机器学习-数据预处理全指南:从缺失值到特征编码
在机器学习的流程中,数据预处理是决定模型性能的关键步骤。原始数据往往存在缺失值、量纲不一致、特征类型复杂等问题,直接影响模型的训练效果。本文将围绕数据预处理的核心环节展开,包括缺失值处理、数据标准化、特征编码和数据二值化,帮助你掌握提升数据质量的实用方法。
一、缺失值处理:让数据更完整
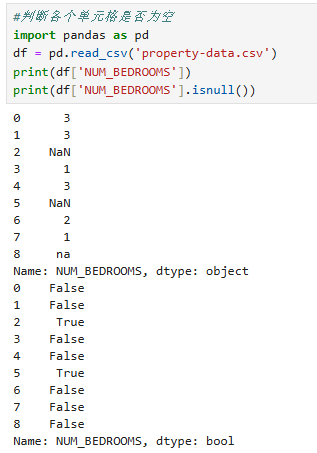
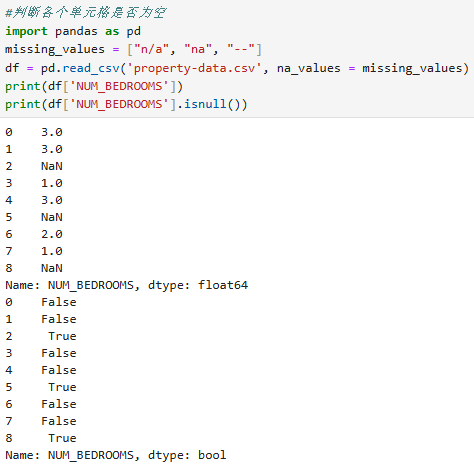
1.isnull():判断各个单元格是否为空
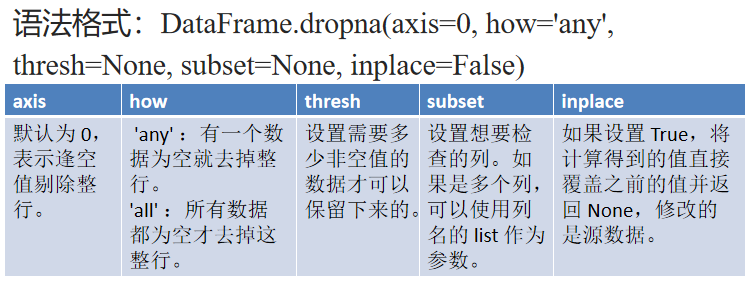
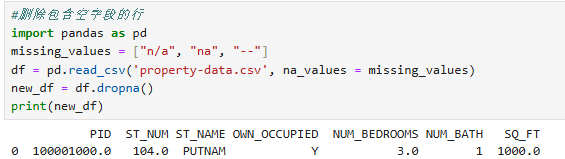
2.dropna():删除包含空字段的行
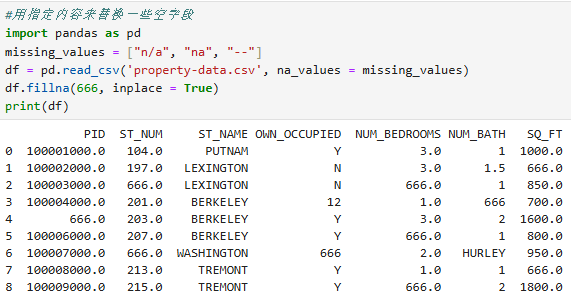
3.fillna() :用指定内容来替换一些空字段
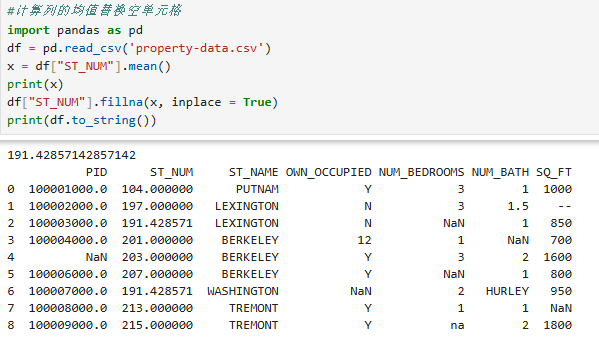
4.mean():计算列的均值替换空单元格
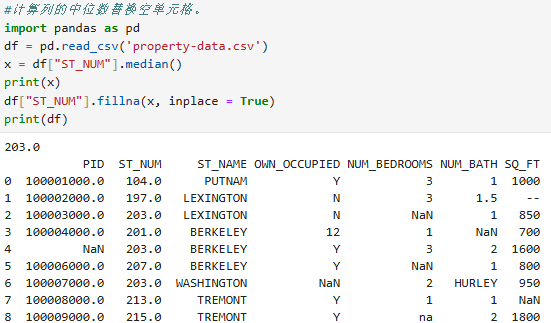
5.median():计算列的中位数替换空单元格
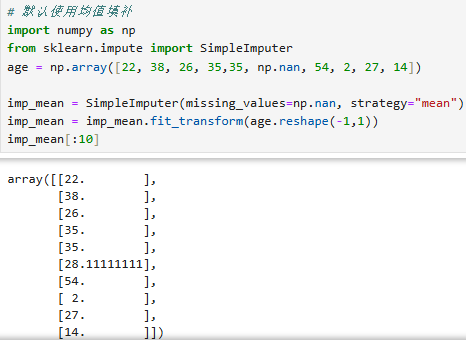
6.Impute.SimpleImputer():
处理缺失值之使用均值填补
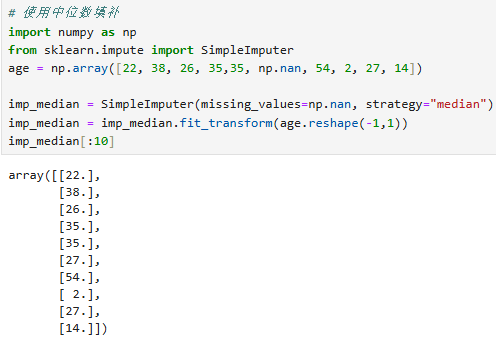
中位数填补
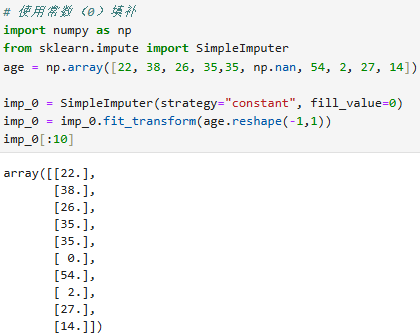
常数填补
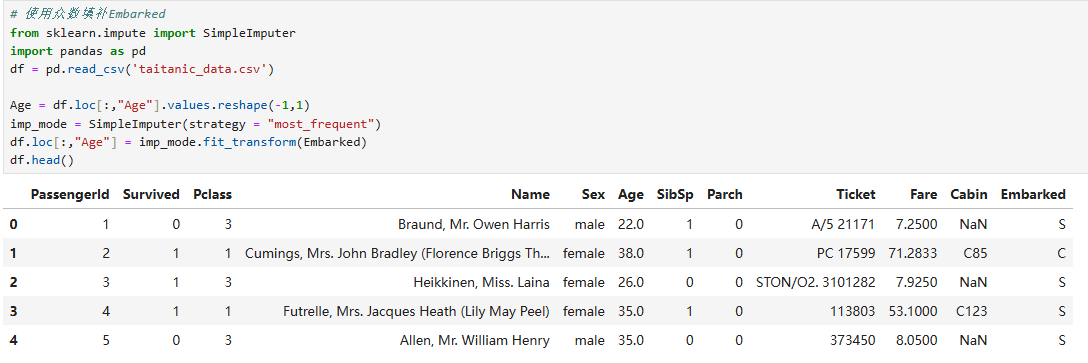
众数填补
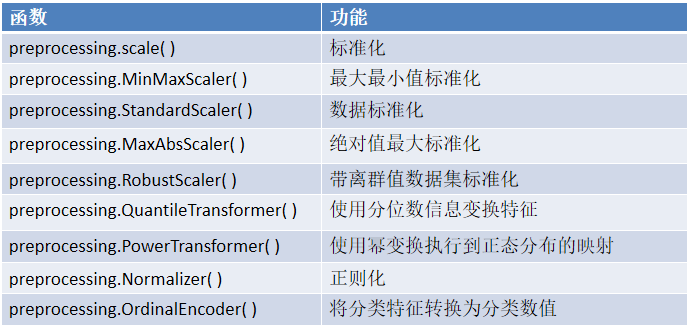
二、数据标准化:消除量纲影响


1.preprocessing.MinMaxScaler( ):最大最小值标准化

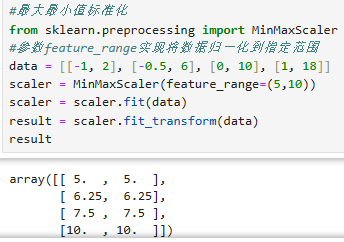
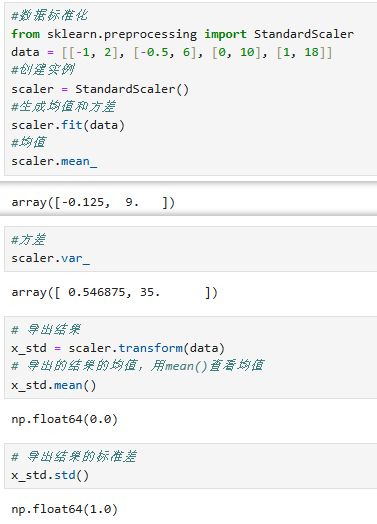
2.preprocessing.StandardScaler( ):Z值数据标准化
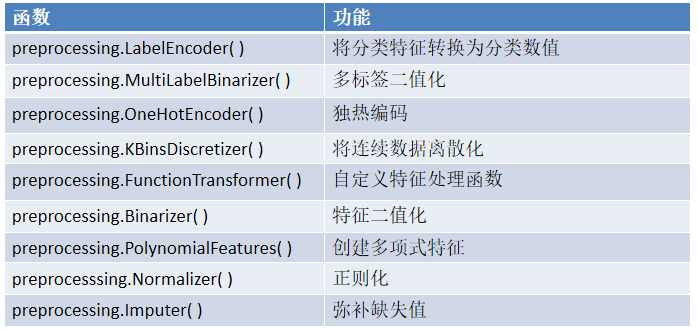
三、特征编码:让模型读懂类别
1. 名义变量:数值之间相互独立,彼此没有联系 性别:男、女
2. 有序变量:数值之间有顺序,不能进行计算 学历:小学、初中、高中
3. 有距变量:数值之间有联系且可以计算 分数:100、90、60




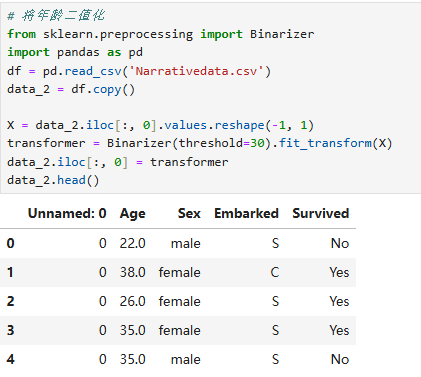
四、数据二值化:简化特征表达
根据数值是否大于某个阈值,将数据分为两类0或1
五、总结
数据预处理是机器学习 pipeline 中不可或缺的环节,直接影响模型的泛化能力和预测精度。从缺失值处理到数据标准化,从特征编码到数据二值化,每一步都需要结合数据特点和业务场景选择合适的方法。在实际应用中,建议先深入分析数据分布和缺失情况,再针对性地制定预处理策略,为后续模型训练打下坚实的数据基础。