数学建模竞赛中评价类相关模型
层次分析法(AHP)
一、核心定义
层次分析法,简称AHP,是一种定性与定量相结合的多准则决策方法。它由美国运筹学家托马斯·萨蒂在20世纪70年代提出。
它的核心思想是:将复杂的决策问题分解为目标、准则、方案等层次,在此基础上进行定性和定量分析。 简单来说,就是把人的主观判断用数量形式表达和处理。
二、为什么需要AHP?
在数学建模中,尤其是评价类问题,我们经常会遇到这样的困境:
目标多样:决策受到多个因素的影响(例如,选择旅游地要考虑景色、费用、居住、饮食、交通等)。
难以量化:这些因素(准则)的重要性(权重)很难直接用数据衡量,很大程度上依赖于人的主观判断。
存在矛盾:这些准则之间可能相互矛盾(例如,景色好的地方通常费用高)。
AHP就是为了解决这类问题而生的。它提供了一种系统性的、结构化的方法,将决策者的经验判断数字化,从而为多准则、多方案的复杂决策问题提供一个简洁而有力的工具。
三、AHP的核心步骤
使用AHP解决问题,通常包括以下四个基本步骤:
第一步:建立层次结构模型
将问题条理化、层次化,构造一个层次清晰的结构模型。通常分为三层:
目标层:最高层,表示要解决的问题(例如:选择最佳旅游地)。
准则层:中间层,表示衡量是否达到目标的判断准则(例如:景色、费用、居住、饮食、交通)。
方案层:最低层,表示可供选择的方案(例如:苏杭、北戴河、桂林)。
第二步:构造判断(成对比较)矩阵
AHP不把所有因素放在一起比较,而是两两相互比较,以减少比较的困难和提高准确度。
方法:从层次结构模型的第2层(准则层)开始,对于从属于上一层每个因素的同层因素,用成对比较法和1-9比较尺度构造成对比较矩阵。
1-9尺度表:
标度 含义 1 表示两个因素相比,具有同样重要性 3 表示两个因素相比,一个因素比另一个因素稍微重要 5 表示两个因素相比,一个因素比另一个因素明显重要 7 表示两个因素相比,一个因素比另一个因素强烈重要 9 表示两个因素相比,一个因素比另一个因素极端重要 2,4,6,8 上述两相邻判断的中值 示例:在准则层,比较“景色”和“费用”对于“选择旅游地”这个目标的重要性。如果你认为“景色”比“费用”明显重要,那么在矩阵中,“景色”相对于“费用”的标度就是5,而“费用”相对于“景色”的标度就是其倒数1/5。
第三步:层次单排序及其一致性检验
这一步的目的是计算每个判断矩阵的权重向量,并检验逻辑上是否一致。
计算权重:即计算判断矩阵的特征向量,其分量就是对应因素的权重。有近似算法(和法、根法等)和精确算法(求特征值)。
一致性检验:由于判断是主观的,可能会出现矛盾(例如:A比B重要,B比C重要,但C又比A重要,这在逻辑上不一致)。AHP引入了一致性指标CI和一致性比率CR来检验这种不一致的程度是否在可接受的范围内(通常要求CR < 0.1)。如果通过检验,则权重有效;否则,需要调整判断矩阵。
第四步:层次总排序及其一致性检验
层次总排序:计算各层因素对于总目标(最高层)的相对重要性排序权值。这个过程是从最高层到最低层逐层进行的。
最终决策:方案层各方案对总目标的权重计算出来后,权重最大的方案即为最优方案。
四、一个简单的例子(选择旅游地)
建立层次:
目标:选择旅游地
准则:景色、费用、居住、饮食、交通
方案:苏杭、北戴河、桂林
构造判断矩阵:
构造准则层对目标层的矩阵(比较5个准则的重要性)。
构造方案层对每个准则的矩阵(例如,在“景色”准则下,比较三个地方的景色好坏)。
计算权重并检验:
计算准则层5个因素的权重(W = [景色权重,费用权重,...])。
分别计算在“景色”、“费用”等每个准则下,三个方案的权重。
总排序:
苏杭的总得分 = (苏杭的景色权重 * 景色的准则权重) + (苏杭的费用权重 * 费用的准则权重) + ...
同理计算北戴河和桂林的总得分。
总得分最高的地方就是推荐选择。
五、AHP的优点与局限性
优点:
系统性:将问题分解,思路清晰。
简洁实用:所需定量数据信息较少,但能明确表达决策者的主观判断。
定性定量结合:非常适合处理那些难以完全用定量数据分析的复杂问题。
局限性:
主观性较强:结果的准确性很大程度上依赖于决策者的判断。不同的人可能得出不同的结论。
指标过多时数据量大:当因素太多时(通常认为不宜超过9个),构造的判断矩阵数量多,且容易引起混乱和判断不一致。
方案层需要完备:AHP只能在已有方案中择优,不能生成新方案。
总结
在数学建模中,层次分析法是解决评价类问题,特别是确定指标权重的一把利器。当你遇到需要综合考虑多种因素,而这些因素又没有现成的数据来直接衡量其重要性时,AHP就是一个非常值得考虑的方法。它通过严谨的数学方法(矩阵、特征向量)将人的主观判断合理化、数量化,最终给出一个相对科学的决策依据。
如何将这个模型应用在这些题型当中:
核心判断标准:一个问题,两个条件
当你遇到一个问题时,先问自己:“这是不是一个评价、选择、排序类的问题?” 如果答案是“是”,接着看它是否满足以下两个条件:
目标多元性:决策目标受到多个相互关联或相互制约的准则(因素/指标)的影响。
主观判断性:这些准则的重要性(权重)缺乏明确的客观数据,主要依赖于人的主观经验或判断。
如果两个条件都满足,那么AHP大概率就是你的首选武器。
快速识别“AHP题型”的四大信号
在做题时,留意题目中是否出现以下关键词和场景,它们是指向AHP的强烈信号。
信号一:题目直接要求“评价”或“决策”
典型问题:
“请建立模型对...进行综合评价。”
“请选择最优的...”
“请对...进行排序。”
关键词:
评价、评估、优选、排序、决策、衡量、综合实力
信号二:题目包含多个评价维度(准则)
典型描述:
“需要考虑A、B、C、D等多个方面...”
“评价指标包括经济效益、社会效益、环境效益...”
“从价格、性能、外观、售后服务等角度进行选择...”
关键词:
指标、因素、准则、维度、方面、从...角度
信号三:指标的重要性需要人为判断
典型描述:
“...其中,安全性比成本更重要。”
“...专家认为,环境因素应被视为最关键的因素。”
(题目没有给出各指标的具体权重数据,但暗示了它们的重要性不同)
关键词:
更重要、最关键、首要因素、权重(但未给出)
信号四:问题背景模糊,数据难以量化
典型场景:
选择类:选旅游地、选供应商、选投资项目、选专业、选房子。
评价类:企业竞争力评价、城市宜居度评价、员工绩效评价、网络安全风险评估。
资源分配类:科研经费分配(评价各项目的重要性)、发展方案优先序排序。
特点:你发现很难找到直接的数据来计算“哪个更好”,但你可以通过查文献、专家咨询或常识来判断“哪个因素更重要”。
例题1:《空气质量评价问题》
“请建立模型评价北京、上海、广州、深圳四个城市的空气质量。评价指标可考虑PM2.5、PM10、SO₂、NO₂、CO、O₃等污染物的年均浓度。”
分析:
这是不是评价问题?是(评价空气质量)。
是否多准则?是(有6个评价指标)。
权重有数据吗?没有。题目只给了浓度数据,但没说明PM2.5和SO₂谁更重要。这需要根据其对健康影响的常识或专家知识来主观判断。
结论:非常适合AHP。用AHP确定各污染物指标的权重,再结合各城市的浓度数据(需要做数据预处理,如归一化)进行综合评分。
例题2:《旅游目的地选择问题》
“小明想从苏杭、北戴河、桂林中选择一个地方旅游。他考虑的因素有:景色、费用、居住、饮食、交通。请帮他做出决策。”
分析:这就是AHP的经典教学案例,完全符合所有信号。
结论:AHP的标准题型。
什么情况可能不适合或不单独使用AHP?
指标权重有明确客观数据:比如题目直接规定“成本权重占0.6,质量权重占0.4”,那就直接用加权求和(TOPSIS法)即可,不需要AHP来求权重。
评价指标非常多(>9个):判断矩阵会非常庞大且难以满足一致性,考虑与其他方法(如熵权法)结合,或者先用因子分析等降维。
问题完全是客观的优化问题:例如,“在给定成本下,求最大利润”,这是一个规划问题,用线性/非线性规划。
一句话总结:当你需要靠“拍脑袋”来决定哪个因素更重要时,这个“脑袋”就可以用AHP来拍得科学、拍得有道理。
基本思想:AHP是一种定性与定量相结合的多准则决策、评价方法。它将复杂问题分解为目标层、准则层和方案层,通过两两比较确定各层元素的相对重要性,进而进行定性和定量分析。
优点:结构清晰,易于操作,能将定性分析与定量分析相结合,特别适合在社会经济系统的决策分析中使用。
缺点:主观成分较大,当决策者的判断过多地受其主观偏好影响时,结果可能不准确。此外,当遇到因素众多、规模较大的评价问题时,该模型容易出现问题。
应用场景:尤其适合于人的定性判断起重要作用的、对决策结果难于直接准确计量的场合。
建模步骤:
- 构建层次结构模型。
- 构建成对比较矩阵。
- 层次单排序及一致性检验。
- 层次总排序及一致性检验。
层次结构模型:
1. 判断矩阵 (Pairwise Comparison Matrix) - 一切的起点
这是最基础的表达式,是一个 n x n 的正互反矩阵。
A = (a_{ij})_{n×n}
其中:
n是当前层次中相互比较的因素个数。a_{ij}表示第i个因素相对于第j个因素的重要性比值。矩阵满足以下性质:
a_{ij} > 0(正性)a_{ji} = 1 / a_{ij}(互反性)a_{ii} = 1(对角线为1)
2. 权重向量 (Weight Vector) - 核心输出
通过计算判断矩阵 A 的特征向量,可以得到各因素的权重。最常用的近似计算方法是算术平均法(和法)。
步骤1: 将判断矩阵 A 按列归一化。
\bar{a}_{ij} = \frac{a_{ij}}{\sum_{k=1}^{n} a_{kj}}
步骤2: 将归一化后的矩阵按行求和。
W_i = \sum_{j=1}^{n} \bar{a}_{ij}
步骤3: 将行和向量 W_i 归一化,即得到权重向量 ω。
ω_i = \frac{W_i}{\sum_{i=1}^{n} W_i}
最终得到的权重向量为:
ω = [ω₁, ω₂, ..., ω_n]^T
3. 一致性检验指标 (Consistency Index) - 可靠性保证
由于判断是主观的,需要进行一致性检验,确保逻辑上没有自相矛盾。
步骤1: 计算判断矩阵 A 的最大特征值 λ_max。
λ_{max} = \frac{1}{n} \sum_{i=1}^{n} \frac{(Aω)_i}{ω_i}
其中 (Aω)_i 是向量 Aω 的第 i 个分量。
步骤2: 计算一致性指标 CI。
CI = \frac{λ_{max} - n}{n - 1}
步骤3: 查询随机一致性指标 RI(查表获得)。
| n | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| RI | 0 | 0 | 0.52 | 0.89 | 1.12 | 1.26 | 1.36 | 1.41 | 1.46 |
步骤4: 计算一致性比率 CR。
CR = \frac{CI}{RI}
决策规则: 当 CR < 0.10 时,认为判断矩阵的一致性是可以接受的,否则需要重新调整矩阵。
4. 层次总排序 (Overall Priority Synthesis) - 最终结果
这是最终表达式,计算方案层所有元素对于总目标的相对权重。
假设:
准则层
C有m个因素C₁, C₂, ..., C_m,其对于总目标的权重向量为a = [a₁, a₂, ..., a_m]^T。方案层
P有n个方案P₁, P₂, ..., P_n。每个方案
P_j对每个准则C_i的权重为b_{ij}(即针对每个准则C_i,都用一个判断矩阵算出了一个方案层的权重向量[b_{i1}, b_{i2}, ..., b_{in}]^T)。
那么,方案层第 j 个方案 P_j 对于总目标的最终权重 V_j 为:
V_j = \sum_{i=1}^{m} a_i · b_{ij} \quad (j=1,2,...,n)
用矩阵表示非常简洁明了:
V = B · a
其中:
V = [V₁, V₂, ..., V_n]^T是n x 1的总排序权重向量。a = [a₁, a₂, ..., a_m]^T是m x 1的准则层权重向量。B是n x m的矩阵,其第(j, i)元素就是b_{ij}(方案j对准则i的权重)。
最终决策:比较 V₁, V₂, ..., V_n 的大小,最大值对应的方案即为最优方案。
总结
层次结构模型的表达式不是一个单一公式,而是一个公式体系:
A: 表达主观两两比较的 判断矩阵。ω: 表达单一准则下各因素相对重要性的 权重向量。CI/CR: 表达判断逻辑是否合理的 一致性检验公式。V = B · a: 表达从底层方案到顶层目标综合权重的 层次总排序公式。
成对比较矩阵:
一、核心思想
不要同时比较所有因素,而是只进行两两比较。 人类大脑在处理多个因素的相对重要性时,容易混乱。但只比较两个因素,我们就能做出更清晰、更准确的判断。
二、构建步骤
第一步:明确比较的“对象”和“准则”
在开始填数字之前,必须无比清晰以下两点:
比较的元素(Object)是什么? 例如,是要比较“景色、费用、居住、饮食、交通”这5个准则对于“选择旅游地”的重要性。
比较的准则(Criterion)是什么? 即“相对于哪个上层目标”来比较它们?例如,我们是“相对于「选择最佳旅游地」这个总目标”来比较景色和费用谁更重要,而不是孤立地问“景色和费用哪个重要”。
口诀:为谁而比?比的是什么?
第二步:使用1-9标度法进行两两判断
对于n个元素,你需要进行 C(n,2) = n(n-1)/2 次两两比较。使用经典的萨蒂1-9标度法来量化你的判断。
标度 a_{ij} | 含义(因素i与因素j相比) |
|---|---|
| 1 | 同样重要 (Equal Importance) |
| 3 | 稍微重要 (Moderate Importance) |
| 5 | 明显重要 (Strong Importance) |
| 7 | 强烈重要 (Very Strong Importance) |
| 9 | 极端重要 (Extreme Importance) |
| 2, 4, 6, 8 | 上述相邻判断的中间值 (Intermediate Values) |
| 倒数 | 如果因素i与j的重要性之比为 a_{ij},则因素j与i的重要性之比为 a_{ji} = 1 / a_{ij} |
如何提问自己?
对于元素 i 和元素 j,问:
“对于实现上层目标而言,我认为元素i比元素j重要多少?”
技巧:
先定性,后定量:先决定“谁比谁重要”,再决定“重要多少(选择1,3,5,7,9或其倒数)”。
参考锚点:可以先找出你认为最重要的和最不重要的元素,以它们为参考点,去评估其他元素。
第三步:填充矩阵
创建一个 n x n 的表格。根据你的判断,只填充上三角(或下三角) 部分,然后利用互反性质自动填充另一半。
规则:
对角线上的元素
a_{ii}永远是 1(自己和自己比同样重要)。如果你判断
a_{ij} = X,那么对称位置a_{ji}就必须是 1/X。
三、实例演示:选择旅游地
任务: 构建准则层(景色、费用、居住、饮食、交通)对于目标(选择最佳旅游地)的判断矩阵。
假设决策者(你)的判断如下:
景色比费用明显重要 ->
a_{景色,费用} = 5景色比居住稍微重要 ->
a_{景色,居住} = 3景色比饮食稍微重要 ->
a_{景色,饮食} = 3景色比交通明显重要 ->
a_{景色,交通} = 5费用比居住同样重要 ->
a_{费用,居住} = 1费用比饮食稍微不重要 ->
a_{费用,饮食} = 1/3(因为饮食比费用稍微重要)费用比交通同样重要 ->
a_{费用,交通} = 1居住比饮食同样重要 ->
a_{居住,饮食} = 1居住比交通稍微重要 ->
a_{居住,交通} = 3饮食比交通稍微重要 ->
a_{饮食,交通} = 3
根据以上判断填充矩阵:
先填对角线和上三角(根据以上判断):
| A | 景色 | 费用 | 居住 | 饮食 | 交通 |
|---|---|---|---|---|---|
| 景色 | 1 | 5 | 3 | 3 | 5 |
| 费用 | 1 | 1 | 1/3 | 1 | |
| 居住 | 1 | 1 | 3 | ||
| 饮食 | 1 | 3 | |||
| 交通 | 1 |
利用互反性(倒数关系)填充下三角:
| A | 景色 | 费用 | 居住 | 饮食 | 交通 |
|---|---|---|---|---|---|
| 景色 | 1 | 5 | 3 | 3 | 5 |
| 费用 | 1/5 | 1 | 1 | 1/3 | 1 |
| 居住 | 1/3 | 1 | 1 | 1 | 3 |
| 饮食 | 1/3 | 3 | 1 | 1 | 3 |
| 交通 | 1/5 | 1 | 1/3 | 1/3 | 1 |
这样,一个完整的成对比较矩阵就构建完成了。
四、重要注意事项与常见误区
逻辑一致性(最重要!):
你的判断要尽量避免矛盾。例如,如果A比B重要(=5),B比C重要(=3),那么A应该比C重要(应该≈5*3=15,但最大标度是9,所以至少应该是7或9)。如果你判断A不如C重要(=1/3),那就出现了严重的逻辑不一致,后续的一致性检验肯定无法通过。
技巧:填完矩阵后,快速检查一下是否有明显矛盾。正式的一致性检验会在计算权重时进行。
基于事实或专家意见:
判断不应是完全随意的“拍脑袋”。应基于数据(如历史数据、统计数据)、专业知识或团队共识。在数学建模中,可以查阅文献来佐证你的赋值,或者说明“假设决策者认为...”。
不要盲目追求精确:
标度1,3,5,7,9之间的差异已经足够大。不需要使用像2.7、4.2这样过于精细的数字,这反而会显得不科学。使用整数和它们的倒数是最佳实践。
为谁构建矩阵?
这个矩阵反映的是特定决策者(或个人、团队、文献来源)的判断。不同的人可能会构建出不同的矩阵,这体现了AHP处理主观性的特点。
总结:构建成对比较矩阵就是一个系统性的“提问-回答-填表”过程。核心是牢记“两两比较”和“1-9标度”,并在过程中尽力保持逻辑的一致性。
一致性检验:
一、为什么要做一致性检验?
因为人的判断可能存在矛盾。例如:
你认为A比B重要(=5)
B比C重要(=3)
根据逻辑,A应该比C明显重要(5×3=15,由于标度最大为9,所以至少应为7或9)。
但如果你在矩阵中判断A不如C重要(=1/3),这就产生了严重的逻辑不一致。
一致性检验就是用一个量化的指标(CR)来衡量这种不一致的程度是否在可接受的范围内。
二、一致性检验的完整步骤
我们通过一个计算例子来贯穿整个流程。假设有一个3阶判断矩阵 A:
A = | | 因素1 | 因素2 | 因素3 |
| :---- | :--- | :--- | :--- |
| 因素1 | 1 | 5 | 3 |
| 因素2 | 1/5 | 1 | 1/3 |
| 因素3 | 1/3 | 3 | 1 |
我们的目标是计算它的一致性比率CR,并判断是否通过检验。
第一步:计算权重向量 (ω)
采用近似算法——算术平均法(和法)。
将矩阵按列归一化(每列元素除以该列之和)。
列1之和:1 + 0.2 + 0.333 = 1.533
列2之和:5 + 1 + 3 = 9
列3之和:3 + 0.333 + 1 = 4.333
归一化后矩阵
A_norm:
[1/1.533, 5/9, 3/4.333] [0.652, 0.556, 0.692]
[0.2/1.533, 1/9, 0.333/4.333] ≈ [0.130, 0.111, 0.077]
[0.333/1.533, 3/9, 1/4.333] [0.217, 0.333, 0.231]将归一化后的矩阵按行求和。
行1:0.652 + 0.556 + 0.692 = 1.900
行2:0.130 + 0.111 + 0.077 = 0.318
行3:0.217 + 0.333 + 0.231 = 0.781
将行和向量归一化,得到权重向量ω。
行和总和:1.900 + 0.318 + 0.781 = 2.999 ≈ 3
ω1 = 1.900 / 3 = 0.633
ω2 = 0.318 / 3 = 0.106
ω3 = 0.781 / 3 = 0.260
权重向量 ω = [0.633, 0.106, 0.260]^T
第二步:计算最大特征值 (λ_max)
计算矩阵A与权重向量ω的乘积:
Aω。
Aω = [1*0.633 + 5*0.106 + 3*0.260] [1.913][0.2*0.633 + 1*0.106 + 0.333*0.260] ≈ [0.320][0.333*0.633 + 3*0.106 + 1*0.260] [0.785]计算最大特征值λ_max。
λ_max = 1/n * Σ [ (Aω)_i / ω_i ](Aω)₁ / ω₁ = 1.913 / 0.633 ≈ 3.022
(Aω)₂ / ω₂ = 0.320 / 0.106 ≈ 3.019
(Aω)₃ / ω₃ = 0.785 / 0.260 ≈ 3.020
λ_max = (3.022 + 3.019 + 3.020) / 3 = 9.061 / 3 = 3.020
第三步:计算一致性指标 (CI)
公式:CI = (λ_max - n) / (n - 1)
n = 3 (矩阵的阶数)
CI = (3.020 - 3) / (3 - 1) = 0.020 / 2 = 0.010
第四步:查询平均随机一致性指标 (RI)
RI值通过大量随机实验得到,是一个固定值,查表即可。
| 矩阵阶数 (n) | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| RI | 0 | 0 | 0.52 | 0.89 | 1.12 |
本例中 n=3,所以 RI = 0.52。
第五步:计算一致性比率 (CR) 并判断
公式:CR = CI / RI
CR = 0.010 / 0.52 ≈ 0.019
决策规则:
如果 CR < 0.10:认为判断矩阵的一致性可以接受。
如果 CR ≥ 0.10:认为判断矩阵的一致性不可接受,需要返回修改最初的判断值。
本例结论: CR = 0.019 < 0.10,通过一致性检验。权重向量ω=[0.633, 0.106, 0.260]^T 是有效的。
三、如果未通过检验(CR ≥ 0.10)怎么办?
这说明你的判断矩阵中存在明显的逻辑矛盾。你需要:
定位问题:查看矩阵中哪些元素可能导致了不一致。通常,偏离一致性最多的元素可能存在问题。
重新评估:找到这些有问题的两两比较(例如,之前判断A比B=5,B比C=3,但A比C却=1),思考哪个判断最可能出错。
微调数值:修改其中一个或几个判断值(例如,将A比C从1改为7),使整体逻辑更通顺。
重新计算:用新的矩阵重新计算权重和CR,直到满足CR < 0.1为止。
技巧:通常微调重要性最高的因素所对应的判断值,对改善CR值最有效。
总结:一致性检验流程口诀
算权重 (ω) -> 列归一,行求和,再归一。
求特征值 (λ_max) -> 算Aω,除ω,求平均。
算CI -> (λ_max - n) / (n - 1)
查RI -> 根据阶数n直接查表。
算CR -> CI / RI
做判断 -> CR < 0.1 ? 通过 : 打回修改。
灰色综合评价法(灰色关联分析)
基本思想:灰色关联分析通过研究数据序列之间的几何相似性,利用关联度大小对评价对象进行比较和排序。关联度越大,说明比较序列与参考序列变化的态势越一致。
优点:计算过程简单,通俗易懂,易于为人们所掌握;数据不必进行归一化处理,可用原始数据进行直接计算,可靠性强;评价指标体系可以根据具体情况增减;无需大量样本,只要有代表性的少量样本即可。
缺点:是一种评价具有大量未知信息的系统的有效模型,但指标体系及权重分配的选择直接影响最终评价结果。
应用场景:对样本量没有严格要求,不要求服从任何分布,适合只有少量观测数据的问题。
建模步骤:
- 建立原始指标矩阵。
- 确定最优指标序列。
- 进行指标标准化或无量纲化处理。
- 求差序列、最大差和最小差。
- 计算关联系数。
- 计算关联度。
第一部分:核心思想与“灰色”的含义
1. 什么是“灰色”?
在系统理论中,我们常用颜色来表示信息的完备程度:
白色系统:信息完全明确。例如一个已知所有参数和运动规律的机械装置。
黑色系统:信息完全未知。例如一个完全不了解其内部结构的黑箱。
灰色系统:信息部分明确、部分不明确,是介于白色和黑色之间的系统。这是现实世界中最常见的情况。
例如,评价一个地区的经济发展水平。我们有一些明确的指标数据(如GDP、人均收入),但还有很多难以量化或信息不全的因素(如政策影响、文化因素、未来潜力)。这个经济系统就是一个典型的灰色系统。
2. 灰色关联分析的核心思想
灰色关联分析的核心目的,就是在一个灰色系统中,通过一定的方法,定量地刻画各种因素之间的关联程度。
它的基本思想是:通过比较各因素构成的数据序列与一个理想序列(参考序列)的几何形状的相似程度,来判断其关联性。几何形状越接近,其变化趋势就越一致,关联度就越大。
一个生动的比喻:
想象一条笔直的理想道路(参考序列)。现在有几辆车(比较序列)在路上开。哪辆车的行驶轨迹与这条理想道路的形状最贴合、偏离最小,哪辆车就与这条路的“关联度”最高。
第二部分:应用场景(什么时候用?)
灰色关联分析非常适合以下情况:
样本量小:不需要大样本数据,通常只要有4个以上样本就可以分析。
规律性不明显:数据不一定需要典型的分布(如正态分布)。
多因素、多指标的系统评价:例如综合评价、方案决策、优势分析等。
动态过程分析:分析随时间变化的序列之间的关联关系。
典型应用领域:
经济效益综合评价:评价多个企业的综合效益。
方案决策:从多个方案中选出最优方案。
影响因素分析:分析哪个因素对结果的影响最大(例如,分析影响农作物产量的主要因素)。
工程质量评估、产业关联分析等。
第三部分:计算步骤(事无巨细版)
我们通过一个完整的例子来一步步演示。假设我们要评价3个学生的综合素质(Student A, B, C),评价指标有4项:成绩(Score)、品德(Ethics)、体育(Sports)、实践(Practice)。数据如下:
| 学生 (Sequence) | 成绩 (X1) | 品德 (X2) | 体育 (X3) | 实践 (X4) |
|---|---|---|---|---|
| 理想学生 (X0) | 90 | 95 | 85 | 90 |
| Student A (X1) | 85 | 90 | 90 | 80 |
| Student B (X2) | 95 | 80 | 70 | 85 |
| Student C (X3) | 75 | 85 | 95 | 90 |
我们的目标是:计算每个学生与“理想学生”的关联度,关联度越高,说明该学生综合素质越好。
第1步:确定参考序列和比较序列
参考序列 (X₀): 理想的、想要进行比较的基准序列。通常由最优值或目标值构成。
本例中:
X0 = [90, 95, 85, 90]
比较序列 (X₁, X₂, ..., Xₙ): 需要与参考序列进行比较的各个序列。
本例中:
X1 = [85, 90, 90, 80],X2 = [95, 80, 70, 85],X3 = [75, 85, 95, 90]
第2步:数据的无量纲化处理(非常重要!)
由于各指标的量纲和数量级可能不同(例如,成绩是百分制,体育可能是等级制),直接计算会突出数值大的指标而弱化数值小的指标。因此必须消除量纲,转化为纯数值。
最常用的方法是初值化法或均值化法。这里介绍最通用的均值化法。
公式: $Y_{i}(k) = \frac{X_{i}(k)}{\frac{1}{m}\sum_{k=1}^{m} X_{i}(k)} = \frac{X_{i}(k)}{\bar{X}_{i}}$
其中,
i是序列编号(0,1,2,3),k是指标点编号(1,2,3,4),m是指标总数(本例中m=4)。$\bar{X}_{i}$ 是第
i个序列所有数据的平均值。
计算过程:
计算每个序列的平均值:
$\bar{X_0} = (90+95+85+90)/4 = 90$
$\bar{X_1} = (85+90+90+80)/4 = 86.25$
$\bar{X_2} = (95+80+70+85)/4 = 82.5$
$\bar{X_3} = (75+85+95+90)/4 = 86.25$
用每个序列的原始值除以其平均值,得到无量纲化后的新序列:
$Y_0 = X0 / \bar{X_0} = [90/90, 95/90, 85/90, 90/90] = [1, 1.0556, 0.9444, 1]$
$Y_1 = X1 / \bar{X_1} = [85/86.25, 90/86.25, 90/86.25, 80/86.25] ≈ [0.9855, 1.0435, 1.0435, 0.9275]$
$Y_2 = X2 / \bar{X_2} = [95/82.5, 80/82.5, 70/82.5, 85/82.5] ≈ [1.1515, 0.9697, 0.8485, 1.0303]$
$Y_3 = X3 / \bar{X_3} = [75/86.25, 85/86.25, 95/86.25, 90/86.25] ≈ [0.8696, 0.9855, 1.1014, 1.0435]$
为了方便后续计算,我们保留四位小数,整理成表:
| 序列 | 指标1 | 指标2 | 指标3 | 指标4 |
|---|---|---|---|---|
| Y0 | 1.0000 | 1.0556 | 0.9444 | 1.0000 |
| Y1 | 0.9855 | 1.0435 | 1.0435 | 0.9275 |
| Y2 | 1.1515 | 0.9697 | 0.8485 | 1.0303 |
| Y3 | 0.8696 | 0.9855 | 1.1014 | 1.0435 |
第3步:计算关联系数
这是最核心的一步。关联系数反映了在每个指标点上,比较序列与参考序列的差值。
公式: $\gamma_{0i}(k) = \frac{\min\limits_{i} \min\limits_{k} |Y_0(k) - Y_i(k)| + \rho \cdot \max\limits_{i} \max\limits_{k} |Y_0(k) - Y_i(k)|}{|Y_0(k) - Y_i(k)| + \rho \cdot \max\limits_{i} \max\limits_{k} |Y_0(k) - Y_i(k)|}$
$\gamma_{0i}(k)$:第
i个比较序列在第k个指标点上与参考序列的关联系数。$|Y_0(k) - Y_i(k)|$:第
k个指标点上两序列的绝对差。$\min\limits_{i} \min\limits_{k} |Y_0(k) - Y_i(k)|$:所有比较序列在所有指标点上的最小绝对差(两级最小差)。
$\max\limits_{i} \max\limits_{k} |Y_0(k) - Y_i(k)|$:所有比较序列在所有指标点上的最大绝对差(两级最大差)。
$\rho$:分辨系数,是一个介于0~1之间的常数,通常取0.5。它的作用是削弱最大绝对差过大带来的失真,提高关联系数之间的差异显著性。
计算过程:
计算各点绝对差 $\Delta_i(k) = |Y_0(k) - Y_i(k)|$
对于 Y1:
Δ1 = [|1.0000-0.9855|, |1.0556-1.0435|, |0.9444-1.0435|, |1.0000-0.9275|] = [0.0145, 0.0121, 0.0991, 0.0725]对于 Y2:
Δ2 = [|1.0000-1.1515|, |1.0556-0.9697|, |0.9444-0.8485|, |1.0000-1.0303|] = [0.1515, 0.0859, 0.0959, 0.0303]对于 Y3:
Δ3 = [|1.0000-0.8696|, |1.0556-0.9855|, |0.9444-1.1014|, |1.0000-1.0435|] = [0.1304, 0.0701, 0.1570, 0.0435]
找出两级最小差和最大差
从所有 Δ 值中找出最小值和最大值:
Min:0.0121(来自 Y1 的第二个指标)Max:0.1570(来自 Y3 的第三个指标)
代入公式计算每个关联系数(取 ρ=0.5)
计算公共部分:
ρ * Max = 0.5 * 0.1570 = 0.0785分母通用部分:
|Δ_i(k)| + 0.0785计算 Y1 的关联系数 γ01(k):
k=1:
(0.0121 + 0.0785) / (0.0145 + 0.0785) = 0.0906 / 0.0930 ≈ 0.9742k=2:
(0.0121 + 0.0785) / (0.0121 + 0.0785) = 0.0906 / 0.0906 = 1.0000k=3:
(0.0121 + 0.0785) / (0.0991 + 0.0785) = 0.0906 / 0.1776 ≈ 0.5101k=4:
(0.0121 + 0.0785) / (0.0725 + 0.0785) = 0.0906 / 0.1510 ≈ 0.6000∴
γ01 = [0.9742, 1.0000, 0.5101, 0.6000]
计算 Y2 的关联系数 γ02(k):
k=1:
0.0906 / (0.1515 + 0.0785) = 0.0906 / 0.2300 ≈ 0.3939k=2:
0.0906 / (0.0859 + 0.0785) = 0.0906 / 0.1644 ≈ 0.5511k=3:
0.0906 / (0.0959 + 0.0785) = 0.0906 / 0.1744 ≈ 0.5195k=4:
0.0906 / (0.0303 + 0.0785) = 0.0906 / 0.1088 ≈ 0.8327∴
γ02 = [0.3939, 0.5511, 0.5195, 0.8327]
计算 Y3 的关联系数 γ03(k):
k=1:
0.0906 / (0.1304 + 0.0785) = 0.0906 / 0.2089 ≈ 0.4337k=2:
0.0906 / (0.0701 + 0.0785) = 0.0906 / 0.1486 ≈ 0.6097k=3:
0.0906 / (0.1570 + 0.0785) = 0.0906 / 0.2355 ≈ 0.3847k=4:
0.0906 / (0.0435 + 0.0785) = 0.0906 / 0.1220 ≈ 0.7426∴
γ03 = [0.4337, 0.6097, 0.3847, 0.7426]
第4步:计算关联度
关联系数很多,信息过于分散,不方便比较。因此需要将每个比较序列在各个指标上的关联系数集中为一个值,即关联度。通常采用求平均值的方法。
公式: $r_{0i} = \frac{1}{m} \sum_{k=1}^{m} \gamma_{0i}(k)$
计算过程:
$r_{01} = (0.9742 + 1.0000 + 0.5101 + 0.6000) / 4 = 3.0843 / 4 = 0.7711$
$r_{02} = (0.3939 + 0.5511 + 0.5195 + 0.8327) / 4 = 2.2972 / 4 = 0.5743$
$r_{03} = (0.4337 + 0.6097 + 0.3847 + 0.7426) / 4 = 2.1707 / 4 = 0.5427$
第5步:依关联度排序,得出结论
将关联度按大小排序:
r01 = 0.7711(Student A)r02 = 0.5743(Student B)r03 = 0.5427(Student C)
结论:Student A 与“理想学生”的关联度最高,因此在这三个学生中,Student A 的综合素质是最好的。
第四部分:深入理解与注意事项
分辨系数 ρ 的影响:
ρ 越小,关联系数间的差异越大,区分能力越强。
ρ 越大,关联系数间的差异越小,稳定性越强。
通常取 0.5,但可以根据实际数据情况在 0.1 到 0.8 之间调整,进行敏感性分析。
无量纲化方法的选择:
初值化:用第一个数据去除所有数据。适用于关注增长趋势的动态分析。
均值化:用平均值去除所有数据。适用于静态的、多指标的综合评价(如本例)。最常用。
选择不同的方法,结果可能会略有差异,但排序通常保持一致。
权重的考虑:
本例中默认所有指标是等权重的。如果觉得“成绩”比“体育”更重要,可以在第4步求关联度时使用加权平均而不是简单平均。
公式变为: $r_{0i} = \sum_{k=1}^{m} [W(k) \cdot \gamma_{0i}(k)]$,其中 $\sum W(k) = 1$。
权重的确定本身也是一个课题,可以用AHP层次分析法、熵权法等。
优点:
计算简单,通俗易懂。
对数据要求低,适用性强。
结果清晰,易于比较。
缺点:
主观性较强。参考序列的设定、分辨系数的选择、无量纲化方法、指标权重的分配都带有人为因素,会影响最终结果。
是一种“相对评价”,结果只说明在待选序列中的排序,其绝对数值大小意义不大。
建立原始指标矩阵的口诀
核心四句口诀
横看对象竖看标,
同行数据可比好。
参考序列心中立,
无量纲化不能少。
口诀详解与操作步骤
1. 横看对象竖看标
含义:这是构建矩阵的基本框架。
操作:
“横看对象”:矩阵的每一行代表一个你要评价的对象(方案、产品、年份、学生等)。
“竖看标”:矩阵的每一列代表一个评价指标(维度、特征、因素等)。
示例:
对象 \ 指标 指标1 (如:GDP) 指标2 (如:人均收入) 指标3 (如:绿化率) 对象A X₁₁ X₁₂ X₁₃ 对象B X₂₁ X₂₂ X₂₃ 对象C X₃₁ X₃₃ X₃₃
2. 同行数据可比好
含义:这是确保分析科学性的核心前提。
操作:
“同行”:指同一个评价对象。
“可比”:确保所有对象的同一列指标(即同一个指标)的数据:
方向一致:必须统一是效益型(越大越好,如利润)或成本型(越小越好,如污染指数)。如果方向不一致,必须进行数据预处理(通常对成本型指标取倒数或做负向变换)。
量纲一致:虽然灰色关联后续会做无量纲化处理,但原始数据如果数量级差异巨大(如一个指标是0.01~0.1,另一个是10000~100000),可能会影响计算稳定性。如果差异过大,可先进行初步的标准化(如除以一个基数)再构建矩阵。
切记:如果指标方向不统一,计算结果将完全错误!
3. 参考序列心中立
含义:在构建矩阵时,就要想好评价的“标杆”是什么。
操作:
参考序列(X₀)可以单独作为一行加入矩阵的第一行,并明确标注。
参考序列的确定方法:
理想值法:每个指标都取所有对象在该指标上的最优值。如果是效益型指标取最大值,成本型指标取最小值。这是最常用、最科学的方法。
目标值法:如果你有明确的目标或计划值,可以直接用它构成参考序列。
示例(接上表,假设所有指标都是效益型):
对象 \ 指标 指标1 指标2 指标3 参考序列 X₀ Max(X₁₁, X₂₁, X₃₁) Max(X₁₂, X₂₂, X₃₂) Max(X₁₃, X₂₃, X₃₃) 对象A (X₁) X₁₁ X₁₂ X₁₃ 对象B (X₂) X₂₁ X₂₂ X₂₃ 对象C (X₃) X₃₁ X₃₂ X₃₃
4. 无量纲化不能少
含义:这是提醒你,原始矩阵建好后并不能直接用于计算关联系数,必须进行无量纲化处理,这是灰色关联分析计算流程中紧接着的关键一步。
操作:将原始矩阵中的每一个数据,通过均值化或初值化等方法,消除量纲,得到一个新矩阵(通常记为Y矩阵),后续所有计算都基于这个新矩阵。
均值化:
新数据 = 原始数据 / 该列数据的平均值(适用于静态综合评价)初值化:
新数据 = 原始数据 / 该列第一个数据(适用于动态趋势分析)
总结与记忆技巧
“横对象,竖指标,建矩阵。”
“效益成本要统一,方向千万别搞逆。”
“参考序列打头阵,最优数值来站立。”
“最后记得消量纲,计算关联才有戏。”
无量纲化处理:
一、核心概念:什么是“量纲”?
量纲(Dimension):也叫单位,是物理量的属性。比如:长度(米、公里)、重量(千克、吨)、时间(秒、小时)、金额(元、万元)等。
数值(Magnitude):是物理量的大小。比如:1.75(米)、70(千克)、5000(元)。
原始数据 = 数值 + 量纲
问题所在:当一个评价体系中包含多个不同量纲的指标时(例如,评价一个人:身高“1.75米”、体重“70千克”、月收入“5000元”),这些数据直接放在一起运算是没有意义的,就像“1.75 + 70 + 5000”一样荒谬。数值的大小会受到量纲的绝对影响。
二、什么是无量纲化处理?
无量纲化(Dimensionless Treatment),也叫作数据的标准化/规范化。
定义:通过一个数学变换,消除原始指标数据的单位(量纲)限制,将其转化为纯的、无单位的数值的过程。
目的:使不同量纲、不同数量级的指标能够放在同一个标准尺度下进行公平的比较和加权运算。
好比:将美元、人民币、黄金都换算成同一种“标准货币”后再比较谁的购买力强。
三、为什么必须进行无量纲化?(为什么“不能少”?)
解决不可公度性:这是最根本的原因。消除了量纲,身高、体重、收入这些原本风马牛不相及的数据才能进行数学运算。
解决数量级差异带来的支配问题:
如果一个指标的数值非常大(如“公司营收”,单位是亿元,数值在100-1000之间),而另一个指标的数值非常小(如“利润率”,单位是%,数值在5-10之间)。
如果不处理,数值大的指标在计算中会“淹没”或“支配”数值小的指标,导致评价结果严重失真,小指标几乎不起作用。无量纲化可以将所有指标 scale 到相近的数值范围内。
四、常用的无量纲化方法(附公式与示例)
假设有n个对象,m个指标,原始数据为 $x_{ij}$ (i=1,2,...,n; j=1,2,...,m)。
1. 均值化法(最常用于灰色关联分析)
思想:用原始值除以该指标所有数据的平均值,将数据转换为围绕1波动的数值。
公式: $y_{ij} = \frac{x_{ij}}{\frac{1}{n}\sum_{i=1}^{n} x_{ij}} = \frac{x_{ij}}{\bar{x}_j}$
其中 $\bar{x}_j$ 是第 j 个指标的平均值。
优点:
能保留原始数据各指标变异程度(差异性)的信息。
转化后的数据与原始数据的对应关系清晰。
示例:
某指标数据为 [200, 300, 400, 500],平均值 = 350。
无量纲化后: [200/350≈0.57, 300/350≈0.86, 400/350≈1.14, 500/350≈1.43]
2. 初值化法(也常用于灰色关联分析,尤其看趋势)
思想:用原始值除以该指标的第一个数据(或某一个特定数据)。
公式: $y_{ij} = \frac{x_{ij}}{x_{1j}}$ (通常用第一个数据做除数)
优点:
特别适合动态序列的分析,所有数据都与初始值相比,可以清楚地看到发展速度和趋势。
示例:
某指标数据为 [200, 300, 400, 500]。
无量纲化后(以第一个数据200为初值): [200/200=1, 300/200=1.5, 400/200=2, 500/200=2.5]
3. Z-Score 标准化(最通用的方法之一)
思想:将数据转换为均值为0、标准差为1的正态分布。
公式: $y_{ij} = \frac{x_{ij} - \bar{x}_j}{S_j}$
其中 $\bar{x}_j$ 是第 j 个指标的平均值。
$S_j$ 是第 j 个指标的标准差。
优点:
处理后的数据严格地服从标准正态分布。
应用极其广泛,多见于各种统计模型和机器学习算法中。
缺点:
当原始数据最大值和最小值未知,或数据超出当前范围时,可能不适用。
示例:
某指标数据为 [1, 2, 3, 4, 5],平均值=3,标准差≈1.58。
无量纲化后: [(1-3)/1.58≈-1.26, (2-3)/1.58≈-0.63, (3-3)/1.58=0, (4-3)/1.58≈0.63, (5-3)/1.58≈1.26]
4. Min-Max 归一化(区间缩放法)
思想:将原始数据线性地映射到一个指定的区间内,通常是[0, 1]。
公式: $y_{ij} = \frac{x_{ij} - \min(x_j)}{\max(x_j) - \min(x_j)}$
优点:
计算简单,结果范围固定,绝对是[0, 1]。
缺点:
抗干扰能力弱,容易受到异常值(极大值、极小值)的影响。
如果未来有新数据超出当前最大最小值范围,需要重新计算。
示例:
某指标数据为 [10, 20, 30, 40]。Min=10, Max=40。
无量纲化后: [(10-10)/30=0, (20-10)/30≈0.33, (30-10)/30≈0.67, (40-10)/30=1]
五、总结与选择建议
| 方法 | 公式 | 优点 | 适用场景 |
|---|---|---|---|
| 均值化 | $y_{ij} = x_{ij} / \bar{x}_j$ | 保留变异信息,意义明确 | 灰色关联分析,多指标静态评价 |
| 初值化 | $y_{ij} = x_{ij} / x_{1j}$ | 反映相对变化趋势 | 灰色关联分析(动态序列),趋势分析 |
| Z-Score | $y_{ij} = (x_{ij} - \bar{x}_j) / S_j$ | 服从标准正态分布,通用性强 | 机器学习,统计分析,需要假设数据服从正态分布的模型 |
| Min-Max | $y_{ij} = \frac{x_{ij} - \min}{\max - \min}$ | 计算简单,结果在[0,1]间 | 图像处理,需要固定范围的数据,且无异常值 |
对于灰色关联分析,首选【均值化法】,其次是【初值化法】。因为它们计算简单,且能很好地满足灰色关联“比较几何形状相似度”的核心思想。
层面一:核心计算公式(关联系数公式)
这是灰色关联分析最核心、最关键的数学表达式,用于计算在每一个指标点上,比较序列与参考序列的关联程度。
关联系数公式:
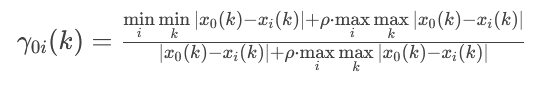
式中符号解释:
$\gamma_{0i}(k)$: 第 $i$ 个比较序列与参考序列在第 $k$ 个指标点上的关联系数。
它的值在 0 和 1 之间。值越大,表示在该点上两序列的关联性越强。
$x_0(k)$: 参考序列在第 $k$ 个指标点的值(已进行无量纲化处理)。
$x_i(k)$: 第 $i$ 个比较序列在第 $k$ 个指标点的值(已进行无量纲化处理)。
$|x_0(k) - x_i(k)|$: 两序列在第 $k$ 个指标点的绝对差。
$\min\limits_{i} \min\limits_{k} |x_0(k) - x_i(k)|$: 所有比较序列在所有指标点上的两级最小差。
先找出每个序列自身的最小差,再从这些最小值中找出最小的一个。
$\max\limits_{i} \max\limits_{k} |x_0(k) - x_i(k)|$: 所有比较序列在所有指标点上的两级最大差。
先找出每个序列自身的最大差,再从这些最大值中找出最大的一个。
$\rho$: 分辨系数,是一个介于 0 到 1 之间的常数,通常取 0.5。它的作用是调节关联系数之间的差异大小,$\rho$ 越小,区分能力越强。
层面二:整体建模的逻辑框架(步骤表达式)
灰色关联分析不是一个单一的方程,而是一个多步骤的算法流程。我们可以用一个清晰的步骤框架来表达它。
灰色关联分析模型 = 以下步骤的序列执行:
确定序列
确定参考序列 $X_0 = (x_0(1), x_0(2), ..., x_0(n))$
确定比较序列 $X_i = (x_i(1), x_i(2), ..., x_i(n)), \quad i=1,2,...,m$
无量纲化处理 (通常采用均值化法)
$Y_i(k) = \frac{X_i(k)}{\frac{1}{n}\sum_{k=1}^{n} X_i(k)} = \frac{X_i(k)}{\bar{X_i}}$
逐点计算关联系数 (应用核心公式)
对每一个 $i$ (每一个比较序列),对每一个 $k$ (每一个指标点),计算:
$\gamma_{0i}(k) = \frac{\Delta_{min} + \rho \Delta_{max}}{\Delta_{0i}(k) + \rho \Delta_{max}}$其中 $\Delta_{0i}(k) = |Y_0(k) - Y_i(k)|$
$\Delta_{min} = \min\limits_{i} \min\limits_{k} \Delta_{0i}(k)$
$\Delta_{max} = \max\limits_{i} \max\limits_{k} \Delta_{0i}(k)$
计算关联度 (综合关联系数)
将每个比较序列在各点的关联系数求平均值,得到一个综合的关联度值 $r_{0i}$。
$r_{0i} = \frac{1}{n} \sum_{k=1}^{n} \gamma_{0i}(k)$
注:如果各指标重要性不同,可在此步采用加权平均:$r_{0i} = \sum_{k=1}^{n} [w_k \cdot \gamma_{0i}(k)]$, 其中 $\sum_{k=1}^{n} w_k = 1$。
关联度排序
根据关联度 $r_{0i}$ 的大小进行排序,形成关联序。$r_{0i}$ 越大,说明该比较序列与参考序列的关联程度越高,越好或越接近。
它的核心是关联系数公式,但其本身是一个多步骤的算法流程,没有单一的万能表达式。
模糊综合评价法
基本思想:模糊综合评价法以模糊数学为基础,应用模糊关系合成的原理,将一些边界不清、不易定量的因素定量化,从多个因素对被评价事物隶属等级状况进行综合性评价。
优点:数学模型简单,容易掌握,对多因素、多层次的复杂问题评判效果较好。模糊评价模型不仅可对评价对象按综合分值的大小进行评价和排序,而且还可根据模糊评价集上的值按最大隶属度原则去评定对象所属的等级,结果包含的信息量丰富。
缺点:并不能解决评价指标间相关造成的评价信息重复问题,隶属函数的确定还没有系统的方法,而且合成的算法也有待进一步探讨。其评价过程大量运用了人的主观判断,由于各因素权重的确定带有一定的主观性,因此,模糊综合评判是一种基于主观信息的综合评价方法。
应用场景:适用于对社会经济系统问题进行评价,如产品质量评估、项目风险评估等。
建模步骤:
- 确定因素集、评语集。
- 构造模糊关系矩阵。
- 确定指标权重。
- 进行模糊合成和做出评价。
一、什么是模糊综合评价法?
模糊综合评价法是一种基于模糊数学(Fuzzy Mathematics)的综合评价方法。它的核心思想是:用精确的数学语言来描述和处理现实世界中大量存在的“模糊”概念(例如“服务质量好”、“环境优美”、“风险高”等),并通过一套系统的步骤,将多个影响因素的综合评价由一个“模糊”的定性结果转化为一个清晰的定量结果。
简单来说,它解决了传统评价方法中“非此即彼”的弊端,允许“亦此亦彼”的中间状态,从而使评价结果更符合人类的思维习惯和客观现实。
二、为什么需要它?(适用场景)
当你遇到以下情况时,模糊综合评价法就非常有用:
评价指标难以量化:比如评价一个餐厅的“氛围”,评价一位员工的“工作态度”。
评价结果受多种因素影响:需要综合考虑多个指标,而不是只看单一指标。
评价标准本身是模糊的:比如“优秀”、“良好”、“一般”、“较差”这些等级之间没有绝对的界限。
需要处理主观判断:专家的意见、用户的感受往往是模糊的,该方法能有效聚合这些主观信息。
典型应用领域:
教学质量评估(学生评价老师)
员工绩效考评
供应商选择
投资项目风险评价
环境影响评价
消费者满意度调查
医疗诊断辅助
三、核心步骤(通过一个例子详解)
我们用一个简单的例子来贯穿整个流程:评价一家餐厅的综合体验。
第1步:确定评价因素集(U)
首先要明确从哪些方面(指标)来进行评价。这些因素构成了一个集合。
例子:我们选择四个关键因素:
u1:菜品口味u2:服务质量u3:环境氛围u4:价格水平所以,因素集 U = {菜品口味, 服务质量, 环境氛围, 价格水平}
第2步:确定评价等级集(V)
即设定可能的评价结果等级,也称为评语集。
例子:我们设定五个等级:
v1:非常好v2:好v3:一般v4:差v5:非常差所以,等级集 V = {非常好, 好, 一般, 差, 非常差}
第3步:确定权重集(A)
不同的评价因素其重要性是不同的。我们需要为每个因素分配一个权重,权重之和一般为1。确定权重的方法有很多,如层次分析法(AHP)、专家打分法、熵权法等。
例子:经过专家讨论或顾客调查,我们认为:
菜品口味最重要,权重 0.4
服务质量次之,权重 0.3
环境氛围,权重 0.2
价格水平,权重 0.1
所以,权重集 A = (0.4, 0.3, 0.2, 0.1)
第4步:构建模糊关系矩阵(R)
这是最核心的一步。我们需要对每个评价因素 ui,进行单因素评价,得到一个关于评价等级 V 的模糊隶属度向量 Ri。
如何得到这个矩阵?—— 通常通过问卷调查。
例如,我们向100位顾客发放问卷。
对“菜品口味(u1)”的评价结果:
50人认为“非常好”
30人认为“好”
15人认为“一般”
5人认为“差”
0人认为“非常差”
那么,它的隶属度向量 R1 = (50/100, 30/100, 15/100, 5/100, 0/100) = (0.5, 0.3, 0.15, 0.05, 0)
同理,假设我们得到其他因素的评价结果:
R2(服务质量) = (0.6, 0.2, 0.1, 0.1, 0)
R3(环境氛围) = (0.4, 0.3, 0.2, 0.1, 0)
R4(价格水平) = (0.1, 0.2, 0.3, 0.3, 0.1)
将这些行向量组合起来,就得到了模糊关系矩阵 R:
| 非常好(v1) | 好(v2) | 一般(v3) | 差(v4) | 非常差(v5) | |
|---|---|---|---|---|---|
| u1 | 0.5 | 0.3 | 0.15 | 0.05 | 0 |
| u2 | 0.6 | 0.2 | 0.1 | 0.1 | 0 |
| u3 | 0.4 | 0.3 | 0.2 | 0.1 | 0 |
| u4 | 0.1 | 0.2 | 0.3 | 0.3 | 0.1 |
第5步:进行模糊合成(计算综合评价结果B)
将权重向量 A 和模糊关系矩阵 R 进行合成运算,得到一个综合的评价向量 B。这个向量表示该餐厅的整体体验隶属于各个评价等级的程度。
最常用的合成算子是 M(∧, ∨),即“取小取大”算子,但有时会丢失信息。更常用和合理的算子是普通矩阵乘法或 M(•, ⊕)(即乘与有界和)。
我们使用更通用的加权平均型合成(普通矩阵乘法):
B = A ◦ R
其中◦表示矩阵乘法。计算过程:
B = (0.4, 0.3, 0.2, 0.1) ◦
[ 0.5 0.3 0.15 0.05 0 ]
[ 0.6 0.2 0.1 0.1 0 ]
[ 0.4 0.3 0.2 0.1 0 ]
[ 0.1 0.2 0.3 0.3 0.1 ]对于第一个元素(隶属于“非常好”的程度):
b1 = (0.4 * 0.5) + (0.3 * 0.6) + (0.2 * 0.4) + (0.1 * 0.1) = 0.20 + 0.18 + 0.08 + 0.01 = 0.47同理计算:
b2 = (0.4*0.3) + (0.3*0.2) + (0.2*0.3) + (0.1*0.2) = 0.12 + 0.06 + 0.06 + 0.02 = 0.26b3 = (0.4*0.15) + (0.3*0.1) + (0.2*0.2) + (0.1*0.3) = 0.06 + 0.03 + 0.04 + 0.03 = 0.16b4 = (0.4*0.05) + (0.3*0.1) + (0.2*0.1) + (0.1*0.3) = 0.02 + 0.03 + 0.02 + 0.03 = 0.10b5 = (0.4*0) + (0.3*0) + (0.2*0) + (0.1*0.1) = 0 + 0 + 0 + 0.01 = 0.01
所以,综合评价结果向量 B = (0.47, 0.26, 0.16, 0.10, 0.01)
第6步:对评价结果向量进行分析处理
得到向量 B 后,有三种方式来处理结果:
最大隶属度原则:直接看 B 中哪个数值最大。这里 0.47 最大,对应的等级是“非常好”。所以我们可以得出结论:该餐厅的综合体验为“非常好”。
优点:简单直观。
缺点:有时会丢失信息,比如当两个值非常接近时(如0.45和0.44),可能会误判。
加权平均法:给每个评价等级赋予一个分值(比如“非常好”=5分,“好”=4分,“一般”=3分,“差”=2分,“非常差”=1分),然后计算综合得分。
综合得分 = (0.47*5 + 0.26*4 + 0.16*3 + 0.10*2 + 0.01*1) / (0.47+0.26+0.16+0.10+0.01) = (2.35+1.04+0.48+0.20+0.01) / 1.0 = 4.08
满分是5分,得到4.08分,这是一个量化的结果,可以进行更精确的排序和比较。
模糊向量单值化:类似加权平均,但更通用。
在实际应用中,最大隶属度原则和加权平均法最为常用。
四、优缺点总结
| 优点 | 缺点 |
|---|---|
| 1. 结果清晰,系统性强:能将复杂的模糊问题转化为定量分析。 | 1. 主观性较强:权重设置和单因素评价矩阵的构建都依赖人的主观判断。 |
| 2. 包容模糊信息:很好地解决了定性指标难以量化的问题。 | 2. 计算可能复杂:当指标非常多时,计算量会增大,需要借助软件(如Excel, MATLAB, Python)。 |
| 3. 适用性广:可用于任何带有多指标、模糊性的综合评价场景。 | 3. 合成算子的选择有讲究:选择不同的算子(如取大取小或加权平均)可能会得到不同的结果,需要根据问题特性选择。 |
五、如何提高其科学性和可靠性?
科学确定权重:不要拍脑袋决定权重,尽量使用AHP、熵权法等科学方法。
保证数据来源可靠:问卷调查的样本量要足够,受访者要具有代表性。
合理选择合成算子:理解不同算子的特点,选择最适合当前问题模型的一个。
进行灵敏度分析:微调权重,看结果是否发生剧烈变化,以检验模型的稳定性。
因素集(U)、评语集(V):
一、如何确定评价因素集(U)
因素集就是你要评价的对象的所有评价指标(Criteria)的集合。确定因素集的过程,本质上是一个构建评价指标体系的过程。
核心原则:
因素集应该全面、系统地反映评价对象的各个方面,但同时要避免指标过多过杂,导致重点不突出。
具体方法与步骤:
1. 文献研究法 (Literature Review)
做法:查阅与你的评价对象相关的学术论文、行业报告、标准文件等。已有的研究通常已经建立了一套相对成熟的指标体系,你可以直接借鉴或在其基础上进行修改。
例子:你要评价“智慧城市的发展水平”。通过查阅大量文献,你会发现学者们普遍从“智慧基础设施”、“智慧治理”、“智慧经济”、“智慧民生”、“智慧环境”等几个维度来构建因素集。
2. 头脑风暴法 (Brainstorming) & 专家访谈法 (Expert Interview)
做法:召集相关领域的专家、资深从业者或有经验的用户,通过开放式的讨论,集思广益,列出所有可能的影响因素。
优点:可以发掘出一些潜在的、未被文献收录但实际非常重要的“隐性”指标。
例子:评价一个“APP的用户体验”。除了常见的“易用性”、“美观度”、“性能”,专家可能会提出“情感化设计”、“隐私安全感”等更深层的因素。
3. 业务流程分析法 (Business Process Analysis)
做法:如果评价对象是一个流程或服务,可以将其全过程分解为多个环节,每个环节都可以作为一个评价因素。
例子:评价“快递服务质量”。流程可以分解为:下单便捷性、支付灵活性、打包质量、配送速度、配送员态度、售后处理等,每个环节都是一个因素。
4. 理论模型法 (Theoretical Model)
做法:基于一个成熟的理论模型来构建指标体系。这是最科学、最令人信服的方法。
例子:
评价企业绩效:可以基于平衡计分卡(BSC)模型,从“财务”、“客户”、“内部流程”、“学习与成长”四个维度确定因素。
评价用户体验:可以借鉴Peter Morville的蜂巢模型,从“有用性”、“可用性”、“合意性”、“可寻性”、“可达性”、“可靠性”、“价值性”等方面确定因素。
5. 层层分解,建立层次结构
对于一个复杂的对象,因素集往往不是一层,而是多层的。
做法:先确定几个一级指标(准则层),然后将每个一级指标分解为若干个更具体的二级指标(指标层)。如果需要,还可以继续分解。
例子:评价“大学生综合素质”
一级指标U:{思想道德素质U1, 科学文化素质U2, 身心健康素质U3, 能力发展素质U4}
二级指标:将U1(思想道德素质)分解为:{政治表现U11, 道德修养U12, 法制观念U13, 集体观念U14}
最终输出:一个结构清晰、层次分明的指标集合。例如:
U = {u1, u2, u3, ..., un} 或 带有层级关系的 U = {U1: [u11, u12, ...], U2: [u21, u22, ...], ...}
二、如何确定评价评语集(V)
评语集是所有可能评价结果的等级集合。它是对评价结果的定性描述。
核心原则:
评语等级要覆盖所有可能的情况,等级数量要适中(通常为奇数,如3、5、7级),且等级之间应含义明确、相互独立、便于区分。
具体方法与步骤:
1. 直接定义法
做法:根据研究问题和常识,直接定义一组符合语言习惯的评语等级。这是最常用的方法。
常见的等级设置:
三级:{好, 中, 差}, {高, 中, 低}, {满意, 一般, 不满意}
五级(最常用):
{非常满意, 比较满意, 一般, 不太满意, 非常不满意}
{优秀, 良好, 中等, 及格, 不及格}
{完全同意, 同意, 中立, 不同意, 完全不同意}
七级:{极好, 很好, 好, 一般, 差, 很差, 极差} (用于需要更精细区分的场合)
2. 李克特量表法 (Likert Scale)
做法:这实际上是直接定义法的一种标准化形式。通常采用5级或7级量表,每个等级对应一个分数(如5分制或7分制)。
例子:在问卷中,让受访者对某个陈述发表同意程度:
非常不同意
不同意
一般
同意
非常同意
这五个选项就构成了一个评语集。
3. 注意事项
保持中立:等级数量最好为奇数,这样可以提供一个中间的“中立”或“一般”选项,避免强迫用户选择。
覆盖全面:评语集要能涵盖从极端正面到极端负面的所有可能性。
语义清晰:每个等级的表述要清晰,避免产生歧义。确保不同的评价者对“好”和“较好”的理解是一致的。
与因素匹配:评语集对所有评价因素都应是适用的。例如,你用{非常好, 好, 一般, 差} 来评价“菜品口味”是合适的,但用来评价“价格水平”时,可能需要调整为{非常便宜, 便宜, 合理, 贵, 非常贵},其本质仍然对应着五级评语集。
最终输出:一个含义明确的等级集合。例如:
V = {v1, v2, v3, v4, v5} = {非常好, 好, 一般, 差, 非常差}
总结与关系
| 步骤 | 核心任务 | 常用方法 | 输出结果 |
|---|---|---|---|
| 确定因素集 (U) | 解决“从哪些方面评” | 文献研究、头脑风暴、理论模型、业务流程分析 | 一个多层次、无遗漏的指标体系 |
| 确定评语集 (V) | 解决“评出什么结果” | 直接定义、李克特量表 | 一组奇数个、含义清晰的等级选项 |
两者关系:因素集(U)决定了评价的宽度和深度,而评语集(V)决定了评价结果的分辨率和精度。一个好的模糊综合评价,始于一个科学合理的因素集和评语集。
TOPSIS法(逼近理想解排序法)
基本思想:TOPSIS法通过计算每个方案与理想解和负理想解的距离,来确定各方案的相对优劣。理想解是设想中最好的方案,负理想解是设想中最差的方案。
优点:能够较好地处理多属性决策问题,特别适用于需要考虑多个评价指标的情况。
缺点:需要确保数据的同趋势化和归一化处理,以避免量纲和趋势不同对评价结果的影响。
应用场景:适用于多属性决策分析,如供应商选择、投资方案评估等。
建模步骤:
- 准备好数据,并进行同趋势化处理。
- 数据归一化处理解决量纲问题。
- 找出最优和最劣矩阵向量。
- 分别计算评价对象与正理想解距离D+或负理想解距离D-。
- 结合距离值计算得出接近程序C值,并进行排序得出结论。
TOPSIS法(Technique for Order Preference by Similarity to Ideal Solution),即逼近理想解排序法。
这是一种非常经典且实用的多属性决策(MADM) 或多准则决策(MCDM) 方法。它的核心思想非常直观且符合人类思维习惯。
一、核心思想
TOPSIS法的基本理念是:最佳方案应该尽可能地靠近“正理想解”(想象中最完美的方案),同时又尽可能地远离“负理想解”(想象中最差的方案)。
正理想解 (Positive Ideal Solution): 是一个虚拟的方案,它由所有评估指标(属性)中的最优值构成。例如,在评价汽车时,正理想解可能就是“最便宜的价格、最高的马力、最豪华的内饰、最低的油耗”(成本型指标取最小值,效益型指标取最大值)。
负理想解 (Negative Ideal Solution): 是另一个虚拟的方案,它由所有评估指标中的最劣值构成。同样评价汽车,负理想解就是“最贵的价格、最低的马力、最简陋的内饰、最高的油耗”。
TOPSIS通过计算每个实际方案与这两个“理想中”的方案的相对距离来进行排序。与正理想解越近、同时与负理想解越远的方案,就是越好的方案。
二、适用场景
TOPSIS法广泛应用于各个领域,只要是需要从多个选项中根据多个标准做出选择的问题,都可以考虑使用它。
供应商选择(根据价格、质量、交货期、服务等指标)
投资项目评估(根据投资回报率、风险、周期等指标)
人才选拔(根据学历、工作经验、技能、面试得分等指标)
项目选址(根据成本、交通、市场、环境等指标)
产品评估(根据性能、价格、用户体验、口碑等指标)
三、计算步骤(附详细公式和示例)
我们通过一个简单的例子来一步步说明。假设要购买一台手机,有3个备选方案(A, B, C),我们根据4个指标来评估:
价格(元):成本型指标(越小越好)
续航(小时):效益型指标(越大越好)
摄像头(分):效益型指标(越大越好)
颜值(分):效益型指标(越大越好)
原始数据如下表所示:
| 方案 | 价格(元) | 续航(小时) | 摄像头(分) | 颜值(分) |
|---|---|---|---|---|
| 手机A | 3000 | 10 | 8 | 7 |
| 手机B | 5000 | 12 | 9 | 8 |
| 手机C | 4000 | 8 | 7 | 9 |
第一步:构建初始决策矩阵
将数据整理成矩阵形式,每一行是一个方案,每一列是一个指标。

第二步:将决策矩阵标准化(归一化)
由于不同指标的量纲(单位)不同(元、小时、分),数值大小差异很大,无法直接比较。因此需要消除量纲的影响,转化为无量纲的数值。
常用的方法是向量归一法,公式为:
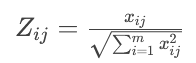
xij
其中,$x_{ij}$ 是原始值,$Z_{ij}$ 是标准化后的值,$m$ 是方案的数量(本例中m=3)。
我们以“价格”列为例进行计算:
$\sqrt{3000^2 + 5000^2 + 4000^2} = \sqrt{9,000,000 + 25,000,000 + 16,000,000} = \sqrt{50,000,000} \approx 7071.06$
手机A价格标准化:$3000 / 7071.06 \approx 0.424$
手机B价格标准化:$5000 / 7071.06 \approx 0.707$
手机C价格标准化:$4000 / 7071.06 \approx 0.566$
同理,计算其他列,得到标准化矩阵 $Z$:

第三步:确定加权标准化矩阵
如果每个指标的重要性不同,需要赋予权重。假设我们赋予四个指标的权重分别为:价格 0.4,续航 0.3,摄像头 0.2,颜值 0.1。(权重之和为1)
加权公式为:
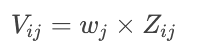
其中,$w_j$ 是第 j 个指标的权重。
计算后得到加权标准化矩阵 $V$:

第四步:确定正理想解和负理想解
从加权标准化矩阵 $V$ 的每一列中找出最大值和最小值。
正理想解 $V^+$:对于效益型指标取最大值,成本型指标取最小值。
价格(成本型)取最小值:
min(0.170, 0.283, 0.226) = 0.170续航(效益型)取最大值:
max(0.182, 0.219, 0.146) = 0.219摄像头(效益型)取最大值:
max(0.124, 0.139, 0.108) = 0.139颜值(效益型)取最大值:
max(0.057, 0.066, 0.074) = 0.074$\therefore V^+ = {0.170, 0.219, 0.139, 0.074}$
负理想解 $V^-$:与正理想解相反,效益型取最小值,成本型取最大值。
价格(成本型)取最大值:
max(0.170, 0.283, 0.226) = 0.283续航(效益型)取最小值:
min(0.182, 0.219, 0.146) = 0.146摄像头(效益型)取最小值:
min(0.124, 0.139, 0.108) = 0.108颜值(效益型)取最小值:
min(0.057, 0.066, 0.074) = 0.057$\therefore V^- = {0.283, 0.146, 0.108, 0.057}$
第五步:计算各方案到理想解的距离
使用欧几里得距离公式计算。
到正理想解的距离 $S_i^+$:
$S_i^+ = \sqrt{\sum_{j=1}^{n} (V_{ij} - V_j^+)^2}$到负理想解的距离 $S_i^-$:
$S_i^- = \sqrt{\sum_{j=1}^{n} (V_{ij} - V_j^-)^2}$
我们计算手机A的距离:
$S_A^+ = \sqrt{(0.170-0.170)^2 + (0.182-0.219)^2 + (0.124-0.139)^2 + (0.057-0.074)^2} = \sqrt{0 + 0.001369 + 0.000225 + 0.000289} = \sqrt{0.001883} \approx 0.0434$
$S_A^- = \sqrt{(0.170-0.283)^2 + (0.182-0.146)^2 + (0.124-0.108)^2 + (0.057-0.057)^2} = \sqrt{0.012769 + 0.001296 + 0.000256 + 0} = \sqrt{0.014321} \approx 0.1197$
同理,可以计算出所有方案的距离:
| 方案 | $S_i^+$ (到正理想解距离) | $S_i^-$ (到负理想解距离) |
|---|---|---|
| 手机A | 0.0434 | 0.1197 |
| 手机B | 0.1134 | 0.0539 |
| 手机C | 0.0786 | 0.0731 |
第六步:计算相对贴近度并排序
相对贴近度 $C_i$ 的计算公式为: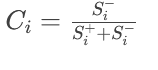
$C_i$ 的值在 0 到 1 之间。
$C_i$ 越接近 1,说明该方案越接近正理想解,同时越远离负理想解,方案越好。
$C_i$ 越接近 0,说明该方案越接近负理想解,同时越远离正理想解,方案越差。
计算各方案的 $C_i$:
手机A: $C_A = 0.1197 / (0.0434 + 0.1197) \approx 0.734$
手机B: $C_B = 0.0539 / (0.1134 + 0.0539) \approx 0.322$
手机C: $C_C = 0.0731 / (0.0786 + 0.0731) \approx 0.482$
第七步:排序
根据 $C_i$ 值从大到小进行排序:
手机A ($C_i = 0.734$)
手机C ($C_i = 0.482$)
手机B ($C_i = 0.322$)
因此,最优选择是手机A。
四、优缺点
优点:
直观易懂:逻辑清晰,符合常人思维。
计算过程规范:步骤明确,易于编程实现。
信息利用充分:考虑了原始数据的所有信息。
灵活性好:可以容纳不同量纲的指标,并通过权重体现重要性。
缺点:
权重主观性:权重的确定往往依赖专家打分或AHP等方法,存在主观性。
“逆序”问题:增加或减少方案可能会改变原有方案的排序结果(虽然TOPSIS对此相对不敏感,但仍可能存在)。
对数据分布敏感:归一化方式的选择(如极差归一化、向量归一化等)可能会影响结果。
五、总结
TOPSIS法是一种强大且实用的多准则决策工具。它通过定义一个“理想中”的最佳和最差方案,将复杂的多指标比较问题,转化为计算每个实际方案与这两个理想方案相对距离的简单几何问题。尽管在权重设定上可能存在主观性,但其清晰的逻辑和强大的功能使其成为管理科学、工程技术、经济学等领域不可或缺的决策分析方法。
数据包络分析(DEA)
基本思想:DEA是一种多指标投入和产出评价的研究方法,它应用数学规划模型计算比较决策单元(DMU)之间的相对效率,对评价对象做出评价。
优点:能够处理多投入和多产出的复杂系统评价问题,无需考虑投入和产出的量纲统一问题。
缺点:只能评价决策单元的相对效率,而非绝对效率;当决策单元数量较少时,评价结果可能不够稳定。
应用场景:适用于多投入和多产出的复杂系统评价,如学校效率评估、医院绩效评估等。
建模步骤:
- 确定评价对象和投入产出指标。
- 收集数据并构建DEA模型。
- 计算各决策单元的效率值。
- 分析评价结果并提出改进建议。
数据包络分析(Data Envelopment Analysis, DEA)。
这是一个非常重要的管理科学和运筹学工具,用于评估具有多输入和多输出的决策单元(DMU)的相对效率。
一、核心思想:什么是DEA?
想象一下,你是一个管理者,需要评估手下10个销售部门的效率。每个部门都用“员工数量”、“广告预算”和“办公面积”(输入)来产生“销售额”和“客户满意度得分”(输出)。有的部门花了很多钱但销售额一般,有的部门人少但业绩突出。你怎么科学地、公平地比较它们?
DEA就是解决这个问题的利器。它的核心思想是:
相对效率,而非绝对效率:DEA不关心一个部门“理论上”最多能产出多少,而是关心在当前所有被评估的部门(决策单元DMU)中,这个部门的表现如何。效率最高的部门会被赋予100%的效率值(1.0),其他部门的效率值则是相对于这些“最佳实践者”而言的。
构建一个“效率前沿面”:DEA会通过数学规划的方法,找出所有DMU中表现最好的那些,并将它们连接起来,形成一个“包络面”(Frontier)。这个面包裹了所有其他的DMU。落在前沿面上的DMU是有效的(效率=1),落在这个面内部的DMU是低效的(效率<1)。
权重内生化:传统的效率评估需要人为设定各个输入和输出指标的权重(例如,你认为“员工数量”比“广告预算”重要一倍)。但DEA的巧妙之处在于,它为每个被评估的DMU自动选择最有利于其自身的权重,以计算出其可能达到的最高效率得分。这避免了主观偏见,保证了评估的公平性。
二、基本模型:CCR 和 BCC
DEA有两个最基础也是最经典的模型,以提出者的名字命名。
1. CCR模型 (Charnes, Cooper, Rhodes - 1978)
核心假设:规模报酬不变(Constant Returns to Scale, CRS)。即投入增加一倍,产出也正好增加一倍。这个假设适用于运营在最优规模下的DMU。
目标:衡量的是综合技术效率,它包含了纯技术效率和规模效率。
特点:CCR模型得出的效率值代表的是DMU在既定产出下,其投入可以按比例缩减的程度。例如,一个DMU的效率值为0.7,意味着它可以用现有70%的投入达到目前的产出水平。
2. BCC模型 (Banker, Charnes, Cooper - 1984)
核心假设:规模报酬可变(Variable Returns to Scale, VRS)。即投入的增加可能带来产出的递增、不变或递减回报。这个假设更贴近现实。
目标:从综合技术效率中分离出纯技术效率,剔除了规模因素的影响。它可以告诉我们DMU的管理水平本身是否高效。
重要衍生:通过比较CCR和BCC模型的效率值,可以计算出规模效率:
规模效率 = CCR效率值 / BCC效率值如果规模效率 = 1,说明该DMU处于最佳规模。
如果规模效率 < 1,说明该DMU规模不当(可能太大或太小)。
三、DEA的分析步骤(以一个简单案例说明)
假设我们要评估3所小学(A, B, C)的效率。
输入指标 (Inputs):
I1: 教师数量 (人)I2: 年度预算 (万元)
输出指标 (Outputs):
O1: 毕业生平均成绩 (分)O2: 学生综合素质评分 (分)
数据:
| 学校 | 教师 (I1) | 预算 (I2) | 平均成绩 (O1) | 综合素质 (O2) |
|---|---|---|---|---|
| A | 20 | 50 | 90 | 85 |
| B | 30 | 100 | 95 | 90 |
| C | 40 | 150 | 98 | 92 |
步骤 1:定义问题与选择DMU
DMU就是A, B, C三所学校。
步骤 2:确定输入与输出指标
如上所示。
步骤 3:选择DEA模型
这里我们选择投入导向的CCR模型(即关注在现有产出下,投入能减少多少)。
步骤 4:构建数学规划并求解(以评估学校A为例)
DEA会为每个DMU单独求解一个线性规划问题。对于学校A,模型会问:“在保证产出不降低的前提下,学校A的投入理论上最多能缩减到现在的百分之多少?”
求解过程(简化理解):
模型会尝试将学校A与所有学校的线性组合进行比较。它会发现,学校A用20个老师和50万预算,产出了90和85。学校B用30个老师和100万预算,产出了95和90。学校B的投入是A的1.5倍多,但产出并没有达到1.5倍。学校A用更少的资源,实现了相对不错的产出。经过计算,学校A的效率值很可能为1(或非常接近1),即它是有效的。
反之,学校C投入巨大,但产出相比投入的增长并不显著,其效率值很可能小于1。学校B可能处于中间。
步骤 5:解释结果
假设我们得到以下结果:
| 学校 | CCR效率值 | 结论 |
|---|---|---|
| A | 1.000 | DEA有效。是其他学校的标杆。 |
| B | 0.850 | DEA无效。其投入可以缩减到当前的85%而不减少产出。 |
| C | 0.750 | DEA无效。效率最低,资源浪费最严重。 |
步骤 6:提供改进建议(投影分析)
DEA不仅能给出效率值,还能指出如何改进。对于学校B(效率值0.85),模型会给出一个“目标值”:
目标投入 = 当前投入 × 效率值 = (30, 100) * 0.85 ≈ (25.5, 85)
这意味着,学校B应该以25.5名教师和85万元预算,努力达到它目前的产出水平(95, 90)。这些目标值就是它在“效率前沿面”上的投影点。
四、DEA的优点与局限性
优点:
无需预设函数关系:不需要知道输入和输出之间的精确生产函数。
擅长处理多输入多输出:这是DEA最强大的地方。
单位不变性:输入输出数据的量纲(如人、万元、分)不影响分析结果。
提供改进方向:不仅给出分数,还给出具体的改进目标。
局限性:
对极端值/误差敏感:一个异常高效的DMU会拉高整个前沿面,导致其他DMU效率值偏低;一个数据录入错误会严重影响结果。
是描述性而非预测性:它评价的是历史数据的相对表现,不能预测未来效率。
绝对效率的错觉:效率值为1只代表在样本组内相对有效,如果加入新的更高效的DMU,其效率值可能会下降。
指标选择至关重要:指标选择不当会导致荒谬的结论。指标间最好避免高度相关性。
五、常见应用领域
DEA的应用极其广泛,几乎涵盖所有需要评估效率的领域:
银行业:评估分支行的效率(输入:员工数、营运成本;输出:存款额、贷款额、利润)。
** healthcare**:评估医院、诊所的效率(输入:医生数、床位、设备;输出:治愈病人数、手术量、患者满意度)。
教育业:评估学校、院系的效率(输入:师资、经费、设施;输出:毕业生数量、就业率、科研成果)。
制造业:评估工厂、生产线的效率(输入:劳动力、资本、原材料;输出:产品数量、良品率)。
公共服务:评估政府部门、图书馆、消防队的效率。
供应链管理:评估供应商、第三方物流公司的绩效。
总结
数据包络分析(DEA) 是一个强大的、非参数的、数据驱动的效率评估工具。它通过构建一个“最佳实践”前沿面,为多输入多输出的同类决策单元提供相对效率评分和改进方案。尽管存在一些局限性,但在管理实践和学术研究中,它始终是绩效评估领域不可或缺的主流方法之一。要使用DEA,通常需要借助专门的软件,如DEAP, MaxDEA, EMS,或者R/Python中的相关工具包。
在数学建模竞赛中,评价类问题是绝对的主流题型,而选择合适的模型是成功的关键。下面我将对数学建模竞赛中常用的评价类模型进行一个系统的总结,包括它们的核心思想、适用场景、优缺点以及如何选择,并附上一个对比表格以供快速参考。