深度学习 --- 基于ResNet50的野外可食用鲜花分类项目代码
深度学习 — 基于ResNet50的野外可食用鲜花分类项目代码
文章目录
- 深度学习 --- 基于ResNet50的野外可食用鲜花分类项目代码
- 项目目录
- 数据集
- 一,项目工具
- cbam
- onnx
- utils
- 混淆矩阵
- 二,模型加入cbam
- 三,模型迁移
- 四,模型训练
- 五,模型推理以及预测
- 六,简易可视化
项目目录
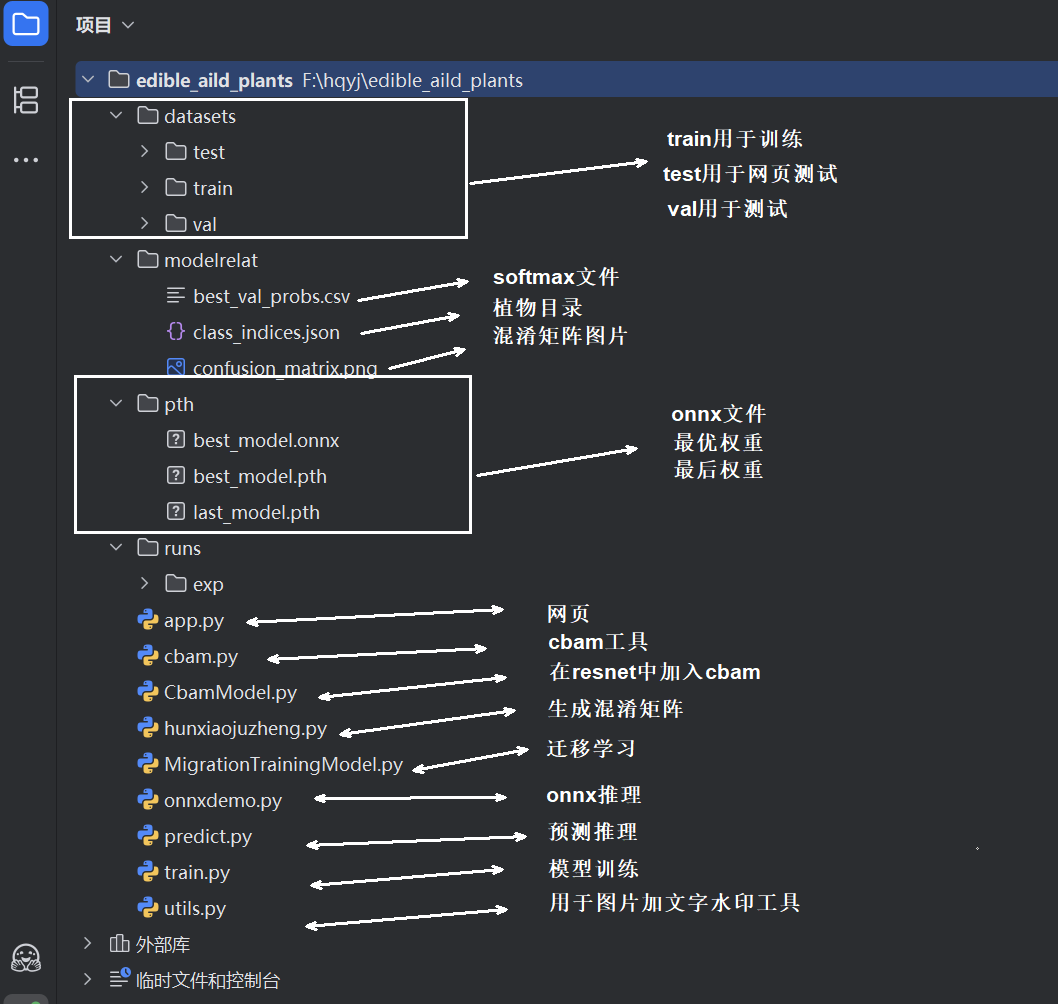
数据集
datasets
链接: https://pan.baidu.com/s/14C1OC5kQuuzGxqEHDqMNuQ
一,项目工具
cbam
cbam.py
import torch
import torch.nn as nnclass ChannelAttention(nn.Module):def __init__(self, in_planes, ratio=16):super().__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.max_pool = nn.AdaptiveMaxPool2d(1)self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)self.relu = nn.ReLU()self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = self.fc2(self.relu(self.fc1(self.avg_pool(x))))max_out = self.fc2(self.relu(self.fc1(self.max_pool(x))))out = avg_out + max_outreturn self.sigmoid(out)class SpatialAttention(nn.Module):def __init__(self, kernel_size=7):super().__init__()self.conv = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = torch.mean(x, dim=1, keepdim=True)max_out, _ = torch.max(x, dim=1, keepdim=True)out = torch.cat([avg_out, max_out], dim=1)out = self.conv(out)return self.sigmoid(out)class CBAM(nn.Module):def __init__(self, in_planes, ratio=16):super().__init__()self.ca = ChannelAttention(in_planes, ratio)self.sa = SpatialAttention()def forward(self, x):x = self.ca(x) * xx = self.sa(x) * xreturn x
onnx
onnxdemo.py
import os
import json
import time
import numpy as np
import onnxruntime as ort
from PIL import Image
from torchvision import transforms
from MigrationTrainingModel import resnet50_my
import torchPTH_PATH = 'pth/best_model.pth' # 权重
ONNX_PATH = 'pth/best_model.onnx' # 导出后 ONNX
IMG_PATH = 'datasets/train/Purple_Deadnettle/Purple-Deadnettle3.jpg' # 待预测图片# 设备
DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')# 预处理
MEAN = (0.5, 0.5, 0.5)
STD = (0.5, 0.5, 0.5)
transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(MEAN, STD)
])# 类别映射
with open('modelrelat/class_indices.json', 'r', encoding='utf-8') as f:idx2name = json.load(f)# -----------------------中文映射 dict-----------------------
plant_cn = {"0": "紫花苜蓿", "1": "芦笋", "2": "蓝马鞭草", "3": "阔叶车前", "4": "牛蓟","5": "香蒲", "6": "繁缕", "7": "菊苣", "8": "猪殃殃", "9": "款冬","10": "苦苣菜", "11": "蓍草", "12": "紫锥花", "13": "金钱薄荷", "14": "绛三叶","15": "皱叶酸模", "16": "飞蓬", "17": "蒲公英", "18": "柔毛黄堇菜", "19": "接骨木","20": "月见草", "21": "蕨叶蓍", "22": "田芥", "23": "柳兰", "24": "勿忘草","25": "蒜芥", "26": "山风铃草", "27": "宝盖草", "28": "老鹳草", "29": "虎杖","30": "乔派草", "31": "矢车菊", "32": "葛藤", "33": "藜", "34": "锦葵","35": "鬼臼", "36": "绣线菊", "37": "水飞蓟", "38": "毛蕊花", "39": "新英格兰紫菀","40": "蔓虎刺", "41": "独行菜", "42": "梭鱼草", "43": "野甘菊", "44": "仙人掌梨","45": "紫花野芝麻", "46": "野胡萝卜", "47": "红三叶", "48": "酸模", "49": "荠菜","50": "春美草", "51": "向日葵", "52": "软茎蔓", "53": "茶树", "54": "川续断","55": "石芥花", "56": "药用蜀葵", "57": "野蜂香", "58": "野黑樱桃", "59": "野葡萄","60": "野韭", "61": "酢浆草"
}# ---------------------------导出 ONNX---------------------------------
def export_onnx():if os.path.exists(ONNX_PATH):print('ONNX 已存在,跳过导出。')returnos.makedirs(os.path.dirname(ONNX_PATH), exist_ok=True)net = resnet50_my(num_classes=50).to(DEVICE)net.load_state_dict(torch.load(PTH_PATH, map_location=DEVICE))net.eval()dummy = torch.randn(1, 3, 224, 224).to(DEVICE)torch.onnx.export(net, dummy, ONNX_PATH,export_params=True,opset_version=11,do_constant_folding=True,input_names=['input'],output_names=['output'],dynamic_axes={'input':{0:'batch_size'}, 'output':{0:'batch_size'}})print('ONNX 导出完成:', ONNX_PATH)# -----------------ONNX 推理--------------------------
def onnx_predict(img_path: str):export_onnx() # 确保已导出sess = ort.InferenceSession(ONNX_PATH)input_name = sess.get_inputs()[0].nameimage = Image.open(img_path).convert('RGB')tensor = transform(image).unsqueeze(0).numpy()start = time.time()logits = sess.run(None, {input_name: tensor})[0]cost = (time.time() - start) * 1000prob = float(np.max(logits))idx = int(np.argmax(logits))name_en = idx2name.get(str(idx), 'Unknown')name_cn = plant_cn.get(str(idx), '未知植物')print(f'推理耗时: {cost:.2f} ms')return idx, name_en, name_cn, prob# ---------------- 主函数 ----------------------if __name__ == '__main__':idx, name_en, name_cn, prob = onnx_predict(IMG_PATH)print(f'预测索引: {idx}')print(f'英文名称: {name_en}')print(f'中文名称: {name_cn}')print(f'置信度 : {prob:.4f}')
utils
utils.py
from shutil import copy
import uuid
from PIL import Image, ImageDraw, ImageFont
import cv2
import numpy as np
import re
import json
import requests# 生成UUID的函数
def generate_uuid():return str(uuid.uuid4())# opencv实现视频里面写入中文字符串的函数
def cv2AddChineseText(img, text, position, textColor, textSize):if (isinstance(img, np.ndarray)): # 判断是否OpenCV图片类型img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))# 创建一个可以在给定图像上绘图的对象draw = ImageDraw.Draw(img)# 字体的格式fontStyle = ImageFont.truetype("simsun.ttc", textSize, encoding="utf-8") # simsun.ttc语言包放在程序同级目录下# 绘制文本draw.text(position, text, textColor, font=fontStyle)# 转换回OpenCV格式return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)# 把json字符串写入到json文件中。
"""
def writ2json(data, path):with open(path + '/result.json', 'w', encoding='utf-8') as file:# 将字符串写入文件file.write(data)
"""def writ2json(data, path):# 确保路径存在斜杠结尾if not path.endswith('/'):path += '/'# 检查输入数据是字符串还是Python对象if isinstance(data, str):# 如果是字符串,解析为Python对象parsed_data = json.loads(data)else:# 如果是Python对象(如字典/列表),直接使用parsed_data = data# 将格式化后的JSON写入文件with open(path + 'result.json', 'w', encoding='utf-8') as file:json.dump(parsed_data, file, indent=4, ensure_ascii=False)# 读取json文件返回json字符串
def read2json(path):with open(path, 'r', encoding='utf-8') as file:# 读取文件内容data = file.read()result_json = json.loads(data)return result_jsondef query_fruit_nutrition(fruit_name):url = "https://www.simoniu.com/commons/nutrients/"response = requests.get(url + fruit_name)# print(response.text)jsonObj = json.loads(response.text)return jsonObj['data']
混淆矩阵
hunxiaojuzheng.py
import torch
import json
import seaborn as sns
import matplotlib.pyplot as plt
from torchvision import transforms, datasets
from sklearn.metrics import confusion_matrix
from torch.utils.data import DataLoader
from MigrationTrainingModel import resnet50_my# ---------------- 配置 ----------------
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
json_path = "modelrelat/class_indices.json"
class_indict = json.load(open(json_path, 'r'))
num_classes = len(class_indict)# ----------------数据预处理----------------
transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])# ----------------加载测试集(按文件夹分好类)----------------
test_dir = "datasets/train"
test_dataset = datasets.ImageFolder(root=test_dir, transform=transform)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)# ----------------加载模型----------------
weights_path = "pth/best_model.pth"
model = resnet50_my(num_classes=num_classes).to(device)
model.load_state_dict(torch.load(weights_path, map_location=device))
model.eval()# ----------------收集预测和标签----------------
all_preds = []
all_labels = []with torch.no_grad():for inputs, labels in test_loader:inputs = inputs.to(device)labels = labels.to(device)outputs = model(inputs)_, preds = torch.max(outputs, 1)all_preds.extend(preds.cpu().numpy())all_labels.extend(labels.cpu().numpy())# ----------------生成混淆矩阵----------------
cm = confusion_matrix(all_labels, all_preds)# ----------------可视化----------------
plt.figure(figsize=(9, 9))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',xticklabels=list(class_indict.values()),yticklabels=list(class_indict.values()))
plt.title('Confusion Matrix - Plant Classification')
plt.ylabel('True Label')
plt.xlabel('Predicted Label')
plt.xticks(rotation=90)
plt.yticks(rotation=0)
plt.tight_layout()
plt.savefig("modelrelat/confusion_matrix.png")
plt.show()
二,模型加入cbam
CbamModel.py
import torch.nn as nn
from torchvision.models.resnet import ResNet, Bottleneck
from cbam import CBAMclass BottleneckCBAM(Bottleneck):def __init__(self, *args, **kwargs):super().__init__(*args, **kwargs)# ---------------- 用 conv3 的输出通道数初始化 CBAM----------------out_channels = self.conv3.out_channelsself.cbam = CBAM(out_channels)def forward(self, x):identity = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out = self.relu(out)out = self.conv3(out)out = self.bn3(out)# ----------------在残差相加前加 CBAM----------------out = self.cbam(out)if self.downsample is not None:identity = self.downsample(x)out += identityout = self.relu(out)return outdef resnet50_cbam(num_classes: int = 50):model = ResNet(block=BottleneckCBAM,layers=[3, 4, 6, 3],replace_stride_with_dilation=[False, False, False])model.fc = nn.Linear(2048, num_classes)return modelif __name__ == '__main__':model = resnet50_cbam()print(model)
三,模型迁移
MigrationTrainingModel.py
import torch.nn as nn
from torchvision.models import resnet50,ResNet50_Weights
from CbamModel import resnet50_cbamdef resnet50_my(num_classes: int = 50,train_layers=('layer3', 'layer4', 'fc'),pretrained: bool = True,):# ----------------建模型----------------model = resnet50_cbam(num_classes=num_classes)# ----------------迁移权重----------------if pretrained:state = resnet50(weights=ResNet50_Weights.DEFAULT).state_dict()own = model.state_dict()state = {k: v for k, v in state.items()if k in own and v.shape == own[k].shape}own.update(state)model.load_state_dict(own, strict=False)# ---------------- 冻结----------------for name, p in model.named_parameters():if any(layer in name for layer in train_layers) or 'cbam' in name:p.requires_grad = Trueelse:p.requires_grad = Falseprint("Loaded pretrained weights:", len(state), "keys")return modelif __name__ == '__main__':model = resnet50_my()print(model)
四,模型训练
import os
import sys
import json
import torch
import numpy as np
import pandas as pd
import torch.nn as nn
from torchvision import transforms, datasets
import torch.optim as optim
from tqdm import tqdm
from MigrationTrainingModel import resnet50_my
from torch.utils.tensorboard import SummaryWriter
from sklearn.metrics import classification_reportdef train():# ---------------- 使用GPU训练 ----------------device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print("using {} device.".format(device))# 查看使用的 GPU# ---------------- 数据预处理 ----------------data_transform = {"train": transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),"val": transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}# ---------------- 数据集 ----------------data_root = os.path.abspath(os.path.join(os.getcwd(), 'datasets'))image_path = os.path.join(data_root, 'train')print("当前脚本目录:", os.path.dirname(os.path.abspath(__file__)))print("实际 dataset 路径:", image_path)print("路径是否存在:", os.path.exists(image_path))print("类别列表:", os.listdir(image_path))dataset = datasets.ImageFolder(root=image_path, transform=data_transform["train"])train_num = len(dataset)# ---------------- 类别索引 -> 类别名称----------------plant_list = dataset.class_to_idxcla_dict = dict((val, key) for key, val in plant_list.items())json_str = json.dumps(cla_dict, indent=4)with open('modelrelat/class_indices.json', 'w') as json_file:json_file.write(json_str)# ---------------- 划分训练集和验证集 ----------------train_size = int(0.8 * len(dataset))val_size = len(dataset) - train_sizetrain_dataset, validate_dataset = torch.utils.data.random_split(dataset, [train_size, val_size])# ----------------数据加载器----------------batch_size = 32train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=0)validate_loader = torch.utils.data.DataLoader(validate_dataset, batch_size=batch_size, shuffle=False, num_workers=0)print("using {} images for training, {} images for validation.".format(train_size, val_size))# 打印训练集和验证集的数量# ---------------- 模型,损失函数,优化器 ----------------net = resnet50_my(num_classes=50)#模型选择net.to(device)loss_function = nn.CrossEntropyLoss()#损失函数是交叉熵optimizer = optim.Adam(net.parameters(), lr=0.001)#优化器选择是 Adambest_model_path = 'pth/best_model.pth'last_model_path = 'pth/last_model.pth'os.makedirs('pth', exist_ok=True)# -------------- 继续训练:加载已有权重 --------------start_epoch = 0best_acc = 0.0if os.path.isfile(best_model_path):print("✅ 发现已有权重,继续训练...")net.load_state_dict(torch.load(best_model_path, map_location=device))else:print("⏩ 从头训练...")epochs = 80train_steps = len(train_loader)# ---------------- TensorBoard writer ----------------# 使用代码 tensorboard --logdir runs/exp 在命令行运行writer = SummaryWriter('runs/exp')# ---------------- 训练循环 ----------------best_probs = Nonebest_labels = Nonebest_preds = Nonefor epoch in range(start_epoch, start_epoch + epochs):net.train()running_loss = 0.0train_bar = tqdm(train_loader, file=sys.stdout)for step, data in enumerate(train_bar):images, labels = dataimages, labels = images.to(device), labels.to(device)optimizer.zero_grad()outputs = net(images)loss = loss_function(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()train_bar.desc = f"epoch[{epoch+1}/{start_epoch+epochs}] loss:{loss:.3f}"# ---------------- 验证 ----------------net.eval()all_preds, all_labels = [], []all_probs = []acc = 0.0with torch.no_grad():val_bar = tqdm(validate_loader, file=sys.stdout)for data in val_bar:images, labels = dataimages, labels = images.to(device), labels.to(device)outputs = net(images)probs = torch.softmax(outputs, dim=1)preds = torch.max(outputs, dim=1)[1]all_probs.append(probs.cpu().numpy())all_preds.append(preds.cpu().numpy())all_labels.append(labels.cpu().numpy())acc += torch.eq(preds, labels).sum().item()val_accurate = acc / val_sizeprint(f'[epoch {epoch+1}] loss: {running_loss/train_steps:.3f} val_acc: {val_accurate:.3f}')# ----------------缓存当前结果----------------all_probs = np.concatenate(all_probs)all_preds = np.concatenate(all_preds)all_labels = np.concatenate(all_labels)# ---------------- TensorBoard ----------------writer.add_scalar('Loss/train', running_loss / train_steps, epoch + 1)writer.add_scalar('Acc/val', val_accurate, epoch + 1)# ---------------- 保存模型 ----------------torch.save(net.state_dict(), last_model_path)if val_accurate > best_acc:best_acc = val_accuratetorch.save(net.state_dict(), best_model_path)# 缓存最佳 epoch 的 softmaxbest_probs = all_probsbest_labels = all_labelsbest_preds = all_preds# ---------------- 训练结束,打印 ----------------print('\n----------------指标报告 ----------------')print(classification_report(best_labels, best_preds, digits=5, zero_division=0))# ---------------- softmax ----------------if best_probs is not None:df = pd.DataFrame(best_probs,columns=[f'prob_{i}' for i in range(best_probs.shape[1])])df['true_label'] = best_labelsdf['pred_label'] = best_predsdf.to_csv('modelrelat/best_val_probs.csv', index=False, float_format='%.6f')print('已保存softmax')writer.close()print('Finished Training')if __name__ == '__main__':train()
五,模型推理以及预测
import os
import time
import json
import torch
from PIL import Image
from torchvision import transforms
from MigrationTrainingModel import resnet50_mydevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")MEAN = (0.5, 0.5, 0.5)
STD = (0.5, 0.5, 0.5)transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(MEAN, STD)
])json_path = r"modelrelat/class_indices.json"
class_indict = json.load(open(json_path, 'r'))weights_path = r"pth/best_model.pth"
model = resnet50_my(num_classes=50).to(device)
model.load_state_dict(torch.load(weights_path, map_location=device))
model.eval()def image_predict(image_path: str):start_time = time.time()if not os.path.exists(image_path):predicted_class = torch.tensor([-1])else:img = Image.open(image_path).convert('RGB')img_tensor = transform(img).unsqueeze(0)predicted_class = predict(img_tensor)end_time = time.time()print(f'植物识别时间: {(end_time - start_time) * 1000:.2f} ms')return predicted_classdef predict(img_tensor: torch.Tensor):img_tensor = img_tensor.to(device)with torch.no_grad():output = model(img_tensor)_, predicted = torch.max(output, 1)return predicteddef map_plant_class(predicted_class: torch.Tensor):plant_to_chinese = {"0": "Alfalfa","1": "Asparagus","2": "Blue_Vervain","3": "Broadleaf_Plantain","4": "Bull_Thistle","5": "Cattail","6": "Chickweed","7": "Chicory","8": "Cleavers","9": "Coltsfoot","10": "Common_Sow_Thistle","11": "Common_Yarrow","12": "Coneflower","13": "Creeping_Charlie","14": "Crimson_Clover","15": "Curly_Dock","16": "Daisy_Fleabane","17": "Dandellion","18": "Downy_Yellow_Violet","19": "Elderberry","20": "Evening_Primrose","21": "Fern_Leaf_Yarrow","22": "Field_Pennycress","23": "Fireweed","24": "Forget_Me_Not","25": "Garlic_Mustard","26": "Harebell","27": "Henbit","28": "Herb_Robert","29": "Japanese_Knotweed","30": "Joe_Pye_Weed","31": "Knapweed","32": "Kudzu","33": "Lambs_Quarters","34": "Mallow","35": "Mayapple","36": "Meadowsweet","37": "Milk_Thistle","38": "Mullein","39": "New_England_Aster","40": "Partridgeberry","41": "Peppergrass","42": "Pickerelweed","43": "Pineapple_Weed","44": "Prickly_Pear_Cactus","45": "Purple_Deadnettle","46": "Queen_Annes_Lace","47": "Red_Clover","48": "Sheep_Sorrel","49": "Shepherds_Purse","50": "Spring_Beauty","51": "Sunflower","52": "Supplejack_Vine","53": "Tea_Plant","54": "Teasel","55": "Toothwort","56": "Vervain_Mallow","57": "Wild_Bee_Balm","58": "Wild_Black_Cherry","59": "Wild_Grape_Vine","60": "Wild_Leek","61": "Wood_Sorrel"}return plant_to_chinese.get(str(predicted_class.item()), "未知植物")if __name__ == "__main__":image_path = r"datasets/train/Chicory/Chicory2.jpg"pred_idx = image_predict(image_path)print(f"Predicted index: {pred_idx.item()}")print(f"Predicted Plant Class: {map_plant_class(pred_idx)}")
六,简易可视化
import cv2
import torch
import torch.nn as nn
import numpy as np
import gradio as gr
import torchvision.transforms as transforms
from predict import map_plant_class,image_predict
from utils import cv2AddChineseTextplant_to_chinese = {"Alfalfa": "紫花苜蓿","Asparagus": "芦笋","Blue_Vervain": "蓝马鞭草","Broadleaf_Plantain": "阔叶车前","Bull_Thistle": "牛蓟","Cattail": "香蒲","Chickweed": "繁缕","Chicory": "菊苣","Cleavers": "猪殃殃","Coltsfoot": "款冬","Common_Sow_Thistle": "苦苣菜","Common_Yarrow": "蓍草","Coneflower": "紫锥花","Creeping_Charlie": "金钱薄荷","Crimson_Clover": "绛三叶","Curly_Dock": "皱叶酸模","Daisy_Fleabane": "飞蓬","Dandellion": "蒲公英","Downy_Yellow_Violet": "柔毛黄堇菜","Elderberry": "接骨木","Evening_Primrose": "月见草","Fern_Leaf_Yarrow": "蕨叶蓍","Field_Pennycress": "田芥","Fireweed": "柳兰","Forget_Me_Not": "勿忘草","Garlic_Mustard": "蒜芥","Harebell": "山风铃草","Henbit": "宝盖草","Herb_Robert": "老鹳草","Japanese_Knotweed": "虎杖","Joe_Pye_Weed": "乔派草","Knapweed": "矢车菊","Kudzu": "葛藤","Lambs_Quarters": "藜","Mallow": "锦葵","Mayapple": "鬼臼","Meadowsweet": "绣线菊","Milk_Thistle": "水飞蓟","Mullein": "毛蕊花","New_England_Aster": "新英格兰紫菀","Partridgeberry": "蔓虎刺","Peppergrass": "独行菜","Pickerelweed": "梭鱼草","Pineapple_Weed": "野甘菊","Prickly_Pear_Cactus": "仙人掌梨","Purple_Deadnettle": "紫花野芝麻","Queen_Annes_Lace": "野胡萝卜","Red_Clover": "红三叶","Sheep_Sorrel": "酸模","Shepherds_Purse": "荠菜","Spring_Beauty": "春美草","Sunflower": "向日葵","Supplejack_Vine": "软茎蔓","Tea_Plant": "茶树","Teasel": "川续断","Toothwort": "石芥花","Vervain_Mallow": "药用蜀葵","Wild_Bee_Balm": "野蜂香","Wild_Black_Cherry": "野黑樱桃","Wild_Grape_Vine": "野葡萄","Wild_Leek": "野韭","Wood_Sorrel": "酢浆草"
}# 预处理
transform = transforms.Compose([transforms.ToTensor(),transforms.Resize((512, 512)),
])def plant_shibie(image_path):origin_img = cv2.imread(image_path)print("图片路径:", image_path)class_name=image_predict(image_path)print("识别结果:",class_name.item())mapped_animal_class=map_plant_class(class_name)result = ""if (mapped_animal_class!='None'):result = mapped_animal_classprint("识别结果:", result)test_img = cv2AddChineseText(origin_img,text=plant_to_chinese[result],position=(40, 40),textColor=(38, 223, 223), # BGRtextSize=40)# 3. BGR → RGBtest_img = cv2.cvtColor(test_img, cv2.COLOR_BGR2RGB)return test_img# 在TabbedInterface外层包裹Blocks并添加CSS样式# 定义更完善的蓝色主题CSS样式
custom_css = """
/* 主容器设置 */
/* 强制重置所有容器宽度 */
gradio-app > .gradio-container {max-width: 100% !important;width: 100% !important;min-width: 90% !important;margin: 0 auto !important;padding: 0px !important;
}gradio-app > div{margin: 0px !important;
}/* 覆盖内部容器限制 */
.contain, .blocks, .block, .panel {max-width: 100% !important;width: 100% !important;min-width: 100% !important;margin: 0px !important;
}/* 消除所有潜在宽度限制 */
.gr-box, .gr-block, .interface {max-width: none !important;width: auto !important;
}/* 主标题样式 */
h1 {font-size: 24px !important;color: #1565C0 !important;text-shadow: 2px 2px 4px rgba(25, 118, 210, 0.3) !important;background: linear-gradient(to right, #F0F8FF, #C6E2FF) !important;padding: 5px !important;border-radius: 12px !important;text-align: center !important;margin-top: 5px !important;margin-bottom: 10px !important;
}/* 选项卡按钮基础样式 */
button.tab-button {background-color: #E3F2FD !important;color: #0D47A1 !important;border: 1px solid #90CAF9 !important;margin: 2px !important;padding: 10px 25px !important;border-radius: 5px !important;transition: all 0.3s ease !important;font-weight: 500 !important;
}/* 鼠标悬停效果 */
button.tab-button:hover {background-color: #BBDEFB !important;transform: translateY(-2px) !important;box-shadow: 0 2px 8px rgba(25, 118, 210, 0.2) !important;
}/* 选中状态 */
button.tab-button.selected {background: #2196F3 !important;color: white !important;border-bottom: 3px solid #1976D2 !important;box-shadow: 0 4px 6px rgba(33, 150, 243, 0.4) !important;
}/* 选项卡容器 */
div.tabs {background: linear-gradient(145deg, #F8F9FA, #E9ECEF) !important;padding: 12px !important;border-radius: 12px !important;box-shadow: 0 4px 12px rgba(0, 0, 0, 0.1) !important;margin-bottom: 10px !important;
}
"""school_name = "野外可食用植物智能识别检测系统"plant_interface=gr.Interface(fn=plant_shibie,title='野外可食用植物智能识别检测系统',inputs=[gr.Image(label='源图片',type="filepath")],outputs=[gr.Image(show_label=False)],examples=[['datasets/train/Purple_Deadnettle/Purple-Deadnettle3.jpg'], ['datasets/test/Dandellion.jpg'],['datasets/test/Asparagus.jpg'],['datasets/test/Sunflower.jpg'],['datasets/test/Blue_Vervain.jpg']]
)with gr.Blocks(css=custom_css, theme=gr.themes.Default(primary_hue="blue")) as myapp:tabbed_interface = gr.TabbedInterface([plant_interface],["🌿野外可食用植物智能识别检测系统" ],title=("<div style='text-align: center; padding: 20px; text-decoration:underline'>"f"🚀{school_name}卷积神经网络项目<br>""<div style='font-size: 0.8em; color: #1976D2; text-decoration:none !important;'>CNN卷积神经网络项目集合</div>""</div>"))if __name__ == '__main__':# 定义端口号gradio_port = 8888gradio_url = f"http://127.0.0.1:{gradio_port}"myapp.launch(server_name="127.0.0.1",server_port=gradio_port,debug=True,# auth=("admin", "123456"),# auth_message="请输入账号信息访问此应用。测试账号:admin,密码:123456",# inbrowser=False,# prevent_thread_lock=True,)