通过编程方式控制浏览器的行为,如打开网页、填写表单、点击按钮等。
支持的浏览器类型:
__all__ = ["ActionChains","Chrome",#√"ChromeOptions","ChromeService","ChromiumEdge","DesiredCapabilities","Edge", #√"EdgeOptions","EdgeService","Firefox", #√"FirefoxOptions","FirefoxProfile","FirefoxService","Ie","IeOptions","IeService","Keys","Proxy","Remote","Safari","SafariOptions","SafariService","WPEWebKit","WPEWebKitOptions","WPEWebKitService","WebKitGTK","WebKitGTKOptions","WebKitGTKService",
]
from selenium.webdriver.chrome.service import Service
这行代码导入了 Service 类,该类用于配置 Chrome 浏览器的启动服务。
用途:Service 类可以帮助你更灵活地配置 Chrome 浏览器的启动参数,例如指定 ChromeDriver 的路径、设置环境变量等。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time# ---------------------------
# 1. 配置 chromedriver 路径并初始化浏览器
# ---------------------------
# 替换为你本地 chromedriver 的实际路径
chromedriver_path = r"C:\Program Files\Google\Chrome\Application\chromedriver.exe"
service = Service(chromedriver_path)# 初始化 Chrome 浏览器(可以加一些启动参数,比如无头模式、禁用图片等,按需添加)
options = webdriver.ChromeOptions()
# options.add_argument('--headless') # 无头模式,不弹出浏览器窗口(调试用的话可以先注释掉)
# options.add_argument('--disable-gpu') # 禁用 GPU 加速(某些环境下需要)
# options.add_argument('--no-sandbox') # 可选,解决一些权限问题
driver = webdriver.Chrome(service=service, options=options)# ---------------------------
# 2. 访问豆瓣电影 Top250 首页
# ---------------------------
url = "https://movie.douban.com/top250"
driver.get(url)# 可以加个等待,确保页面加载完成(也可以用显式等待,下面示例会演示)
time.sleep(3) # ---------------------------
# 3. 定位并提取单页中的电影信息(名称、评分、简介链接等)
# ---------------------------
# 先定义一个列表,用来存储所有电影信息
movies = []# 找到当前页面所有的“电影条目”(每个条目是 <div class="item">...)
movie_items = driver.find_elements(By.CSS_SELECTOR, ".item")for item in movie_items:# 电影名称:一般在 <span class="title"> 标签里title_elem = item.find_element(By.CSS_SELECTOR, ".title")title = title_elem.text# 电影评分:一般在 <span class="rating_num"> 标签里rating_elem = item.find_element(By.CSS_SELECTOR, ".rating_num")rating = rating_elem.text# 电影简介链接:一般在 <a> 标签里(也可以拿到 href 属性跳转到详情页)link_elem = item.find_element(By.CSS_SELECTOR, "a")link = link_elem.get_attribute("href")# 把这一条电影信息存到字典里,再 append 到列表movie_info = {"title": title,"rating": rating,"link": link}movies.append(movie_info)# ---------------------------
# 4. 翻页,继续爬取下一页(直到没有下一页为止)
# ---------------------------
while True:try:# 找到“下一页”按钮(一般是 <span class="next"> 里的 <a> 标签)next_page_elem = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, ".next a")))# 点击“下一页”next_page_elem.click()# 等待新页面加载(可以酌情调整等待时间,或者用显式等待特定元素)time.sleep(3)# 再次定位当前页面所有的电影条目movie_items = driver.find_elements(By.CSS_SELECTOR, ".item")for item in movie_items:title_elem = item.find_element(By.CSS_SELECTOR, ".title")title = title_elem.textrating_elem = item.find_element(By.CSS_SELECTOR, ".rating_num")rating = rating_elem.textlink_elem = item.find_element(By.CSS_SELECTOR, "a")link = link_elem.get_attribute("href")movie_info = {"title": title,"rating": rating,"link": link}movies.append(movie_info)except Exception as e:# 如果找不到“下一页”按钮,或者点击失败,说明已经到最后一页了print("已经爬取完所有页面,或者发生异常:", e)break# ---------------------------
# 5. 关闭浏览器,并打印/保存结果
# ---------------------------
driver.quit()# 打印爬到的电影信息(前几条示例)
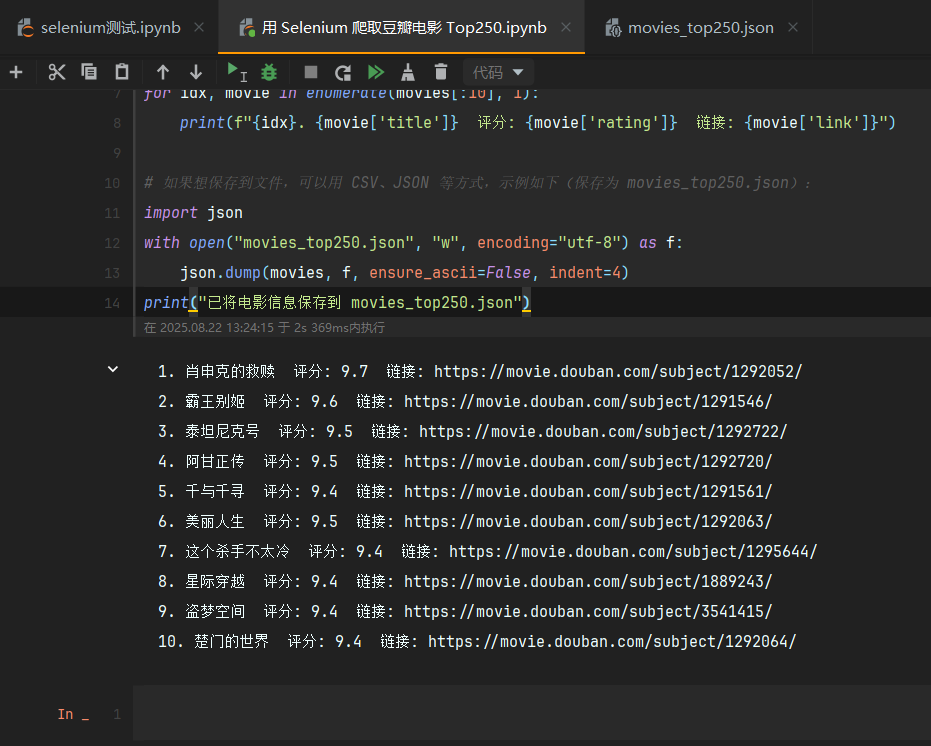
for idx, movie in enumerate(movies[:10], 1):print(f"{idx}. {movie['title']} 评分: {movie['rating']} 链接: {movie['link']}")# 如果想保存到文件,可以用 CSV、JSON 等方式,示例如下(保存为 movies_top250.json):
import json
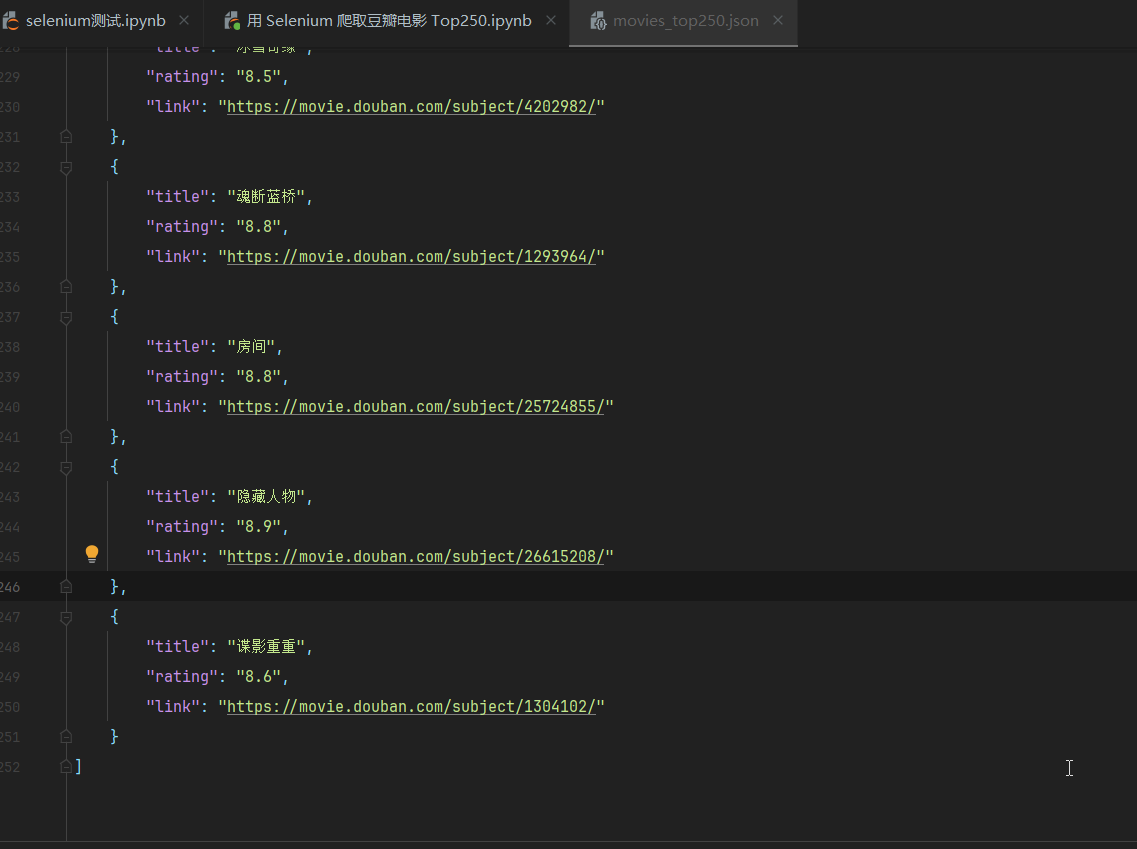
with open("movies_top250.json", "w", encoding="utf-8") as f:json.dump(movies, f, ensure_ascii=False, indent=4)
print("已将电影信息保存到 movies_top250.json")
movies
[{'title': '肖申克的救赎','rating': '9.7','link': 'https://movie.douban.com/subject/1292052/'},{'title': '霸王别姬','rating': '9.6','link': 'https://movie.douban.com/subject/1291546/'},{'title': '泰坦尼克号','rating': '9.5','link': 'https://movie.douban.com/subject/1292722/'},{'title': '阿甘正传','rating': '9.5','link': 'https://movie.douban.com/subject/1292720/'},{'title': '千与千寻','rating': '9.4','link': 'https://movie.douban.com/subject/1291561/'},{'title': '美丽人生','rating': '9.5','link': 'https://movie.douban.com/subject/1292063/'},{'title': '这个杀手不太冷','rating': '9.4','link': 'https://movie.douban.com/subject/1295644/'},{'title': '星际穿越','rating': '9.4','link': 'https://movie.douban.com/subject/1889243/'},{'title': '盗梦空间','rating': '9.4','link': 'https://movie.douban.com/subject/3541415/'},{'title': '楚门的世界','rating': '9.4','link': 'https://movie.douban.com/subject/1292064/'},{'title': '辛德勒的名单','rating': '9.5','link': 'https://movie.douban.com/subject/1295124/'},{'title': '忠犬八公的故事','rating': '9.4','link': 'https://movie.douban.com/subject/3011091/'},{'title': '海上钢琴师','rating': '9.3','link': 'https://movie.douban.com/subject/1292001/'},{'title': '三傻大闹宝莱坞','rating': '9.2','link': 'https://movie.douban.com/subject/3793023/'},{'title': '疯狂动物城','rating': '9.2','link': 'https://movie.douban.com/subject/25662329/'},{'title': '放牛班的春天','rating': '9.3','link': 'https://movie.douban.com/subject/1291549/'},{'title': '机器人总动员','rating': '9.3','link': 'https://movie.douban.com/subject/2131459/'},{'title': '无间道','rating': '9.3','link': 'https://movie.douban.com/subject/1307914/'},{'title': '控方证人','rating': '9.6','link': 'https://movie.douban.com/subject/1296141/'},{'title': '大话西游之大圣娶亲','rating': '9.2','link': 'https://movie.douban.com/subject/1292213/'},{'title': '熔炉','rating': '9.3','link': 'https://movie.douban.com/subject/5912992/'},{'title': '触不可及','rating': '9.3','link': 'https://movie.douban.com/subject/6786002/'},{'title': '寻梦环游记','rating': '9.1','link': 'https://movie.douban.com/subject/20495023/'},{'title': '教父','rating': '9.3','link': 'https://movie.douban.com/subject/1291841/'},{'title': '当幸福来敲门','rating': '9.1','link': 'https://movie.douban.com/subject/1849031/'}]