从聚类到集成,两种实用算法框架分享
一、K-means:让数据自己 “找组织”
什么是聚类?
聚类属于无监督学习的范畴 —— 简单说就是手里没有标签时,我们要把长得像的样本分到一组。比如给一堆用户数据,不需要提前知道 “高价值用户”“潜在用户” 这些标签,聚类算法能自动帮我们发现数据中隐藏的分组规律。
怎么衡量 “像不像”?
判断样本是否相似,关键看距离度量方式:
- 欧式距离:最常用的一种,就像平面上两点间的直线距离,扩展到 n 维空间就是各维度差值的平方和开根号。
- 曼哈顿距离:更像城市里打车的路线,算的是坐标差值的绝对值之和(比如从 (1,2) 到 (3,5),距离就是 | 1-3|+|2-5|=5)。
K-means 的核心步骤
- 先定一个 k 值(想分成几类),随机选 k 个样本当初始 “聚类中心”
- 算每个样本到这 k 个中心的距离,把样本分到最近的中心那组
- 重新计算每组的均值,作为新的聚类中心
- 重复第 2、3 步,直到中心位置不再变化,聚类结果就稳定了
怎么评价聚类效果?
可以看CH 指标:这个值越大,说明组内样本越集中(紧凑),组间差异越明显(分散),聚类效果就越好。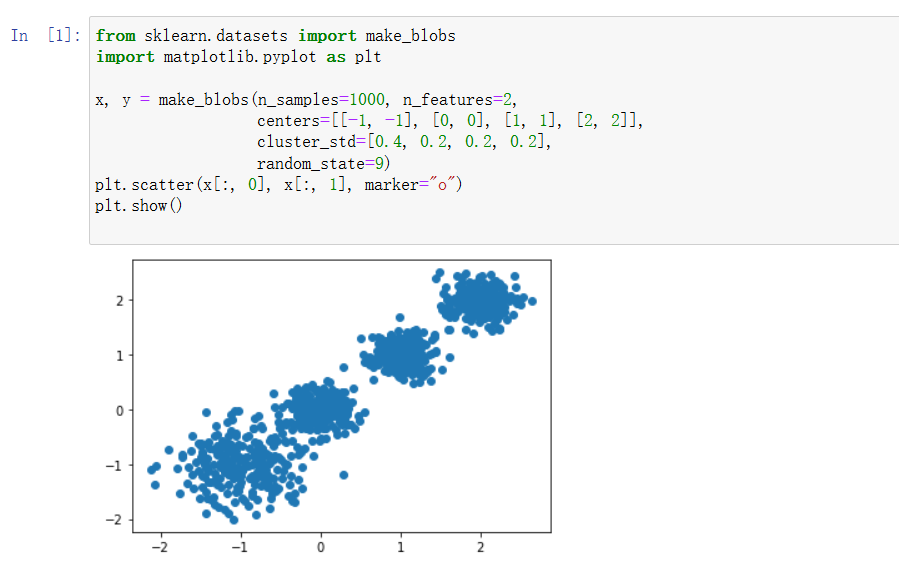
优缺点很鲜明
- 优点:简单快速,对常规数据集很友好
- 缺点:k 值得自己定(这点很麻烦),对非凸形状的簇不太敏感,计算量会随样本数线性增长
二、集成学习:三个臭皮匠顶个诸葛亮
核心思想
就像做决策时,多听几个专家的意见往往比单听一个更靠谱。集成学习就是把多个 “弱学习器”(性能一般的模型)组合起来,变成一个 “强学习器”(性能更优的模型)。
常见的三种组合套路
Bagging(并行模式)
代表是随机森林:- 随机:既随机采样数据,又随机选特征,让每个决策树都有点 “个性”
- 森林:多棵决策树并行生长,最后投票(分类)或平均(回归)出结果
优势是能处理高维数据,还能告诉我们哪些特征更重要,训练速度也快(树可以并行生成)。
Boosting(串行模式)
典型如 AdaBoost:
从弱学习器开始,每次都根据上一轮的错误调整样本权重 —— 分错的样本会被 “重点关照”(权重提高),下一个学习器会更关注这些难分的样本。最后按每个学习器的表现给权重,组合成强学习器。Stacking(堆叠模式)
更 “暴力” 的组合方式:先让各种模型(KNN、SVM、随机森林等)分别输出结果,再把这些结果当新特征,训练一个 “元模型” 来做最终预测,相当于 “用模型的结果再建模”。
组合策略
- 简单平均 / 加权平均(回归常用)
- 投票法(分类常用,少数服从多数)