t-SNE详解与实践【附代码】
一、t-SNE 的算法流程可以简要概括为:
- 在高维空间中计算数据点之间的相似性 (条件概率)
- 在低维空间中随机初始化数据点
- 计算低维空间中数据点的相似性
- 优化目标函数 (最小化 KL 散度),更新低维空间中数据点的位置
- 重复步骤 3-4,直到收敛
二、代码示例
在 Python 中实现 t-SNE 非常方便,成熟的机器学习库有 Scikit-learn 和 OpenTSNE。
1、Scikit-learn 提供了 t-SNE 的标准实现:
from sklearn.manifold import TSNE
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt# 加载数据
iris = load_iris()
X = iris.data
y = iris.target# t-SNE 降维
tsne = TSNE(n_components=2, random_state=42)
X_tsne = tsne.fit_transform(X)# 可视化
plt.figure(figsize=(8, 8))
colors = ['red', 'green', 'blue']
for i in range(len(colors)):plt.scatter(X_tsne[y == i, 0], X_tsne[y == i, 1], c=colors[i], label=iris.target_names[i])
plt.legend()
plt.show()
结果图:
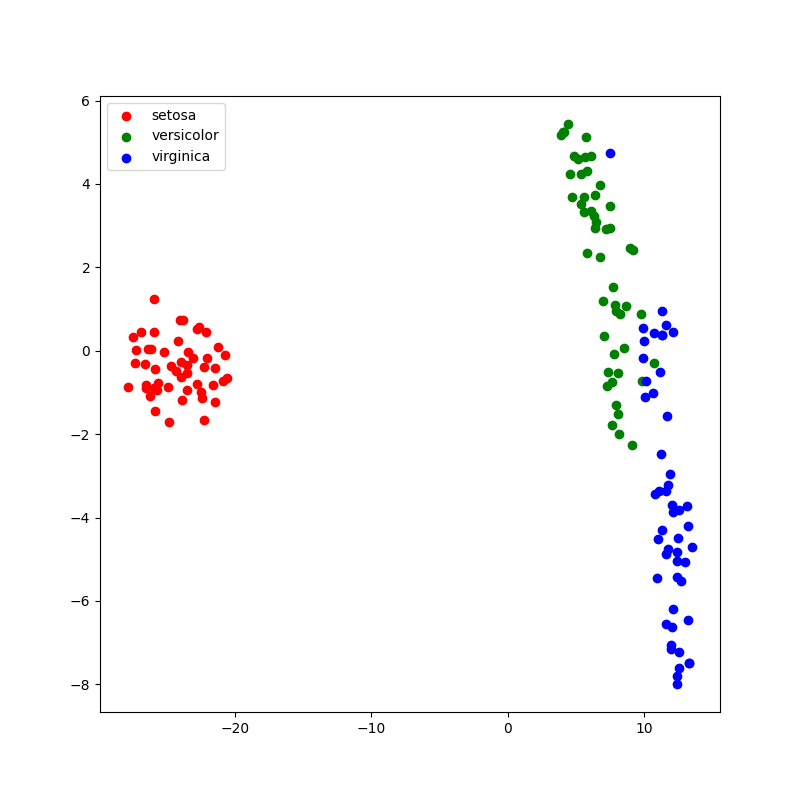
2、OpenTSNE 对 t-SNE 算法做了诸多优化,如 Barnes-Hut 近似方法,并用 C++ 重写了关键步骤,这使得 OpenTSNE 在运行速度上大幅领先于 sklearn。
from openTSNE import TSNE
from sklearn.datasets import load_digits
import matplotlib.pyplot as plt
import numpy as np# 加载数据
digits = load_digits()
X = digits.data
y = digits.target# t-SNE 降维
tsne = TSNE(n_components=2,perplexity=30,metric="euclidean",n_jobs=8,random_state=42,
)
X_tsne = tsne.fit(X)# 可视化
plt.figure(figsize=(12, 12))
colors = plt.cm.rainbow(np.linspace(0, 1, 10))
for i in range(10):plt.scatter(X_tsne[y == i, 0], X_tsne[y == i, 1], color=colors[i], label=str(i))
plt.legend()
plt.show()
三、参数
t-SNE算法的主要参数包括:
n_components(降维后的维度,一般设为2或3);perplexity(困惑度,通常在5到50之间);learning_rate(学习率);random_state
tsne = TSNE(n_components=2, perplexity=30, learning_rate=200, random_state=42)data_tsne = tsne.fit_transform(data_scaled)random_state
- 在需要设置 random_state 的地方给其赋一个值,当多次运行此段代码能够得到完全一样的结果,别人运行此代码也可以复现你的过程。
- 若不设置此参数则会随机选择一个种子,执行结果也会因此而不同了。
- 虽然可以对 random_state 进行调参,但是调参后在训练集上表现好的模型未必在陌生训练集上表现好,所以一般会随便选取一个 random_state 的值作为参数。
四、调参与优化
t-SNE的效果在很大程度上依赖于参数的选择,常用的参数有perplexity、learning_rate等。调参的过程中可以通过网格搜索或交叉验证来选择最优参数。
# 示例:调整perplexity参数for perplexity in [5, 10, 30, 50]:tsne = TSNE(n_components=2, perplexity=perplexity, learning_rate=200, random_state=42)data_tsne = tsne.fit_transform(data_scaled)tsne_df = pd.DataFrame(data_tsne, columns=['Component 1', 'Component 2'])plt.figure(figsize=(10, 8))sns.scatterplot(x='Component 1', y='Component 2', data=tsne_df)plt.title(f't-SNE Visualization with perplexity={perplexity}')plt.show()五、处理大规模数据集
t-SNE对大规模数据集的处理能力有限,通常建议在大数据集上使用先进行降采样或其他降维方法(如PCA)进行预处理。
1、先使用PCA降维
from sklearn.decomposition import PCA# 先使用PCA降维
pca = PCA(n_components=50)data_pca = pca.fit_transform(data_scaled)2、然后使用t-SNE
tsne = TSNE(n_components=2, perplexity=30, learning_rate=200, random_state=42)data_tsne = tsne.fit_transform(data_pca)tsne_df = pd.DataFrame(data_tsne, columns=['Component 1', 'Component 2'])六、解释与应用
t-SNE降维结果的可解释性通常较低,因此在实际应用中需要结合其他分析方法进行解释。例如,可以结合聚类分析、分类模型等方法进行综合分析。